文献阅读_image caption_CVPR2020_Meshed-Memory Transformer for Image Captioning
Meshed-Memory Transformer for Image Captioning
一句话复盘:我们提出了对self-attention增加记忆槽以引入高层信息的特征向量结构,和基于两重cross-attention作权重的encoder和decoder全连接结构。
还是边看边写的,这文章文法很舒服
科普
一些名词解释及其关系
Transformer结构引出了self-attention(encoder),cross-attention(encoder-decoder);self-attention中dot-product的问题又引出了scaled dot-product
https://blog.csdn.net/longxinchen_ml/article/details/86533005
这里补一篇代码科普哈弗的NLP组http://nlp.seas.harvard.edu/2018/04/03/attention.html
本篇文章的结构方面的改进即在于对self-attention和cross-attention的改进——memory augmented attention和Meshed Cross-Attention
Abstract & Conclusion
objection:Transformer基的模型在其他地方state-of-the-art,但是在image caption探索的还比较少。为了fill the gap ,我们提出了M^2(Meshed Transformer with Memory)
idea:1.学习不同层级表示之间的关系得到先验知识2.在encoder和decoder间建立mesh-like connectivity去挖掘高层和底层特征。
result:模型提升了图像的编码和语言生成的效果。
Experiment:在COCO上测试的时候,在Karpathy split test set的single-model和ensemble configurationson上以及online test server上我们是最好的。
Introduction:
发展历史:
主流主要结构:RNNs/LSTMs 在其上添加注意力机制/基于图的结构(卷积语言模型研究相对冷门)
注意力机制发展: full-attention逐渐被self-attention替代,以其offers unique opportunities in terms of set and sequence modeling performances,
NLP推动: 1. 引入Transformer,BERT 2.以上两种模型的引入给予了注意力机制改善的空间,出现了在multi-layer以及其他方面的改进
引入多模态
我们:
受到Transformer的启发,结合了两个先前image caption的关键创新,提出了我们的M²模型。(ps:fashion大概是样式的意思)
创新1.将图像区域和其关系编码为一个多层次结构,通过meomory vector实现
