
对于NS3源码分析的反思与总结
-
构建断点调试环境是进行源码分析的第一步. 以下是VSCode配置文件,以及开启调试的代码:
{
"version": "0.2.0",
"configurations": [
{
"name": "dctcp",
"type": "cppdbg",
"request": "launch",
"program": "/home/*****/ns3.35/ns-allinone-3.35/ns-3.35/build/scratch/${fileBasenameNoExtension}",
"args": [],
"stopAtEntry": false,
"cwd": "/home/*****/ns3.35/ns-allinone-3.35/ns-3.35/scratch",
"environment": [],
"externalConsole": true,
"MIMode": "gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
// "preLaunchTask": "build",
"miDebuggerPath": "/usr/bin/gdb",
"miDebuggerServerAddress": "localhost:1234"
},
]
}# 进行waf的配置: 关闭python接口,减少编译量
./waf --disable-python configure
# 进行编译:
./waf
# 将NS3 LOG输出为文件:
./waf --run scratch/test.cc > ns3_log.out 2>&1
# 开启gdbserver进行断点调试:
./waf --run scratch/test.cc --command-template='gdbserver :1234 %s' # 这里的 command-template 的 %s 相当于编译后可执行文件的全路径 -
进行源码阅读的时候我认为需要按照以下步骤进行分析:
-
了解应用系统基本的抽象概念:
例如: NS3中重要的抽象概念有: Node, NetDevice, Protocol, Channel, Packet, Socket, Scheduler 等
不需要了解每个抽象概念是怎么实现的, 只需要对其的作用有一个大概的认识, 方便在后续环节中更好地理解模块之间地调用
-
对于应用的主循环或主方法有一个大致认识:
当然,这一点不知道对于其他应用是否成立. 在NS3中,
Simulator::Run ();就是其主入口从主入口开始断点, 通过进入主入口的函数找到运行模块的逻辑
![]()
-
对于核心容器中的内容进行分析:
由于NS3和很多其他面向对象的程序一样使用了
interface,CallBack进行对象之间的调用, 直接阅读静态的代码只能读到接口的声明,而不能获得具体的对象信息.这种情况下,可以通过在基类中创建自己的函数, 进行对象内容的打印. 为什么不用断点进行查看? 因为在模拟程序中需要查看的对象数量较大, 一般有十几到几十个, 如果使用断点则需要清晰记住每个中断的时候对应的是哪个对象, 非常的困难.
这是我在
Object类中创建的进行对象内容打印的函数. 似乎是由于NS3中的对象的引用间存在循环, 导致如果放开递归限制会造成栈溢出. 所以我在这对递归的层数进行了限制.void Object::recurentPrintHelper(Ptr<Object> instance, size_t level){
std::string shifting = "";
for (size_t i = 0; i < level; i++)
{
shifting += "\t";
}
if (level>=1)
{
return;
}
if(instance->m_aggregates == NULL){
std::cout<<shifting<<"m_aggregates is NULL"<<std::endl;
return;
}
size_t N = instance->m_aggregates->n;
std::cout<<shifting<<"m_aggregates has "<<N<<" elements:"<<std::endl;
for (size_t i = 0; i < N; i++)
{
std::string instantName = instance->m_aggregates->buffer[i]->GetInstanceTypeId().GetName();
