KClient——kafka消息中间件源码解读
最近在拜读李艳鹏的《可伸缩服务架构——框架与中间件》,该篇随笔,针对第二章的KClient(kafka消息中间件)源码解读项目,进行学习。
kclient消息中间件
从使用角度上开始入手学习
kclient-processor
该项目使用springboot调用kclient库,程序目录如下:
- domain
- Cat : 定义了一个cat对象
- Dog : 定义了一个Dog对象
- handler : 消息处理器
- AnimalsHandler : 定义了Cat和Dog的具体行为
- KClientApplication.java : Spring boot的主函数——程序执行入口
- KClientController.java : Controller 文件
top.ninwoo.kclient.app.KClientApplication
1.启动Spring Boot
ApplicationContext ctxBackend = SpringApplication.run(
KClientApplication.class, args);
2.启动程序后将自动加载KClientController(@RestController)
top.ninwoo.kclient.app.KClientController
1.通过@RestController,使@SpringBootApplication,可以自动加载该Controller
2.通过kafka-application.xml加载Beans
private ApplicationContext ctxKafkaProcessor =
new ClassPathXmlApplicationContext("kafka-application.xml");
kafka-application.xml声明了一个kclient bean,并设置其初始化执行init方法,具体实现见下章具体实现。
<bean name="kClientBoot" class="top.ninwoo.kafka.kclient.boot.KClientBoot" init-method="init"/>
另外声明了一个扫描消息处理器的bean
<context:component-scan base-package="top.ninwoo.kclient.app.handler" />
具体内容在下一节介绍
- 使用
@RequestMapping定义/,/status,/stop,/restart定义了不同的接口
这些接口实现比较简单,需要注意的是他们调用的getKClientBoot()函数。
上文,我们已经通过xml中,添加了两个Bean,调用Bean的具体实现方法如下:
private KClientBoot getKClientBoot() {
return (KClientBoot) ctxKafkaProcessor.getBean("kClientBoot");
}
通过Bean获取到KClient获取到了KClientBoot对象,便可以调用其具体方法。
top.ninwoo.kclient.app.handler.AnimalsHandler
消息处理函数
1.使用@KafkaHandlers进行声明bean,关于其具体实现及介绍在具体实现中进行介绍
2.定义了三个处理函数
- dogHandler
- catHandler
- ioExceptionHandler
dogHandler
具体处理很简单,主要分析@InputConsumer和@Consumer的作用,具体实现将在后续进行介绍。
@InputConsumer(propertiesFile = "kafka-consumer.properties", topic = "test", streamNum = 1)
@OutputProducer(propertiesFile = "kafka-producer.properties", defaultTopic = "test1")
public Cat dogHandler(Dog dog) {
System.out.println("Annotated dogHandler handles: " + dog);
return new Cat(dog);
}
@InputConsumer根据输入参数定义了一个Consumer,通过该Consumer传递具体值给dog,作为该处理函数的
输入。@OutputProducer根据输入参数定义一个Producer,而该处理函数最后返回的Cat对象,将通过该Producer最终传递到Kafka中
以下的功能与上述相同,唯一需要注意的是 @InputConsumer和@OutputProducer可以单独存在。
@InputConsumer(propertiesFile = "kafka-consumer.properties", topic = "test1", streamNum = 1)
public void catHandler(Cat cat) throws IOException {
System.out.println("Annotated catHandler handles: " + cat);
throw new IOException("Man made exception.");
}
@ErrorHandler(exception = IOException.class, topic = "test1")
public void ioExceptionHandler(IOException e, String message) {
System.out.println("Annotated excepHandler handles: " + e);
}
top.ninwoo.kclient.app.domain
只是定义了Cat和Dog对象,不做赘述。
总结
到这里,总结下我们都实现了哪些功能?
