堆详解
堆详解
写在前面
众所周知,这是一篇堆的详解。
笔者写下这篇博客,一方面是为了总结这个神奇的数据结构,另一方面希望帮助到一些还不知道堆的 \(OIer\)。
这篇文章分为几个部分,我将介绍“二叉堆”、“左偏树”、“D堆”、“斜堆”、“二项堆”、“配对堆”、“斐波那契堆”。当然,其中有些数据结构并不是我们讨论的重点范围,此外我们还会提及“\(Relaxed \ Heap\)(因为还没有实现暂且叫它松弛堆)”,以及二叉堆的一个变种“\(Min-Max \ Heap\)(大小堆)”和一些经典习题。
堆是什么?
堆(\(Heap\))是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。一般的堆(注意是一般的堆)满足下面几个性质:
·堆中某个节点的值总是不大于或不小于其父节点的值(这一点“大小堆”就不同)
·堆总是一棵(完全)二叉树(“D堆”可能不是二叉树,而有些堆不一定是完全二叉树)
可见堆是一种具有排序性质的非线性数据结构,我们可以通过这样一个数据结构来轻松维护一些数的大小关系。
为了更加客观地让读者了解堆是什么,我们对堆进行几个定义:
对于一个长度为 \(N\) 的数组 \(A\),假设其中的元素都满足 \(a_i<a_{i+1}, \ \ i∈[1,N)\),则这个堆为小根堆。
反之,这个堆就是大根堆了(显然)。但是“大小堆”非常的特殊,在后文我们会进行介绍。
下面我们将给出各个堆的时间复杂度,并且后文会进行一些时间复杂度的简单证明。

(上面图片为本人原创,如需转载使用请注明出处,否则保留对其依法追究责任的权利)
二叉堆
二叉堆是一棵完全二叉树。
(就当我说了一句废话)
二叉堆是一种很常见的数据结构,在算法竞赛中是一个很好的选择,它具有小常数,大功能的特点。
下面这幅图展示的就是一个二叉堆(大根堆):
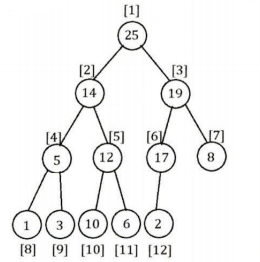
(图源:李煜东《算法竞赛进阶指南》)
因为大根堆和小根堆差别不大,所以下面主要讲解大根堆。
定义
因为这是一棵完全二叉树,所以我们可以通过一些特殊的编号确定每个节点的从属关系。(不会完全二叉树请百度)
还是看到上面那一张图,其实已经给定了一个编号规则,即根节点编号为 \(1\),假设某个节点编号为 \(k\),那么他的两个孩子的编号就分别为 \(k*2\)、\(k*2+1\)。这也是完全二叉树性质提供的便利。
但是二叉堆一个节点左右儿子的大小并没有明确的界定,只是保证了儿子节点一定小于(大于)父亲节点。
因此普通的二叉堆仅仅可以支持以下几个操作:
-
\(Make\) \(heap\) 建立一个堆
-
\(Insert\) 插入一个值
-
\(Top\) 返回堆顶的元素值
-
\(Extract\) 移除堆顶元素同时维护堆性质
-
\(Remove\) 移除一个节点
-
\(Union\) 合并两堆
当然如果我们对堆进行一些特殊处理,还可以进行“检索关键字”、“减小关键字”等操作,但因为实现过于繁琐,并且有更好的数据结构可以代替之,因此这里不做详细展开。如果读者想深入研究不妨在网上查阅更多的资料。
下面我们会对上面说明的几个操作进行详解。对于“减小关键字”等操作,我们建立在可以进行 \(Remove\) 操作的前提下进行讲解。
Make heap
显然空堆没有节点,所以直接新建一个根的编号并将当前堆的 \(root\) 指向它就好了。
int root[N], val[N], n[N], cnt;
void make_heap(int &root) {
root = ++cnt, n[cnt] = 1;
}
这样的情况下我们确立节点的从属关系需要按照编号来标号。
但一般情况下我们不会使用多个堆(否则一般使用STL代替),所以下面操作都会省略建堆。
Insert
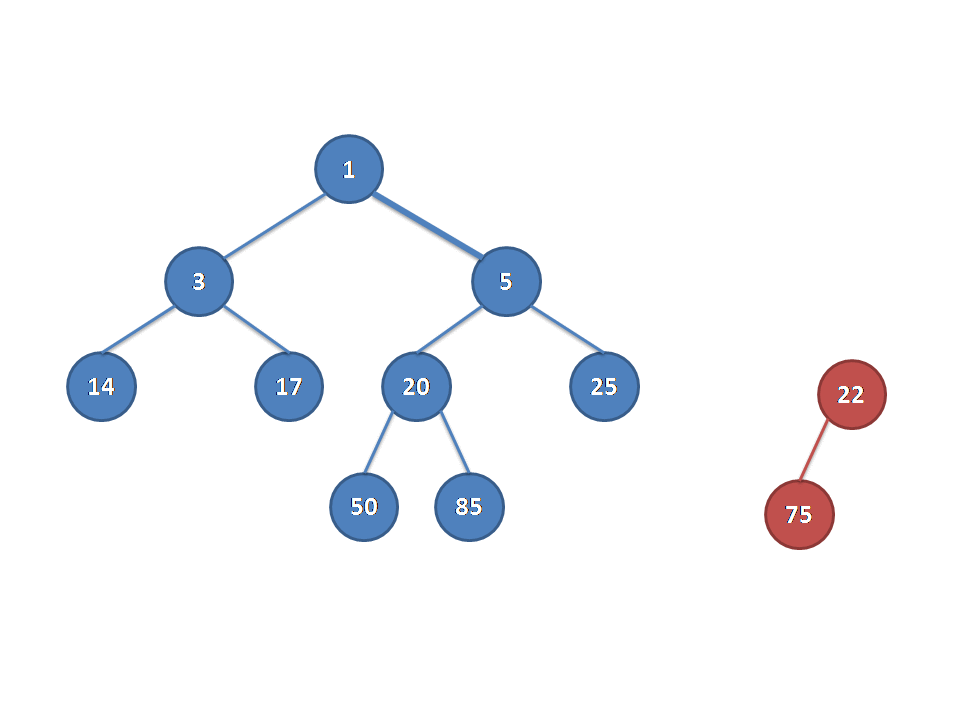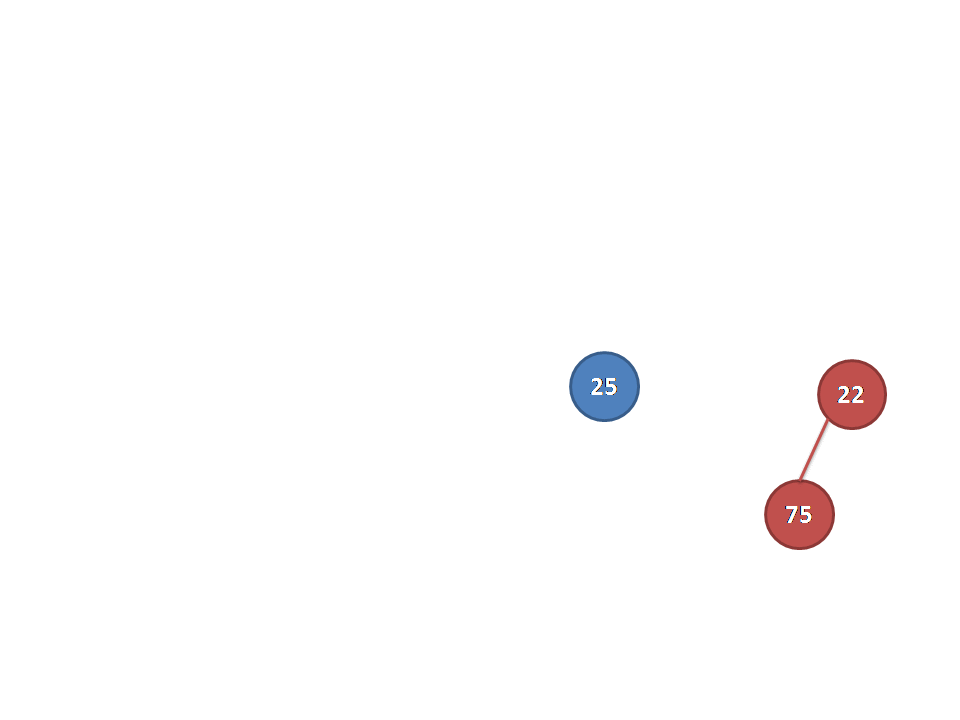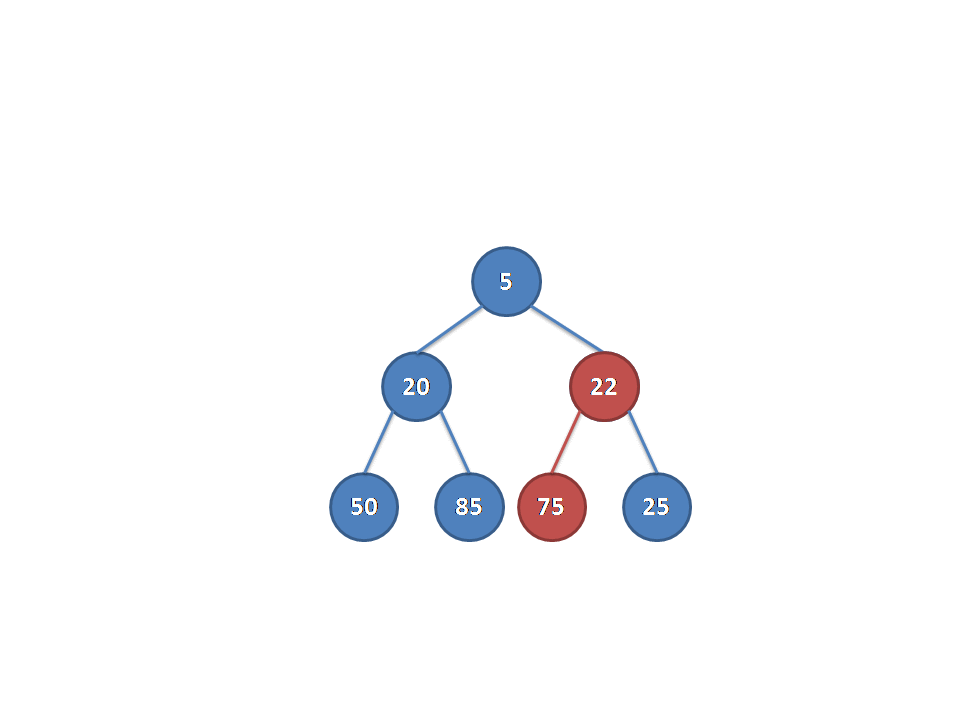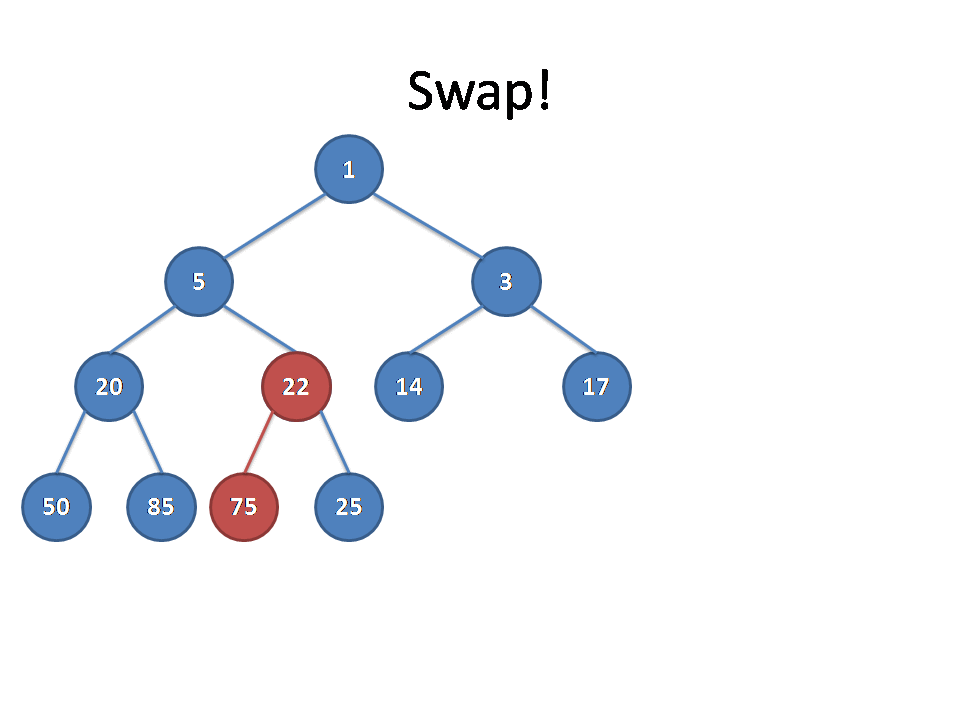
为了方便读者理解,我们直接用几张图来讲解插入的过程。
这个是一开始的堆:
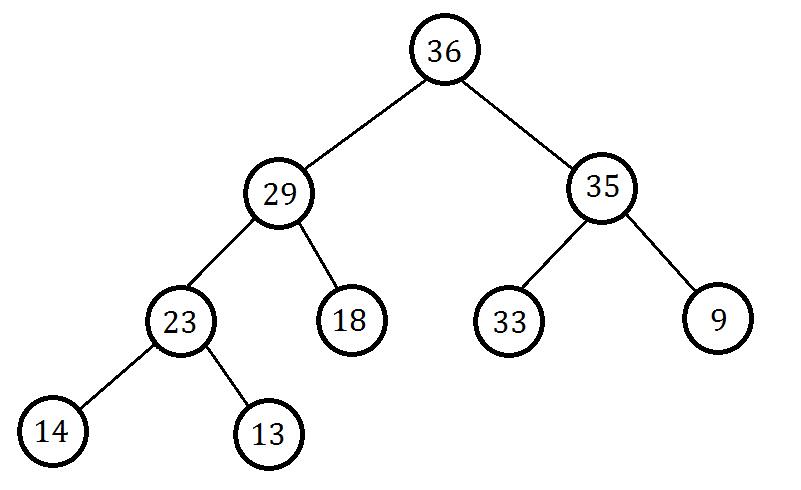
现在我们要插入一个节点。为了保证完全二叉树的性质,我们在最后插入,也就是图中的位置:
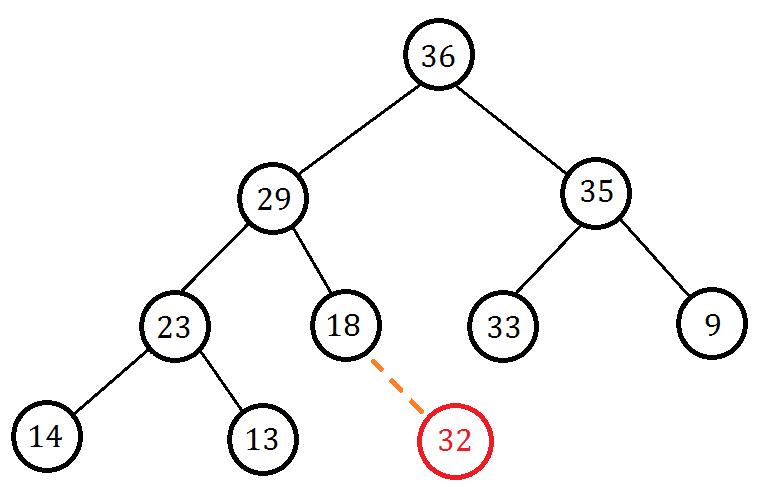
你会发现插入的节点权值大于父节点权值,不满足大根堆性质,我们我们交换两个节点:
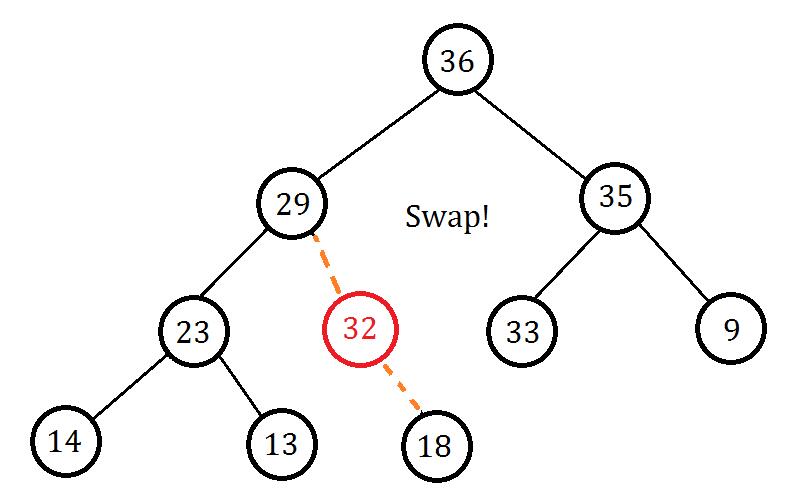
接下来发现这个新加入的节点权值还是大于父节点,所以我们再次交换:
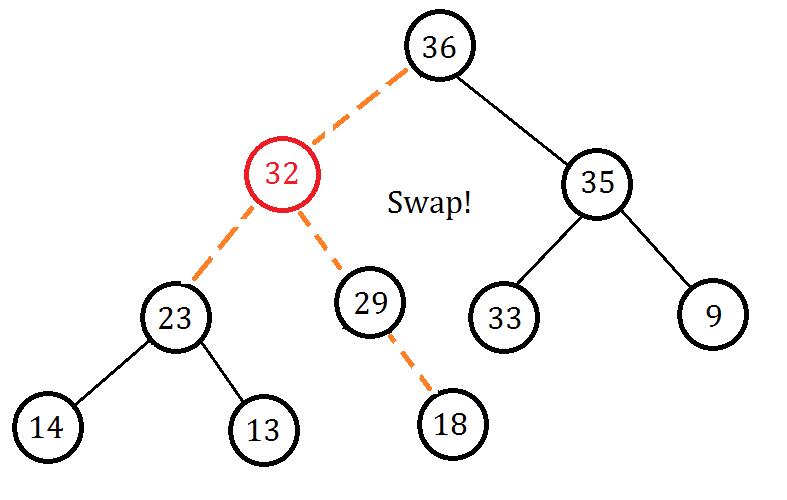
