


面试题整理
1.java跨平台的原理
具有平台无关性
Java是“一次编写,到处运行(Write Once,Run any Where)"的语言,因此采用Java语言编写的程序具有很好的可移植性,而保证这一点的正是Java的虚拟机机制。在引入虚拟机之后,Java语言在不同的平台上运行不需要重新编译。
Java跨平台原理
由源文件(.java)—>字节码文件(.class)(二进制文件)-----> 解释---->Unix,Win,Linux等机器。
1.一次编译,到处运行
2.编译器的作用:将源文件编译成class文件
3.虚拟机的作用:将字节码文件解释成对应平台机器码并执行。
4.java可以实现跨所有的平台?只有提供并且安装了相对应的虚拟机就可以跨该平台。
5.虚拟机和解释器的关系:解释器是虚拟机的一个重要的组成部分。
6.Java语言的执行要经过编译和解释两个阶段。
2.数据类型
包括基本数据类型和引用数据类型
整型:
byte 1个字节 二进制位8位 00000001 -128~127 1byte = 8bit 默认值:0
short 2个字节 二进制位16位 是int的二分之一
int 4个字节 二进制位32位
long 8个字节 二进制位64位 long l1 = 10L;
字符型:
char 1个字节 c = 'a';
浮点型:
float 4个字节 f1 = 1.1f; //单精度
double 8个字节 d1 = 2.2; //双精度
布尔型:
boolean 1个字节 b2 = true;

3.java中标识价格BigDecimal
1.不论是float 还是double都是浮点数,而计算机是二进制的,浮点数会失去一定的精确度。
2.Java在java.math包中提供的API类BigDecimal,用来对超过16位有效位的数进行精确的运算。双精度浮点型变量double可以处理16位有效数。在实际应用中,需要对更大或者更小的数进行运算和处理。
4.双精度&单精度
1.单精度和双精度精确的范围不一样
2.单精度,一般在计算机中存储占用4字节,也就是32位,有效位数为7位;
3.双精度〈double〉在计算机中存储占用8字节,64位,有效位数为16位。
4.单精度在一些处理器上比双精度更快而且只占用双精度一半的空间.
5.但是当值很大或很小的时候.它将变得不精确。当你需要小数部分并且对精度的要求不高时,单精度浮点型的变量是有用的。