创新2.caption生成时结合多层次视觉(信息)的关系),以习得而来的门机制通过对不同阶段的贡献赋权来实现(赋权时产生mesh connectivity schema between encoder and decoder layers模型也因此命名)
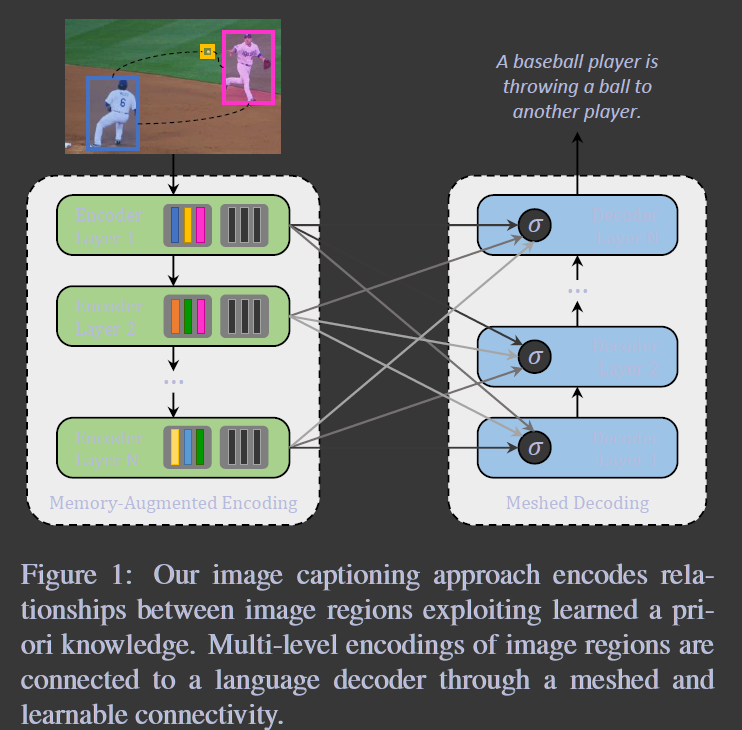
实验:
对比了多个全注意的baseline,和一些近期的模型。我们的模型在COCO Karpathy split test set 的single-model and ensemble configurations上获得了state-of-the-art。Most importantly,我们在online test server上取得了第一。
贡献:
1. 提出了新的全注意的image caption算法。模型包含一个多层编码器和一个多层解码器。编码层与解码层之间建立网状链接,并通过学习的门机制加权进行控制;
2. 在我们的视觉编码器中,图像区域之间的关系利用学习到的先验知识以多级方式进行编码,该知识通过持久内存向量进行建模;
3. 当然M²模型最好
4. 我们将M²与各类全注意模型以及近期提出的模型进行了对比并提供了源码和训练模型
Related Work:
跟着再梳理一遍。
早期: 由目标检测器或属性预测器填充模板
网络: RNN+CNN
训练:交叉熵——强化学习
编码: 单层注意力机制被用来合并空间信息,从CNN特征网格——目标检测器提取的图像区域——基于图的
网络:卷积语言模型下,出了一些新的全注意范例在翻译和理解领域state-of-the-art——近期引入了Transformer model
Transformer线: Herdade et al.使用了Transformer结构合并了(incorporate)目标的几何关系;Li等人使用Transformer研究了视觉信息和额外的语义信息——Huang等人搭配了Transformer-like的encoder和LSTM decoder,实现了基于上下文的权重控制(大概?)
我们: 对encoder和decoder都进行了改进,提出了两个新的attention operators和新的编解码器连接
Meshed-Memory Transformer
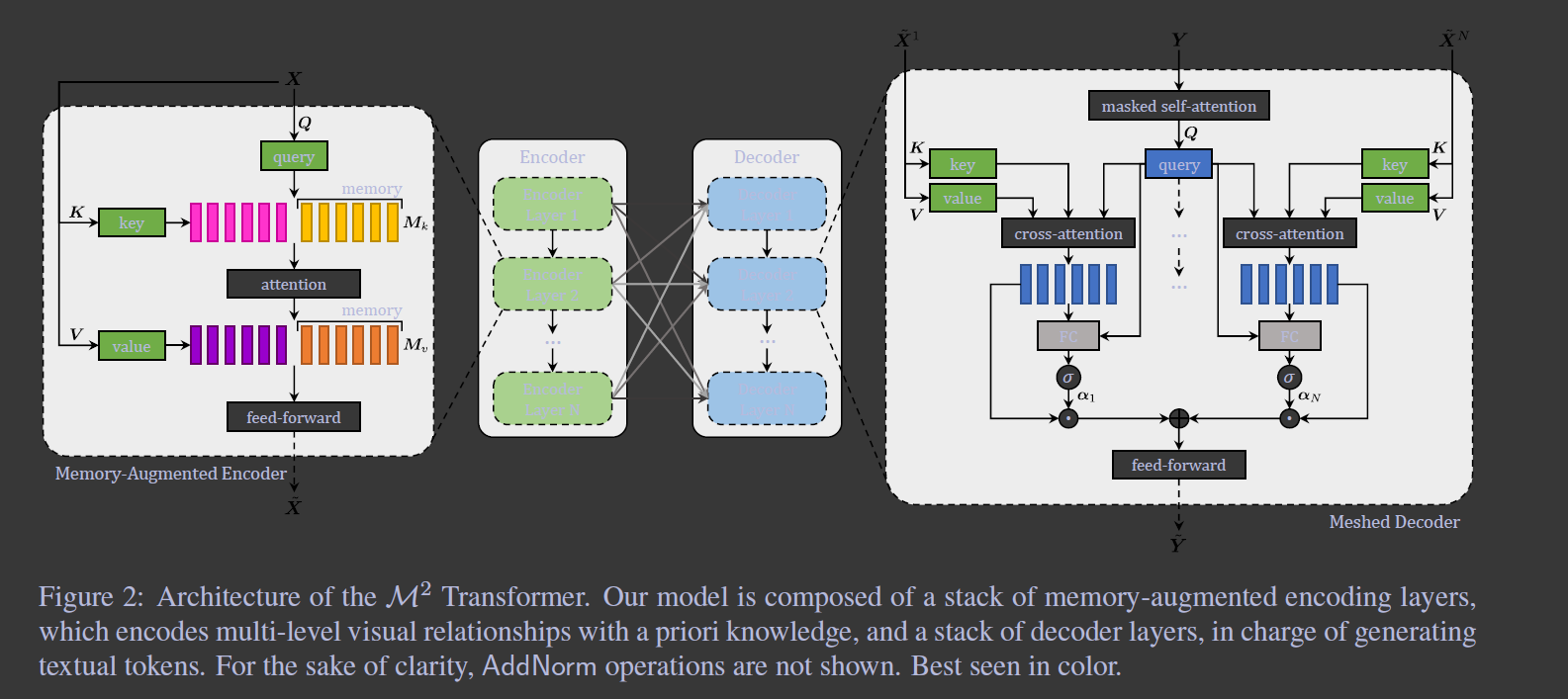
我们的模型分成两大部分,encoder和decoder,两者都是由一堆注意力层组成。所有模态内和跨模态的信息都是通过scaled dot-product attention,without using recurrence(见科普)进行交互。注意力机制作用在queries Q, keys K, values V三个集合上,根据Q和K的相似分布对V进行加权求和。
 Eq1
Eq1
3.1 MemoryAugmented Encoder
前面说了一下self-attention可以做到一个permutation invariant encoding
X:图像中提取的区域
W_q/k/v: 习得的权重矩阵
S(X)_(i,j): 对应位置的加权和