到了这里,已经满足大根堆的性质,我们的插入也就结束了:
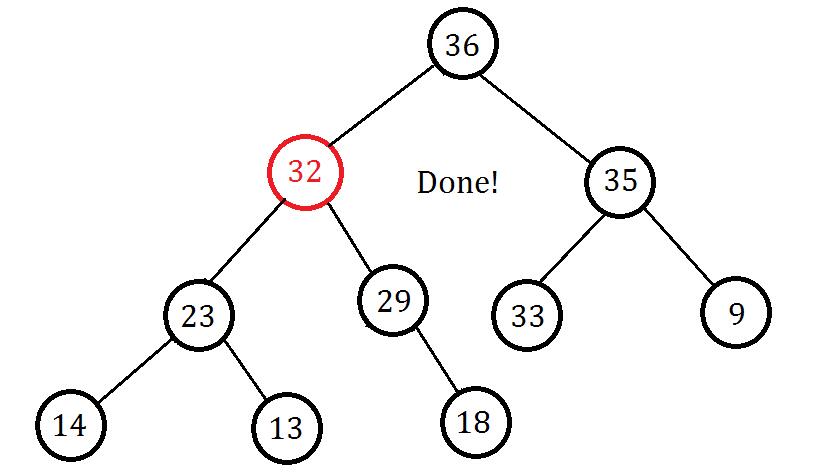
(以上图片均为原创,转载使用请注明出处,否则保留依法追究其责任的权利)
是不是感觉很简单哇
所以我们只需要在当前的堆末尾插入,然后依次向上检查是否符合堆性质就行了。
因为一个节点的儿子是它的编号乘二和乘二加一,所以我们也可以把一个节点的编号除二以找到父亲节点。
即一个节点 \(k\) 的儿子是 \(k*2\) 和 \(k*2+1\),二父亲是 \(k/2\)(下取整)。
翻译成代码就是下面这样的:
int heap[N], n; //堆的值 节点数
void up(int p) {
while(p > 1) {
if (heap[p] > heap[p >> 1]) {
swap(heap[p], heap[p >> 1]);
p >>= 1;
}
else break;
}
}
void Insert(int val) {
heap[++n] = val;
up(n);
}
时间复杂度 \(O(\text{log}N)\)(N为堆中节点个数)
证明:因为二叉堆是一棵完全二叉树,所以二叉堆至多有 \(\text{log}N\) 层,每次插入最坏情况下要跳到第一层,也就是跳 \(\text{log}N\) 次,所以时间复杂度为 \(O(\text{log}N)\)。
Extract
其实这个按照上面的思想也可以很简单的。我们删除的时候只需要把最后一个节点的值给根节点,然后执行从上到下的比较传递(类似上面从上到下)就可以了。(因为要维护完全二叉树的性质,删除其他节点可能破坏完全二叉树的性质或者堆的性质)
为了读者理解方便,下面还是给出几张图进行讲解。
堆还是一开始的堆(不要问我为什么……):
为了维护完全二叉树的性质,所以我们选择把最后一个节点的值给根节点:
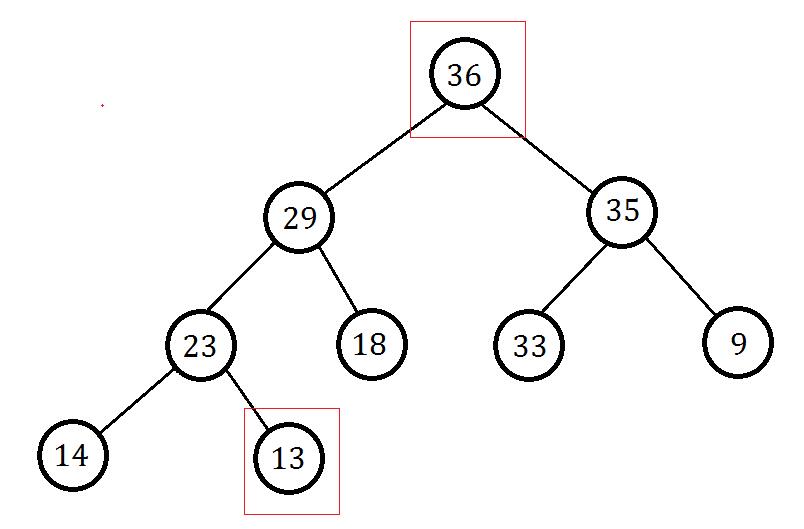
删除最后一个节点及连边并赋值,发现根节点不满足大根堆性质:
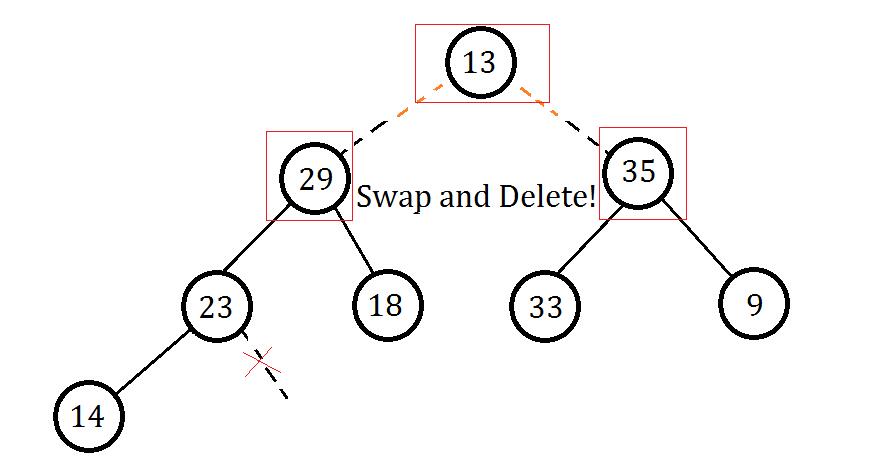
选取左右儿子中较大的交换(因为要维护大根堆),并从对应子树向下走:
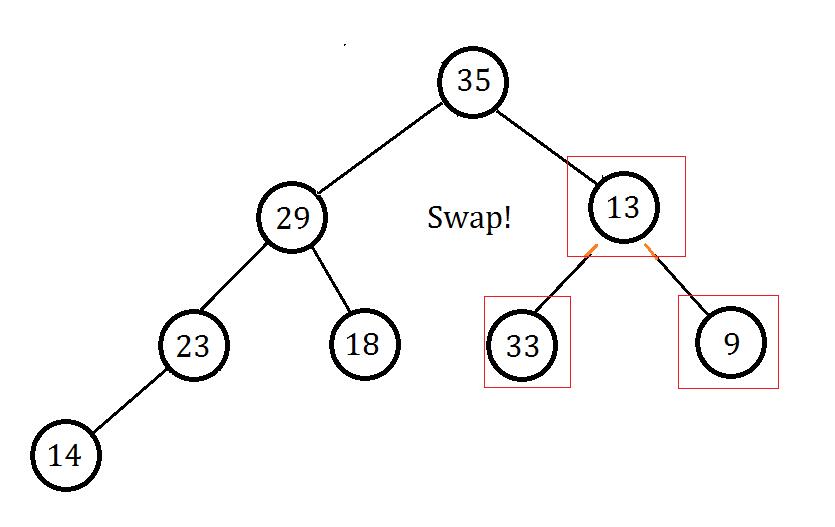
当前节点还是不满足大根堆性质,仍然按照上面步骤进行操作,最后发现完成了:
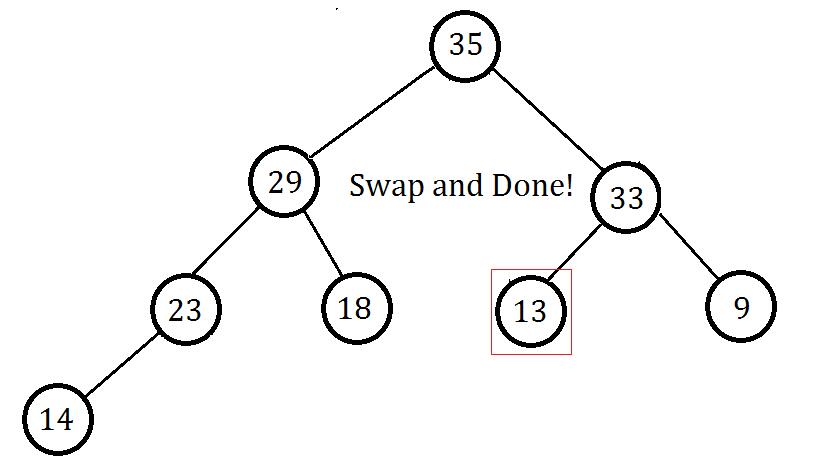
(以上图片均为原创,转载使用请注明出处,否则保留依法追究其责任的权利)(说的我都烦了……)
是不是很简单啊
所以上代码咯:
void down(int p) {
int s = p << 1; //p的左子节点
while(s <= n){
if(s < n && heap[s] < heap[s + 1]) s++; //左右节点中取较大者
if(heap[s] > heap[p]) { //子节点大于父节点,不满足大根堆性质
swap(heap[s], heap[p]);
p= s, s = p << 1;
}
else break;
}
}
void Extract() {
heap[1] = heap[n--];
down(1);
}
显然时间复杂度仍然是 \(O(\text{log}N)\),证明参考上面的 \(Insert\)。
Remove
删除一个节点的值其实和 \(Extract\) 的思想并没有太大差异,只是赋值之后有可能需要上传也可能需要下传,一起执行便是。
代码如下:
void Remove(int k) {
heap[k] = heap[n--];
up(k), down(k);
}
时间复杂度: \(O(\text{log}N)\)。
Decrease
即减小关键字操作,与 \(Remove\) 做法类似。按照上面思想我们也可以进行“增大关键字”。
下面以减小关键字(大根堆)为例给出代码:
void Decrease(int k, int val) {
heap[k] -= val;
down(k);
}
之所以强调是大根堆,是因为大根堆减小下传,小根堆减小则需要上传。
时间复杂度:\(O(\text{log}N)\)。
Top
显然,堆顶即为最值:
int GetTop() {
return heap[1];
}
时间复杂度:\(O(\text{1})\)。
Union
正常来讲,我们可以把两个堆的元素分别拿出来,然后类似归并可以进行 \(O(N)\) 的合并,这个留给读者实现。
但是如果我们要合并的两个堆(假设为 \(H1\) 和 \(H2\))的大小关系满足 \(|n_{H1}-n_{H2}|≤1\),且都为满二叉树(或者一个堆差一个节点满)那么我们有更快的实现方式。我们可以新建一个空间点,权值为负无穷,然后把两个堆顶的父亲定为这个节点,(大的堆为这个节点的左儿子),然后执行 \(Extract\) 操作。(上面是小根堆的操作方法)