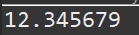
单精度是这样的格式,1位符号,8位指数,23位小数。

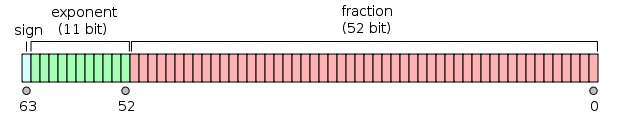
双精度是这样的格式,1位符号,11位指数,52位小数。
单精度数的尾数用23位存储,加上默认的小数点前的1位1,2^(23+1) = 16777216。因为 10^7 < 16777216 < 10^8,所以说单精度浮点数的有效位数是7位。
双精度的尾数用52位存储,2^(52+1) = 9007199254740992,10^16 < 9007199254740992 < 10^17,所以双精度的有效位数是16位。
5.面向对象三大特征(封装,继承,多态)
封装。也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
继承。它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。通过继承创建的新类称为“子类"或"派生类",被继承的类称为“基类"、“父类"或“超类"。
多态。它是指在父类中定义的属性和方法被子类继承之后,可以具有不同的数据类型或表现出不同的行为,这使得同一个属性或方法在父类及其各个子类中具有不同的含义。
6.装箱&拆箱
Java为每一个基本数据类型都引入了对应的包装类型,从Java 5开始引入了自动装箱/拆箱机制,把基本类型转换成包装类型的过程叫做装箱;反之,把包装类型转换成基本类型的过程叫做拆箱,使得二者可以相互转换。
1.包装类型可以为null,而基本类型不可以。
2.包装类型可用于泛型,而基本类型不可以。
3.基本类型比包装类型更高效。基本类型在栈中直接存储的具体数值,而包装类型则存储的是堆中的引用。很显然,相比较于基本类型而言,包装类型需要占用更多的内存空间。
6.1自动装箱:将基本数据类型重新转化为对象
自动拆箱:将对象重新转化为基本数据类型
6.2int和Integer有什么区别?
- Integer是int的包装类;int是基本数据类型;
- Integer变量必须实例化后才能使用; int变量不需要;
- Integer实际是对象的引用,指向此new的Integer对象;int是直接存储数据值;
- Integer的默认值是null; int的默认值是0。
7.子类继承父类,子类必须能够访问到父类的构造方法,protected肯定能访问到
8.Integer缓存的实现
- 为了节省内存和提高性能,Integer类在内部通过使用相同的对象引用实现缓存和重用,
- IntegerCache是个Integer的内部类,在类加载的时候创建了256个缓存Integer对象,范围-128至127,value相同的Integer对象是同一个对象。
- 最小值-128在一开始就设置死了,但是127是可以通过 -XX:AutoBoxCacheMax进行修改的.
9.运算符&&||和&|的区别
- 与运算(都是真才为真)包含&&(短路与)和&(不短路与)
- 或运算(一真为真)|| 表示短路或,| 表示不短路或
短路运算符左边的判断为false的时候,就不再去判断运算符右边的判断
&|是位运算符,按位与和按位或
10.==和equals的区别
- ==常用于相同的基本数据类型之间的比较,也可用于相同类型的对象之间的比较;
- equals方法主要用于两个对象之间,检测一个对象是否等于另一个对象;
- 如果==比较的是基本数据类型,那么比较的是两个基本数据类型的值是否相等;
- 如果==是比较的两个对象,那么比较的是两个对象的引用,也就是判断两个对象是否指向了同一块内存区域;
11.String str="abc"创建了几个对象?String str=new String("abc")创建了几个对象
一个,两个
1.创建了一个String对象 'abc'(1个)
2.我们可以把上面这行代码分成 String str 、= 、 "abc" 和 new String() 四部分来看待。
- String str只是定义了一个名 为str的String类型的变量,因此它并没有创建对象
- new String("abc")又能 被看成"abc"和new String()
并且 abc 字符串之前没有用过,这毫无疑问创建了两个对象
- 一个是new String 创建的一个新的对象
- 一个是常量“abc”对象的内容创建出的一个新的String对象(2个)
12.String,stringbuffer和stringbuilder的区别
1)首先String、StringBuffer、StringBuilder在JDK中都被定义为final类,这意味着他们不可以被继承。
2)String最常见,与StringBuffer相比,String的性能较差,因为对String类型进行改变的时候都会重新生成一个新的String对象,这在字符串拼接操作时很明显,因此内容经常改变的字符串不应该使用String,如果不考虑多线程,则应使用StringBuilder。
3)StringBuffer生成一个对象后,在进行字符串拼接操作时,调用append方法即可,不会产生新的对象,仅对对象本身进行操作,性能比String要高。另外StringBuffer是线程安全的,因此适合在多线程中使用,也正因为如此,速度跟StringBuilder相比会比较慢。
4)StringBuilder的使用方法跟StringBuffer类似,但其是非线程安全的,因此一般常用于单线程,效率比StringBuffer高。
13.String 类可以被继承吗?为什么?为什么String类要设计为不可被继承的
java中不可以继承String类. 因为String类有final修饰符,而final修饰的类是不能被继承的。
String 使用final修饰的主要原因:
由于专String类被final修饰不能被继承,所以就不能修改,这就避免了因继承而引起的安全隐患。
由于String类在程序中使用毕竟频属繁, 设置为final可以提高执行效率
14.实现一个拷贝文件夹的方法,使用字节流还是字符流
这里我们要考虑我们的文件是字符类型的,还是字节类型的:
字符类型一般包括:word、txt、文本类型。
字节类型一般包括:图片、声音、图像等。
因为一般字符流最终都要转换成字节流,所以为考虑到通用性,要用字节流。
15.数据库的分类和常见的数据库你知道那些?
根据数据库的架构和数据组织原理进行分类
1、早期根据数据库的组织数据的存储模型分类
●层次数据库:基于层次的数据结构(数据分层)
●网状数据库:基于网状的数据结构(数据网络)
●关系数据库:基于关系模型的数据结构(二维表)
2、现在较多根据实际数据管理模型分类(存储介质)
●关系型数据库:基于关系模型的数据结构(二维表)通常存储在磁盘
●非关系型数据库:没有具体模型的数据结构(键值对)通常存储在内存
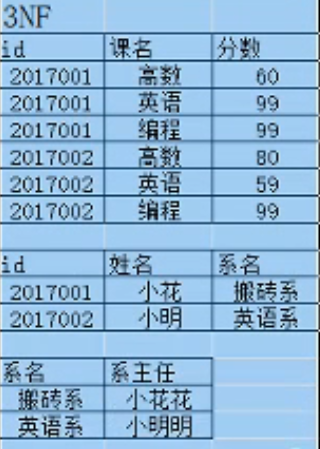
16.介绍一下三范式,设计表时一定要追求三范式吗?
- 第一范式(列不可分):强调的是列的原子性,即数据库表的每一列都是不可分割的原子数据项.
- 第二范式(不能部分依赖):要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性。
- 第三范式(不能传递依赖):任何非主属性不依赖于其它非主属性。
要满足第三范式必须先满足第二范式,要想满足第二范式必须先满足第一范式.
第三范式的好处就是:1.数据不会有冗余 2.做更新操作只需要单表操作。
但也不一定必须追求第三范式:
比如:用户信息表(id,gid,gname) 国家城市表(gid,gname) 这里的用户信息表按照一般思维,是只存gid就行了,但是为什么还存gname呢?
优点如下:
1.国家地区表 基本上不会有变化,所以把gname存在用户信息表
2.在查询的时候不用再次关联查到地区名称了,少一次关联查询,性能提升不少。