- 程序启动
- 调用KClientBoot.init()方法
- AnimalsHandler定义了消费者和生产者的具体方法。
kclient-core
kclient消息中间件的主体部分,该部分将会涉及
- kafka基本操作
- 反射
项目结构如下:
- boot
- ErrorHandler
- InputConsumer
- OutputProducer
- KafkaHandlers
- KClientBoot
- KafkaHandler
- KafkaHandlerMeta
- core
- KafkaConsumer
- KafkaProducer
- excephandler
- DefaultExceptionHandler
- ExceptionHandler
- handlers
- BeanMessageHandler
- BeansMessageHandler
- DocumentMessageHandler
- ObjectMessageHandler
- ObjectsMessageHandler
- MessageHandler
- SafelyMessageHandler
- reflection.util
- AnnotationHandler
- AnnotationTranversor
- TranversorContext
在接下来的源码阅读中,我将按照程序执行的顺序进行解读。如果其中涉及到没有讨论过的模块,读者可以向下翻阅。这么
做的唯一原因,为了保证思维的连续性,尽可能不被繁杂的程序打乱。
top.ninwoo.kafka.kclient.boot.KClientBoot
如果读者刚刚阅读上一章节,那么可能记得,我们注册了一个kClientBoot的bean,并设置了初始化函数init(),所以,在kclient源码的阅读中
,我们将从该文件入手,开始解读。
public void init() {
meta = getKafkaHandlerMeta();
if (meta.size() == 0)
throw new IllegalArgumentException(
"No handler method is declared in this spring context.");
for (final KafkaHandlerMeta kafkaHandlerMeta : meta) {
createKafkaHandler(kafkaHandlerMeta);
}
}
1.该函数,首先获取了一个HandlerMeta,我们可以简单理解,在这个数据元中,存储了全部的Handler信息,这个Handler信息指的是上一章节中通过@KafkaHandlers定义的处理函数,
具体实现见top.ninwoo.kafka.kclient.boot.KafkaHandlerMeta。
2.获取数据元之后,通过循环,创建对应的处理函数。
for (final KafkaHandlerMeta kafkaHandlerMeta : meta) {
createKafkaHandler(kafkaHandlerMeta);
}
3.getKafkaHandlerMeta函数的具体实现
a.通过applicationContext获取包含kafkaHandlers注解的Bean名称。
String[] kafkaHandlerBeanNames = applicationContext
.getBeanNamesForAnnotation(KafkaHandlers.class);
b.通过BeanName获取到Bean对象
Object kafkaHandlerBean = applicationContext
.getBean(kafkaHandlerBeanName);
Class<? extends Object> kafkaHandlerBeanClazz = kafkaHandlerBean
.getClass();
c.构建mapData数据结构,具体构建见top.ninwoo.kafka.kclient.reflection.util.AnnotationTranversor
Map<Class<? extends Annotation>, Map<Method, Annotation>> mapData = extractAnnotationMaps(kafkaHandlerBeanClazz);
d.map转数据元并添加到数据元meta list中。
meta.addAll(convertAnnotationMaps2Meta(mapData, kafkaHandlerBean));
4.循环遍历创建kafkaHandler
for (final KafkaHandlerMeta kafkaHandlerMeta : meta) {
createKafkaHandler(kafkaHandlerMeta);
}
createKafkaHandler()函数的具体实现:
a.通过meta获取clazz中的参数类型
Class<? extends Object> paramClazz = kafkaHandlerMeta
.getParameterType()
b.创建kafkaProducer
KafkaProducer kafkaProducer = createProducer(kafkaHandlerMeta);
c.创建ExceptionHandler
List<ExceptionHandler> excepHandlers = createExceptionHandlers(kafkaHandlerMeta);
d.根据clazz的参数类型,选择消息转换函数
MessageHandler beanMessageHandler = null;
if (paramClazz.isAssignableFrom(JSONObject.class)) {
beanMessageHandler = createObjectHandler(kafkaHandlerMeta,
kafkaProducer, excepHandlers);
} else if (paramClazz.isAssignableFrom(JSONArray.class)) {
beanMessageHandler = createObjectsHandler(kafkaHandlerMeta,
kafkaProducer, excepHandlers);
} else if (List.class.isAssignableFrom(Document.class)) {
beanMessageHandler = createDocumentHandler(kafkaHandlerMeta,
kafkaProducer, excepHandlers);
