大数据推荐系统课程笔记
-
电商网站的推荐是分为多个模块的, 不同的模块使用不同的推荐逻辑
-
推荐系统算法的目的是挑选出用户真正喜欢的东西进行推荐
-
课程主要内容:
-
推荐系统概述:
-
推荐系统的目的:
-
针对信息过载推出的初步筛选措施, 将海量内容中用户可能感兴趣的内容进行推送
-
对于商家, 如果其质量过硬, 让更多的人获取其的资讯
-
-
推荐系统的应用:
证券/理财, 个性化旅游, 个性化广告, 个性化邮件, 位置服务, 个性化阅读, 社交网络, 电影视频, 电子商务, 个性化音乐不同的应用环境有不同的主要矛盾也有不同的解决方案
例如: 电子商务中用户购买了一个物品之后短时间内可能没有更多的需求, 但是音乐可能会有更多的需求
用户在浏览电商网站的时候一般都是集中精神, 但是对于音乐可能集中的精力不多. 所以不同的推荐系统的原则是不同的
-
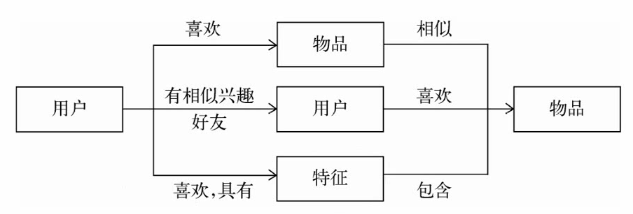
推荐系统的基本思想
了解用户想要的东西, 将有对应属性的物品推荐给用户. 但是由于很多时候用户自己也不知道自己想要什么, 所以需要通过机器学习的方式, 从其行动历史, 社交网络中得到其需求的抽象画像
![]()
三种常见的推荐思路:
-
如果用户的需求特征可以获取, 且物品的特征可以获取, 则将符合用户需求特征的物品推荐给用户
-
如果用户的需求特征能够在一段时间内保持不变, 则根据用户的行为历史, 利用
购买,点赞等行为推断其需求特征 -
如果用户的需求和其他用户的需求横向具有相似性, 则可以通过横向的需求特征的迁移来推断用户的需求特征
注: 这里的基本思路都是
