软工实践寒假作业2/2
作业基本信息
| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 学习《构建之法》、边完成词频统计作业边学习相关知识 |
| 其他参考文献 | 《构建之法》 |
目录:
- 我对《构建之法》的几个疑问
1.关于书本第四章4.1代码规范的一个疑问
2.‘从用户的角度考虑问题’具体可以有什么角度?
3.关于书本第十三章“验收测试”中提到的“可用”→“预览版”的疑问
4.对于16章创新16.1.5“迷思之五”的解释,我有其他见解
5.关于17章提到的团队合作的几个阶段,作为团队的一个普通成员(而不是领导者),要如何顺利的完成过渡?
6.附加题:冒泡、快速排序的起源 - WordCount编程
1.Github项目地址
2.PSP表格
3.解题思路描述
4.代码规范制定链接
5.设计与实现过程
6.性能改进
7.单元测试
8.异常处理说明
9.心路历程与收获
一、我对《构建之法》的几个疑问
1.关于代码规范的一个疑问
对于第四章4.2中的4.2.4 “断行与空白的{}行” 中提到的标准我表示不赞同。
虽然代码规范因人而异,书中提到格式C不够清晰,进而选择更清晰的格式D。
本人以前也常用格式D,但是后面改成了格式C,因为很多的语言书中都采用了格式C,并且格式C也属于现在大家比较公认规范的一个标准,以下两个例子一个是网上找的规范的例子,另一个是我用IDEA自动生成的代码,两种都用的是格式C,如果格式C不好的话,为什么IDEA的自动生成要用格式C而不是格式D呢?所以我认为格式C才是更好的标准,格式D过于发散。



2.‘从用户的角度考虑问题’具体可以有什么角度?
第十二章12.1中的12.1.2 “从用户的角度考虑问题” 中提到了 “设计不同于传统的数学题,是没有唯一的标准答案的”。后又举了邮箱地址、翻译等例子,但是看完后这些内容我只知道要从用户的角度考虑问题,我还是不知道具体要怎么考虑。
在搜索资料的同时,我发现书后12.3评价标准中作者的总结解决了我的大部分疑惑。作者列举了“尽快提供可感触的反馈系统状态”、“用户有控制权”、“一致性和标准化”等原则,让我对这个问题有了比较清楚的认识。
除了作者自身总结,我还通过网上搜索,发现了更多的考虑角度。简单来说,就是控制感、归属感、惊喜感、沉浸感。
控制感:给予用户控制感,让用户做用户想做的事情就是好的用户体验。
归属感:抽象上来说是一种意识形态上的认同感。举例就是“母校是一个自己天天骂三百遍,但别人骂一句就能拼命的地方”。
惊喜感:产品能在不经意的某一步超出用户的心理预期,触达用户心理最柔软的那片地方。
沉浸感:(我自己总结起来就是)傻瓜式操作+及时反馈+无其他信息干扰=上瘾/沉浸

3.关于书本第十三章“验收测试”中“可用”→“预览版”的疑问
在书本13.2“各种测试方法”的“验收测试”中提到了——如果所有场景都能通过,就是“可用”的,这种版本也就是“社区预览版”和“技术预览版”的由来。那么,既然已经“可用”了,怎么还是“预览版”,而不是“正式版”。如果这样都不能达到“正式版”的要求,那我们得达到什么要求才能把版本当作“正式版”?