17.java中什么是序列化和反序列化?
Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是指把字节序列恢复为Java对象的过程:
序列化:序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中。核心作用是对象状态的保存与重建。我们都知道,Java对象是保存在JVM的堆内存中的,也就是说,如果JVM堆不存在了,那么对象也就跟着消失了。
而序列化提供了一种方案,可以让你在即使JVM停机的情况下也能把对象保存下来的方案。就像我们平时用的U盘一样。把Java对象序列化成可存储或传输的形式(如二进制流),比如保存在文件中。这样,当再次需要这个对象的时候,从文件中读取出二进制流,再从二进制流中反序列化出对象。
反序列化:客户端从文件中或网络上获得序列化后的对象字节流,根据字节流中所保存的对象状态及描述信息,通过反序列化重建对象。
18.java中不想序列化的字段怎么处理?
对于不想进行序列化的变量,使用transient关键字修饰。
transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient变量的值被设为初始值,如int型的是0,对象型的是null。transient 只能修饰变量,不能修饰类和方法。
19.深拷贝&浅拷贝
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。
深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象。
20.什么 是反射?
反射是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;
对于任意一个对象,都能够调用它的任意一个方法和属性;
这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的反射机制。
21.反射常用API类
反射API用来生成JVM中的类、接口或则对象的信息。
- Class类:反射的核心类,可以获取类的属性,方法等信息。
- Field 类: Java.lang.reflec包中的类,表示类的成员变量,可以用来获取和设置类之中的属性值。
- Method类: Java.lang.reflec包中的类,表示类的方法,它可以用来获取类中的方法信息或者执行方法。
- Constructor类: Java.lang.reflec包中的类,表示类的构造方法。
22.反射的使用步骤
- 获取想要操作的类的Class对象,这是反射的核心,通过Class对象我们可以任意调用类的方法。
- 调用Class类中的方法,既就是反射的使用阶段。
- 使用反射API来操作这些信息。
23.获取Class对象的方式
1.Class.forName(“类的路径");当你知道该类的全路径名时,你可以使用该方法获取 Class类对象。
1 Class clz = Class.forName( "java.lang.String");
2.类名.class。这种方法只适合在编译前就知道操作的Class。
1 Class clz = String.class;
3.对象名.getClass()。
1 String str = new String( "Hello");
2 Class clz = str.getclass();
4.如果是基本类型的包装类,可以调用包装类的Type属性来获得该包装类的Class对象。
24.List 子类的特点
ArrayList:
底层数据结构是数组,查询快,增删慢
线程不安全, 效率较高
Vector
底层数据结构是数组,查询快,增删慢
线程安全, 效率较低
LinkedList
底层数据结构是链表,查询慢,增删快
线程不安全,效率较高
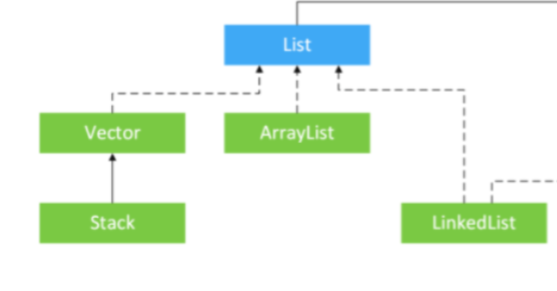
25.ArrayList ,linkedList,Vector的区别
同上
26.HashSet如何查重复
当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
hashCode()与equals()的相关规定:
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,对两个equals方法返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
- hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
==与equals的区别
- ==是判断两个变量或实例是不是指向同一个内存空间 equals是判断两个变量或实例所指向的内存空间的值是不是相同
- ==是指对内存地址进行比较 equals()是对字符串的内容进行比较
- ==指引用是否相同 equals()指的是值是否相同
27.HashMap和HashSet的区别

