
后端算法实现领域需要学习的内容
部分资料来源于维基百科
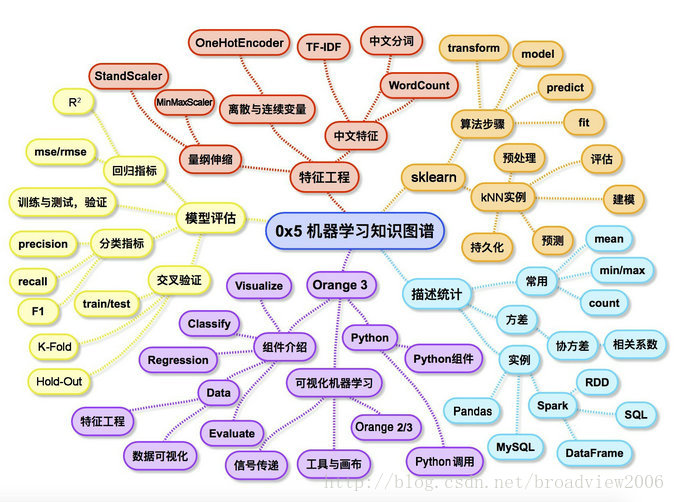
机器学习知识:
Hadoop:
-
是什么: Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架。它支持在商用硬件构建的大型集群上运行的应用程序。Hadoop是根据谷歌公司发表的MapReduce和Google文件系统的论文自行实现而成。
-
MapReduce: 是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(归纳)”,及他们的主要思想,都是从函数式编程语言借鉴的,还有从矢量编程语言借来的特性。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归纳)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
-
Google档案系统: GFS专门为Google的核心数据即页面搜索的存储进行了优化。数据使用大到若干G字节的大文件持续存储,而这些文件极少被删除、覆盖或者减小;通常只是进行添加或读取操作。它也是针对Google的计算机集群进行的设计和优化,这些节点是由廉价的“常用”计算机组成,这就意味着必须防止单个节点的高损害率和随之带来的数据丢失。其它设计理念包括高数据吞吐率,甚至这带来了存取反应期变差。
-
-
资源推荐(推荐资料来源于网络)
-
《Hadoop权威指南(第1版)曾大聃译》
-
《Hadoop权威指南(第2版) 周敏奇译》
-
《Hadoop权威指南(第4版) 华东师范大学数据科学与工程学院译》
-
-
-
java + python
后端服务器语言和后端机器学习建模
mysql + redis
开源关系型数据库和非关系型数据兄弟
hive
-
Apache Hive是一个建立在Hadoop架构之上的数据仓库。它能够提供数据的精炼,查询和分析。可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Kafka
-
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库。该设计受事务日志的影响较大。
-
资源
-
flink
-
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和管道方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
Flink提供高吞吐量、低延迟的流数据引擎以及对事件-时间处理和状态管理的支持。Flink应用程序在发生机器故障时具有容错能力,并且支持exactly-once语义。程序可以用Java、Scala、Python和SQL等语言编写,并自动编译和优化到在集群或云环境中运行的数据流程序。
Flink并不提供自己的数据存储系统,但为Amazon Kinesis、Apache Kafka、Alluxio、HDFS、Apache Cassandra和Elasticsearch等系统提供了数据源和接收器。
-
资源
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号