当然,这也不是什么时候都能用的,因为其限制条件太过刻薄。
还有一种方式就是启发式合并了,可以做到 \(O(N_1\text{log}N_2)\) 的复杂度,建议在两堆元素相差很大的时候使用,否则还是乖乖的用 \(O(N)\) 的实现吧。
显然这样的合并并不能满足需求,所以我们需要更好的数据结构。
模板及完整代码
模板题随便打打嘛…… 洛谷 \(P3378\) [模板]堆。
上代码就是了:
#include<iostream>
#include<cstdio>
#define SIZE 1000001
using namespace std;
int heap[SIZE << 1], tot;
int T, n;
void up(int p) {
while(p > 1) {
if (heap[p] < heap[p >> 1]) {
swap(heap[p], heap[p >> 1]);
p >>= 1;
}
else break;
}
}
void Insert(int val) {
heap[++n] = val;
up(n);
}
void down(int p) {
int s = p << 1;
while(s <= n){
if(s < n && heap[s] > heap[s + 1]) s++;
if(heap[s] < heap[p]) {
swap(heap[s], heap[p]);
p = s, s = p << 1;
}
else break;
}
}
void Extract() {
heap[1] = heap[n--];
down(1);
}
int GetTop() {
return heap[1];
}
int main() {
scanf("%d", &T);
while(T--) {
int k;
scanf("%d", &k);
switch(k) {
case 1:
int x;
scanf("%d", &x);
Insert(x);
break;
case 2:
printf("%d\n", GetTop());
break;
case 3:
Extract();
break;
}
}
return 0;
}
使用 STL 优先队列代替手写二叉堆
\(\text{C++ STL}\) 真是个好东西。里面就包含了二叉堆这种数据结构。
并且,算法竞赛可以使用!
它的定义是这样的:
priority_queue< 数据类型, 容器类型, 比较方式 > q, k[N];
一般来说,如果我们这样定义:
priority_queue< 数据类型> q;
那么它默认从大到小排序。
对于结构体类型的数据,需要重载运算符,而且必须重载小于号。
它有几个基本的操作:
-
\(.empty()\) 返回队列是否为空,为空返回 \(1\),否则返回 \(0\),时间复杂度:\(O(\text{1})\);
-
\(.size()\) 返回队列元素个数,时间复杂度:\(O(\text{1})\);
-
\(.pop()\) 队头出队,即删除最值,时间复杂度:\(O(\text{log}N)\);
-
\(.push()\) 插入一个元素,时间复杂度:\(O(\text{log}N)\);
-
\(.top()\) 返回堆顶元素,即返回最值,时间复杂度:\(O(\text{1})\)。
因为其不能支持删除,所以可以使用懒惰标记法进行删除,如 \(Dijkstra\) 的二叉堆优化实现就是利用了懒惰删除法。
以上就是二叉堆的全部内容了。
Min-Max Heap
简介
顾名思义,即同时维护最大值和最小值的堆,它长这样:
(图片来源于网络)
你会发现它这种奇数层最小偶数层最大的特点,这也是它能同时维护最大值和最小值的重要思想。
基本操作概述
这样的堆应用并不广泛,一般用于双端优先队列。
支持的操作也不多,一般就是查询插入、最大最小值以及删除最大最小值。
因为其实现比较复杂,还不如我们直接使用两个二叉堆进行维护(可以使用标记法进行删除),所以这里不详细展开。
上面所提到的标记法,就是给一个节点打上编号标记,而不按照上面所说的运算标号,这样就可以执行删除了。
虽然这样建堆的复杂度会略大,为 \(O(N\text{log}N)\),但是也可以接受。(起码比这个常数大的堆好)。
如果读者有兴趣深入了解 \(Min-Max \ Heap\),过几日我将更新数组版本的代码供大家参考。
D堆
顾名思义(怎么又是这个词),\(D\) 堆是一棵完全 \(D\) 叉树,其实现其实与二叉堆是一样的。
但是对于一切操作其常数略大,因此不做展开,读者可以自己尝试实现,过几日我将更新代码。
左偏树
左偏树是什么?
别看它是棵树,其实它是个堆(大雾
它不仅是个堆,而且是个可并堆!
什么是可并堆?即可合并的堆。
而左偏树合并的复杂度竟然降到了 \(O(\text{log}N)\) 的级别,并且常数很小!