知你所想, 精准推荐, 但是当所想不能被直接获知的时候, 使用物以类聚和人以群分的方式进行需求的推断 -
-
推荐系统中的数据分析:
-
用户数据: 个人信息, 喜好标签 用户基本信息: 性别, 年龄, 兴趣标签
-
物品信息: 内容信息, 分类标签, 关键词 (分类标签和关键词是为了进行精确的推荐而对内容信息进行的预处理) 推荐物品的元数据: 关键字, 分类标签, 基因描述
-
用户和物品的关联信息: 评分, 标签, 点击, 浏览, 购买, 收藏 用户行为信息: 显式反馈数据, 隐式反馈数据
-
-
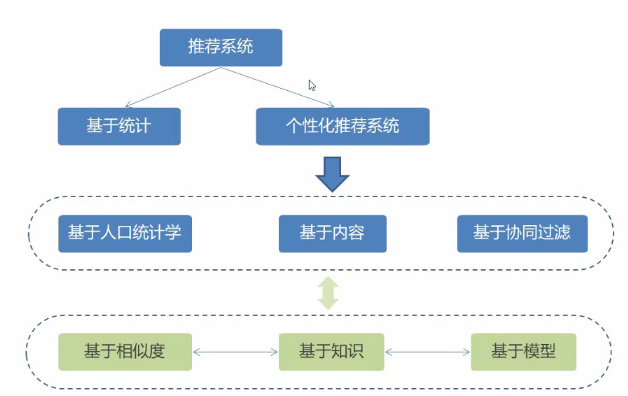
推荐系统的分类
-
根据结果的实时性:
-
离线推荐
-
实施推荐
-
-
根据推荐的原则分类:
-
基于相似度推荐: 进行
物以类聚人以群分的推荐思路, 计算不同物品, 不同用户之间的相似程度, 进行推荐 -
基于知识的推荐(基于规则): 直接规定什么人推荐什么物品的规则 进行推荐
-
基于模型的推荐: 通过训练模型来发现规则, 然后使用规则进行推荐
-
-
根据结果是否个性化分类:
-
基于统计的非个性化分类
-
个性化推荐
-
-
基于数据源的分类:
-
基于人口统计学的推荐: 主要基于用户的数据进行的推荐 (关键词: 用户标签, 用户画像)
-
基于内容的推荐: 主要基于商品的信息的推荐
-
基于协同过滤的推荐: 主要基于用户的行为数据进行的推荐
![]()
-
-
-
-
推荐算法分类: (按照数据源进行的分类 – 由此可见, 不同的数据源有不同的内在结构, 也绑定了不同的算法结构)
-
基于人口统计学的推荐
基于用户的基本信息, 对于其进行相似度的计算
-
基于内容的推荐