} else if (List.class.isAssignableFrom(paramClazz)) {
beanMessageHandler = createBeansHandler(kafkaHandlerMeta,
kafkaProducer, excepHandlers);
} else {
beanMessageHandler = createBeanHandler(kafkaHandlerMeta,
kafkaProducer, excepHandlers);
}
e.创建kafkaConsumer,并启动
KafkaConsumer kafkaConsumer = createConsumer(kafkaHandlerMeta,
beanMessageHandler);
kafkaConsumer.startup();
f.创建KafkaHanlder,并添加到列表中
KafkaHandler kafkaHandler = new KafkaHandler(kafkaConsumer,
kafkaProducer, excepHandlers, kafkaHandlerMeta);
kafkaHandlers.add(kafkaHandler);
createExceptionHandlers的具体实现
1.创建一个异常处理列表
List<ExceptionHandler> excepHandlers = new ArrayList<ExceptionHandler>();
2.从kafkaHandlerMeta获取异常处理的注解
for (final Map.Entry<ErrorHandler, Method> errorHandler : kafkaHandlerMeta
.getErrorHandlers().entrySet()) {
3.创建一个异常处理对象
ExceptionHandler exceptionHandler = new ExceptionHandler() {
public boolean support(Throwable t) {}
public void handle(Throwable t, String message) {}
support方法判断异常类型是否和输入相同
public boolean support(Throwable t) {
// We handle the exception when the classes are exactly same
return errorHandler.getKey().exception() == t.getClass();
}
handler方法,进一步对异常进行处理
1.获取异常处理方法
Method excepHandlerMethod = errorHandler.getValue();
2.使用Method.invoke执行异常处理方法
excepHandlerMethod.invoke(kafkaHandlerMeta.getBean(),
t, message);
这里用到了一些反射原理,以下对invoke做简单介绍
public Object invoke(Object obj,
Object... args)
throws IllegalAccessException,
IllegalArgumentException,
InvocationTargetException
参数:
- obj 从底层方法被调用的对象
- args 用于方法的参数
在该项目中的实际情况如下:
Method实际对应top.ninwoo.kclient.app.handler.AnimalsHandler中的:
@ErrorHandler(exception = IOException.class, topic = "test1")
public void ioExceptionHandler(IOException e, String message) {
System.out.println("Annotated excepHandler handles: " + e);
}
参数方面:
- kafkaHandlerMeta.getBean() : AninmalsHandler
- t
- message
invoke完成之后,将会执行ioExceptionHandler函数
4.添加异常处理到列表中
excepHandlers.add(exceptionHandler);
createObjectHandler
createObjectsHandler
createDocumentHandler
createBeanHandler
createBeansHandler
以上均实现了类似的功能,只是创建了不同类型的对象,然后重写了不同的执行函数。
实现原理和异常处理相同,底层都是调用了invoke函数,通过反射机制启动了对应的函数。
下一节对此做了详细介绍
invokeHandler
1.获取对应Method方法
Method kafkaHandlerMethod = kafkaHandlerMeta.getMethod();
2.执行接收返回结果
Object result = kafkaHandlerMethod.invoke(
kafkaHandlerMeta.getBean(), parameter);
3.如果生产者非空,意味着需要通过生产者程序将结果发送到Kafka中
if (kafkaProducer != null) {
if (result instanceof JSONObject)
kafkaProducer.send(((JSONObject) result).toJSONString());
else if (result instanceof JSONArray)
kafkaProducer.send(((JSONArray) result).toJSONString());
else if (result instanceof Document)
kafkaProducer.send(((Document) result).getTextContent());
else
kafkaProducer.send(JSON.toJSONString(result));
生产者和消费者创建方法
protected KafkaConsumer createConsumer(
final KafkaHandlerMeta kafkaHandlerMeta,
MessageHandler beanMessageHandler) {
KafkaConsumer kafkaConsumer = null;
if (kafkaHandlerMeta.getInputConsumer().fixedThreadNum() > 0) {