补充HashSet的实现: HashSet的底层其实就是HashMap,只不过我们HashSet是实现了Set接口并且把数据作为K值,而V值一直使用一个相同的虚值来保存。如源码所示:

由于HashMap的K值本身就不允许重复,并且在HashMap中如果K/V相同时,会用新的V覆盖掉旧的V,然后返回旧的V,那么在HashSet中执行这一句话始终会返回一个false,导致插入失败,这样就保证了数据的不可重复性。
28.HashMap的容量(16)
HashMap作为一种数据结构,元素在put的过程中需要进行hash运算,目的是计算出该元素存放在hashMap中的具体位置。hash运算的过程其实就是对目标元素的Key进行hashcode,再对Map的容量进行取模,而JDK 的工程师为了提升取模的效率,使用位运算代替了取模运算,这就要求Map的容量一定得是2的幂。而作为默认容量,太大和太小都不合适,所以16就作为一个比较合适的经验值被采用了。为了保证任何情况下Map的容量都是2的幂,HashMap在两个地方都做了限制。首先是,如果用户制定了初始容量,那么HashMap会计算出比该数大的第一个2的幂作为初始容量。另外,在扩容的时候,也是进行成倍的扩容,即4变成8,8变成16。
除了初始化的时候会指定HashMap的容量,在进行扩容的时候,其容量也可能会改变。HashMap有扩容机制,就是当达到扩容条件时会进行扩容。HashMap的扩容条件就是当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容。在HashMap中,threshold = loadFactor * capacity。loadFactor是装载因子,表示HashMap满的程度,默认值为0.75f,设置成0.75有一个好处,那就是0.75正好是3/4,而capacity又是2的幂。所以,两个数的乘积都是整数。对于一个默认的HashMap来说,默认情况下,当其size大于12(16*0.75)时就会触发扩容。

