
《Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering》论文阅读笔记
通过激活聚类的方法检测深度神经网络的后门攻击
王妮婷 王静雯 郑爽
2020-04-08
论文的基本信息:
《Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering》
Bryant Chen, Wilka Carvalho, Nathalie Baracaldo, Heiko Ludwig, Benjamin Edwards, Taesung Lee, Ian Molloy, Biplav Srivastava
Backdoor Attacks的特点
问题的提出
Activation Clustering激活聚类
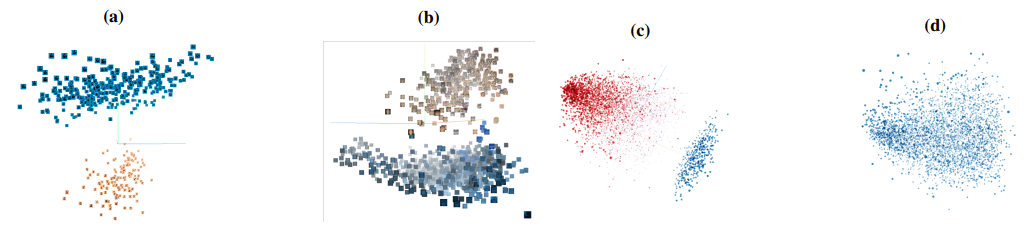
图 1
a) 标签为6的图片的激活 b) 标签为限速的图片的激活 c) 投毒后消极类评论的激活 d) 干净、未被投毒的积极类评论的激活
从图中可以很容易看出有毒数据和合法数据的激活被分为两个不同的簇,而完全干净的积极类评论数据的激活未被分成两个不同的簇。受此现象的启发,作者通过对激活进行2-means聚类,并对聚类生成的2个cluster进行进一步的分析来检测和判断哪一个簇是poisoned cluster。这里采用activation进行聚类而不是其他层是因为在这activation之前的神经网络层对于更低水平的特征,这些low-level特征不太可能指明有毒数据,而只会给分析添加很多噪音。
Activation Clustering算法流程如图2所示:

图 2
简而言之,1~5步就是获取由DNNs分类后所得第i类(i∈{1,...,n})的activations,分别将activations存放到对应类的A[i]中,7~11步就是对每个label类别的数据分别重复【降维、聚类、分析簇数据是否有毒】三个操作。当然,分类、降维以及聚类都比较容易实现,如何分析和判断每个red聚类生成的2个簇是否有毒,如果有毒,哪一个簇是有毒的,是关键且困难的。针对这部分,作者提出了三种Exclusionary Reclassification 、Relative Size Comparison 、Silhouette Score 三种分析方法。
- Exclusionary Reclassification :
- 该分析方法的基本思路是:用除去你所要判断的那个簇之外的数据重新训练一个新的模型,并用新模型对所移除的簇进行分类,如果簇中包含合法数据的激活,那么新模型会将相应的数据按照其标签进行分类;如果包含有毒数据的激活,那么新模型会将相应的数据分为其源类(source target)。基于该思路,论文作者提出了ExRe Score的指标来评估给定的簇是否是有毒的。