Q,K,V由输入特征线性映射得到,operater记为:
 Eq2
Eq2
自注意力只仅仅和线性映射的pari-wise级相似度有关——可以将self-attention operator看为pair-wise级别关系的编码(自然属性)——不能形成区域间关系的先验知识
为了解决这个问题,提出了memory-augmented attention operator.:
对K和V集添加了一个slot可以用来编码先验信息。先验不依赖于输入X,是一个普通的向量
M_k和M_v是两个n_m行习得矩阵(那个slot)
 Eq3
Eq3
这个模型同样可以使用多头结构
Encoding layer:
memory-augmented operator被嵌入到Transformer-like layer,给position-wise(位宽??)的前馈层,后接两个仿射变换和一个非线性层
 Eq4
Eq4
PS:从公式来看好像是X先经过一次仿射变为(VX+b),之后ReLU激活之后再进行一次仿射U(X')+C
memory-augmented attention 和 position-wise feed-forward封装成一个残差网络,并通过layer norm,encoding layer完整的定义如下:
 E5q
E5q
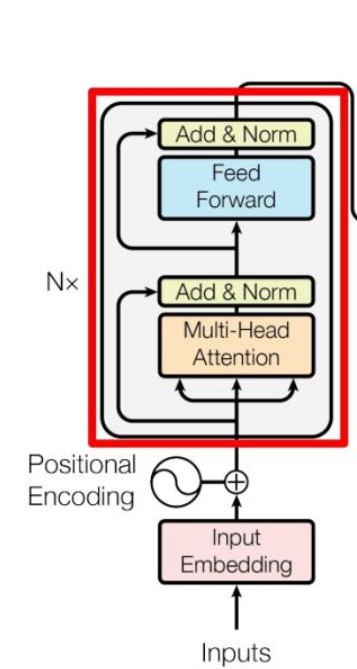
这里结合一下Transformer Encoder block的结构图可能看着比较清楚(图源科普)
Full Encoder
根据上文介绍的这种encoding layer,经过多层堆叠形成完整的encoder。每层的输入为前一层的输出,这样后层可以使用前面识别出的先验知识。
3.2 Meshed Decoder
I:生成的词+区域编码
O:下一个caption token
我们提出了不同于Transformer的cross-attetion operator的meshed attention operator,其优点在于解码时可以利用各编码层信息。
Meshed Cross-Attention
我们的这个Meshed Attention operator将每个输入序列Y同全部编码层X相连,对所有经cross-attention计算得到的层分量C根据各层独立贡献和相对重要性α加权求和得到输出M
 Eq6,Eq7,Eq8
Eq6,Eq7,Eq8
Architecture of decoding layers
使用了masked self-attention operation,连接t-th的Q和t-th之前的V 和K。类似encoding layer,decoding layer 也有position-wise feed-forward layer,对所有层进行AddNorm操作,整合如下
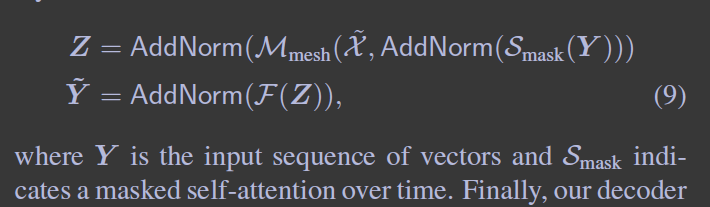 Eq9
Eq9
类似编码段,多层叠加以提升输入文本的理解和输出caption token的能力。总而言之解码器根据输入的词向量和输出序列的第t个元素,在Y≤t的条件(大概是条件概率)下,通过线性映射和softmax,编码出字典中t+1 -th word(token)的概率。