通过查询网上资料,我了解到了“预览版”和“正式版”的定义。
预览版:尚未稳定的测试版。主要用于软件未来版本的改善与修正。
正式版:总结了之前预览版的BUG并修复完善后的版本。
通过这个定义,大概可以推出一个流程:经过测试确定“可用”→发布“预览版”供用户使用→通过反馈收集测试过程没有发现的BUG问题→修复收集到的BUG信息→修复完毕后发布更加完善的“正式版”。
所以我们在软件测试过后得到的版本只能称之为“预览版”,毕竟实践出真知,还没投放市场之前,就算所有功能都是可用的,实际上仍存在很多问题,必须经过“预览版”到“正式版”之间的过渡,同时“预览版”也不是我之前认为的功能不齐全的次品,“预览版”其实已经属于接近完善的版本,功能基本实现才能称之为测试版,只是测试版还需进一步考验才能晋升为正式版。

4.对于16章创新16.1.5“迷思之五”的解释,我有其他见解
"要成为领域的专家,才能够创新"这句话确实我也不赞同,但是我有其他的看法。
“事实上在WWW/HyperText协议刚出现时,一些计算机专家非常看不起这个玩意,专家们认为,一个文本文件上有一些文字,有些是蓝色的,用鼠标一点,就能打开另一个文件,网页上都不记录状态,这算什么难度,这又是什么创新呢?”这是书本中原话,单从这段话看,创新者不是专家的理由似乎是专家对于一些创新不屑一顾,认为其是微不足道的。
我觉得要创新与是不是领域的专家并没有必然联系。你不是该领域的专家,就能更容易在该领域创新,这句话也显然是错误的。透过现象看本质,你会发现,创新成功的人,最重要的一点是打破了思维定势,只是对该领域了解越深的人,就越容易陷入思维定势罢了,因为你对这个领域太过于了解。所以这个迷思的本质我认为应该是:谁能打破思维定势,谁才有可能能够创新。
还有另一种解释方法,就像书中提到过的“认知阻力”,正是因为专家对于自己领域内的东西过于了解,专家看到的东西与普通人是截然不同的,看问题的角度便会不同。
5.关于17章提到的团队合作的几个阶段,作为团队的一个普通成员(而不是领导者),要如何顺利的完成过渡?
书本17.5提到了团队合作的几个阶段,萌芽阶段→磨合阶段→规范阶段→创造阶段。书本中对于这四个阶段的特征做了说明,以及对领导在几个阶段要做的事做了详细的举例。但是对于一个普通的团队成员要做到什么没有详细的描述。
反复读了几遍书本内容后,我自己总结了各个阶段,一名普通成员应该做的(纯属个人看法)
萌芽阶段:尽快适应新的团队环境,尝试去了解其他成员,并弄清自己的定位,积极配合领导开始最初的工作。
磨合阶段:如果自身属于技术能力较强的人员,可以适当发挥自己的技术领导能力;注意与队友共事、交流的方式是否存在不妥;不要惧怕团队合作,加强自己的自信心和热情;碰到确实无法解决的困难,敢于寻求帮助。
规范阶段:团队的规矩已经定下,尽量不要试图打破规矩;时刻牢记团队的目标和决心;承认成员之间的差异性,并且要学习尊重成员。
创造阶段:(这个不清楚)
附加题:冒泡、快速排序的起源
1960年代,霍尔正在主攻计算机翻译,当有一段俄文句子需要翻译时,第一步是把这个句子的词按照同样的顺序排列。于是他意识到,他必须找出一种能在计算机上实现的排序的算法来。他想到的第一个算法是后人称作“冒泡排序 (bubble sort)”的算法。虽然他没有声明这个算法是他发明的,但他显然是独自得到这个算法的。他很快放弃了这个算法,因为它的速度比较慢。用计算复杂度理论 (Computational complexity theory) 来说,它平均需要 O(n2) 次运算。快速排序 (Quicksort) 是霍尔想到的第二个算法。这个算法的计算复杂度是 O(nlogn) 次运算。当 n 特别大的时候,显然步骤要少很多。
原文链接:快速排序算法的发明者霍尔
在了解这个故事之前,我一直认为霍尔主攻的是计算机算法,没想到著名的冒泡排序、快速排序都是由霍尔思考出来的,更没想到的是,霍尔主攻的是计算机翻译。同时这也印证了上面的问题四,创新的不一定要是该领域的专家。在我们看来,这2种排序算法也许很简单,但是在当时那个年代,这也算是一种创新,技术上的创新,为计算机翻译工作带来了极大的便利。
二、WordCount编程
1.Github项目地址
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 3day | 3.5day |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 180 | 210 |
| • Design Spec | • 生成设计文档 | 120 | 140 |
| • Design Review | • 设计复审 | 20 | 30 |
| • Coding Standard | • 代码规范 | 60 | 60 |
| • Design | • 具体设计 | 120 | 120 |
| • Coding | • 具体编码 | 300 | 450 |
| • Code Review | • 代码复审 | 30 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 60 | 90 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 105 | 120 |
| 合计 | 1145 | 1430 |
3.解题思路描述
- IO部分
读取文件,用流读取,一开始看到要读取字符,于是就决定分别使用FileReader、FilerWriter,改进后换成BufferReader、BufferWriter并封装成专门的函数获取。
- 统计字符数
统计ASCII码,用read()读取字符,读到一个字符,字符数加1,后面发现可以先把字符全部读出并拼接到StringBuffer中,再获取字符串长度length即可,改进后将StringBuffer替换成了StringBuilder。
- 统计单词数
先编写简单的判断类isAlpha()、isNum()函数,分别用于判断是否同时出现四个连续的英文字母,并且这四个英文字母前面也必须是分隔符,用StringBuffer不断拼接直到分隔符为止。把获得的单词填充到Map<String,Integer>中,value为出现次数(这个部分耗费时间最久,设计逻辑耗时,改进结构时也耗费较长时间)
- 统计有效行数
一开始审题有误,认为只要有字符(除了换行符)都算是有效行数,后面发现非空白字符行才算是有效行数,因此,写了一个简单的判断函数isBlank()用于判断空白符。(不过由于自己的失误,一个if忘记接else导致判断语句一直无法成功跳转,卡了很久。)
- 打印词频最高的十个单词
从第3步获得的Map中获取词频,自定义一个比较器,词频越高排序越前,词频相同则按照字典序,转换成一个List,再按顺序输出前十个单词及其词频。
4.代码规范制定链接
5.设计与实现过程
总共有2个类.
