文件 IO流
- 文件类File
- 相对路径
- 绝对路径
File对象既可以代表文件也可以代表文件夹
1 File file = new File("d:\\bingtu.txt");
判断文件是否存在
- exists()
1 boolean b = file.exists();
创建文件
- createNewFile()
1 file1.createNewFile();
创建文件夹
- mkdir
- mkdirs
1 //mkdir只能创建当前文件夹,如果父级目录不存在,则会创建失败 2 file2.mkdir(); 3 //mkdirs可以创建文件夹 4 file2.mkdirs();
删除文件
删除文件夹,如果文件夹里面有东西就会删除失败
- delete()
1 file2.delete();
判断是文件还是文件夹
- isFile()
- isDirectory()
1 file.isFile();//判文件 2 file.isDirectory();//判文件夹
获取子元素
- listFiles()
1 public boolean clearDir(String name) { 2 File file = new File(name); 3 if(file.exists() && file.isDirectory()) { 4 File[] arr = file.listFiles(); 5 for(File f:arr) { 6 f.delete(); 7 } 8 } 9 return true; 10 }
重命名
- renameTo()
1 file1.renameTo(new File("d:\\aaa\\txt"));
getName getPath getParent
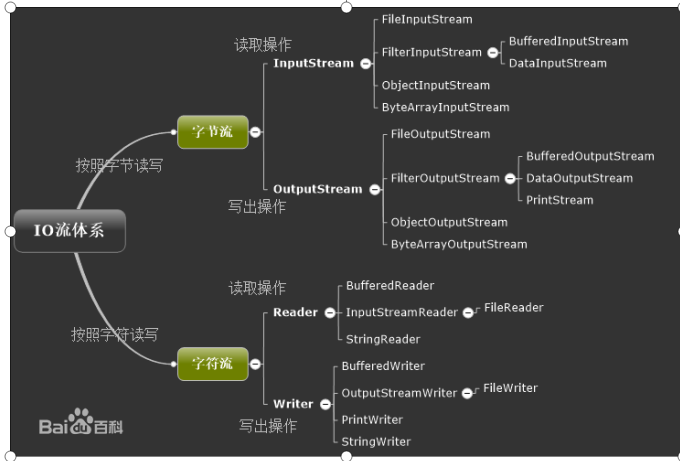
- IO
I/O , 输入流 , /输出流事项对程序来说
每次从文件中读4个字节然后打印输出.
1 FileInputStream fis =new FileInputStream("d:\\aaa\\txt1.txt");//abcdefghifk 2 byte[] arr = new byte[4]; 3 int count = 0; 4 fis.read(arr); 5 System.out.println(new String(arr));//abcd 6 fis.read(arr); 7 System.out.println(new String(arr));//edgh 8 fis.read(arr); 9 System.out.println(new String(arr));//igkh 10 fis.read(arr); 11 System.out.println(new String(arr));//igkh
声明的arr , 相当于一个小推车.大小为4,每次都从文件中装人4个字符,然后打印出来.
问题就在这里,每次装入一个新东西的时候,都会从里面拿出来一个和他进行置换.
那么,如果文件中的元素都被复制出来了呢?
例如上面的例子,我们文件中的字母到k就已经结束了,第10行的代码所以已经没什么东西在装了,打印出来的还是上一次数组中存的东西,
还有一点就是说,你看看第9行的代码,我们文件的最后一个元素时k.故上一次放在小推车里面的h并没有被置换出去.
也就是说:
1 //会出现重复的内容例如igkh 2 //abcd 3 //efgh 4 //igkh 5 while((count = fis.read(arr)) != -1) { 6 System.out.println(new String(arr)); 7 }
这里是用了一个count对他进行记录.
当read()完的时候会返回-1.
难道我们就没有什么办法了吗?
答案是否定的
请看
1 //用0把没读的覆盖掉例如igk 2 //abcd 3 //efgh 4 //igk 5 while((count = fis.read(arr)) != -1) { 6 System.out.println(new String(arr , 0 , count)); 7 }
new String(arr , 0 , count)
这句话我差了一段时间才理解的,它的方法定义是这么写的
1 String(char value[], int offset, int count)
也就是说声明了一个数组values,从offset(开端)到count(结尾)
声明了这么大的一个String
这有什么用呢,也就是说我这么写就可以每次记录count输出了几个字符,然后避免掉上次输出的元素这次还会输出的情况.