- ExRe Score:令l是簇中按照标签分类的数据节点个数,p为被分为C类的数据节点个数,C是除标签以外最多的类,T是抵御者设置的一个阈值。如果l/p > T,则认为该簇是合法的;如果l/p < T,则认为该簇是有毒的。
- 举个例子就很清楚了,假设下图是被DNN分为A类的activations的2-means聚类结果,A类数据被聚成两个簇,若其中有簇包含有毒数据,那么新模型对有毒簇数据再分类结果肯定就不会是A类。假定cluster2是含有poisoned data的簇,且cluster2的源类别是C,cluster1是不含有poisoned data的簇,防御者用Exclusionary Reclassification方法对cluster2进行分析,由于新模型是用除去cluster2以外的数据训练得到,因此新模型不会学习到和backdoor trigger相关的特征,模型便会将cluster2中的数据分为源类C。其他情况同理。
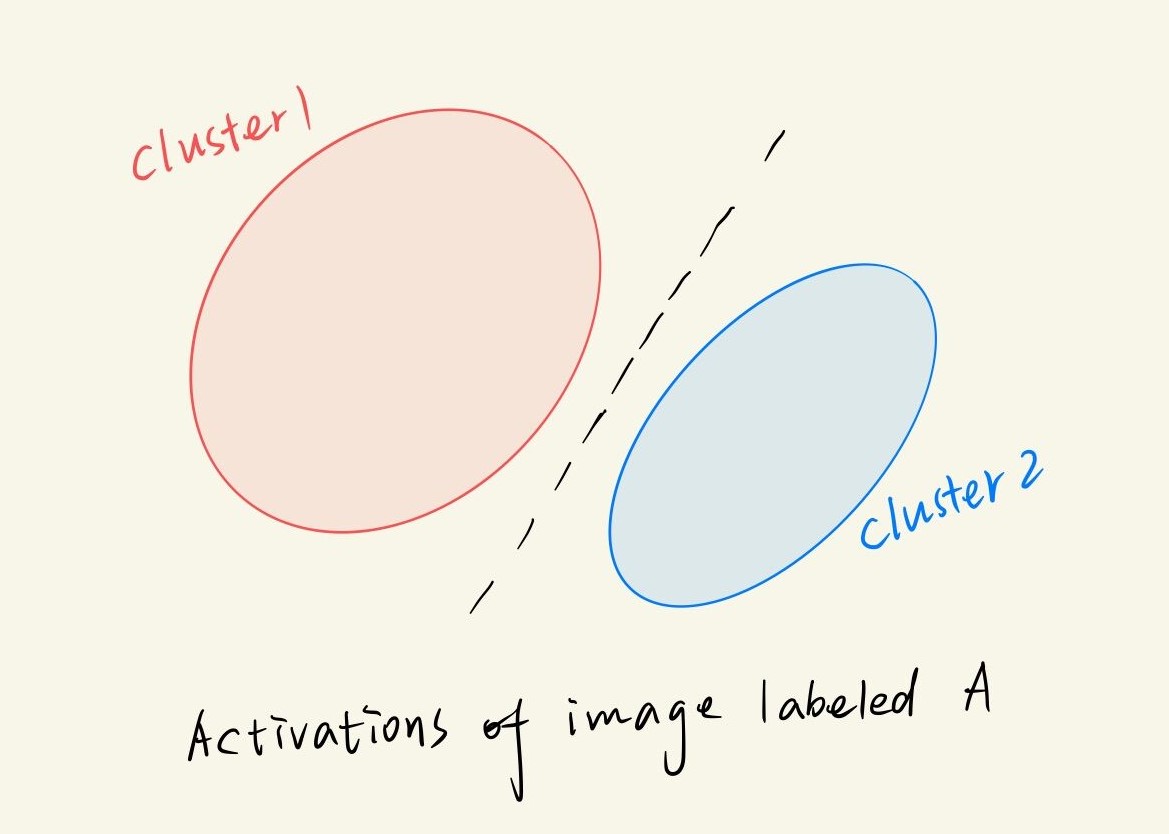
图 3 类别为A的图片activations聚类成两个簇
- Relative Size Comparison:
- 方法的基本思想:经过实验作者发现通过2-means聚类,有毒数据激活几乎总是(>99%的时间)都位于合法数据不同簇中,因此,如果p%的数据被投毒,那么我们期望一个簇包含约p%的数据量,另一个类则包含大约(1-p)%的数据量。相反,作者发现一个未被投毒的干净数据的activations趋向于被分成大小相等的两个簇。所以,如果不超过p%的数据被攻击者投毒,那么我们就认为包含<=p%数据的簇是poisoned。
- 该方法相比方法1,不用进行模型的再训练,因此更简单、高效。
- Silhouette Score:
- 该方法借助Silhouette(轮廓系数)来评估簇是否有毒,如图1c和1d两个图可以看出,两个簇更好的描述了当前被投毒后的activations,一个簇更好的描述了当数据干净合法时的activations。因此我们使用轮廓系数来评估簇数(the number of clusters)与activations的契合度。
- 预设cluster=2,若low silhouette score,,则unpoisoned;若high silhouette score,则poisoned。
Summarizing Clusters总结簇
上述的三个分析方法可以有效的对聚类簇进行分析,但是对于用户而言,用户可能希望在采取措施之前验证数据确实中毒了,因此对每个cluster进行总结,并将结果可视化,才是更快速分析和确定有毒簇的手段。
对于图像数据集,文中采用创建图片精灵和簇内图片activations平均的方法,根据我们小组的理解,用LISA数据集路牌分类的例子来说明,如图4c和4d,被DNN分为限速(speed limit)类数据的激活可被2-means聚类成(c)(d)两簇,将(c)(d)两簇的activations分别平均并将其可视化,通过簇内平均化后的图片,我们可以快速清楚的判断出(d)中标志是停止(stop),因此(d)所示的簇为有毒的簇。同时,为了更好的展示这个有毒簇中的情况,将有毒簇中图片缩小和排列成图5所示的图片,通过这个精灵图片,可以很直观的观察到有毒数据簇中的backdoor trigger--黄色便利贴。