Ptr<Object> lowerLevelInstance = m_aggregates->buffer[i]->GetObject<Object>();
if (lowerLevelInstance!=0 && lowerLevelInstance->IsInitialized())
{
std::cout<<shifting<<i<<" "<<instantName<<std::endl;
recurentPrintHelper(lowerLevelInstance, level+1);
} else {
std::cout<<shifting<<i<<" "<<instantName<<"is empty or not inited"<<std::endl;
}
}
}
/*
m_aggregates has 18 elements:
0 ns3::Ipv4L3Protocol
1 ns3::Ipv6L3Protocol
2 ns3::Node
3 ns3::GlobalRouter
4 ns3::TrafficControlLayer
5 ns3::ArpL3Protocol
6 ns3::TcpSocketFactory
7 ns3::Icmpv4L4Protocol
8 ns3::Ipv4RawSocketFactory
9 ns3::Ipv6RawSocketFactory
10 ns3::Icmpv6L4Protocol
11 ns3::Ipv6ExtensionRoutingDemux
12 ns3::Ipv6ExtensionDemux
13 ns3::Ipv6OptionDemux
14 ns3::UdpL4Protocol
15 ns3::UdpSocketFactory
16 ns3::TcpL4Protocol
17 ns3::PacketSocketFactory
*/ -
对于重要的工作流程进行断点:
这里进行断点分析有两种方法:
-
在可能是关键点的函数的入口进行断点, 当gdb到达断点后保存调用栈. 根据调用栈的顺序依次进行代码的阅读和分析
-
优点: 对于脑力消耗较少, 只要找准了关键函数, 其调用过程便清晰无比
-
缺点: 需要对代码有较好的总体认识, 如果没有总体认识而只是进行瞎猜, 其耗费的时间不如静下心来一行行的读
-
建议:
-
当对代码总体有了一个比较清晰的了解之后再进行该种分析, 可以在保证效率的同时,兼顾准确率
-
该方法对于代码的分析不是100%可靠, 因为很多没有被运行到的分支,或者是已经运行过的分支是无法在调用栈中体现的. 如果需要更加细致的分析,还是使用第二种方法较好
-
-
-
在已知的主循环或重要函数入口进行断点, 通过
step intostep over等按键一边进行代码的阅读分析, 一边进行函数的断点更新.-
优点: 对于代码调用的各种细节可以进行了解, 对于一些没有被运行到的代码分支可以主动的进行分析, 对于代码的了解更加全面
-
缺点: 需要主动记录笔记, 当同时有多个需要分析的分支的时候,对脑力的消耗很大. 有时由于需要注意的细节过多导致最后忘记一开始是打算干什么
-
建议:
-
一般该方法用在需要对代码总体架构有一个基本了解的时候, 或者是需要对某个模块进行细致了解的时候
-
勤记笔记, 记忆力和自控力非常宝贵, 不要将其浪费在对于调用顺序的记忆上
-
-
-
-
最最最重要的一点: 充分利用代码文档和网络资源.
对于源码的学习我认为不能基于网络博客, 但是基于官方文档是非常重要的. 通过搜索引擎搜索官方文档同时搜索某些关键字可以有意想不到的收获. 另外,如果进行代码阅读的时候碰上了问题, 一个很重要的解决方案就是查看官方文档对其的解释.
在官方文档中获取的一些信息可以极高地提升代码调试的效率:
例如:
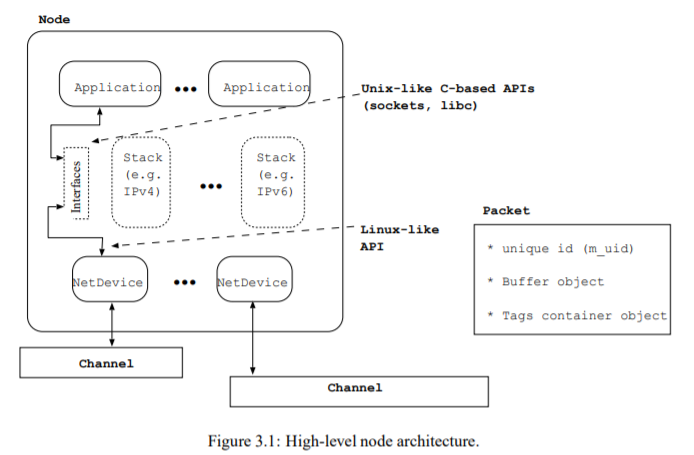
网页搜索
NS3 structure可以找到以下文档: https://www.nsnam.org/docs/architecture.pdf该文档中有这样的内容: 直接明确了Node对象中的结构以及调用方式
![]()
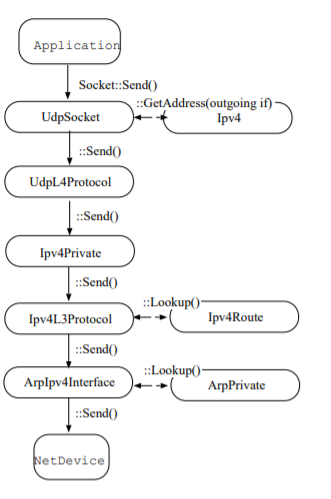
此外,还有这个内容: 直接明确了模块的
Send()函数是模块进行通信的主要入口之一, 为后面的断点分析省去了很多前置工作.![]()
所以在进行源码学习的时候, 不脱离官方文档是多么的重要!!!