kafkaConsumer = new KafkaConsumer(kafkaHandlerMeta
.getInputConsumer().propertiesFile(), kafkaHandlerMeta
.getInputConsumer().topic(), kafkaHandlerMeta
.getInputConsumer().streamNum(), kafkaHandlerMeta
.getInputConsumer().fixedThreadNum(), beanMessageHandler);
} else if (kafkaHandlerMeta.getInputConsumer().maxThreadNum() > 0
&& kafkaHandlerMeta.getInputConsumer().minThreadNum() < kafkaHandlerMeta
.getInputConsumer().maxThreadNum()) {
kafkaConsumer = new KafkaConsumer(kafkaHandlerMeta
.getInputConsumer().propertiesFile(), kafkaHandlerMeta
.getInputConsumer().topic(), kafkaHandlerMeta
.getInputConsumer().streamNum(), kafkaHandlerMeta
.getInputConsumer().minThreadNum(), kafkaHandlerMeta
.getInputConsumer().maxThreadNum(), beanMessageHandler);
} else {
kafkaConsumer = new KafkaConsumer(kafkaHandlerMeta
.getInputConsumer().propertiesFile(), kafkaHandlerMeta
.getInputConsumer().topic(), kafkaHandlerMeta
.getInputConsumer().streamNum(), beanMessageHandler);
}
return kafkaConsumer;
}
protected KafkaProducer createProducer(
final KafkaHandlerMeta kafkaHandlerMeta) {
KafkaProducer kafkaProducer = null;
if (kafkaHandlerMeta.getOutputProducer() != null) {
kafkaProducer = new KafkaProducer(kafkaHandlerMeta
.getOutputProducer().propertiesFile(), kafkaHandlerMeta
.getOutputProducer().defaultTopic());
}
// It may return null
return kafkaProducer;
}
这两部分比较简单,不做赘述。
小结
KClientBoot.java实现了:
- 获取使用KafkaHandlers中定义注释的方法及其它信息
- 基于反射机制,生成处理函数。
- 执行处理函数
- 创建对应Producer和Consumer
还剩余几个比较简单的部分,比如shutdownAll()等方法,将在具体实现处进行补充介绍。
到此,整个项目的主体功能都已经实现。接下来,将分析上文中出现频率最高的kafkaHandlerMeta与生产者消费者的具体实现。
top.ninwoo.kafka.kclient.boot.KafkaHandlerMeta
KafkaHandlerMeta存储了全部的可用信息,该类实现比较简单,主要分析其成员对象。
- Object bean : 存储底层的bean对象
- Method method : 存储方法对象
- Class<? extends Object> parameterType : 存储参数的类型
- InputConsumer inputConsumer : 输入消费者注解对象,其中存储着创建Consumer需要的配置
- OutputProducer outputProducer : 输出生产者注解对象,其中存储着创建Producer需要的配置
- Map<ErrorHandler, Method> errorHandlers = new HashMap<ErrorHandler, Method>() 异常处理函数与其方法组成的Map
top.ninwoo.kafka.kclient.core.KafkaProducer
该类主要通过多态封装了kafka Producer的接口,提供了更加灵活丰富的api接口,比较简单不做赘述。
top.ninwoo.kafka.kclient.core.KafkaConsumer
该类的核心功能是:
- 加载配置文件
- 初始化线程池
- 初始化GracefullyShutdown函数
- 初始化kafka连接
在这里跳过构造函数,但在进入核心问题前,先明确几个成员变量的作用。
- streamNum : 创建消息流的数量
- fixedThreadNum : 异步线程池中的线程数量
- minThreadNum : 异步线程池的最小线程数
- maxThreadNum : 异步线程池的最大线程数
- stream : kafka消息流
- streamThreadPool : kafka消息处理线程池
在每个构造函数后都调用了init()方法,所以我们从init()入手。另外一个核心方法startup()将在介绍完init()函数进行介绍。
init()
在执行核心代码前,进行了一系列的验证,这里跳过该部分。
1.加载配置文件
properties = loadPropertiesfile();
2.如果共享异步线程池,则初始化异步线程池
sharedAsyncThreadPool = initAsyncThreadPool();
3.初始化优雅关闭
initGracefullyShutdown();
4.初始化kafka连接
initKafka();
initAsyncThreadPool()
完整代码如下:
private ExecutorService initAsyncThreadPool() {
ExecutorService syncThreadPool = null;
if (fixedThreadNum > 0)
syncThreadPool = Executors.newFixedThreadPool(fixedThreadNum);
else
syncThreadPool = new ThreadPoolExecutor(minThreadNum, maxThreadNum,