同时我还写了以下几个方法
文件的复制
1 //从src 读一个文件,写入到 dest 2 static void copy(String src , String dest) throws FileNotFoundException { 3 long l1 = System.currentTimeMillis(); 4 File f_src = new File(src); 5 File f_dest = new File(dest); 6 if(!f_src.exists()) { 7 throw new FileNotFoundException("找不到源文件"); 8 } 9 if(!f_dest.exists()) { 10 try { 11 f_dest.createNewFile(); 12 } catch (IOException e) { 13 // TODO Auto-generated catch block 14 e.printStackTrace(); 15 } 16 } 17 18 FileInputStream fis = null;//字符流 19 BufferedInputStream bis = null; 20 FileOutputStream fos = null; 21 BufferedOutputStream bos = null; 22 try { 23 //buffer的大小是8k 24 //Buffer嵌套字符流 25 fis = new FileInputStream(src); 26 bis = new BufferedInputStream(fis);//缓存输入流 27 28 fos = new FileOutputStream(dest); 29 bos = new BufferedOutputStream(fos); 30 31 byte[] arr = new byte[1024*2];//声明了大小为2k的小车车装数据 32 33 int count = 0;//每次读取多少个字节,返回字节数 , 如果读完了就会返回-1 34 //文件大小480076KB 35 //用字符流用时 3823ms 36 //嵌套上Buffer用时 3143ms 37 //....这好像看不出来啥 38 //其实如文件非常大的话,应该套上Buffer用时能到字符流用时的一半 39 while((count = bis.read(arr))!=-1) { 40 fos.write(arr , 0 , count);//每次把count大小的数据写进去 41 } 42 } catch (IOException e) { 43 e.printStackTrace(); 44 } finally { 45 try { 46 if(fis != null) { 47 fis.close(); 48 } 49 if(fos != null) { 50 fos.close(); 51 } 52 } catch (IOException e) { 53 e.printStackTrace(); 54 } 55 } 56 57 long l2 = System.currentTimeMillis(); 58 System.out.println(l2 - l1); 59 }
其中用到了
System.currentTimeMillis();
这个方法在代码块的一开始写上,记录当前时间
这么方法从程序开始设定为默认值从1970年开始,然后到代码块末未结束,再记录一下
然后这两个数相减,就能知道整个程序跑了多久.
这里我们还用到了Buffer
Buffer嵌套字符流
因为FileInputStream是一个字符流的输入(上面有一个图对它进行描述)这么频繁的一个字符一个字符的调用势必会对性能产生很大的影响
因此我们有了BufferedInputStream,这样的话每次Buffer填满的时候一次性的操作完,就很节省时间
Buffer的大小是8k
上面的代码我们测试了使用Buffer和不使用的时间差距,我们发现套上buffer会更快
文件大小480076KB
用字符流用时 3823ms
嵌套上Buffer用时 3143ms
....这好像看不出来啥
其实如文件非常大的话,应该套上Buffer用时能到字符流用时的一半
输出