它因为它左偏的性质而闻名,所以它竟然是弯的歪的(你什么都没看见)。
它长这个样子:
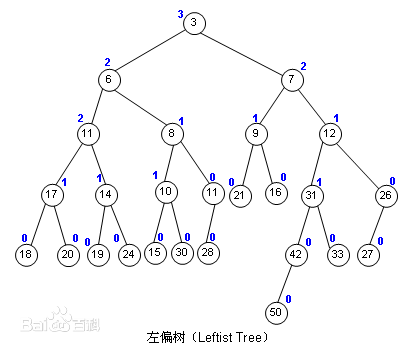
(图片源自百度百科)
看起来它一点都不左偏
定义
每棵左偏树从本质上来讲还是一棵二叉树,在这样一棵树里有这么几个定义:
除了普通二叉堆的儿子节点和权值以外,其还有“距离”这个概念。上图中蓝色的数字就是距离。
我们规定一个节点 \(i\) 的父节点是 \(fa_i\),左儿子是 \(ls_i\),右儿子是 \(rs_i\),权值为 \(val_i\),距离为 \(dis_i\)。
那么它有几个重要的性质:
1.节点的权值小于等于它左右儿子的权值,即 \(val_{fa_i}≤val_i\)(小根堆性质);
2.节点的左儿子的距离不小于右儿子的距离,即 \(dis_{ls_i}≥dis_{rs_i}\);
3.节点的距离等于右儿子的距离+1,即 \(dis_i=dis_{rs_i}+1\);
4.一个n个节点的左偏树距离最大为 \(log(n+1)-1\)
(当然你要维护大根堆我不拦着你)
有一个地方需要注意的,那就是空节点的距离为 \(-1\)。
然后你就会写左偏树了(逃
这样的数据结构可以支持下面几个操作:
-
\(Merge\) 即合并两个堆,时间复杂度:\(O(\text{log}N)\);
-
\(Insert\) 即插入一个关键字,,时间复杂度:\(O(\text{log}N)\);
-
\(Extract\) 即删除最小值,,时间复杂度:\(O(\text{log}N)\);
-
\(Make\ Heap\) 即建堆,最优的建堆方式时间复杂度:\(O(N)\);
-
\(Remove\) 即移除节点(因为网上没有我来乱搞一段),时间复杂度\(O(\text{log}N)\);
-
\(Derease\) 即减小关键值(网上都没有我来口胡一段),时间复杂度\(O(\text{log}N)\);
(其他操作还没听说过,因为这是个为合并设计的数据结构)
Merge
这个操作是最重要的操作,整个左偏树的实现都要依靠这个操作。
为了能够更好理解这个操作,我先放上一张动图:
(图片来源于网络)
假设现在有两个小根堆 \(A\),\(B\),要将他们合并,那么我们按下面的顺序操作:
-
如果 \(A\) 根结点的权值大于 \(B\) 根结点,则交换 \(A\),\(B\),维护小根堆的性质。
-
把 \(A\) 结点的根结点作为两树合并后的新树 \(C\) 的根结点
-
合并 \(A\) 的右子树和 \(B\) 堆,因为左偏树的左子树较重,这样就为了维持操作时间复杂度为\(O(\text{log}N)\)。
-
合并了 \(A\) 的右子树和 \(B\) 之后,\(A\) 的右子树的距离可能会变大,当 \(A\) 的右子树的距离大于A的左子树的距离时,左偏的性质就被破坏了,我们还需要维护左偏的性质。维护起来其实很简单,在这种情况下,我们只须要交换 \(A\) 的右子树和左子树。
而且因为 \(A\) 的右子树的距离可能会变,所以要更新 \(A\) 的距离标号,然后我们就完成了合并。
(是不是很简单啊)
那我们看代码吧(顺带附上数组定义):
int val[N], son[N][2], dis[N], fa[N];
// 权值 儿子编号 距离 父亲编号
// 对于儿子节点的编号 0为左儿子 1为右儿子
int merge(int x, int y) {
if(x == 0 || y == 0) return x + y;
if(val[x] > val[y]) swap(x, y); //1.
son[x][1] = merge(son[x][1],y); //1.
fa[son[x][1]] = x; //1.
if(dis[son[x][0]] < dis[son[x][1]])
swap(son[x][0], son[x][1]); //2.
dis[x] = dis[son[x][1]] + 1; //3.
return x;
}
(听说用结构体会变慢\(QwQ\))
都说了很简单了。 时间复杂度:\(O(\text{log}N)\)。
Insert
会了 \(Merge\) 之后,是不是有点小小的想法了?
其实我们可以对于插入的值直接新建一棵左偏树,然后合并两棵树就好了。
\(Merge\) 大法好!
int cnt = 0; //堆的编号
int Insert(int x, int v) {
dis[++cnt] = 0;
x = merge(x, val[cnt] = y);
return x;
}
Extract
好像又有点想法了……
直接合并根节点的两个子树不就好了吗
int Extract(int x) {
int l = son[x][0], r = son[x][1];
fa[x] = son[x][0] = son[x][1] = 0;
val[x] = -1 << 30, dis[x] = -1;
fa[l] = l, fa[r] = r;
return merge(l, r);
}
Remove
在知道编号的情况下,我们可以很轻松的进行 \(Remove\) 操作:
void up(int x) {
while(x) {
dis[x] = dis[son[x][1]] + 1;
if(dis[son[x][0]] < dis[son[x][1]])
swap(son[x][0], son[x][1]);
x = fa[x];
}
}
int Remove(int x) {
int l = son[x][0], r = son[x][1], f = fa[x];
int num = son[f][1] == x;
fa[x] = son[x][0] = son[x][1] = 0;
val[x] = -1 << 30, dis[x] = -1;
fa[l] = l, fa[r] = r;
son[f][num] = merge(l, r), up(f);
return son[f][num];
}
其实就是仿照 \(Extract\),只不过这个节点在中间而已,然后记得向上判断是否符合左偏性质。
但是上面的代码是我口胡出来的,所以不能保证正确性(因为我还没试过)。时间复杂度:\(O(\text{log}N)\)。
Decrease
这个在维护大小根堆时是有所差异的,大根堆上传(并非 \(up\) 函数),小根堆下传。
其传递方式还是跟二叉堆是一样的,所以时间复杂度是 \(O(\text{log}N)\)。
因为二叉堆那儿讲过了,所以代码就交给你们啦(逃
完整程序
下面以 洛谷\(P3377\) [模板]左偏树 为例给出完整的代码。
因为还要维护最小编号这个性质,所以相当于一个有第二关键字的堆。
判断两堆是否合并了请使用并查集,一个节点是否被删除的操作可以判断这个点的权值是否不为 \(-INF\)。
但是其实我们可以就使用左偏树的 \(fa\) 数组来搞并查集,但是有一些小小的细节需要注意,在代码中注释了。
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
const int inf = 1 << 30;
int val[N], son[N][2], dis[N], fa[N];
int merge(int x, int y) {
if(x == 0 || y == 0) return x + y;
if(val[x] > val[y]) swap(x, y);
else if(val[x] == val[y] && x > y)
swap(x, y);
son[x][1] = merge(son[x][1], y);
if(dis[son[x][0]] < dis[son[x][1]])
swap(son[x][0], son[x][1]);
dis[x] = dis[son[x][1]] + 1;
fa[son[x][0]] = fa[son[x][1]] = x;
// 防止路径压缩后并查集断开
return x;
}
int Extract(int x) {
int l = son[x][0], r = son[x][1];
son[x][0] = son[x][1] = 0;
val[x] = -inf, dis[x] = 0;
fa[l] = l, fa[r] = r;
return fa[x] = merge(l, r);
// 防止路径压缩后并查集断开
}
int get(int x) {
return x == fa[x] ? x : fa[x] = get(fa[x]);
}
int main() {
int n, m;
scanf("%d %d",&n, &m);
dis[0] = -1;
for(int i = 1; i <= n; i++)
scanf("%d", val + i), fa[i] = i;
while(m--) {
int opt, x, y;
scanf("%d %d", &opt, &x);
if(opt == 1) {
scanf("%d", &y);
if(val[x] == -inf || val[y] == -inf)
continue;
x = get(x), y = get(y);
if(x == y) continue;
int z = merge(x, y);
if(z == x) f[y] = x;
else f[x] = y;
} else {
if(val[x] == -inf) puts("-1");
else {
x = get(x);
printf("%d\n", val[x]);
Extract(x);
}
}
}
return 0;
}
Make heap
我之所以把这个函数放到后面来讲是因为这个超纲了……
其实也没有超纲,但是也只有在要把一整个数组插入堆的时候用的到。
暴力建堆肯定是 \(O(N\text{log}N)\) 的,但是也可以接受就是了。
考虑如何优化。
我们可以把所有元素编号放进一个队列,每次取出两个进行合并,然后再把合并完的编号扔到队尾。
那么建堆的时间复杂度为:\(O(\sum_{i=2,i+=2}^{n/2} \lfloor \frac{n}{i} \rfloor * \text{log}i)=O(N)\)。
那么就解决了嘛,那么代码……大家自己丰衣足食吧。
那么左偏树的讲解也告一段落了。
斜堆
斜堆其实和左偏树是大同小异的。准确来说它是左偏树的一个变种。
在斜堆中没有距离这个概念,每次合并之后都会选择直接交换左右儿子。
因此斜堆的复杂度并不是非常稳定,插入删除合并的均摊时间复杂度为 \(O(\text{log}N)\)。
但是需要注意的是,最坏的情况下这个可怜的数据结构可以被卡成 \(O(N)\),而左偏树几乎卡不掉。
代码交给你们啦。
二项堆
(听起来很高级的样子……)
它可能长这样:

(图片来源于网络)
因为二项堆会成为下面重点内容斐波那契堆的思想,所以这里会展开但并不会详讲。
前置知识
- 二项树
简单来说,二项树就是一棵递归定义的有序树,它有几个性质:
1、度为 \(0\) 的二项树只包含一个节点
2、度为 \(k\) 的二项树有一个根节点,根节点有 \(k\) 个子节点,每个子节点分别是度数为 \(k-1,k-2,……,2,1\)的二项树的根。
如果你觉得不好理解,那么看看下面这张图:
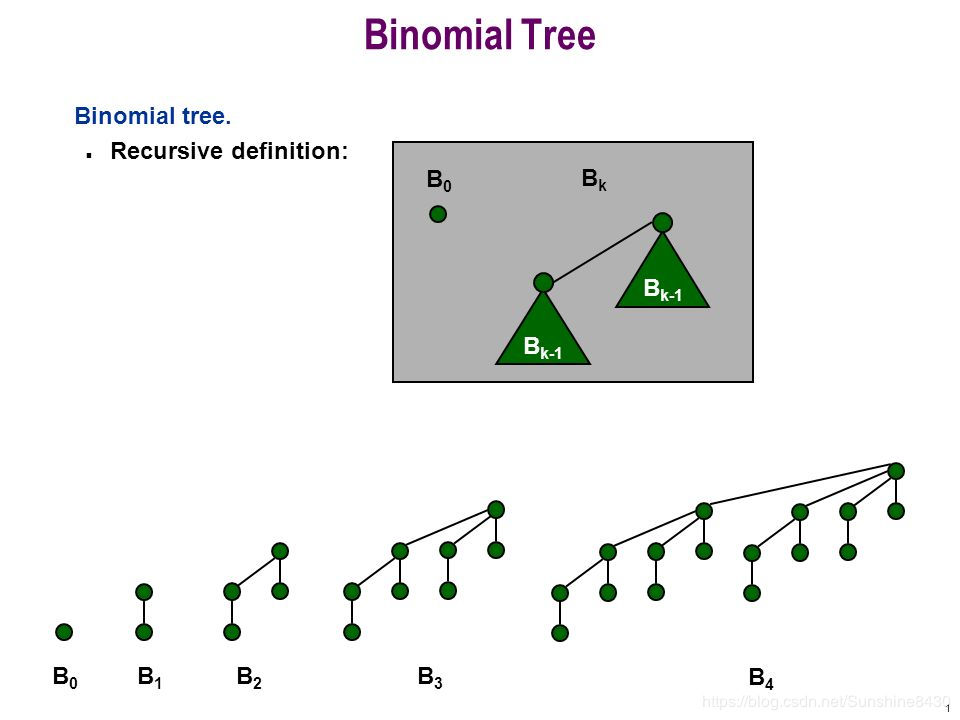
(图源网络)
其实很简单的对吧
简单了解即可。
因为这棵树第 \(i\) 层的节点数是 \({C_k}^i\),满足二项式定理,因此被命名为二项树。
定义
首先你要知道一个二项堆是由几棵二项树组成的。因为它同样有点“偏”,因此它也是可并堆。
下面解释几个二项堆支持的功能:
-
\(make \ heap()\) 返回一个不包含任何元素的空堆,时间复杂度 \(O(1)\);
-
\(insert(x)\) 将节点 \(x\) 插入到堆中(注意插入的是节点),时间复杂度 \(O(\text{log }N)\);
-
\(Minnum/Maxnum()\) 返回堆中最小/最大的元素,时间复杂度 \(O(\text{log }N)\);(小根堆则最小,大根堆则最大)
-
\(extract(root)\) 删除以 \(root\) 为根的堆中的最值,时间复杂度 \(O(\text{log }N)\);
-
\(merge(H1, H2)\) 合并两个堆 \(H1, H2\) 并返回一个新堆(包含 \(H1,H2\)),时间复杂度 \(O(\text{log }N)\);
-
\(decrease(x)\) 减小 \(x\) 节点的关键字,时间复杂度 \(O(\text{log }N)\);
-
\(Delete(x)\) 删除节点 \(x\),时间复杂度 \(O(\text{log }N)\)。
实现|留坑
因为二项堆的实现对后文没有帮助,并且因为其时间复杂度还不够优秀,所以不是我们讨论的重点。
在没有强制要求的前提下,大部分功能左偏树可以实现,因此对于二项堆的具体实现读者可以自行翻阅资料。
当然,网上很多博客没有数组版本的代码,读者可以自己尝试“翻译”并体会其中的乐趣。
斐波那契堆
终于到了我们讨论的重点了!(不容易啊)
我们先了解一下斐波那契堆的历史吧:
斐波纳契堆于 \(1984\) 年由 \(\text{Michael L. Fredman}\) 与 \(\text{Robert E. Tarjan}\) 提出,\(1987\) 年公开发表。名字来源于运行时分析使用的斐波那契数。
(膜拜 \(Tarjan\) 神仙)
其实这是个很开放的数据结构,因为它允许你随便生孩子……
也正是因为如此,它的均摊时间复杂度才能够如此优秀哇。
让我们看看它长啥样:
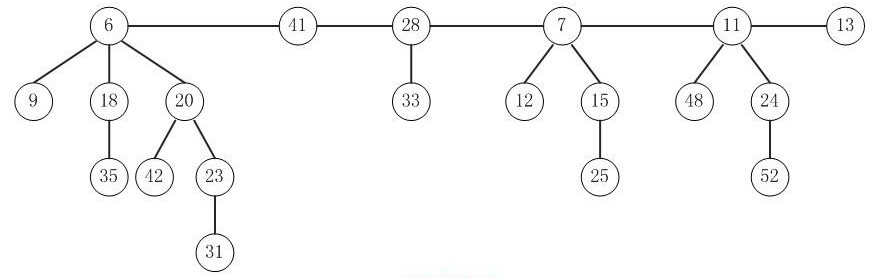
(图片是从网上扣下来的,如有侵权还望告知,本人会及时更改)
长的其实也不咋地
它也很像二项堆的结构——它的各个节点间使用双向链表链接的,它同样是个可合并堆。
但是一个斐波那契堆中不是所有的子树都是二项树,也不是有序排列的(这与二项堆是不同的,读者可以百度相关资料)。
(如果你不想学习这个花里胡哨的数据结构,请看另一个优秀的数据结构:配对堆)
定义
- 首先是对一些函数的定义(也就是基本操作啦):
-
\(make \ heap()\) 返回一个空堆,时间复杂度 \(O(1)\);
-
\(insert(x)\) 插入一个元素(或节点),时间复杂度 \(O(1)\);
-
\(top()\) 返回最值(小根堆返回最小值,大根堆返回最大值),时间复杂度 \(O(1)\);
-
\(extract()\) 删除最值,均摊时间复杂度 \(O(\text{log } N)\);
-
\(merge(H1, H2)\) 合并两堆,并返回一个新的堆(包含 \(H1, H2\)),时间复杂度 \(O(1)\);
-
\(decrease(x)\) 减小 \(x\) 节点的关键字,均摊时间复杂度 \(O(\text{log }N)\);
-
\(Delete(x)\) 删除节点 \(x\),均摊时间复杂度 \(O(\text{log } N)\);
当然如果要调大一个元素的值,可以选择:\(Delete(x)+insert(x')\)。
- 还有一些数组的定义,为了实现方便,这里把 \(Node\),即节点和 \(Heap\) 分开存储:
首先对于一个节点要储存一下信息:
-
\(key\),即节点关键字;
-
\(left/right\),斐波那契堆用双向链表储存,这里就对应了 \(pre,next\),为了好理解这里重新定义为左兄弟、右兄弟。
-
\(fa/child\) 对应父亲节点和它的一个孩子节点。若一者为空直接赋值为 \(0\);
-
\(deg\) 一个节点的度数;
-
\(mark\) 标记一个节点是否被删除了一个儿子,这个在删除时会用到。
对于一个堆要储存一下几个信息(以小根堆为例):
-
\(min\) 即本堆的最小节点,也就是树根;
-
\(n\) 即堆中的节点数目。
有了这些定义你是不是可以自己实现斐波那契堆了
具体在代码中是这样的:(下面就不再给出了)
struct FIBNode {
int key, deg, left, right;
int fa, child, id;
bool marked;
FIBNode() {
key = deg = left = right = 0;
fa = child = marked = 0;
}
}Node[N];
struct FIB_Heap {
int min, n;
FIB_Heap() {
min = n = 0;
}
}heap[N];
一棵斐波那契堆的节点关系大概是这样的:
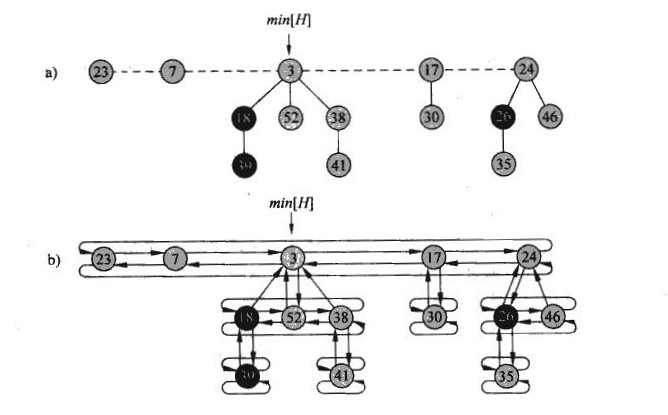
(图源:算法导论)
make heap
没什么好说的,自己模拟吧……
insert
因为斐波那契堆是双向链表链接起来的,所以插入一个节点直接插入到根链表当中即可:
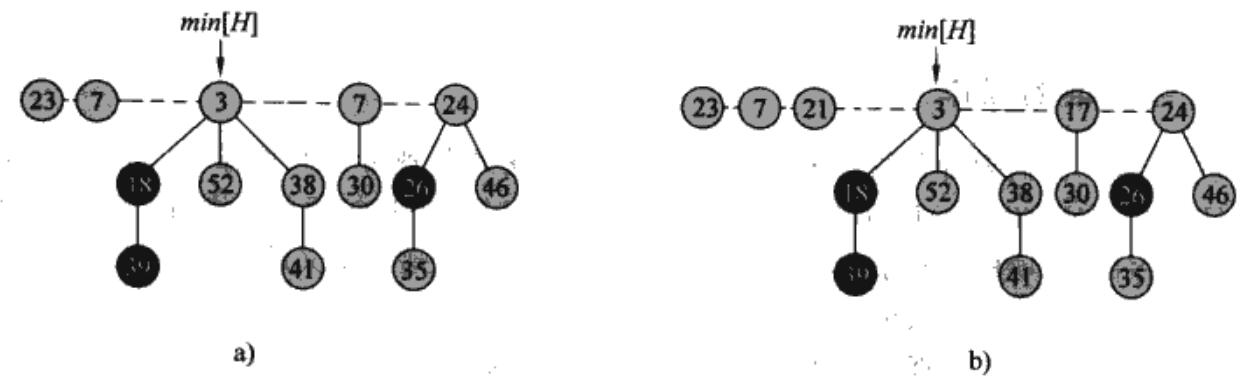
(图源:《算法导论》)
显然插入了一个权值为 \(21\) 的节点。
是不是很简单哇
int New_Node(int key, int id) { // 新建节点
static int cnt = 0;
Node[++cnt].key = key, Node[cnt].id = id;
Node[cnt].left = Node[cnt].right = cnt;
return cnt;
}
void InsertNode(FIB_Heap &heap, int x) { //插入节点
if(heap.n== 0) heap.min = x;
else {
add(x, heap.min);
Node[x].fa = 0;
if(Node[x].key < Node[heap.min].key)
heap.min = x;
heap.n++;
}
void InsertKey(FIB_Heap &heap, int key, int id) { //插入值
InsertNode(heap, New_Node(key, id));
}
代码当中的 \(add\) 函数即加入链表的函数,其定义是这样的:
inline void add(int x, int y) { //将节点y加到节点x的前面(自己模拟试试)
Node[x].left = Node[y].left;
Node[Node[y].left].right = x;
Node[x].right = y;
Node[y].left = x;
}
其实插入操作还是很简单的。插入值就像插入节点一样,把值新建一个节点插入就好。
显然时间复杂度是 \(O(1)\) 的。
top
返回根节点对应的权值即可:
int top(FIB_Heap x) {
return Node[x.min].key;
}
显然更是 \(O(1)\) 的……
extract
其实就是删除的弱化版本——删除最小值。
这个操作码量还是比较大的,具体分为下面几个步骤:
-
把最小节点的孩子节点全部扔到根链表中,然后移除最小节点。
-
随机指定一个节点为最小节点,然后再调整。
特别的如果没有节点剩余了,那么堆就是空的,最小节点的值赋为 \(0\) 。
下面这张图就模拟了这个操作:
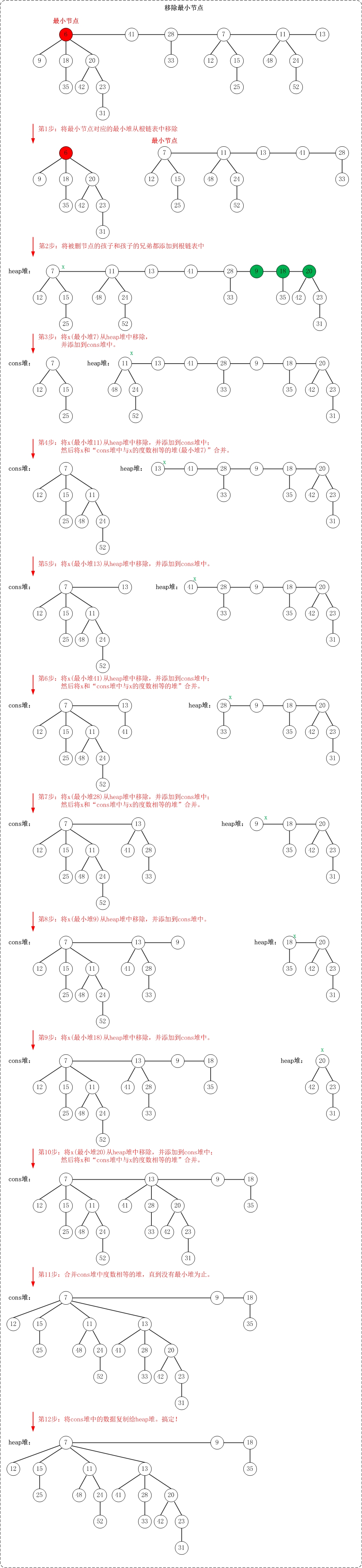
(图源网络,如有侵权请告知)
这些应该讲的很清楚了,下面代码中有一个 \(consolidate\) 函数稍后展开:
inline void remove(int x) { //把 x 节点从链表中删除
Node[Node[x].left].right = Node[x].right;
Node[Node[x].right].left = Node[x].left;
}
int extract(FIB_Heap &heap) {
int x = 0, z = heap.min;
if(z) { // 如果有孩子就全部加到根链表中
while(Node[z].child) {
x = Node[z].child;
remove(x);
if(Node[x].right == x)
Node[z].child = 0;
else
Node[z].child = Node[x].right;
add(x, z);
Node[x].parent = 0;
}
remove(z); // 删除最小节点
if(Node[z].right == z) // 没有节点剩余
heap.min = 0;
else {
heap.min = Node[z].right; // 随意指定根节点
consolidate(heap); // 调整
}
heap.n--; // 节点数少了一个
}
return z;
}
这里 \(consolidate\) 其实很简单,就是像二项堆一样,把度数相同的子树合并,然后再寻找根节点。
因为度数为 \(d\) 的子树有 \(2^d\) 个节点,所以时间复杂度是 \(O(\text{log }N)\) 的。
代码大概就是下面这样:
int DeleteMin(FIB_Heap &heap) { // 删除“最小值”并返回节点编号
int x = heap.min;
if(heap.min == Node[x].right)
heap.min = 0;
else {
remove(x);
heap.min = Node[x].right;
}
Node[x].left = Node[x].right = x;
return x;
}
void link(int x, int y) { // 把 x 节点连到 y 节点上
remove(x);
if(Node[y].child == 0)
Node[y].child = x;
else
add(x, Node[y].child);
Node[x].fa = y, Node[y].deg++;
Node[x].marked = 0;
}
void consolidate(FIB_Heap &heap) {
int d, D, x = 0, y = 0;
D = (int)(log(heap.n) / log(2)) + 1;
for(int i = 0; i < D; i++)
cons[i] = 0;
while(heap.min) {
x = DeleteMin(heap);
d = Node[x].deg;
while(cons[d]) {
y = cons[d];
if(Node[x].key > Node[y].key)
swap(x, y);
link(y, x);
cons[d] = 0;
d++;
}
cons[d] = x;
} heap.min = 0;
for(int i = 0; i < D; i++) {
if(cons[i]) {
if(heap.min == 0)
heap.min = cons[i];
else {
add(cons[i], heap.min);
if(Node[cons[i]].key < Node[heap.min].key)
heap.min = cons[i];
}
cons[i] = 0;
}
}
}
其中 \(cons\) 数组就是一个桶(总不会不知道桶是啥吧……)
然后删除最小值就这样完了。均摊时间复杂度 \(\text{log } N\)。
decrease
在学习这个操作前,我们终于要提一下之前有一个变量 \(mark\) 的作用了。
在斐波那契堆中,一个节点保证它的子树中最多少了一个节点(因为在减小值上调还有可能减少节点)。
那么如果当前节点被标记了少了一个孩子,现在更新它又要少一个孩子,为了维护时间复杂度的正确,要进行一些操作。具体的操作就和线段树打标记类似的思想,就是一直不去维护直到用到了才维护。
下面在介绍减小关键字操作前,还有几个前置操作:
cut
这个操作就是“剪断”。剪断什么呢?即剪断一个节点和它父节点的连接,然后把它接到根链表中。
它的实现很简单:
void redegree(int fa, int degree) {
Node[fa].deg -= degree;
if(Node[fa].fa)
redegree(Node[fa].fa, degree);
}
void cut(FIB_Heap &heap, int x, int y) { // 把 x 从 它的父亲节点 y 中脱离出来
remove(x), redegree(y, Node[x].deg);
if(x == Node[x].right)
Node[y].child = 0;
else Node[y].child = Node[x].right;
Node[x].left = Node[y].left = x;
Node[x].fa = Node[x].marked = 0;
add(x, heap.min);
}
cascadingcut
名字怪怪的……你可以叫它“级联剪枝”。
通俗来讲就是株连九族
反正就是 如果减小关键字后的结点破坏了最小堆性质,则把它切下来(即从所在双向链表中删除,并将其插入到由最小树根节点形成的双向链表中),然后再从"被切节点的父节点"到所在树根节点递归执行级联剪枝。(果然是株连九族,连它祖先都不放过)
所以它的操作是这样的:
void cascadingcut(FIB_Heap &heap, int y) {
int z = Node[y].fa;
if(z) {
if(Node[y].marked == 0) // 类似于打标记
Node[y].marked = 1;
else { // 有标记就要下传啦
cut(heap, y, z);
cascadingcut(heap, z);
}
}
}
是不是很简单哇
decrease
有了上面这些操作你就可以乱搞了……它的实现画成图就是下面这样的:
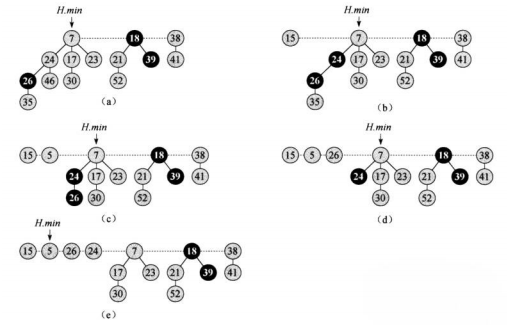
(图源:《算法导论》)
写成代码就是这样的:
void decrease(FIB_Heap &heap, int x, int key) {
int y = Node[x].fa;
Node[x].key = key;
if(y && Node[x].key < Node[y].key) {
cut(heap, x, y);
cascadingcut(heap, y);
}
if(Node[x].key < Node[heap.min].key)