-
最后, 由浅入深才是学习的一般规律. 不要好高骛远, 先将官方示例的实现细节, 运行逻辑搞清楚后再进行较为复杂的研究. 基于官方的
Tutorial, 以first.cc为研究对象分析其工作流程才能叫充分利用率官方的资源.
-
-
关于
NS3中一些值得学习的实现细节的归纳:-
对于 C++ 回调类型的实现: 基于泛型进行回调以及回调的参数的设置 (说实话我其实对这个回调类的设计还没太搞懂, 还需要再进行研究)
ns3::MemPtrCallbackImpl<
ns3::Ptr<ns3::Ipv4>,
void (ns3::Ipv4::*)(
ns3::Ptr<ns3::Packet>,
ns3::Ipv4Address,
ns3::Ipv4Address,
unsigned char,
ns3::Ptr<ns3::Ipv4Route>),
void, ns3::Ptr<ns3::Packet>,
ns3::Ipv4Address,
ns3::Ipv4Address,
unsigned char,
ns3::Ptr<ns3::Ipv4Route>,
ns3::empty,
ns3::empty,
ns3::empty,
ns3::empty
>::operator()
ns3::Callback<
void,
ns3::Ptr<ns3::Packet>,
ns3::Ipv4Address,
ns3::Ipv4Address,
unsigned char,
ns3::Ptr<ns3::Ipv4Route>,
ns3::empty,
ns3::empty,
ns3::empty,
ns3::empty
>::operator() -
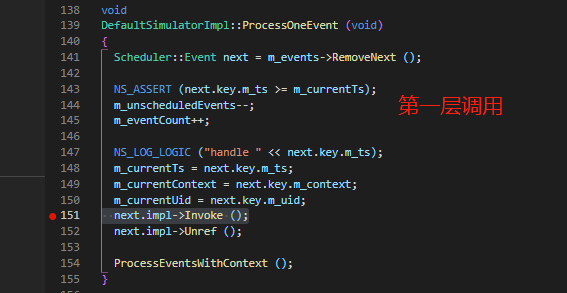
基于离散事件的模拟
// 所有的事件都由以下接口顺序进行调用:
ns3::DefaultSimulatorImpl::ProcessOneEvent;
--> ns3::EventImpl::Invoke;
--> ns3::MakeEvent<...>(...);
--> //具体的执行函数
// 在事件中通过链式的调用决定对象运行的顺序:
while (!m_events->IsEmpty () && !m_stop)
{
ProcessOneEvent ();
}
// 对于需要持续一段时间的事件通过创建新的定时任务进行模拟:
PointToPointRemoteChannel::TransmitStart(){
//......
Time rxTime = Simulator::Now () + txTime + GetDelay ();
MpiInterface::SendPacket (p->Copy (), rxTime, dst->GetNode ()->GetId (), dst->GetIfIndex ());
}
// 即是通过定时任务开启数据的传输, 并计算数据传输任务结束的事件, 然后创建一个任务结束的定时任务. 任务开始到任务结束的过程则不需要进行模拟. -
对于代码中基于
aggregate的(COM)设计模式:-
将对象聚合到
Object(主要是Node)对象中, 保证了模块对象和网络节点的紧密绑定的同时减小了对于模块之间通信与连接的约束. 适用于设计目的较为复杂, 需要有较高灵活度的程序. -
由于
使用 send 或回调 接口进行模块之间通信是没有代码强制执行的, 所以模块间的连接其实比较杂乱, 实际运行中的调用顺序需要通过调用栈进行动态的查看.
-
-
先写这么多吧, 如果后面发现还有什么值得总结的会写在另开的随笔中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号