1 static void output() { 2 FileOutputStream fos = null; 3 try { 4 fos = new FileOutputStream("d:\\aaa\\txt1.txt", true); 5 String str = "********"; 6 byte[] arr = str.getBytes(); 7 fos.write(arr); 8 } catch (FileNotFoundException e) { 9 e.printStackTrace(); 10 } catch (IOException e) { 11 e.printStackTrace(); 12 } finally { 13 try { 14 if (fos != null) { 15 fos.close(); 16 } 17 } catch (IOException e) { 18 // TODO Auto-generated catch block 19 e.printStackTrace(); 20 } 21 } 22 }
输入
1 void input() throws Exception { 2 FileInputStream fis = new FileInputStream("d:\\aaa\\txt1.txt"); 3 int count = 0; 4 byte[] arr = new byte[4]; 5 while ((count = fis.read(arr)) != -1) { 6 System.out.println(new String(arr, 0, count)); 7 } 8 fis.close(); 9 }
小例子:
使用Object的方法输入输出
1 package day09; 2 3 import java.io.FileInputStream; 4 import java.io.FileOutputStream; 5 import java.io.ObjectInputStream; 6 import java.io.ObjectOutputStream; 7 8 public class test { 9 public static void main(String[] args) throws Exception { 10 w(); 11 r(); 12 } 13 14 static void r() throws Exception { 15 FileInputStream fis = new FileInputStream("d:\\aaa\\txt\\txt.txt"); 16 ObjectInputStream ois = new ObjectInputStream(fis); 17 Cup cup = (Cup)ois.readObject(); 18 System.out.println(cup); 19 fis.close(); 20 ois.close(); 21 } 22 23 24 static void w() throws Exception { 25 Cup cup = new Cup("red", 33); 26 FileOutputStream fos = null; 27 ObjectOutputStream oos = null; 28 try { 29 fos = new FileOutputStream("d:\\aaa\\txt\\txt.txt"); 30 oos = new ObjectOutputStream(fos); 31 oos.writeObject(cup); 32 oos.flush(); 33 }catch (Exception e) { 34 e.printStackTrace(); 35 } finally { 36 fos.close(); 37 oos.close(); 38 } 39 } 40 }
1 package day09; 2 3 import java.io.Serializable; 4 5 public class Cup implements Serializable{ 6 7 private String color; 8 9 private int price; 10 11 public Cup(String color , int price) { 12 // TODO Auto-generated constructor stub 13 this.color = color; 14 this.price = price; 15 } 16 }
- transient(不可被序列化)
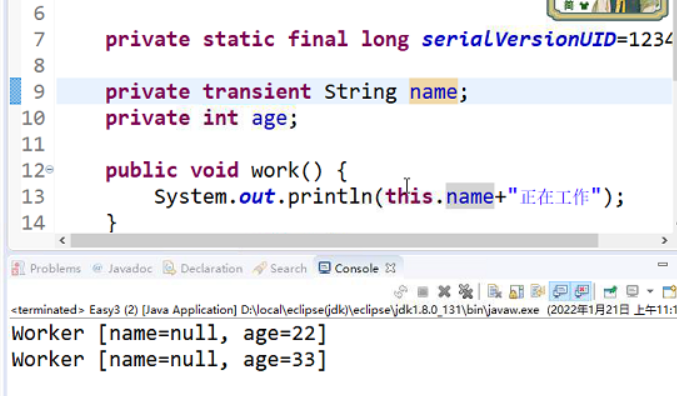
name加了transient防止被序列化,就是说往出传的时候,会检查他的serialVersionUID,不匹配就不会传
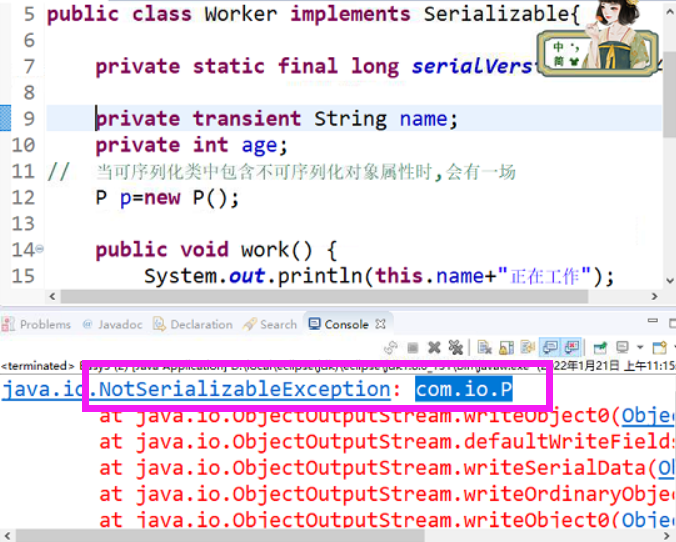
P因为没有序列化,所以抛出来了异常

 浙公网安备 33010602011771号
浙公网安备 33010602011771号