60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
return syncThreadPool;
}
首先,如果异步线程数大于0,则使用该参数进行创建线程池。
syncThreadPool = Executors.newFixedThreadPool(fixedThreadNum);
如果线程数不大于0,使用minThreadNum,maxThreadNum进行构造线程池。
syncThreadPool = new ThreadPoolExecutor(minThreadNum, maxThreadNum,
60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
Executors简介
这里介绍Executors提供的四种线程池
- newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
- newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
ThreadPoolExecutor简介
ThreadPooExecutor与Executor的关系如下:
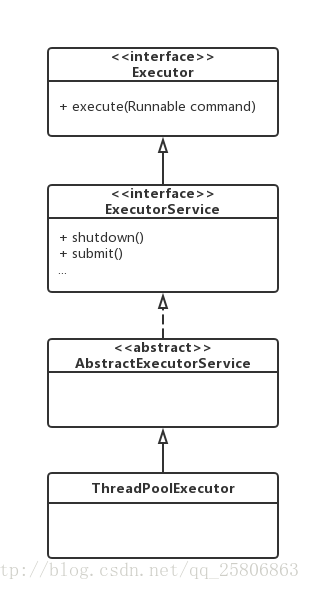
构造方法:
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue);
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler)
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory)
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
参数说明:
- corePoolSize
核心线程数,默认情况下核心线程会一直存活,即使处于闲置状态也不会受存keepAliveTime限制。除非将allowCoreThreadTimeOut设置为true。
- maximumPoolSize
线程池所能容纳的最大线程数。超过这个数的线程将被阻塞。当任务队列为没有设置大小的LinkedBlockingDeque时,这个值无效。
- keepAliveTime
非核心线程的闲置超时时间,超过这个时间就会被回收。
- unit
指定keepAliveTime的单位,如TimeUnit.SECONDS。当将allowCoreThreadTimeOut设置为true时对corePoolSize生效。
- workQueue
线程池中的任务队列.
常用的有三种队列,SynchronousQueue,LinkedBlockingDeque,ArrayBlockingQueue。
- SynchronousQueue
线程工厂,提供创建新线程的功能。
- RejectedExecutionHandler
当线程池中的资源已经全部使用,添加新线程被拒绝时,会调用RejectedExecutionHandler的rejectedExecution方法。
initKafka
由于kafka API已经改动很多,所以这里关于Kafka的操作仅做参考,不会详细介绍。
1.加载Consumer配置
ConsumerConfig config = new ConsumerConfig(properties);
2.创建consumerConnector连接
consumerConnector = Consumer.createJavaConsumerConnector(config);
3.存储kafka topic与对应设置的消息流数量
Map<String, Integer> topics = new HashMap<String, Integer>();
topics.put(topic, streamNum);
4.从kafka获取消息流
Map<String, List<KafkaStream<String, String>>> streamsMap = consumerConnector
.createMessageStreams(topics, keyDecoder, valueDecoder);
streams = streamsMap.get(topic);
5.创建消息处理线程池
startup()
上述init()主要介绍了kafka消费者的初始化,而startup()则是kafkaConsumer作为消费者进行消费动作的核心功能代码。
1.依次处理消息线程streams中的消息
for (KafkaStream<String, String> stream : streams) {
2.创建消息任务
AbstractMessageTask abstractMessageTask = (fixedThreadNum == 0 ? new SequentialMessageTask(
stream, handler) : new ConcurrentMessageTask(stream, handler, fixedThreadNum));
3.添加到tasks中,以方便关闭进程
tasks.add(abstractMessageTask);
4.执行任务
streamThreadPool.execute(abstractMessageTask);
AbstractMessageTask
任务执行的抽象类,核心功能如下从消息线程池中不断获取消息,进行消费。
下面是完整代码,不再详细介绍:
abstract class AbstractMessageTask implements Runnable {
protected KafkaStream<String, String> stream;
protected MessageHandler messageHandler;
AbstractMessageTask(KafkaStream<String, String> stream,
MessageHandler messageHandler) {
this.stream = stream;
this.messageHandler = messageHandler;
}
public void run() {
ConsumerIterator<String, String> it = stream.iterator();
while (status == Status.RUNNING) {
boolean hasNext = false;
try {
