
python 全栈开发,Day28(复习,os模块,导入模块import和from)
一、复习
collections
增加了一些扩展数据类型 :namedtuple orderdict defaltdict
队列和栈
time 时间
三种格式 : 时间戳 结构化 字符串
random
随机数 打乱顺序
sys
和python解释器交互的:
path 导入模块的时候 从这个路径中获取
argv 以脚本的形式执行一个文件的时候,可以加一些参数
import sys
print(sys.argv) #['xx.py','alex','sb']
学习方法:
先把老师的代码敲一遍,并把代码逐一注释
再开一个新文件,根据注释,还原代码
昨日作业讲解:
y-m-d h:M:S 比如2017-07-08 10:23:41 从当前时间开始 比起y-m-d h:M:S过去了多少年 多少月 多少天 多少小时,多少分,多少秒
步骤分解
当前的时间 时间戳
过去的时间 转成时间戳
时间戳相减
相减之后的结果转成结构化时间
结构化时间 - 1970.1.1 0:0:0 #英国时间
先来解释一下结构化时间,有2种方式,分别是
import time
struct_time = time.localtime(0)
ret = time.strftime('%Y-%m-%d %H:%M:%S',struct_time)
print(ret) # 中国结构化时间
struct_time = time.gmtime(0)
ret = time.strftime('%Y-%m-%d %H:%M:%S',struct_time)
print(ret) # 英国结构化时间
执行输出:
1970-01-01 08:00:00
1970-01-01 00:00:00
那么为什么要用英国时间呢?
因为英国时间的时分秒都是0,没有数字比0更小了。
但如果用中国时间,那么比8小的数字,就会出现负数,比如7:30
所以说,用英国时间,是最准确的。由于时分秒都是0,所以不需要相减
import time
def cal_time(fmt_time,fmt):
now = time.time()
time_before = time.mktime(time.strptime(fmt_time,fmt))
sub_time = now - time_before
struct_time = time.gmtime(sub_time)
return '过去了%d年%d月%d天%d小时%d分钟%d秒' % \
(struct_time.tm_year - 1970, struct_time.tm_mon - 1,
struct_time.tm_mday - 1, struct_time.tm_hour,
struct_time.tm_min, struct_time.tm_sec)
ret = cal_time('2018-4-23 10:30:20','%Y-%m-%d %H:%M:%S')
print(ret)
执行输出:
过去了0年0月2天4小时20分钟51秒
要求 生成随机验证码
基础需求: 6位数字验证码 数字可以重复
进阶需求: 字母+数字 4位验证码 数字字母都可以重复
这是一道面试题
完成第一个基础需求
import random
def id_code(num):
ret = '' # 定义空字符串
for i in range(num):
n = random.randint(0,9) # 数字由0~9组成
ret += str(n) # 将数字转换为字符串,并拼接
return ret
print(id_code(6))
执行输出:
803296
完成进阶需求
有一个难点,如果获取所有的大小写字母,全手写一遍?太Low了
这个时候,就需要用到ascii码。
import random
def id_code(num): # num 大写字母 小写字母在每一位被取到的概率相同
ret = ''
for i in range(num):
number = str(random.randint(0,9)) # 所有数字
alph_num = random.randint(97,122) # a97 z122 +25 所有小写字母
alph_num2 = random.randint(65,90) # A65 Z97 +25 所有大写字母
alph = chr(alph_num) # 大写
alph2 = chr(alph_num2) # 小写
choice = random.choice([number,alph,alph2]) # 数字,大写,小写。每种是1/3的几率
ret += choice # 组合字符串
return ret
print(id_code(6)) # 取6位
执行输出:
01J98C
额外一个需求,字母和数字,取50%的概率
import random
def id_code(num): # num 大写字母 小写字母在每一位被取到的概率相同
ret = ''
for i in range(num):
number = str(random.randint(0,9)) # 所有数字
alph_num = random.randint(97,122) # a97 z122 +25 所有小写字母
alph_num2 = random.randint(65,90) # A65 Z97 +25 所有大写字母
alph = chr(alph_num) # 大写
alph2 = chr(alph_num2) # 小写
choice = random.choice([alph, alph2]) # 字母大小写,取50%的概率
choice = random.choice([number,choice]) # 数字和字母,取50%的概率
ret += choice # 组合字符串
return ret
print(id_code(6)) # 取6位
执行输出:
Q4I17t
二、os模块
os模块是与操作系统交互的一个接口
当前执行的这个python文件目录相关的工作路径
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
和文件夹相关的
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
和文件相关的
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
和操作系统差异相关的
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
和执行系统命名相关的
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
和环境变量相关的
os.environ 获取系统环境变量
和操作系统路径相关的os.path
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。
即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
注意:os.stat('path/filename') 获取文件/目录信息 的结构说明
stat 结构: st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
举例:
获取当前工作目录,即当前python脚本工作的目录路径
import os print(os.getcwd())
执行输出:
E:\python_script\day26
改变当前脚本工作目录;相当于shell下cd
注意:文件不会移动,只是内存的值改变了
import os
print(os.getcwd())
os.chdir("D:\\")
print(os.getcwd())
执行输出:
E:\python_script\day26
D:\
返回当前目录: ('.')
import os print(os.curdir)
执行输出: .
返回结果是一个点,表示当前路径
获取当前目录的父目录字符串名:('..')
import os print(os.pardir)
执行输出: ..
返回结果是2个点,表示上一级目录
在linux里面,每一个文件夹,使用ls -l 时,会出现点和点点
生成单级目录;相当于shell中mkdir dirname
import os
os.mkdir('dirname/son_dir')
如果文件不存在,就报错:
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'dirname/son_dir'
可生成多层递归目录
import os
os.makedirs('dirname/son_dir')
执行程序,就会发现多了一个目录dirname\son_dir
如果文件不存在,会自动创建。
删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
import os
os.rmdir('dirname/son_dir')
执行程序,就会发现dirname目录下的son_dir文件夹,不存在了。
若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
在dirname目录下创建a目录,a目录下再创建c目录,c目录下再创建d目录
import os
os.removedirs('dirname/a/b/c/d')
执行程序
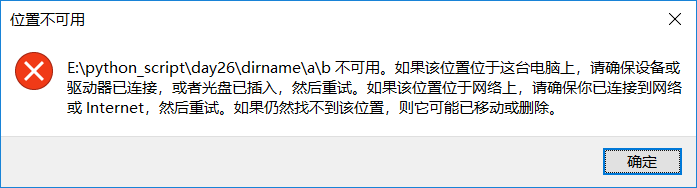
可以发现,连dirname也被删除掉了
列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
import os
print(os.listdir('E:\python_script\day26'))
执行输出:
['example.ini', 'file1', 'file2', 'new2.ini', 'test.log', 'test.py', 'userinfo.log', '随机码.py']
获取文件/目录信息 的结构说明
import os print(os.stat(r'E:\python_script\day26\new2.ini'))
执行输出:

Pycharm小技巧:
当输出的内容,一行显示过长时。可以按左边红色方框的按钮,它会自动换行显示。
r'E:\python_script\day26\new2.ini' 前面的r表示转义
'r'是防止字符转义的 如果路径中出现'\t'的话 不加r的话\t就会被转义 而加了'r'之后'\t'就能保留原有的样子
否则执行报错
输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
print(os.name)
执行输出:nt
import os
if os.name == 'nt':
path = 'python\\2.mok.py' # windows文件路径,加双斜杠
elif os.name == 'posix':
path = 'python/2.mok.py'
print(path)
windows执行输出:
python\2.mok.py
优化代码:
path = 'python%s2.mok.py'%os.sep print(path)
windows执行输出:
python\2.mok.py
os.system
运行shell命令,直接显示
test.py代码如下:
import os
print(os.system("dir")) # windows显示目录中的文件和子目录列表
执行程序,显示乱码

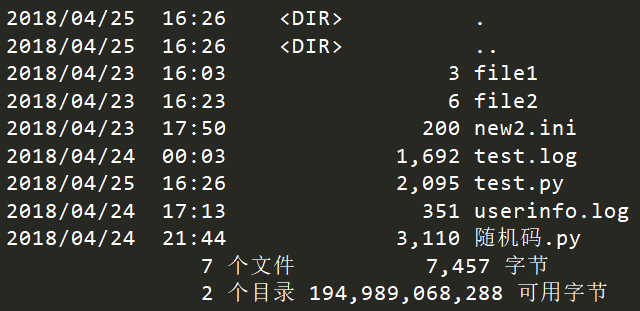
os.popen运行shell命令,获取执行结果
修改test.py文件,内容如下:
import os
print(os.popen("dir").read())
执行程序:
获取系统环境变量
import os print(os.environ)
执行输出:
environ({'COMMONPROGRAMW6432': 'C:\\Program Files\\Common Files', 'LOGONSERVER':
...
重点要掌握的,有以下这些:
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
path系列
返回path规范化的绝对路径
import os
print(os.path.abspath('test.log'))
执行输出:
E:\python_script\day26\test.log
将path分割成目录和文件名二元组返回
import os
print(os.path.split(os.path.abspath('test.log')))
执行输出:
('E:\\python_script\\day26', 'test.log')
返回path的目录。其实就是os.path.split(path)的第一个元素
import os
print(os.path.dirname(os.path.abspath('test.log')))
执行输出:
E:\python_script\day26
返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。
即os.path.split(path)的第二个元素
import os
print(os.path.basename(os.path.abspath('test.log')))
执行输出:
test.log
如果path存在,返回True;如果path不存在,返回False
import os print(os.path.exists(r'E:\python_script\day26\test.log'))
执行输出: True
如果path是绝对路径,返回True
import os print(os.path.isabs(r'E:\python_script\day26\test.log'))
执行输出: True
如果path是一个存在的文件,返回True。否则返回False
import os print(os.path.isfile(r'E:\python_script\day26\test.log'))
执行输出: True
如果path是一个存在的目录,则返回True。否则返回False
import os print(os.path.isdir(r'E:\python_script\day26\test.log'))
执行输出:
False
将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
import os print(os.path.join(r'E:\python_script\day26','test.log'))
执行输出:
E:\python_script\day26\test.log
返回path所指向的文件或者目录的最后访问时间
import os print(os.path.getatime(r'E:\python_script\day26\test.log'))
执行输出:
1524498744.3853774
返回path所指向的文件或者目录的最后修改时间
import os print(os.path.getmtime(r'E:\python_script\day26\test.log'))
执行输出:
1524499380.404139
返回path的大小
import os print(os.path.getsize(r'E:\python_script\day26'))
执行输出:
4096
用getsize 统计文件夹小大,是不准的,windows永远是4096
统计文件是准确的
import os print(os.path.getsize(r'E:\python_script\day26\test.log'))
执行输出:
1692
三、导入模块import和from
1. 什么是模块?
一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
2. 为何要使用模块?
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script
3.如何使用模块?
import
示例文件:自定义模块my_module.py,文件名my_module.py,模块名my_module
my_module.py文件内容如下:
print('from the my_module.py')
demo.py文件内容如下:
import my_module
为什么这段代码,Pycharm会飘红呢?

因为我的Pycharm的工作目录为E:\python_script
而代码所在的目录为E:\python_script\day26
在工作目录下面,找不到my_module文件,所以报错
为了解决这个,需要点击file->open 选择文件夹为E:\python_script\day26
点击Open in current windows->ok
在新窗口中,点击deme.py文件,就不会飘红了。
执行demo.py文件
程序输出:
from the my_module.py
what ?为什么执行了?
导入一个模块,相当于这个模块从上到下依次被执行了
一个模块,会不会被多次导入呢?
修改demo.py文件,内容如下:
import my_module import my_module import my_module
执行输出:
from the my_module.py
说明只导入了一次
同一个模块不会被多次导入
总结:
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句)
我们可以从sys.modules中找到当前已经加载的模块,sys.modules是一个字典,内部包含模块名与模块对象的映射,该字典决定了导入模块时是否需要重新导入。
修改my_module.py,内容如下:
print('from the my_module.py')
def func():
print('in func')
那demo.py如何调用呢?修改demo.py文件
import my_module my_module.func() # 执行函数
执行输出:
from the my_module.py
in func
import 的 过程
import一个模块的时候,首先创建一个属于my_module的内存空间
加载my_module模块中所有的代码
将my_module模块中的名字方法放在my_module的命名空间里
my_module.py增加一个变量,修改文件,内容如下:
print('from the my_module.py')
money = 100
def func1():
print('in func')
def func2():
print('in func2')
修改demo.py,调用func2和money
import my_module my_module.func2() print(my_module.money)
执行输出:
from the my_module.py
in func
100
demo.py里面也创建一个func1和money
那么调用时,它会调用谁呢?
import my_module
money = 200
def func1(): # func1函数名不冲突
print('in my func1')
my_module.func1() # 执行my_module模块中的func1函数
func1() # 执行当前模块中的func1函数
print(money)
执行输出:
from the my_module.py
in func
in my func1
200
从结果中,可以看出,函数func1调用的是当前模块中的。
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突
总结:首次导入模块my_module时会做三件事:
1.为源文件(my_module模块)创建新的名称空间,在my_module中定义的函数和方法若是使用到了global时访问的就是这个名称空间。
2.在新创建的命名空间中执行模块中包含的代码,见初始导入import my_module
提示:导入模块时到底执行了什么? In fact function definitions are also ‘statements’ that are ‘executed’; the execution of a module-level function definition enters the function name in the module’s global symbol table. 事实上函数定义也是“被执行”的语句,模块级别函数定义的执行将函数名放入模块全局名称空间表,用globals()可以查看
3.创建名字my_module来引用该命名空间
这个名字和变量名没什么区别,都是‘第一类的’,且使用my_module.名字的方式可以访问my_module.py文件中定义的名字,my_module.名字与test.py中的名字来自两个完全不同的地方。
为模块名起别名,相当于m1=1;m2=m1
相当于内存名改名了,原来的名字就不能用了
import my_module as mm print(mm.money) print(my_module.money) # 这里就不能用my_module
执行输出:
from the my_module.py
100
为什么要起别名呢?
1.模块名太长的可以起别名
2.有特殊需求
现在有一个需求,用户可以选择json或者pickle
import pickle
import json
inp = input('json or pickle>>> ').split()
if inp == 'json':
json.dumps({'k':'v'})
elif inp == 'pickle':
pickle.dumps({'k':'v'})
那么问题来了,有多处调用
代码都复制一遍?太low了
改用别名的方式:
inp = input('json or pickle>>> ').strip()
if inp == 'json':
import json as m
elif inp == 'pickle':
import pickle as m
else:
print('未定义!')
a = m.dumps({'k':'v'})
print(a)
执行输出:
json or pickle>>> json
{"k": "v"}
这样看来,代码就精简了
还有一个场景,数据库方面的
有两中sql模块mysql和oracle,根据用户的输入,选择不同的sql功能
#mysql.py
def sqlparse():
print('from mysql sqlparse')
#oracle.py
def sqlparse():
print('from oracle sqlparse')
#test.py
db_type=input('>>: ')
if db_type == 'mysql':
import mysql as db
elif db_type == 'oracle':
import oracle as db
db.sqlparse()
在一行导入多个模块
import os,sys,time
可以这么写,但是不推荐,一行导入多个模块
根据PEP8规范,不建议一行多个模块
一个缩进是4个空格
推荐一行一个模块
import os import sys import time
总结:
<strong>PEP8
每一行import 应该导入一个模块
如果不是必要的需求,所有的模块都应该在文件的顶端导入
关于导入模块的顺序 先导入内置的 再导入扩展 最后导入自定义
import
导入模块: 模块的名字要符合变量的定义规范
不要起你知道的内置的名字的模块
模块不会被多次导入
导入模块相当于
开辟了一个新的空间
执行被导入模块中的代码
创建一个模块名作为这块空间的引用
导入的模块中的名字和全局文件中的名字不会冲突
import 。。。 as 。。。
导入多个模块 import a,b,c
PEP8规范
每一行import 应该导入一个模块
如果不是必要的需求,所有的模块都应该在文件的顶端导入
关于导入模块的顺序 先导入内置的 再导入扩展 最后导入自定义
</strong>
from ... import...
从my_module导入money变量
修改demo.py,内容如下:
from my_module import money
执行输出:
from the my_module.py
为啥会输出上面那段话呢?
因为代码是从上向下执行,from也是把代码执行完了
获取my_module模块中的money变量
修改demo.py,内容如下:
from my_module import money print(money)
执行输出:
from the my_module.py
100
添加同名的变量money
修改demo.py,内容如下:
from my_module import money print(money) money = 20 print(money)
执行输出:
from the my_module.py
100
20
说明,如果当前有重名,变量会覆盖
增加同名的func1,改变代码位置:
def func1():
print('in demo')
from my_module import money
func1()
执行输出:
from the my_module.py
in demo
对比import my_module,会将源文件的名称空间'my_module'带到当前名称空间中,使用时必须是my_module.名字的方式
而from 语句相当于import,也会创建新的名称空间,但是将my_module中的名字直接导入到当前的名称空间中,在当前名称空间中,直接使用名字就可以了
总结:
导入模块的时候 sys.modules import
使用变量的时候看的是命名空间 globals()
导入多个
修改demo.py
from my_module import func1,func2 func1() func2()
执行输出:
from the my_module.py
in func
in func2
尽管导入的func1,func2都属于全局的变量了,
但是使用func2的时候要用到的变量仍然是局部的
my_module和 demo 是2个内存空间
my_module不能引用demo的变量
from 也支持as
from my_module import func1 as func
用户可以选择算法:
修改my_module.py的代码
def func1():
print('sha')
def func2():
print('sha256')
def func3():
print('md5')
修改demo.py,内容如下:
from my_module import func1,func2,func3
inp = input('sha or sha2 or md5>>>')
if inp == 'sha':
from my_module import func1 as func
elif inp == 'sha2':
from my_module import func2 as func
elif inp == 'md5':
from my_module import func3 as func
func()
执行输出:
sha or sha2 or md5>>>sha2
sha256
也支持导入多行
from my_module import (read1,
read2,
money)
导入所有
from my_module import *
修改my_module.py
class A:pass
a = 1
def func1():
print('sha')
def func2():
print('sha256')
def func3():
print('md5')
修改demo.py
from my_module import * print(a) print(A) print(func1)
执行输出:
1
<class 'my_module.A'>
<function func1 at 0x0000023EC8749950>
看下面的图
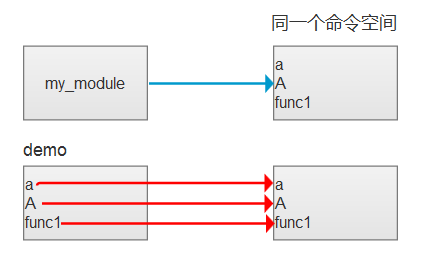
在my_module,里面维护了变量a,A,func1
在demo里面,也有a,A,func1。但是它实际对应的值,是my_module里面的a,A,func1
在my_module.py中新增一行
这样在另外一个文件中用from my_module import *就这能导入列表中规定的两个名字
修改my_module.py文件,内容如下:
__all__=['a','A']
class A:pass
a = 1
def func1():
print('sha')
def func2():
print('sha256')
def func3():
print('md5')
再次执行demo.py就会报错
NameError: name 'func1' is not defined
因为func被约束了。__all__只能约束*,其他的不能约束
比如
from my_module import func1
总结:
from ... import ...
from 模块名 import 名字
导入的名字直接属于全局,但是指向模块的名字所在的内存空间
导入的名字如果是函数或者方法,引用了全局的变量,
仍然使用模块中的变量
导入的名字和全局的名字是一样的,谁最后抢占到就是谁的
可以导入多个名字,用逗号分割
还可以起别名 as
from 模块 import * 那么默认会把模块中所有名字都导入到全局
* 和 __all__
今日作业:
作业1:计算文件夹中所所有文件的大小 作业2: 思考:假如有两个模块a,b。 我可不可以在a模块中import b ,再在b模块中import a?
答案:
1.
import os
def visitDir(path):
if not os.path.isdir(path): # 判断是否为目录
print('Error: "', path, '" is not a directory or does not exist.')
return
else:
global x # 设置全局变量
try:
for lists in os.listdir(path): # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
sub_path = os.path.join(path, lists) # 将多个路径组合为文件名
file_size = os.path.getsize(sub_path) # 文件大小
x += 1 # 计算器加1
print('No.{}\t{}\t{}字节'.format(x,sub_path,file_size)) # 输出文件列表
if os.path.isdir(sub_path): # 判断路径是否为目录
visitDir(sub_path) # 调用自身
except:
pass
if __name__ == '__main__':
x = 0 # 计数器初始值
path = r"E:\python_script\day26\test"
visitDir(path) # 执行函数
print('Total Permission Files: ', x) # 输出文件个数
执行输出:
No.1 E:\python_script\day26\test\a 0字节 No.2 E:\python_script\day26\test\a\b 0字节 No.3 E:\python_script\day26\test\a\b\meow.rar 5241字节 No.4 E:\python_script\day26\test\a\b\openvpn-2.4.4.tar.gz 1390194字节 No.5 E:\python_script\day26\test\a\b\Shadow-win-2.5.zip 186030字节 No.6 E:\python_script\day26\test\a\meow.rar 5241字节 No.7 E:\python_script\day26\test\a\openvpn-2.4.4.tar.gz 1390194字节 No.8 E:\python_script\day26\test\a\Shadow-win-2.5.zip 186030字节 No.9 E:\python_script\day26\test\fds 0字节 No.10 E:\python_script\day26\test\fds\232 0字节 No.11 E:\python_script\day26\test\fds\232\新建 Microsoft PowerPoint 演示文稿.pptx 0字节 No.12 E:\python_script\day26\test\fds\Shadow-win-2.5.zip 186030字节 No.13 E:\python_script\day26\test\meow.rar 5241字节 No.14 E:\python_script\day26\test\openvpn-2.4.4.tar.gz 1390194字节 No.15 E:\python_script\day26\test\Shadow-win-2.5.zip 186030字节 Total Permission Files: 15