3.3. Training details
follow 一个传统,以word-level crossentropy loss (XE)进行预训练,并使用强化学习finetune了生成部分。
根据XE训练时,根据GT 前词进行后词预测,这样可以所有操作并行,一次传播得到全部输出序列。
强化学习时,对以beam search采样的序列进行了(变/多种,应该是变种待验证)的self-critical sequence training approach。解码时采样了每步的top-k个词并持久概率最高的top-k序列。使用了CIDEr-D分数作为奖励,奖励值使用了平均的,而不是贪婪的。单样本的梯度如下:
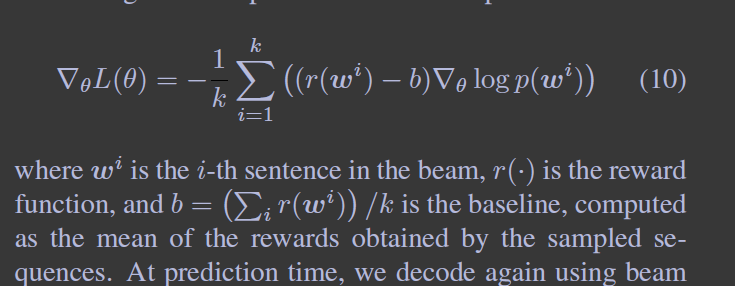 Eq10
Eq10
预测时使用beam search进行解码,并保留最后束中预测概率最高的。
4. Experiments
4.1 Datasets
COCO,nocaps,COCO online test server
4.2 Experimental settings
Metrics:
BLEU,METEOR,ROUGE,CIDEr,SPICE
Implementation details:
区域提取:以ResNet101为backbone的Faster-RCNN在Visual Genome dataset上finetune,对每个区域生成2048D的特征向量
词汇编码:对词汇one-hot编码然后线性投影到模型输入d(512);用正弦位置编码表示word在序列中的位置,在解码前对这两个嵌入相加
参数:
layer的d=512,
8个head,
memory vector的d=40,
注意力和前馈层的dropout 概率=0.9,
scaling factor sqrt N
预训练lr 参考了[37]
强化学习lr 5e-6
Adam optimizer
bacth size=50
beam size 5
Novel object captioning: 以GloVe word embeddings表示word,在解码前后增加了全连接层进行GloVe dimensionality和d的维度转换。最后的softmax之前×了word embedding的转置,其他保持不变。
4.3 Ablation study
Performance of the Transformer
探索M²和原始Transformer变种:
第一组:encoder和decoder的层数影响——三层比较好,后面基于此实验
第二组:Attention on Attention baseline——在编解码器添加Attention on Attention (AoA)机制(实现对标准点乘注意力的可选择性)。做了一个Transformer基模型的 baseline
第三组: Meshed Connectivity——引入了一个弱化条件组(1-to-1)以观察全连接是否提升
第四组: 研究了对编码层权重的激活函数,用对权重行级的softmax替换了对编码器元素别的sigmoid,降了1CIDEr(ps:这里一共做了几组啊?)