基于内容的基本信息以及标签, 对其进行相似度计算
-
基于协同过滤的推荐
用户和物品的关系可以表现为一个二部图, 通过图中的链接进行物品的过滤
-
基于近邻的过滤(cluster): – 也是基于相似性
-
用户近邻
-
物品近邻
-
-
基于模型的过滤:
-
奇异值分解
-
潜在语义分析
-
支持向量机
-
-
-
混合推荐
-
加权混合
-
切换混合: 为不同的用户使用不同的推荐逻辑
-
分区混合: 将不同的推荐结果放置在UI中不同的位置
-
分层混合: 进行多层的推荐, 底层的推荐被看作上层推荐的输入
-
-
-
推荐系统的评测方法
-
什么推荐系统是好的推荐系统:
-
让用户更快的获取到自己需要的内容
-
让内容更好的推送到需要的用户手中
-
让平台更有效地保留用户资源
-
-
评价方式:
-
离线实验: 使用离线的数据进行模型的训练和测试 (方便, 但是无法直接获得业务上关注的指标)
-
用户调查: 寻找一些用户进行测试, 并提供问卷咨询 (成本较高, 样本数量要足够)
-
AB测试: 将用户随机分为两组, 使用不同的推荐系统, 统计不同推荐系统中的用户表现 (用户行为搜集时间长, 但是用户数据真实)
-
-
评价指标;
-
预测准确度: 离线可获得
-
评分预测: 通过预测评分来衡量用户可能的满意程度, 准确度一般使用
均方根误差(RMSE)或者平均绝对误差(MAE)进行评价 -
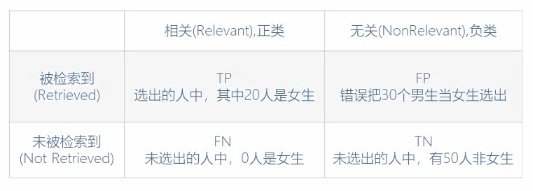
Top-N推荐评价: 由于网站推荐展示只显示前N个, 所以考察前N个对象中用户喜欢的数量(例如, 点击的数量). 使用
