Python正则表达式学习摘要
@
为什么使用正则表达式
典型的搜索和替换操作要求您提供与预期的搜索结果匹配的确切文本。虽然这种技术对于对静态文本执行简单搜索和替换任务可能已经足够了,但它缺乏灵活性,若采用这种方法搜索动态文本,即使不是不可能,至少也会变得很困难。
通过使用正则表达式,可以:
- 测试字符串内的模式。
例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。 - 替换文本。
可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。 - 基于模式匹配从字符串中提取子字符串。
可以查找文档内或输入域内特定的文本。
例如,您可能需要搜索整个网站,删除过时的材料,以及替换某些 HTML 格式标记。在这种情况下,可以使用正则表达式来确定在每个文件中是否出现该材料或该 HTML 格式标记。此过程将受影响的文件列表缩小到包含需要删除或更改的材料的那些文件。然后可以使用正则表达式来删除过时的材料。最后,可以使用正则表达式来搜索和替换标记。
语法
元字符

e.g.
import re
print(re.findall("[aeiou]","Let me go back either"))
print(re.findall("[^aeiou]","Let me go back either"))
rint(re.search(".","sunck is a good man 7"))
print(re.findall("[^0-9a-zA-Z_]","sunck is a good man 7"))
print(re.search("\d","sunck is a good man 7"))
print(re.search("[^\d]","sunck is a good man 7"))
print(re.findall("[\W]","sunck is a good man 7 "))
print(re.findall("[\n]","sunck is a good man 7 \n"))
print(re.findall(".","sunck is a good man 7 \n",flags=re.S))
Output

锚字符

e.g.
import re
print(re.search("^sunck","sunck is good man"))
print(re.search("man$","sunck is good man"))
#re.M 多行匹配
print(re.findall("^sunck","sunck is good man\nsunck is good man",re.M))
print(re.search("\Asunck","sunck is good man\nsunck is good man",re.M))
print(re.findall("man$","sunck is good man\nsunck is good man",re.M))
print(re.search("man\Z","sunck is good man\nsunck is good man",re.M))
Output

匹配多个字符

e.g.
import re
print(re.findall(r"(man)","You bully man"))
print(re.findall(r"a?","aaa")) #非贪婪匹配
print(re.findall(r"a*","aaa")) #贪婪匹配
print(re.findall(r".*","aaabaa")) #贪婪匹配
print(re.findall(r"a+","aabaaaa")) #贪婪匹配
print(re.findall(r"a+","aba"))
print(re.findall(r"ab{3}","aabaaabaaabaaa"))
Output

特殊

e.g.
import re
print(re.findall(r"//*.*/*/", "/* part1 */ /* part */"))
//* 后面的/是转义特殊字符
print(re.findall(r"//*.*?/*/", "/* part1 */ /* part */"))
Output
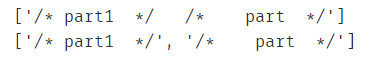
主要函数
re.match()
函数语法: re.match(pattern, string, flags=0)
函数功能:匹配成功re.match方法返回一个匹配的对象,否则返回None。
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式。详细内容 |
| re.I:忽略大小写 | |
| re.L:做本地户识别 | |
| re.M:多行匹配,影响^和$ | |
| re.s:使.匹配包括换行符在内的所有字符 | |
| re.U:根据Unicode字符集解析字符,影响\w \w \b\B |
e.g.
print(re.match("www","www.baidu.com").span())
print(re.match("www","wwwbaidu.com"))
print(re.match("www","ww.baidu.com"))
print(re.match("www","baidu.wwwcom"))
print(re.match("www","wWw.wwwcom",flags=re.I))
#扫描字符串,返回从起始位置成功的匹配,如果不是从起始位置匹配成功的话,也会返回None
Output

| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
| e.g. |
line = "Cats are smarter than dogs"
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
print(matchObj)
if matchObj:
print("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print("matchObj.group(2) : ", matchObj.group(2))
print("matchObj.group : ", matchObj.groups())
else:
print("No match!!")
Output

re.search()
函数语法:re.search(pattern, string, flags=0)
函数功能:扫描整个字符串并返回第一个成功的匹配。
参数描述同上。
e.g.
import re
print(re.search("sunck","good man is sunck!sunck is nice"))
print(re.search("sunck","good man is Sunck!sunck is nice"))
print(re.search("sunck","good man is Sunck!sunck is nice",flags=re.I))
Output

re.findall()
函数语法:re.findall(pattern, string, flags=0)
函数功能:在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
e.g.
import re
print(re.findall("sunck","good man is sunck!Sunck is nice",flags=re.I))
Output
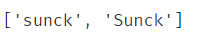
re.split()
函数语法:re.split(pattern, string[, maxsplit=0, flags=0])
函数功能:split 方法按照能够匹配的子串将字符串分割后返回列表,对于一个找不到匹配的字符串而言,split 不会对其作出分割.
e.g.
strl = "sunck is a good man"
print(re.split(r" ",strl))
print(strl.split()) #空参默认切割空格
Output

re.finditer()
函数语法:re.finditer(pattern, string, flags=0)
函数功能:和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
e.g.
str3="sunck is a good man!sunck is a nice man!sunck is a handsome man"
d=re.finditer(r"(sunck)",str3)
while True:
try:
i=next(d)
print(i)
print(i.group())
except StopIteration as e:
break
Output

re.sub()
函数语法:re.sub(pattern, repl, string, count=0, flags=0)
函数功能:用于替换字符串中的匹配项。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认
0 表示替换所有的匹配。 - flags : 编译时用的匹配模式,数字形式。
e.g.
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r'#.*$', "", phone)
print ("电话号码 : ", num)
# 移除非数字的内容
num = re.sub(r'\D', "", phone)
print ("电话号码 : ", num)
Output

当repl参数为函数时:
e.g.
# 将匹配的数字乘于 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))
Output : A46G8HFD1134
re.compile()
函数语法:re.compile(pattern[, flags])
函数功能:编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
e.g.
>>>import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print( m ) # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
练习
Task1
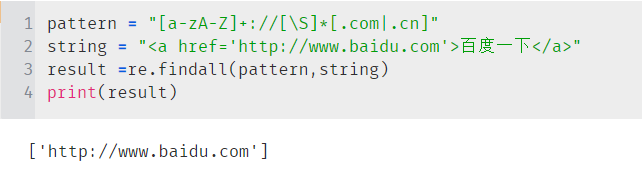
将一串字符串里面以.com或.cn为域名后缀的URL网址匹配出来,过滤掉其他的无关信息。
Task2
将一串字符串里面出现的电话号码信息提取出来,过滤掉其他无关信息。(不懂是哪里的电话格式)

Task3