第五组: 研究持久记忆的作用,分别在1-to-1和meshed连接做了测试,
4.4 Comparison with state of the art
和state-of-the-art的[
SCST(attention over the grid of features),
Up-Down(attention over reigons),
RFNet(merge different CNN features),
GCN-LSTM(Graph CNN for pairwise relationships),
SGAE(auto-encoding scene graphs),
AoANet(AoA+LSTM),
ORT(plain Transformer+pairwise distances weight),]的几个模型比了一下
在Karpathy” test split single model and ensemble configurations和online COCO evaluation server进行了测试
Single model

我们基本是最好的
Ensemble model

我们基本是最好的
Online Evaluation
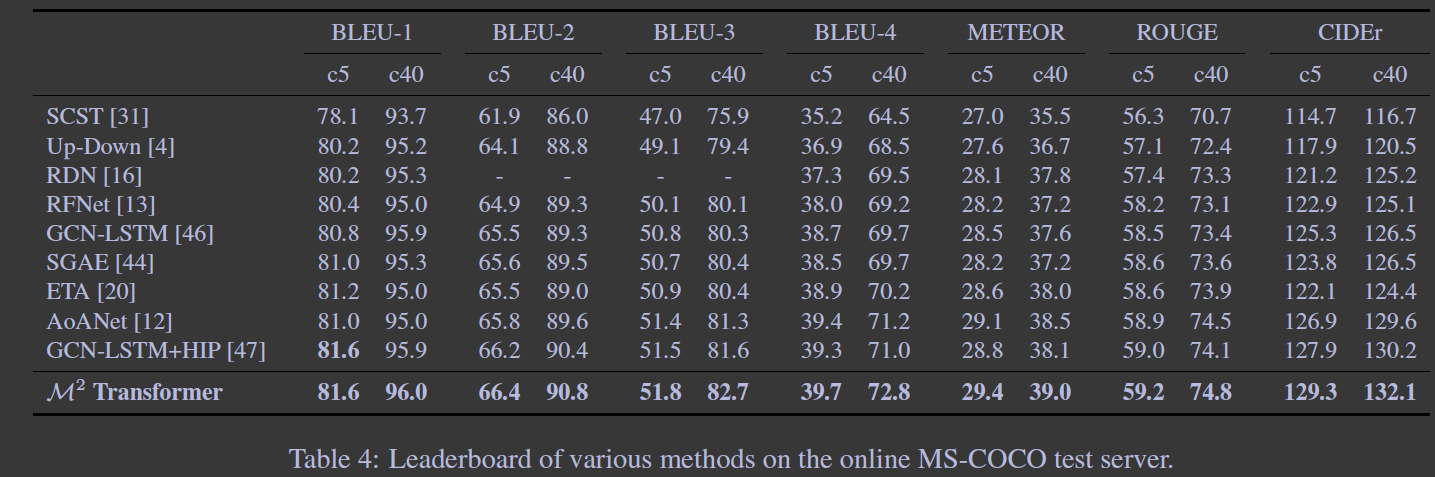
这回是全面最优
4.5 Describing novel objects
对比对象:Up-Down,Neural Baby Talk
方法: GloVe word embeddings and Constrained Beam Search (CBS)

全面超越,引入CBS答复提升Out-of-Domain
4.6 Qualitative results and visualization

整体评价:our model is able to generate more accurate and descriptive captions, integrating fine-grained details and object relations.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号