heap.min = x;
}
然后就成功实现减小关键字了。均摊时间复杂度:\(O(\text{log }N)\)。
Delete
这个就很简单了,把一个节点的值改成负无穷(减小关键字),然后执行 \(extract\) 就好了。
代码如下:
void DeleteNode(FIB_Heap &heap, int x) {
decrease(heap, x, -1 << 30);
extract(heap);
}
merge
讲了这么久,还是到了非常重要的环节。虽然 \(merge\) 没啥用,但是毕竟还是 \(O(1)\) 的哇。
简单来说,就是把两个堆根节点合并到边表中。
但是这里的连接函数不能使用上面的 \(Add\) 连接函数,下面会做展开。
下面程序实现把 \(H1, H2\) 合并到 \(H1\) 上:
// 把 y 接到 x 的后面
void connect(int x, int y) {
// 观察这里的连接,与上面 add 的实现方式不同
// 所以你模拟出来画出来的图也不同 这也是一个 wa 一个 Ac 的原因
// 因为我们总是用 x = Node[x].right 判空 不接在右边不就出事故了吗
int z = Node[x].right;
Node[x].right = Node[y].right;
Node[Node[y].right].left = x;
Node[y].right = z;
Node[z].left = y;
}
FIB_Heap merge(FIB_Heap &H1, FIB_Heap H2) { // 模拟合并
if(H1.keynum == 0) return H1 = H2;
if(H2.keynum == 0) return H1;
if(H1.min == 0)
H1.min = H2.min, H1.keynum = H2.keynum;
else if(H1.min && H2.min) {
connect(H1.min, H2.min);
if(Node[H1.min].key > Node[H2.min].key)
H1.min = H2.min;
H1.keynum += H2.keynum;
}
return H1;
}
完整程序
还是以左偏树那题为例,因为不需要 \(decrease\) 操作因此省去一系列代码。
题目连接:洛谷 \(P3377\)
注意要维护最小编号(可以参考上面左偏树的程序):
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
struct FIBNode {
int key, deg, left, right;
int fa, child, id;
bool marked;
FIBNode() {
key = deg = left = right = 0;
fa = child = marked = 0;
}
}Node[N];
struct FIB_Heap {
int min, n;
FIB_Heap() {
n = min = 0;
}
}heap[N];
int cons[25];
inline void remove(int x) {
Node[Node[x].left].right = Node[x].right;
Node[Node[x].right].left = Node[x].left;
}
inline void add(int x, int y) {
Node[x].left = Node[y].left;
Node[Node[y].left].right = x;
Node[x].right = y;
Node[y].left = x;
}
int New_Node(int key, int id) {
static int cnt = 0;
Node[++cnt].key = key, Node[cnt].id = id;
Node[cnt].left = Node[cnt].right = cnt;
return cnt;
}
void InsertNode(FIB_Heap &heap, int x) {
if(heap.n == 0) heap.min = x;
else {
add(x, heap.min);
Node[x].fa = 0;
if(Node[x].key < Node[heap.min].key)
heap.min = x;
}
heap.n++;
}
void InsertKey(FIB_Heap &heap, int key, int id) {
InsertNode(heap, New_Node(key, id));
}
void connect(int x, int y) {
int z = Node[x].right;
Node[x].right = Node[y].right;
Node[Node[y].right].left = x;
Node[y].right = z;
Node[z].left = y;
}
FIB_Heap merge(FIB_Heap &H1, FIB_Heap H2) {
if(H1.n == 0) return H1 = H2;
if(H2.n == 0) return H1;
if(H1.min == 0)
H1.min = H2.min, H1.n = H2.n;
else if(H1.min && H2.min) {
connect(H1.min, H2.min);
if(Node[H1.min].key > Node[H2.min].key)
H1.min = H2.min;
else if(Node[H1.min].key == Node[H2.min].key)
if(Node[H2.min].id < Node[H1.min].id)
H1.min = H2.min;
H1.n += H2.n;
}
return H1;
}
int DeleteMin(FIB_Heap &heap) {
int x = heap.min;
if(heap.min == Node[x].right)
heap.min = 0;
else {
remove(x);
heap.min = Node[x].right;
}
Node[x].left = Node[x].right = x;
return x;
}
void link(FIB_Heap &heap, int x, int y) {
remove(x);
if(Node[y].child == 0)
Node[y].child = x;
else
add(x, Node[y].child);
Node[x].fa = y;
Node[y].deg++;
Node[x].marked = 0;
}
void Consolidate(FIB_Heap &heap) {
int d, D, x = 0, y = 0;
D = log(heap.n) / log(2) + 1;
while(heap.min) {
x = DeleteMin(heap);
d = Node[x].deg;
while(cons[d]) {
y = cons[d];
if(Node[x].key > Node[y].key)
swap(x, y);
else if(Node[x].key == Node[y].key
&& Node[x].id > Node[y].id)
swap(x, y);
link(heap, y, x);
cons[d] = 0;
d++;
}
cons[d] = x;
} heap.min = 0;
for(int i = 0; i < D; i++) {
if(cons[i]) {
if(heap.min == 0)
heap.min = cons[i];
else {
add(cons[i], heap.min);
if(Node[cons[i]].key < Node[heap.min].key)
heap.min = cons[i];
else if(Node[cons[i]].key == Node[heap.min].key)
if(Node[cons[i]].id < Node[heap.min].id)
heap.min = cons[i];
}
cons[i] = 0;
}
}
}
int extract(FIB_Heap &heap) {
int x = 0, z = heap.min;
if(z) {
while(Node[z].child) {
x = Node[z].child;
remove(x);
if(Node[x].right == x)
Node[z].child = 0;
else
Node[z].child = Node[x].right;
add(x, z);
Node[x].fa = 0;
}
remove(z);
if(Node[z].right == z)
heap.min = 0;
else {
heap.min = Node[z].right;
Consolidate(heap);
}
heap.n--;
}
return z;
}
void redegree(int fa, int degree) {
Node[fa].deg -= degree;
if(Node[fa].fa)
redegree(Node[fa].fa, degree);
}
void cut(FIB_Heap &heap, int x, int y) {
remove(x), redegree(y, Node[x].deg);
if(x == Node[x].right)
Node[y].child = 0;
else Node[y].child = Node[x].right;
Node[x].left = Node[y].left = x;
Node[x].fa = 0;
Node[x].marked = 0;
add(x, heap.min);
}
void cascadingcut(FIB_Heap &heap, int y) {
int z = Node[y].fa;
if(z) {
if(Node[y].marked == 0)
Node[y].marked = 1;
else {
cut(heap, y, z);
cascadingcut(heap, z);
}
}
}
void decrease(FIB_Heap &heap, int x, int key) {
int y = Node[x].fa;
Node[x].key = key;
if(y && Node[x].key < Node[y].key) {
cut(heap, x, y);
cascadingcut(heap, y);
}
if(Node[x].key < Node[heap.min].key)
heap.min = x;
}
void DeleteNode(FIB_Heap &heap, int x) {
decrease(heap, x, -1 << 30);
extract(heap);
}
int a[N], fa[N], ff[N];
bool isdelete[N];
inline int get(int x) {
return x == fa[x] ? x : fa[x] = get(fa[x]);
}
int main() {
int n, m;
scanf("%d %d", &n, &m);
for(int i = 1; i <= n; i++) {
scanf("%d", a + i);
InsertKey(heap[i], a[i], i);
fa[i] = i;
}
for(int i = n + 1; i <= n + n; i++) fa[i] = i;
while(m--) {
int opt, x, y;
scanf("%d %d", &opt, &x);
if(opt == 1) {
scanf("%d", &y);
if(isdelete[x] || isdelete[y]) continue;
int p = get(x), q = get(y);
if(p == q)
continue;
if(p > q) swap(p, q);
merge(heap[p], heap[q]);
fa[q] = p;
Consolidate(heap[p]);
} else {
if(isdelete[x]) { puts("-1"); continue; }
int y = get(x);
printf("%d\n", Node[heap[y].min].key);
isdelete[heap[y].min] = 1;
extract(heap[y]);
}
}
return 0;
}
惊了竟然有 \(300\) 行……(其实还不到)
然后是不是觉得又学会了一种装 X 神器可以出去炫耀了
Relaxed Heap
这个东西也是 \(Tarjan\) 神仙提出来的,它的复杂度和斐波那契堆完全相同(不知道常数如何)
但是我也不会实现,大家有兴趣可以看看这篇论文:Relaxed Heaps
如果大家能够实现也不妨告诉我,我也好补充。
这里只是为了让更多人知道有这么个结构,所以并不展开(原因竟是我不会……)
配对堆
这个东西比斐波那契堆还重要!