精确度(precision)和召回率(recall)进行计算由于其结果本质是一个二分类问题, 所以可以使用混淆矩阵![]()
-
-
用户满意度: 问卷调查
-
覆盖率: 长尾分布, 小众推荐, 离线可获得
-
多样性: 不同时间推荐的物品之间的差异性, 离线可获得
-
惊喜度: 问卷调查
-
信任度: 问卷调查
-
实时性: 代码功能, 离线可获得
-
健壮性: 代码功能,离线可获得
-
商业目标 (如, 点击率, 用户量等)
-
-
-
项目设计:
-
项目框架
-
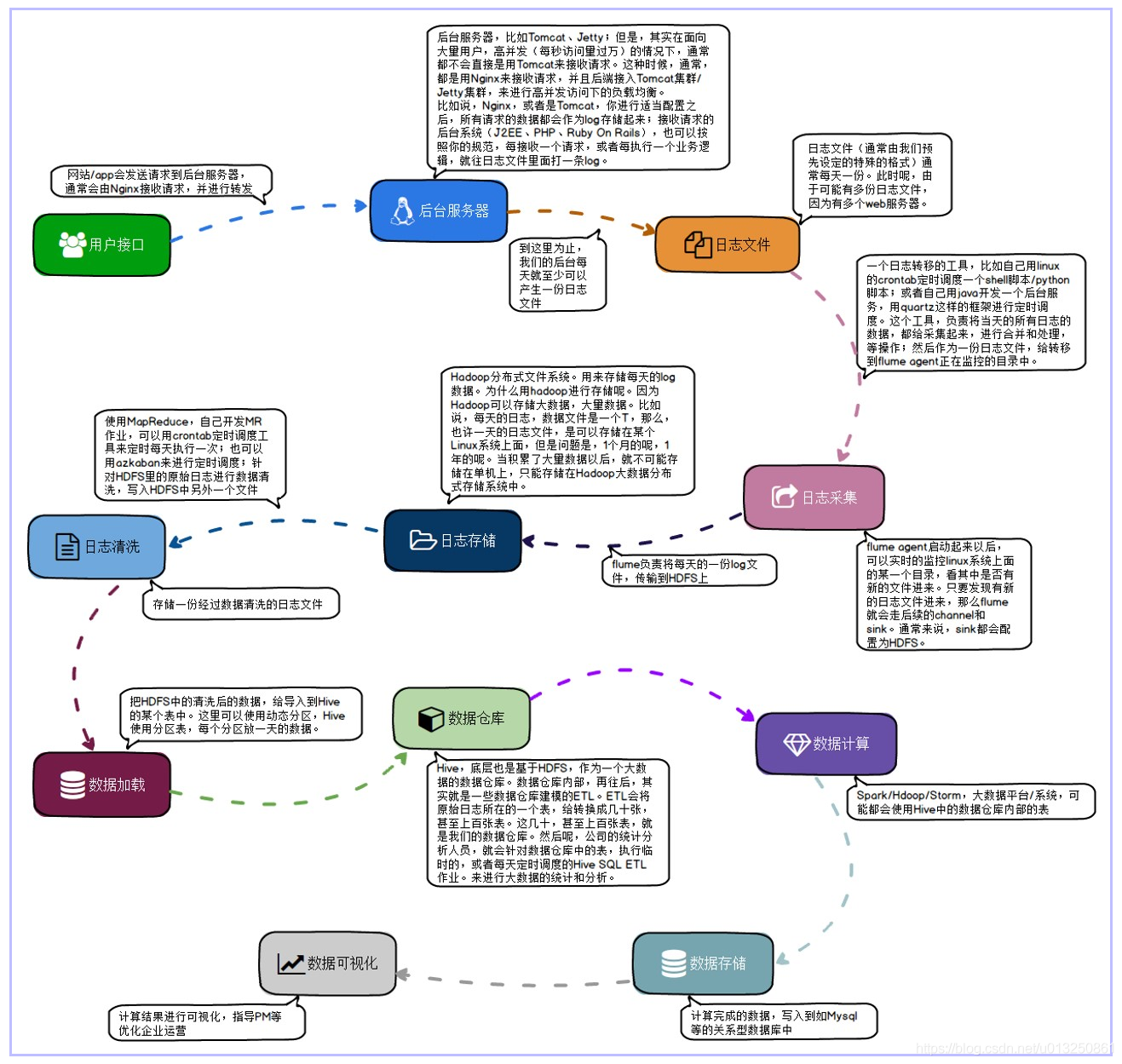
大数据处理流程
(以下图片来自: https://blog.csdn.net/u013250861/article/details/112597851)
![]()
![]()
![]()
-
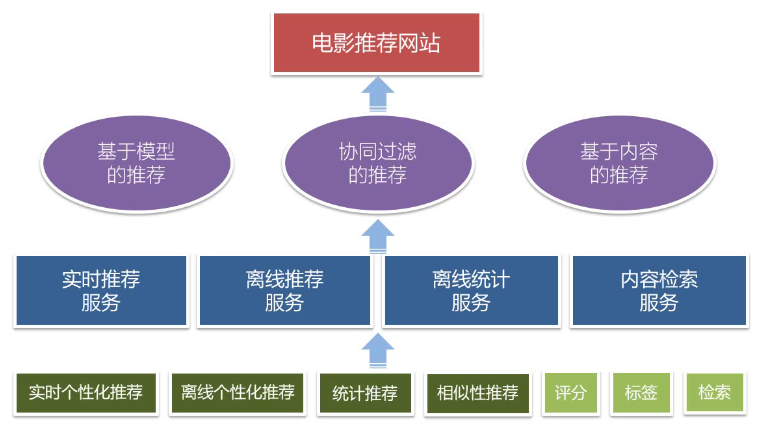
系统模块设计
![]()
-
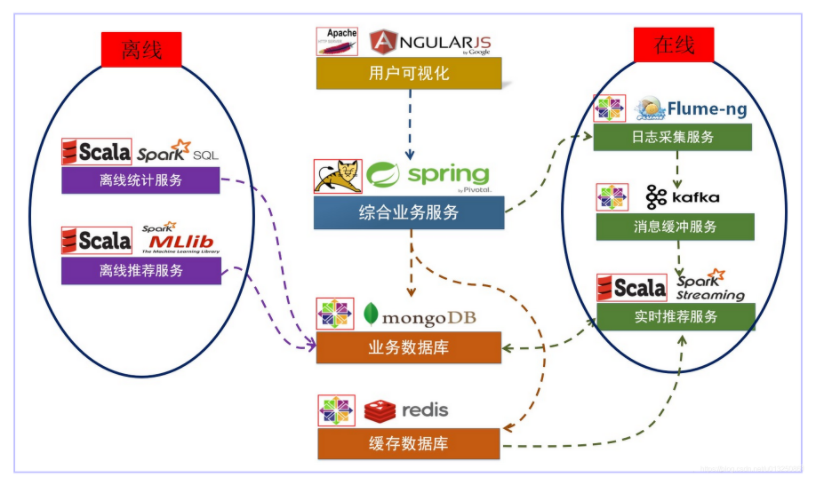
项目系统架构
![]()
-
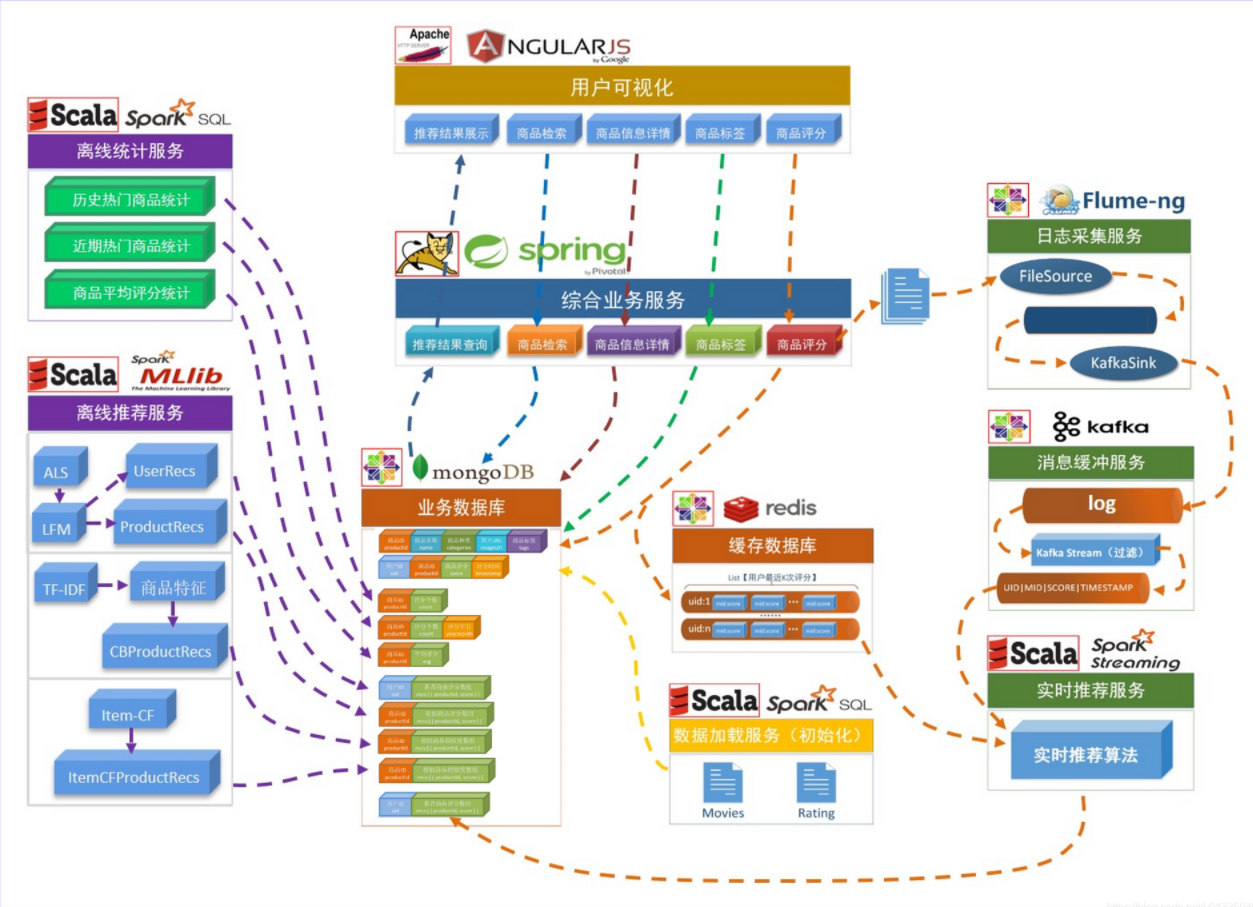
项目数据流
![]()
-
-
数据源解析:
-
研究每个属性和推荐内容的相关性
-
通过数据源的数据建立数据模型, 对于每个推荐内容分别创建对应的数据存储结构
-
-
统计推荐模块
-
历史热门, 近期热门, 平均评分, Top10统计
-
-
离线推荐模块
-
ALS隐语义模型, 电影相似度推荐, 用户相似度推荐
-
-
实时推荐模块
-


 浙公网安备 33010602011771号
浙公网安备 33010602011771号