// When it is interrupted if process is killed, it causes some duplicate message processing, because it commits the message in a chunk every 30 seconds
hasNext = it.hasNext();
} catch (Exception e) {
// hasNext() method is implemented by scala, so no checked
// exception is declared, in addtion, hasNext() may throw
// Interrupted exception when interrupted, so we have to
// catch Exception here and then decide if it is interrupted
// exception
if (e instanceof InterruptedException) {
log.info(
"The worker [Thread ID: {}] has been interrupted when retrieving messages from kafka broker. Maybe the consumer is shutting down.",
Thread.currentThread().getId());
log.error("Retrieve Interrupted: ", e);
if (status != Status.RUNNING) {
it.clearCurrentChunk();
shutdown();
break;
}
} else {
log.error(
"The worker [Thread ID: {}] encounters an unknown exception when retrieving messages from kafka broker. Now try again.",
Thread.currentThread().getId());
log.error("Retrieve Error: ", e);
continue;
}
}
if (hasNext) {
MessageAndMetadata<String, String> item = it.next();
log.debug("partition[" + item.partition() + "] offset["
+ item.offset() + "] message[" + item.message()
+ "]");
handleMessage(item.message());
// if not auto commit, commit it manually
if (!isAutoCommitOffset) {
consumerConnector.commitOffsets();
}
}
}
protected void shutdown() {
// Actually it doesn't work in auto commit mode, because kafka v0.8 commits once per 30 seconds, so it is bound to consume duplicate messages.
stream.clear();
}
protected abstract void handleMessage(String message);
}
SequentialMessageTask && SequentialMessageTask
或许您还比较迷惑如何在这个抽象类中实现我们具体的消费方法,实际上是通过子类实现handleMessage方法进行绑定我们具体的消费方法。
class SequentialMessageTask extends AbstractMessageTask {
SequentialMessageTask(KafkaStream<String, String> stream,
MessageHandler messageHandler) {
super(stream, messageHandler);
}
@Override
protected void handleMessage(String message) {
messageHandler.execute(message);
}
}
在该子类中,handleMessage直接执行了messageHandler.execute(message),而没有调用线程池,所以是顺序消费消息。
class ConcurrentMessageTask extends AbstractMessageTask {
private ExecutorService asyncThreadPool;
ConcurrentMessageTask(KafkaStream<String, String> stream,
MessageHandler messageHandler, int threadNum) {
super(stream, messageHandler);
if (isSharedAsyncThreadPool)
asyncThreadPool = sharedAsyncThreadPool;
else {
asyncThreadPool = initAsyncThreadPool();
}
}
@Override
protected void handleMessage(final String message) {
asyncThreadPool.submit(new Runnable() {
public void run() {
// if it blows, how to recover
messageHandler.execute(message);
}
});
}
protected void shutdown() {
if (!isSharedAsyncThreadPool)
shutdownThreadPool(asyncThreadPool, "async-pool-"
+ Thread.currentThread().getId());
}
}
在ConcurrentMessageTask中, handleMessage调用asyncThreadPool.submit()提交了任务到异步线程池中,是一个并发消费。
而messageHandler是通过KClientBoot的createKafkaHandler创建并发送过来的,所以实现了最终的消费。
总结:
到此全部的项目解读完毕,如果仍有疑惑,可以参看李艳鹏老师的《可伸缩服务架构框架与中间件》一书,同时也可以与我联系交流问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号