你们可以看看它的复杂度——除了减小关键字外竟然和斐波那契堆这么接近!
但是它减小关键字的复杂度也才 \(2^{O(\sqrt{\text{log log} N})}\)(渐进)!
这意味在在 \(N=10^5-10^6\)之间的时候,时间复杂度大概就是 \(O(3-4)\) 左右。
但是其真正的复杂度还没有人能证明出来,所以你们可以自己试试(反正我不会)。
反正就是常数比较小,可以接受。(但是我怎么觉得我写出来的是\(O(1)\)的……)
重点是代码比斐波那契堆短很多!
还是老规矩,先给你们看看它长啥样:
(图源:百度百科)
因为网上没有图了所以……
并且更加让人惊讶的是:这个堆竟然又是 \(Tarjan\) 神仙发明的——一个斐波那契堆的简化版本。
(快膜拜 \(Tarjan\) 神仙)
定义
基本操作函数的定义
-
\(merge(x, y)\) 将编号为 \(x\) 和编号为 \(y\) 的堆合并,并返回合并后的根节点,时间复杂度 \(O(1)\);
-
\(push/insert (x)\) 插入值(或节点) x,时间复杂度 \(O(1)\);
-
\(change(x)\) 修改 \(x\) 节点的值,时间复杂度 \(O(1-\text{log }N)\);
-
\(top()\) 返回堆顶元素值,时间复杂度 \(O(1)\);
-
\(pop/extract ()\) 弹出堆顶元素,即删除最值,时间复杂度 \(O(\text{log }N)\)。
数组名定义
-
\(fa[x]\) 记录 \(x\) 的父亲节点,如果没有父亲赋值为 \(0\);
-
\(val[x]\) 记录 \(x\) 节点的权值;
-
\(root[x]\) 记录第 \(x\) 个堆的根节点编号;
-
\(head/ver/Next\) 链表的操作(即链式前向星)。
当然因为我们删除一个节点之后就空出来了一个数组下标,我们可以采取“回收”的措施。
简单来讲就是额外开一个栈,把没用的节点数组下标扔进去,只要栈不为空,要新建节点时拿出来一个就好。
翻译成代码如下:
struct STACK{
int stk[N], top, x;
STACK() { top = x = 0; }
int get() {
return top ? stk[top--] : ++x;
}
void push(int Index) {
stk[++top] = Index;
}
}Node, temp;
其中 \(Node\) 存的是节点剩下的,\(temp\) 存的是边剩下的。
下面的操作以维护小根堆为例。
merge
(请允许我在别人博客里扣几张图)
假设现在有 \(A, B\) 两个堆要合并,那么选择根节点点权较小的作为另一个堆根节点的父节点,连边即可,即:
-
选择一个堆,其根节点权值较小,其根节点记为 \(x\),另一个堆的根节点记为 \(y\)。
-
令 \(fa[y]=x\),并建立一条 \(x\) 到 \(y\) 的有向边。
在图片中就是这样的:

翻译成代码是这样的:
int head[N], Next[N], root[N];
int fa[N], ver[N], val[N];
void change(int &x, int &y) { // swap(x, y)
x ^= y, y ^= x, x ^= y;
}
void add(int x, int y) {
int cnt = temp.get();
ver[cnt] = y;
Next[cnt] = head[x];
head[x] = cnt;
}
int merge(int x, int y) {
if(val[x] > val[y])
change(x, y);
add(fa[y] = x, y);
return x;
}
(图源网络,如有侵权请告知我及时更换)
其中 \(temp.get()\) 等操作已经在上面“定义”部分给出。
是不是很简单哇
push/insert
为了好听就叫 \(push\) 了……
简单来讲,新建一个节点,赋值,然后合并到根节点。
是不是与左偏树插入的思想很类似?但是这个时间复杂度是 \(O(1)\) 的哦!

(图源网络,如有侵权请告知我及时更换)
void push(int v, int &root) {
int x = Node.get();
val[x] = v;
if(root)
root = merge(root, x);
else root = x;
}
\(Node.get()\) 啥的也在上面“定义”中哦(不会看到这里你连定义都没看吧……)
change
\(change\) 主要有两种,一种调大,一种调小。
其实很简单的……把它和父节点之间的所有联系断开,修改值后执行合并操作就好。
但是因为边表是不好删除的,所以我们干脆不要删除了,这并不会影响正确性。
因为最后我们再用到边表,就是 \(pop/extract\) 操作了,我们只需判断父子节点的从属关系即可。
画成图是这样的:

(图源网络,如有侵权请告知我及时更换)
虽然有人指出这样做好像不是很正确,会破坏配对堆的原有形态,但是我觉得很正常啊……
而且我觉得改大改小好像没什么差别,只不过一般用到都是改小的操作。
void decrease(int x, int v, int &root) {
fa[x] = 0, val[x] = v;
if(x != root)
root = merge(x, root);
}
时间复杂度……应该是 \(O(1)\) 才对吧……(反正我也不会证明)。
top
返回根节点的值即可。
int top(int root) {
return val[root];
}
pop/extract
最缓慢,也是最重要的操作。
(就说你没有 \(pop\) 这个堆还能干啥……)
你会发现之前的操作都是我们乱搞出来的,所以这个时候 \(pop\) 就要付出代价了……
我们要在根节点的整个边表中寻找一个合法的儿子成为整个堆的新根。
其实和左偏树很类似,可以把它所有儿子节点直接两两合并,但是这样的复杂度很容易变成 \(O(N)\)……
然后你就挂了……我们不能像建堆那样逐级合并,那干脆一个一个合并好了。
简单来说,就是合并 \(1,2\),然后并到 \(2\) 中再合并 \(2,3\)……
这个复杂度还是很危险的,但是我们只要保证儿子节点不太多就好,这个操作恰恰能满足这个性质。
所以时间复杂度是 \(O(\text{log }N)\)。

(图源网络,如有侵权请告知我及时更换)
int stk[N];
void pop(int &root) {
int top = 0, x = 0;
for(int i = head[root], y; i; i = Next[i]) {
if(fa[y = ver[i]] == root)
fa[stk[++top] = y] = 0;
temp.push(i);
}
Node.push(root);
root = 0;
while(x < top) {
++x;
if(x == top)
return void(root = stk[x]);
stk[++top] = merge(stk[x], stk[x + 1]);
++x;
}
}
完整代码
这么神奇的数据结构,竟然这么简单!
以 洛谷 \(P3377\) 为例给出完整代码。
记得维护编号啊……(跟上面一样的啦)
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
struct STACK{
int stk[N], top, x;
STACK() { top = x = 0; }
int get() {
return top ? stk[top--] : ++x;
}
void push(int Index) {
stk[++top] = Index;
}
}Node, temp;
int fa[N], head[N], val[N], num[N];
int ver[N], Next[N], root[N];
void change(int &x, int &y) {
x ^= y, y ^= x, x ^= y;
}
void add(int x, int y) {
int cnt = temp.get();
ver[cnt] = y;
Next[cnt] = head[x];
head[x] = cnt;
}
int merge(int x, int y) {
if(val[x] > val[y])
change(x, y);
else if(val[x] == val[y] && num[x] > num[y])
change(x, y);
add(fa[y] = x, y);
return x;
}
void push(int v, int id, int &root) {
int x = Node.get();
val[x] = v, num[x] = id;
if(root)
root = merge(root, x);
else root = x;
}
int stk[N];
void pop(int &root) {
int top = 0, x = 0;
for(int i = head[root], y; i; i = Next[i]) {
if(fa[y = ver[i]] == root)
fa[stk[++top] = y] = 0;
temp.push(i);
}
Node.push(root);
root = 0;
while(x < top) {
++x;
if(x == top)
return void(root = stk[x]);
stk[++top] = merge(stk[x], stk[x + 1]);
++x;
}
}
int top(int root) {
return val[root];
}
void decrease(int x, int v, int &root) {
fa[x] = 0, val[x] = v;
if(x != root)
root = merge(x, root);
}
int f[N];
int get(int x) {
return x == f[x] ? x : f[x] = get(f[x]);
}
bool del[N];
int main() {
int n, m;
scanf("%d %d", &n, &m);
for(int i = 1, x; i <= n; i++) {
scanf("%d", &x), push(x, i, root[i]);
f[i] = i;
}
while(m--) {
int opt, x, y;
scanf("%d %d", &opt, &x);
if(opt == 1) {
scanf("%d", &y);
if(del[x] || del[y]) continue;
x = get(x), y = get(y);
if(x == y) continue;
int r = merge(root[x], root[y]);
if(root[x] == r) f[y] = x;
else f[x] = y;
} else {
if(del[x]) { puts("-1"); continue; }
x = get(x);
printf("%d\n", top(root[x]));
del[num[root[x]]] = 1;
pop(root[x]);
}
}
return 0;
}
总结:这么优秀的数据结构,在算法竞赛中可以选择使用代替左偏树。但是它也有缺点,因为它不能可持久化,这个在下一个部分就会提到。当然在没有特殊要求的情况下,这无疑是一种优秀的数据结构。因为代码很短,就不必要使用 \(\text{C++STL}\) 中的平板电视库了吧……
可持久化相关
应用:贪心
导言
下面给出的几个例题,首先第一题是普通的堆和贪心,第二题和第三题将会介绍堆优化可撤销的贪心。
而第四第五题这两题都是非常经典的堆的题目,有贪心的思想,相对来说思维量也会大一点。
例题 1.1:[NOIp2004] 合并果子
Description
> 在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。多多决定把所有的果子合成一堆。 每一次合并,多多可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。可以看出,所有的果子经过 $n−1$ 次合并之后, 就只剩下一堆了。多多在合并果子时总共消耗的体力等于每次合并所耗体力之和。 因为还要花大力气把这些果子搬回家,所以多多在合并果子时要尽可能地节省体力。假定每个果子重量都为 $1$ ,并且已知果子的种类 数和每种果子的数目,你的任务是设计出合并的次序方案,使多多耗费的体力最少,并输出这个最小的体力耗费值。 例如有 $3$ 种果子,数目依次为 $1$ , $2$ , $9$ 。可以先将 $1$ 、 $2$ 堆合并,新堆数目为 $3$ ,耗费体力为 $3$ 。接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 $12$ ,耗费体力为 $12$ 。所以多多总共耗费体力 $=3+12=15$ 。可以证明 $15$ 为最小的体力耗费值。 $n≤10^4$。很显然,一个贪心思路就是每次都取出最小的两堆,然后合并并累计答案,再把这堆放回去,重复上面的操作,直到最后剩下一堆。
证明就不必了(因为我 \(AC\) 了……)