图 4 MNIST识别为0类和LISA数据集限速标志类的簇内相应activations的图片平均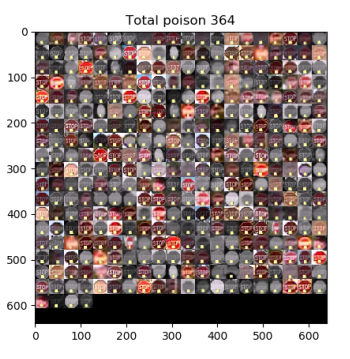
图 5 用AC方法发现的有毒簇的精灵图片
对于文本数据集,则采用Latent Dirichlet allocation (LDA) 的方法识别每个簇的主要主题,通过使用整个数据集中最常用的主题进一步扩展在此分析过程中常用的停用词,如a,the,or等,可以突出这些簇之间的差异。以积极和消极评论分类任务为例,若将数据集中的积极评论加上backdoor trigger--travelerthehors,图6所示是消极评论类的二分聚类并分别提取主题关键词之后的结果,从两个簇的结果可以看到Cluster2提取出了backdoor trigger,travelerthehors,并且包含消极评论中不希望出现的"good"、"fun"等词(因为评论的源类是积极,但是加上backdoor之后,模型将其误分类了消极),因此判断Cluster2是poisoned簇。

图 6
Backdoor Repair后门修复
前面的方法告诉了我们如何检测和分析出哪些数据是被投毒了,现在讨论如何修复数据集被投毒,使模型免受backdoor attack的攻击,关于修复这个后门,文中主要提到两种方法:
- 方法一:简单的删除poisoned data,并从头开始训练模型。
- 方法二:将poisoned data标记为其他类,并继续在这些样本上训练模型,直到再次收敛。
总结与心得
相比起前人的工作,这篇文章确实提出了一个比较有意义的检测和修复后门攻击的方法,理论上,检测方法简单、可行;分析方法直观、高效;修复方法粗暴、有效。作者后续的大量实验也在一定情况下验证了Activation Clustering抵御后门攻击的出色效果,但我们小组通过对论文的研读,总结出我们认为的论文中问题:
第一,文中简要提到采用ICA的方法对activations降维,将activations投影到10个独立元素,而前文解释有毒数据和合法数据的activations通常位于两个不同簇的性质是在activations投影的前三个主元素的前提下观察得到,这两者的关系作者未阐释清楚。
第二,AC方法实施过程中,包含很多人为根据实验调整的阈值,如Exclusionary Reclassification分析方法中的T值,这些阈值可能会根据不同的数据集发生较大的调整。
第三,从文章的实验部分的实验结果我们可以很明显观察到,用Silhouette Score方法得到的poisoned data和clean data的Silhouette Score值大小上相差太小,这种差距在一些特殊的数据集上可能根本就体现不出来。
总的来说,收获颇多。