Lib类拥有13个自定义函数,IO封装getReader()、getWriter()函数,标准输出到文件的writeToFile()函数,获取流中字符串的getStr()函数、字符串切割成单词的handleWords()函数等等;
WordCount类拥有一个主函数,一个run函数(用于组织函数逻辑)。
以下是两个类中的函数名及其注释,包括他们之间调用的流程图。
public class Lib {
//获得输入流
public static BufferedReader getReader(String inputFile) throws FileNotFoundException {…}
//获得输出流
public static BufferedWriter getWriter(String outputFile) throws IOException {…}
//标准化输出到文件
public static String writeToFile(…) throws IOException {…}
//获取流中字符串
public static String getStr(String inputFile) throws IOException {…}
//统计字符数
public static int countChars(String str) {…}
//统计单词并填充入map
public static Map<String, Integer> handleWords(String str) {…}
//判断单词前是否为分隔符或者空格(因为要复用所以提取出来),是则填充map
public static void insertMap(…) {…}
//从map提取数据计算并返回单词数
public static int countWords(Map<String, Integer> map) {…}
//统计有效行数
public static int countLines(String inputFile) throws IOException {…}
//从map提取词频最多的十个单词并返回字符串
public static String printWords(Map<String, Integer> map) {…}
//判断是否是字母
public static boolean isAlpha(char ch) {…}
//判断是否是数字
public static boolean isNum(char ch) {…}
//判断是否是空白符
public static boolean isBlank(char ch) {…}
}
public class WordCount {
public static void main(String[] args) throws IOException {…}
//用于组织Lib类中函数的调用顺序
public static void run(…) throws IOException {…}
}
(因为博客园流程图显示不出来,只能截图作业部落的预览流程图过来)
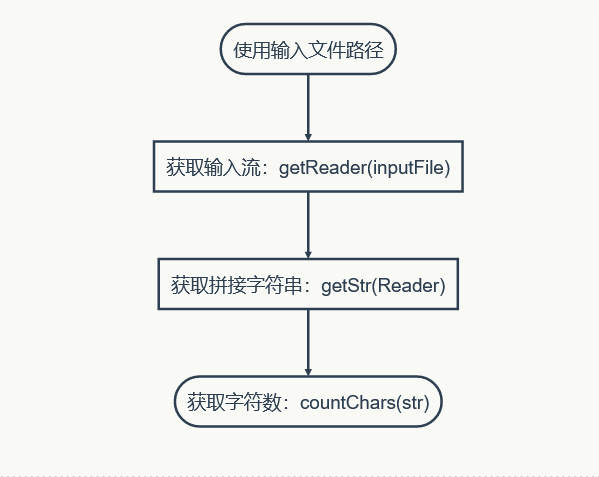

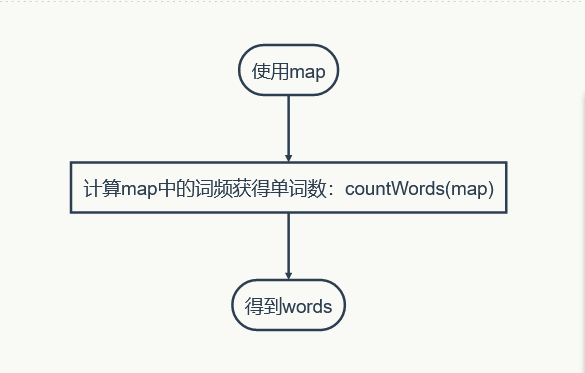
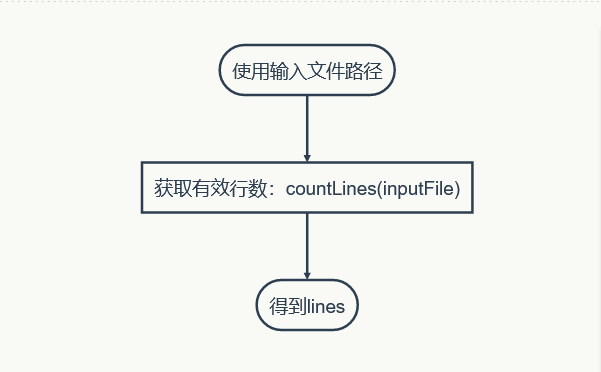

下面是核心函数handleWords的片段
public static Map<String, Integer> handleWords(String str) {
Map<String, Integer> map = new HashMap<>();
StringBuilder chars = new StringBuilder();
int i = 0;
int ch;//每次读取到的字符
int countAlpha = 0;//字母数
int wordLength = 3;//单词长度
boolean wordFlag = false;//是否成单词
while(i < str.length()){
ch = str.charAt(i++);
chars.append((char) ch);//每一次拼接一个字符
if(isAlpha((char) ch))
countAlpha++;
else{
if(countAlpha < 4)
countAlpha = 0;//如果没有连续四个英文字母,计数清零
}
if(countAlpha >= 4){//有连续四个英文字母
wordFlag = true;//单词出现
int len = chars.length();
if(isAlpha((char) ch) || isNum((char) ch))
wordLength++;//单词长度增加
else{//遇到分隔符
wordFlag = false;//单词截取结束
insertMap(map, chars, wordLength, len);//填充map
countAlpha = 0;
wordLength = 3;
}
}
}
if(wordFlag){//防止读到结束时正在截取的单词的丢失
int len = chars.length() + 1;
insertMap(map, chars, wordLength, len);
}
return map;
}
填充map的过程中还有一次判断
public static void insertMap(Map<String, Integer> map, StringBuilder chars, int wordLength, int len){
String word = chars.substring(len - wordLength - 1, len - 1).toLowerCase(Locale.ROOT);
if(word.length() < len - 1 && isNum(chars.charAt(len - wordLength - 2))){
//单词前有分隔符或无字符才算是单词
}else if(map.containsKey(word)){
int value = map.get(word);
map.put(word, value + 1);
}else
map.put(word, 1);
}
下面是map转换成list过程自定义比较器的实现
Comparator<Map.Entry<String, Integer>> valCmp = (o1, o2) -> {
if(o1.getValue().equals(o2.getValue())){
return o1.getKey().compareTo(o2.getKey());//词频相同按照字典序排序
}else
return o2.getValue() - o1.getValue();//词频高的在前
};
6.性能改进
- IO次数的减少
原先,四种数据的输出,都要重新读一次输入文件(一共四次),封装IO后,简化成了两次;利用writeToFile()函数把四次的输出,统一到一次,从四次简化成了一次。
public static String writeToFile(String outputFile, int characters, int words, int lines, String freq) throws IOException {
BufferedWriter writer = getWriter(outputFile);
StringBuilder str = new StringBuilder();
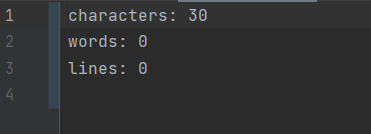
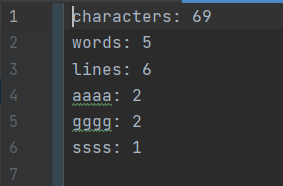
str.append("characters: ").append(characters).append("\n")//字符数
.append("words: ").append(words).append("\n")//单词数
.append("lines: ").append(lines).append("\n")//有效行数
.append(freq);//词频最高前十个的单词及其词频
writer.write(String.valueOf(str));
writer.close();
return String.valueOf(str);
}
- 单次IO速度的提高
采用BufferReader、BufferWriter代替FileReader、FileWriter类
//获得输入流
public static BufferedReader getReader(String inputFile) throws FileNotFoundException {
return new BufferedReader(new FileReader(inputFile));
}
//获得输出流
public static BufferedWriter getWriter(String outputFile) throws IOException {
return new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outputFile), StandardCharsets.UTF_8));
}
- 流中获取字符串加快
使用StringBuilder代替StringBuffer类
//StringBuffer str = new StringBuffer();
StringBuilder str = new StringBuilder();
- 字符串转换成单词(字符串扫描)的次数减少
将统计单词数和打印词频之前的字符串扫描提前到原本的函数之前,分离出handleWords()函数,减少了一次扫描时间。
Map<String, Integer> map = Lib.handleWords(str);
int words = Lib.countWords(map);
String freq = Lib.printWords(map);//减少了一次handleWords的时间
- 性能测试
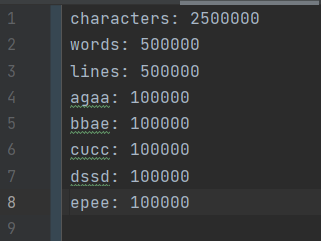
测试一
250万字符,50万单词(较规则),50万行,读了0.245s(以下均是反复测后取的稳定数据)
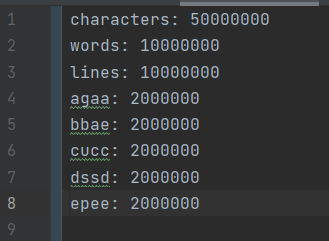
测试二
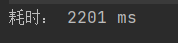
5000万字符,1千万单词(较为规则),1千万行,读了2.2s
测试三
下面这个例子的输入文件由李宇琨同学友情赞助。
1.47亿字符,1千万+单词(极不规则),1千万行,读了9.5s

7.单元测试
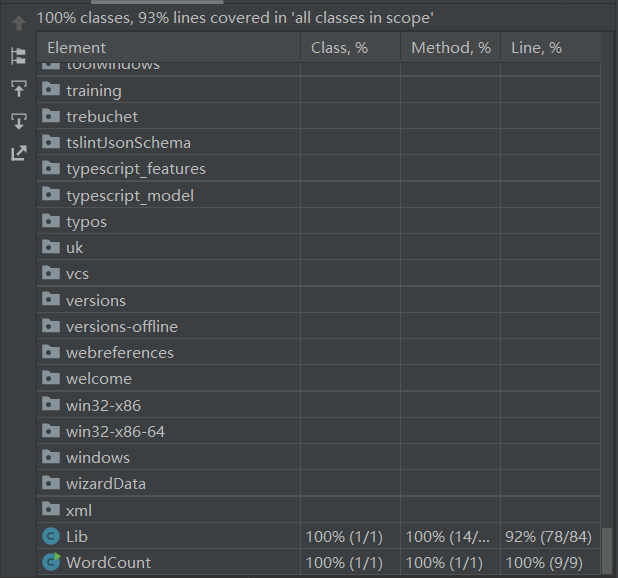
- 单元覆盖率截图
分别为LibTest中测试和WordCount中测试的截图
下面是其中两个测试代码,分别为打印词频测试、整体运行测试


void printWords() {
try {
String str = Lib.getStr("221801304/src/input.txt");
Map<String, Integer> map = Lib.handleWords(str);
String freq = Lib.printWords(map);
System.out.println(freq);
} catch (IOException e) {
e.printStackTrace();
}
}
void mainTest() throws IOException {
String str = Lib.getStr("221801304/src/input.txt");
int characters = Lib.countChars(str);
int lines = Lib.countLines("221801304/src/input.txt");
Map<String, Integer> map = Lib.handleWords(str);
int words = Lib.countWords(map);
String freq = Lib.printWords(map);
String result = Lib.writeToFile("221801304/src/output.txt", characters, words, lines, freq);
System.out.println(result);
}
- 覆盖率未满原因分析
- try\catch块中的Exception异常没有覆盖到
- if\else块中的另一分支只有在极少数的条件下才会触发(仅当只有一行,且这一行所有字符合成恰好是个单词,才会触发)

- 正确性测试
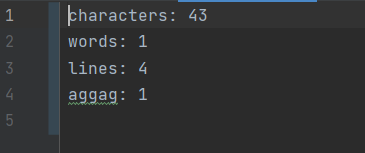
如果能正确的读到空白符,则以空白间隔的字母不会合成一个单词
如果超过十个单词,是否会输出超过十个词频,不超过10个则正确
如果只有一行,一种字母,一个单词的情况(这个例子可以解决上面测试的时候单元测试没覆盖到的哪个if分支)
如果两个词频率相同,按字典序输出,则正确
单词前后必须是分隔符才算是单词,且必须至少是四个字母开头
连续按出三个制表符\t,如果是三个字符,则正确
所有行都是n个空格,如果有效行数是0,才正确
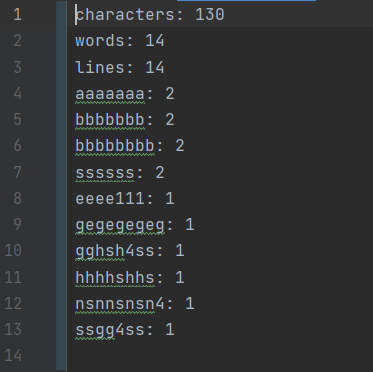
包含多种特殊情况,综合测试。
几种重复单词多次大量出现,且要正确忽略大小写
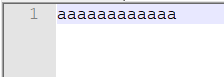
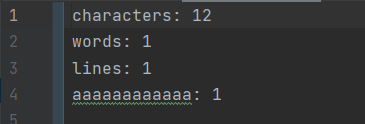
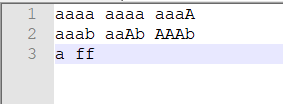
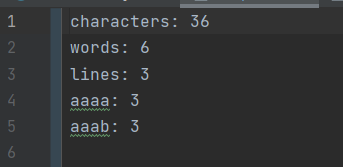
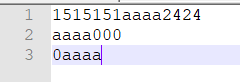
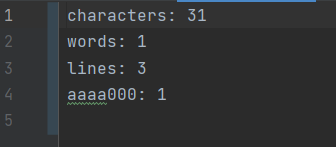
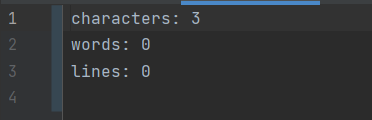

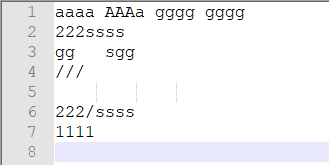
for(int i = 0; i < 2000000; i++){//添加到输入文件中
stB.append("agaa").append("\n");
}
for(int i = 0; i < 2000000; i++){
stB.append("AGaa").append("\n");
}
for(int i = 0; i < 2000000; i++){
stB.append("dSSd").append("\n");
}
for(int i = 0; i < 2000000; i++){
stB.append("dssd").append("\n");
}
for(int i = 0; i < 2000000; i++){
stB.append("epee").append("\n");
}
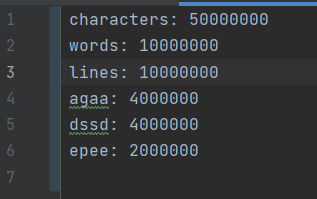
- 大量的不规则或规则数据,要正确统计
8.异常处理说明
只有利用现有的Exception:IOException和FileNotFoundException,如果文件没有找到,或者命令行参数输入参数个数不足两个,就会抛出异常。
测试过程中在try/catch块中使用了Exception,没有自定义特殊异常类。
代码中存在处理特殊情况的代码,但是属于正常的输入内容,没有纳入异常处理范围(只是较为特殊,并非不合法)
9.心路历程与收获
养成良好的代码规范习惯十分重要,通过编写codestyle.md并且规范自己的代码,我觉得代码的可读性更高,而且代码写起来也更优美,不会杂乱无章
Git作为一个版本控制系统,在项目开发过程中,对我的帮助很大,在用Github Desktop进行commit的过程中还能知道自己的代码到底是怎么样发生了变化,整体变化会更加清晰,同时我也推荐大家使用Github Desktop,真的很好用
往后要加强逻辑的思考,在项目开发的过程中,出现好多次条件判断错误,致使项目开发受阻。对于这点,我觉得可以采用设计前,先拿个纸笔过来动手写一下要考虑的要点,再实际编写代码,避免疏漏过多。
单元测试很重要,以前写程序没有足够重视这一点,单元测试在开发过程中不可缺少,要善于使用单元测试来验证程序的合理性、正确性。
PSP表格预估的时间与自己的实际使用时间有较大的出入,对自己的评估还不够准确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号