如果我们选择排序算法的话(说不定能过)复杂度应该是 \(O(\sum^{n}_{i=2}i\text{log}i)\)。
很明显是比较高的。看一下数据范围 \(N≤10^4\)(我认为可以加强),那么 \(O(N\text{log}N)\) 是可以通过的。
因为每次都只需要最小元素,结合时间复杂度,让我们想到了堆。
显然可以实现。但是数据范围较小,使用\(\text{C++STL}\)优先队列(\(\text{priority_queue}\))即可。
题目连接:洛谷\(P1090\) 合并果子
如果不使用万能头文件,优先队列在 \(\text{queue}\) 库文件中,引入调用即可。
因为维护的是小根堆,而优先队列默认大根堆,因此把插入时数变成负数,取出来时再反回来就行了。
#include<bits/stdc++.h>
using namespace std;
priority_queue<int> num;
int main() {
int n, sum = 0;
scanf("%d", &n);
for(int i = 1, x; i <= n; i++) {
scanf("%d", &x);
num.push(-x);
}
while(num.size() > 1) {
int b=num.top(); num.pop();
int a=num.top(); num.pop();
num.push(a + b);
sum -= a + b;
}
printf("%d", sum);
return 0;
}
这一题是比较入门的堆的题目。
例题 1.2 股票
Description
> 你看中了一支股票,打算在接下来的 $n$ 天中每天至多买入或卖出一股。 你已经提前知道接下来 $n$ 天里,第 $i$ 天的股价为 $a_i$,即第 $i$ 天选择买入一股需要花费,卖出一股可盈利。初始时你手中没有股票。 你想知道你在这 $n$ 天中的最大利润。Input format
> 第一行包含一个整数 $n$。 接下来行,每一个整数描述 $a_i$。Outpur format
> 输出一行一个整数表示最大利润。Sample.in
15
9
9
5
6
4
9
2
1
5
8
5
7
8
4
6
Sample.out
23
Constraint
> 对于 $50\%$ 的数据,$n≤5×10^3$; 对于 $100\%$ 的数据,$n≤10^5,a_i≤10^9$。算法一:\(n≤5×10^3\)
设 \(f[i][0/1]\) 表示在第 \(i\) 天卖/不卖股票的最大利润。直接 \(DP\),期望得分 \(50pts\)。
算法二:\(n≤10^5\)
这样的题目,我们肯定是希望把这些天两两配对,使得差值之和尽量的大。
显然上述 \(DP\) 可以优化。但是这里并不谈优化。我们考虑一些神奇的算法——可撤销的贪心。
假设第 \(i\) 天的股票在第 \(j\) 天卖出劣于在第 \(k\) 天卖出,那么我们可以通过“买入”第 \(j\) 天的股票并重新在第 \(k\) 天卖出,这样相当于第 \(j\) 天没有操作。这就是可撤销的思想。
显然第 \(j\) 天的影响被抵消掉了,并且第 \(j\) 天的股票还有可能跟之后某一天匹配。堆优化即可。
时间复杂度 \(O(N\text{log}N)\),期望得分 \(100pts\)。
简单来说,就是你在今天卖不亏的情况下,选择之前一天买入价格最小的统计答案,然后“买入”这一天的股票(也就是插入堆中),这样就可以抵消当前卖的影响了。
#include<bits/stdc++.h>
#define ll long long
std::priority_queue <int> h;
int main() {
int x, n; ll ans = 0;
scanf("%d", &n);
while (n--) {
scanf("%d", &x);
if (!h.empty() && x > - h.top())
ans += x + h.top(), h.pop(), h.push(-x);
h.push(-x);
}
printf("%lld\n", ans);
return 0;
}
请注意:本题没有提交地址!(可以尝试我的数据)
题目数据在这 Here
建议传到洛谷私人(或团队)题库上测,时限 \(1s\),空间 \(512M\)。
例题 1.3 种树
Description
> $cyrcyr$ 今天在种树,他在一条直线上挖了 $n$ 个坑。这 $n$ 个坑都可以种树,但为了保证每一棵树都有充足的养料,$cyrcyr$ 不会在相邻的两个坑中种树。而且由于 $cyrcyr$ 的树种不够,他至多会种 $k$ 棵树。假设 $cyrcyr$ 有某种神能力,能预知自己在某个坑种树的获利会是多少(可能为负),请你帮助他计算出他的最大获利。$n<=500000,k<=n/2$。是不是感觉就是上一个题目的升级版啊 \(QwQ\)
这里没有了天数的限制,但是多了树的限制和“距离”的限制。
但是我们还是考虑贪心。我们就要选出值尽量大的间隔开来的 \(k\) 个坑(或者不满 \(k\)个),这样答案会最大。
下面给每个坑从左到右编号 \(1-n\),第 \(i\) 个坑的权值是 \(val_i\)。
考虑选择一个坑的影响。如果选择一个坑 \(i\),那么 \(i-1,i+1\)(当然两端的坑只有一者)这两个坑就是选不了的。
那么假设我们这个坑不是最优的,这个“撤销”的代价就是 \(val_{i-1}+val_{i+1}-val_i\)。
这样我们就可以乱搞了(因为随便搞是可以撤销当前操作的)。
注意我们选了这个坑就当即更新 \(val_i=val_{i-1}+val_{i+1}-val_i\),并且删除左右两边的坑。
这个操作可以通过双向链表实现。每次操作完还要把 \(val_{i-1}+val_{i+1}-val_i\) 插入堆中实现贪心。
每次取出堆顶的最大元素即可,最多重复 \(k\) 次即可得到答案。
删除掉的元素要打上标记!每次都要找到一个没有被删除的最小元素更新。
(因为一开始我们全部扔到堆中了,现在要收拾这个烂摊子)
时间复杂度 \(O(k\text{log}N)\),期望得分 \(100pts\)。
题目链接:洛谷 \(P1484\) 种树
#include<bits/stdc++.h>
using namespace std;
const int N = 5e5 + 10;
priority_queue< pair<int, int> > q;
int a[N], pre[N], Next[N];
bool del[N];
int main() {
int n, k;
scanf("%d %d", &n, &k);
for(int i = 1; i <= n; i++) {
pre[i] = i - 1, Next[i] = i + 1;
scanf("%d", a + i);
q.push(make_pair(a[i], i));
}
pre[n + 1] = n, Next[0] = 1;
long long ans = 0;
while(k--) {
while(del[q.top().second]) q.pop();
int x = q.top().second;
if(q.top().first <= 0) break;
ans += q.top().first, q.pop();
a[x] = a[pre[x]] + a[Next[x]] - a[x];
q.push(make_pair(a[x], x));
del[pre[x]] = del[Next[x]] = 1;
pre[x] = pre[pre[x]], Next[x] = Next[Next[x]];
Next[pre[x]] = x, pre[Next[x]] = x;
}
printf("%lld\n", ans);
return 0;
}
特别的,本题我们不用判断堆是否为空,因为堆中始终会有元素(\(n>k\))。
例题 1.4 序列合并
Description
> 有两个长度都是 $N$ 的序列 $A$ 和 $B$,在 $A$ 和 $B$ 中各取一个数相加可以得到 $N^2$ 个和,求这 $N^2$ 个和中最小的 $N$ 个。$N≤10^5$。一个非常经典的题目(但是我也忘了叫什么类型了)。
我们将 \(A\),\(B\) 排序得到两个有序数组。那么有一下结论:
-
\(A_1+B_1≤A_2+B_1≤……≤A_n+B_1\),同理 \(A_1+B_2≤A_2+B_2≤……≤A_n+B_2\)……
-
\(A_1+B_1≤A_1+B_2≤……≤A_1+B_n\),同理……(自己推吧)。
考虑让我们在堆中先放入 \(A_1+B_1,A_1+B_2,……,A_1+B_n\) 这 \(N\) 个元素。
显然最小的是第一个元素,接下来考虑如何维护。
需要注意的,就是我们一开始只让所有的初始的 \(B_1\) 入队,考虑记录 \(N\) 个指针 \(now\)。
第 \(now[i]\) 个代表我们一开始放入堆的第 \(i\) 组,也就是 \(A_1+B_{i}\)这组,其 \(A\) 的下标到了 \(now[i]\)。
可能不是很好理解。那么我们考虑当前最小的解是 \(A_k+B_i\)(\(i\)的含义和上面相同),显然我们取出了很多数。
那么下一个有可能成为最小的解是哪个呢?观察上面两个结论,即其他堆的 \(A_{k'}+B_j\)(\(j≠i\))都会大于 \(A_k+B_i\)。
那么就有 \(A_{k+1}+B_i\) 会小于等于任何一个没有被加入过堆中的组合。所以我们只需要把 \(A_{k+1}+B_i\) 加入堆中,这样才有可能成为最优解。(注意是有可能)
可能还是不好理解?那大家手推吧……
时间复杂度 \(O(N\text{log}N)\),期望得分 \(100pts\)。
下面代码用了二元组(\(pair\)),其默认以第一关键字排序。
题目链接:洛谷 \(P1631\) 序列合并
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
priority_queue< pair<int, int> > q;
int a[N], b[N], now[N];
int main() {
int n;
scanf("%d", &n);
for(int i = 1; i <= n; i++)
scanf("%d", a + i);
for(int i = 1; i <= n; i++) {
scanf("%d", b + i);
q.push(make_pair(-(a[1] + b[i]), i));
}
fill(now + 1, now + n + 1, 1);
while(n--) {
printf("%d ", -q.top().first);
int x = q.top().second; q.pop();
q.push(make_pair(-(a[++now[x]] + b[x]), x));
}
return 0;
}
但是仔细观察,上面还有可推出一个结论:
若 \(A_i+B_j\) 是合法答案,那么 \((i-1)(j-1)≤N\)。
读者可以自行尝试并证明。直接计算的复杂度是 \(O(N\sqrt{N}+N\text{log}N)\)。
例题 1.5 最小函数值
Description
> 有 $n$ 个函数,分别为 $F_1,F_2,...,F_n$。定义 $F_i(x)=A_i×x^2+B_i×x+C_i$ $(x∈N^*)$。给定这些 $A_i$、$B_i$ 和 $C_i$,请求出所有函数的所有函数值中最小的 $m$ 个(如有重复的要输出多个)。$n,m≤10^4, A_i≤10,B_≤100,C_i≤10 000$ 且 $A_i,B_i,C_i$ 均为正整数。根据初中的数学知识,这些函数都是开口向上的,并且在 \([0,+∞)\) 上是单调递增的。
然后就转化成为上一个题目的双倍经验了,一样的思路和类似的代码,读者可以自己尝试实现了。
至于证明也和上一题差不多的。
题目链接:P2085 最小函数值
时间复杂度 \(O(N\text{log}N)\),期望得分 \(100pts\)。
#include<bits/stdc++.h>
using namespace std;
const int N = 1e4 + 10;
int a[N], b[N], c[N], now[N];
priority_queue< pair<long long, int> > q;
int func(long long x) { return x * x; }
int main() {
int n, m;
scanf("%d %d", &n, &m);
for(int i = 1; i <= n; i++) {
scanf("%d %d %d", a + i, b + i, c + i);
now[i] = 1;
q.push(make_pair(-(a[i] + b[i] + c[i]), i));
}
while(m--) {
printf("%lld ", -q.top().first);
int x = q.top().second; q.pop();
now[x]++;
q.push(make_pair(-(1LL * a[x] * func(now[x]) + b[x] * now[x] + c[x]), x));
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号