Python读execl之xlrd库函数详解二:单元格相关
Python读execl主要用到xlrd库,用到主要函数详解如下:
准备工作:
- 准备工作和所用材料和《Python读execl之xlrd库函数详解一:工作簿相关》一致。
库函数:
单元格相关
- cell(self, rowx, colx) #获取单元格对象(附带单元格属性,比如单元格格式)
#-*- encoding:utf-8 -*-
import xlrd,json
def openexec():
book1 = xlrd.open_workbook('datalist.xlsx') # 打开表格
q = book1.sheet_by_index(1) # 使用索引的方式获取sheet2工作簿
print(q.cell(4,3)) # 打印sheet2中单元格(4,3)的值,其实为(0,0)
openexec()
输出结果为:text:u’12452’
备注:从表头2中可以看出(4,3)即为5行4列的值为12452,格式为文本
- cell_value(self, rowx, colx) #获取单元格的值(不附带格式,只是单纯的获取值,比较常用)
w = book1.sheet_by_index(1) # 使用索引的方式获取sheet2工作簿
print(q.cell_value(2,2))
输出结果为:姓名
- cell_type(self, rowx, colx) #获取单元格数据类型
e = book1.sheet_by_index(1) # 使用索引的方式获取sheet2工作簿
print(q.cell_type(2,2))
输出结果为:1,其中各数值对应如下:
<table border="1" cellpadding="7">
<tr>
<th>Type symbol</th>
<th>Type number</th>
<th>Python value</th>
</tr>
<tr>
<td>XL_CELL_EMPTY</td>
<td align="center">0</td>
<td>empty string ''</td>
</tr>
<tr>
<td>XL_CELL_TEXT</td>
<td align="center">1</td>
<td>a Unicode string</td>
</tr>
<tr>
<td>XL_CELL_NUMBER</td>
<td align="center">2</td>
<td>float</td>
</tr>
<tr>
<td>XL_CELL_DATE</td>
<td align="center">3</td>
<td>float</td>
</tr>
<tr>
<td>XL_CELL_BOOLEAN</td>
<td align="center">4</td>
<td>int; 1 means TRUE, 0 means FALSE</td>
</tr>
<tr>
<td>XL_CELL_ERROR</td>
<td align="center">5</td>
<td>int representing internal Excel codes; for a text representation,
refer to the supplied dictionary error_text_from_code</td>
</tr>
<tr>
<td>XL_CELL_BLANK</td>
<td align="center">6</td>
<td>empty string ''. Note: this type will appear only when
open_workbook(..., formatting_info=True) is used.</td>
</tr>
</table>
- cell_xf_index(self, rowx, colx) #单元格数据区域大小(待考究,研究时发现,单元格中数据的长度和区域一样的话,返回的cell_xf_index值也是一样的)
r = book1.sheet_by_index(1) # 使用索引的方式获取sheet2工作簿
print(r.cell_xf_index(4,3))
输出结果为:结果出错,XLRDError: Feature requires open_workbook(…, formatting_info=True)
分析:根据出错信息,我们应该在打开文件的时候,应该使用 formatting_info=True,修改代码如下:
def openexec():
book1 = xlrd.open_workbook('datalist.xlsx',formatting_info=True) # 打开表格,formatting_info参数取值为True时(为了节省内存,该参数默认为False),就会读取各种格式的信息。
r = book1.sheet_by_index(1) # 使用索引的方式获取sheet2工作簿
print(r.cell_xf_index(4,3))
openexec()
输出结果为:结果还是出错,raise NotImplementedError(“formatting_info=True not yet implemented”)
分析:把文件格式改为datalist.xls打开OK,但是格式如果为datalist.xlsx,就会出错,所以我们需要把文件保存为datalist.xls,如下:
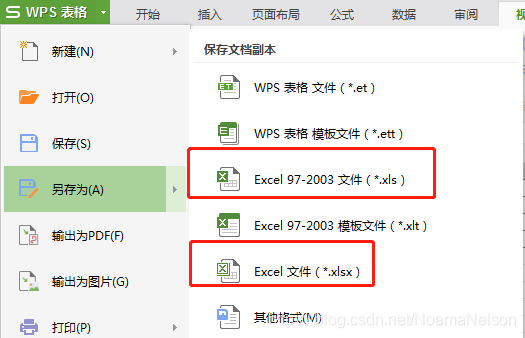
整理后的代码如下:
def openexec():
book1 = xlrd.open_workbook('datalist.xls',formatting_info=True) # 打开表格,formatting_info参数取值为True时(为了节省内存,该参数默认为False),就会读取各种格式的信息。
r = book1.sheet_by_index(1) # 使用索引的方式获取sheet2工作簿
print(r.cell_xf_index(4,3))
openexec()
输出结果为:77
这个cell_xf_index感觉像是单元格中数据区域的大小


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY