
python 全栈开发,Day15(递归函数,二分查找法)
一、递归函数
江湖上流传这这样一句话叫做:人理解循环,神理解递归。所以你可别小看了递归函数,很多人被拦在大神的门槛外这么多年,就是因为没能领悟递归的真谛。
递归函数:在一个函数里执行再调用这个函数本身。
递归的默认最大深度:998
举例,先来一个死循环
def func1():
print(666)
while True:
func1()
执行输出:
666
...
递归函数
def func1():
print(666)
func1()
func1()
执行输出:
666
...
RecursionError: maximum recursion depth exceeded while calling a Python object
那么它是执行到多少次时,报错呢?
加一个计数器
count = 0
def func1():
global count
count += 1
print(count)
func1()
func1()
执行输出:
1
...
998
...
RecursionError: maximum recursion depth exceeded while calling a Python object
说明默认递归深度为998
这个递归深度是可以改的
import sys
#更改默认递归深度
sys.setrecursionlimit(100000)
count = 0
def func1():
global count
count += 1
print(count)
func1()
func1()
执行输出:
...
3807
我的wind10系统,深度只能到这么多
至于实际可以达到的深度就取决于计算机的性能了
linux系统,深度能够达到更深。比如说1000万,我开虚拟机测试的。
不过我们还是不推荐修改这个默认的递归深度,因为如果用997层递归都没有解决的问题要么是不适合使用递归来解决要么是你代码写的太烂了
举个例子来说明递归能做的事情
现在你们问我,alex老师多大了?我说我不告诉你,但alex比 egon 大两岁。
你想知道alex多大,你是不是还得去问egon?egon说,我也不告诉你,但我比武sir大两岁。
你又问武sir,武sir也不告诉你,他说他比太白大两岁。
那你问太白,太白告诉你,他18了。
这个时候你是不是就知道了?alex多大?
1 金鑫 18
2 武sir 20
3 egon 22
4 alex 24
你为什么能知道的?
首先,你是不是问alex的年龄,结果又找到egon、武sir、太白,你挨个儿问过去,一直到拿到一个确切的答案,然后顺着这条线再找回来,才得到最终alex的年龄。这个过程已经非常接近递归的思想。我们就来具体的我分析一下,这几个人之间的规律。
age(4) = age(3) + 2 age(3) = age(2) + 2 age(2) = age(1) + 2 age(1) = 40
那这样的情况,我们的函数怎么写呢?
def age(n):
if n == 1:
return 40
else:
return age(n-1)+2
print(age(4))
执行输出: 24
二、二分查找法
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列
算法有很多种,比如:二分查找,树运算,堆,栈....
使用二分查找的前提
数据是有序且唯一的数字数列
举例:
有一个列表,需要查找出索引为66的值
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
第一种方法: 直接使用index查询
print(l.index(66))
执行输出:17
第二种方法: 使用for循环
count = 0
for i in l:
if i == 66:
print(count)
break
count += 1
执行输出,效果同上
假如我们这个列表特别长,里面好好几十万个数,效率太低了
需要使用二分查找算法
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
你观察这个列表,这是不是一个从小到大排序的有序列表呀?
如果这样,假如我要找的数比列表中间的数还大,是不是我直接在列表的后半边找就行了?
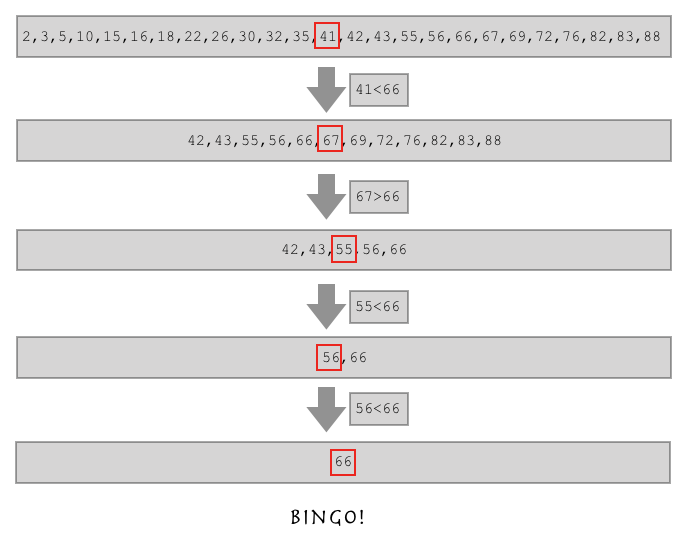
这就是二分查找算法!
那么落实到代码上我们应该怎么实现呢?
简单版二分法
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
def func(l,aim):
mid = (len(l)-1)//2
if l:
if aim > l[mid]:
func(l[mid+1:],aim)
elif aim < l[mid]:
func(l[:mid],aim)
elif aim == l[mid]:
print("bingo",mid)
else:
print('找不到')
func(l,66)
func(l,6)
执行输出:
bingo 0
找不到
升级版二分法
把列表改短一点
li = [2, 3, 5, 10, 15, 33, 55]
def two_search(li, aim, start=0, end=None):
end = len(li) if end is None else end
mid_index = (end - start) // 2 + start # 3
if start <= end:
if li[mid_index] < aim:
return two_search(li, aim, start=mid_index+1, end=end)
elif li[mid_index] > aim:
return two_search(li, aim, start=start, end=mid_index-1) #([2,3,5],3)
elif li[mid_index] == aim:
return mid_index
else:
return '没有此值'
else:
return '没有此值'
print(two_search(li,15))
执行输出:
4
加日志执行:
li = [2, 3, 5, 10, 15, 33, 55]
count = 0
def two_search(li, aim, start=0, end=None):
global count
count += 1
end = len(li)-1 if end is None else end #结束索引值,len(li)要减1,否则如果传100,函数无法结束。
mid_index = (end - start) // 2 + start #中间索引
#加日志
print('第{}执行,start的值为{},end的值为{},mid_index的值为{},li[mid_index]的值为{}'.format(count, start,end,mid_index,li[mid_index]))
if start <= end:
if li[mid_index] < aim:
return two_search(li, aim, start=mid_index+1, end=end)
elif li[mid_index] > aim:
return two_search(li, aim, start=start, end=mid_index-1) #([2,3,5],3)
elif li[mid_index] == aim:
return mid_index
else:
return '没有此值'
else:
return '没有此值'
print(two_search(li,15))
执行输出:
第1执行,start的值为0,end的值为6,mid_index的值为3,li[mid_index]的值为10
第2执行,start的值为4,end的值为6,mid_index的值为5,li[mid_index]的值为33
第3执行,start的值为4,end的值为4,mid_index的值为4,li[mid_index]的值为15
4
解释:
先来解释一下中间索引 // 表示取整除 - 返回商的整数部分 ,比如9//2 输出结果 4
列表有7个元素,第一次,执行时,start为0,(end - start) // 2 + start 等于(6-0)//2 + 0 mid_index的值为3,li[mid_index]的值为10
那么为什么mid_index的等式,后面要加start呢?
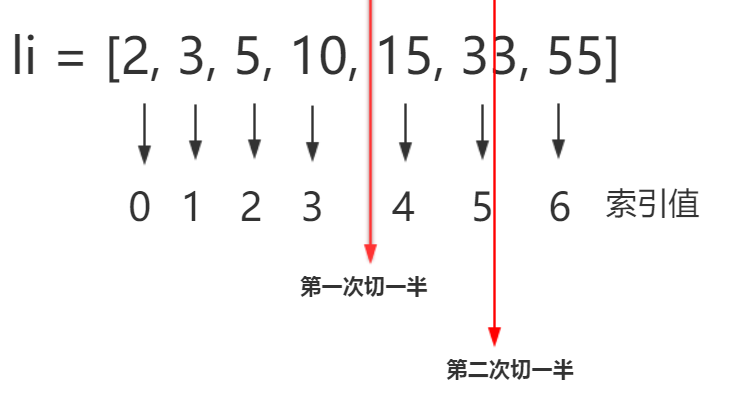
第一次执行时,中间索引值,取3
第二次执行时,中间索引值,取5
如果不加start,那么第二只还是取的是3
第一次执行时,li[mid_index]的值为10,aim的值为15,进入if判断,走第一个if条件
因为找到的中间值比目标值要小,所以start要在mid_index的基础上加1
通俗的来讲,劈一半,左边找的值太小,就找右边,所以要加1
第二次执行时,li[mid_index]的值为33,aim的值为15,进入if判断,走第二个if条件
因为找到的中间值比目标值要大,start依然不变,end要在mid_index的基础上减1
通俗的来讲,再劈一半,左边找的值太大,就继续找左边的,所以要减1
第三次执行时,li[mid_index]的值为15,aim的值为15,进入if判断,走第三个if条件
已经找到目标值了,直接return mid_index 结束整个函数

