SVM 学习笔记
Support Vector Machine(SVM),也是广泛应用于各个领域的机器学习算法。
注意为了方便,本文取消了 \(x_0 = 1\) 的这一维,故原来的 \(\mathbf{\theta}^{\mathbf{T}} \mathbf{x}\),现在记为 \(\mathbf{\theta}^{\mathbf{T}} \mathbf{x} + \theta_0\)。
1. SVM 模型
我们先复习一下 Logistic 回归,我们的函数模型是设 \(h_{\mathbf{\theta}}(\mathbf{x}) = \sigma(\mathbf{\theta}^{\mathbf{T}} \mathbf{x} + \theta_0)\) 表明 \(\mathbf{x}\) 是正类的概率。然后通过代价函数:
来使用数据训练该模型。
由于代价函数中出现了对数函数,不便于计算,我们考虑使用一个便于计算且可以同样在模型决策错误时,让代价函数的值趋于正无穷的单调函数。我们暂且用 \(\operatorname{cost}_1(\mathbf{\theta}^{\mathbf{T}} \mathbf{x} + \theta_0), \operatorname{cost}_0(\mathbf{\theta}^{\mathbf{T}} \mathbf{x} + \theta_0)\) (下标代表了这个代价是否为正类数据的代价)代替代价函数中的两个对数的部分,即让新的代价函数为:
我们一般会选取 \(\operatorname{cost}_1(\mathbf{\theta}^{\mathbf{T}} \mathbf{x} + \theta_0) = \max(0, -\mathbf{\theta}^{\mathbf{T}} \mathbf{x} - \theta_0), \operatorname{cost}_0(\mathbf{\theta}^{\mathbf{T}} \mathbf{x} + \theta_0) = \max(0, \mathbf{\theta}^{\mathbf{T}} \mathbf{x} + \theta_0)\) 做代价函数这两部分。
而且由于 SVM 在代价函数的表示方法上与 Logistic 回归有些不同,我们去掉了第二项的正则化参数,而在第一项前面添加了参数,而且也去掉了取平均,最终的代价函数即为:
不同于 Logistic 回归,会给出一个概率,而 SVM 会给出一个直接的分类:
但是我们会给一个边界因子,使得分类效果更加明显,即我们最终的函数模型为:
我们不妨来看一下这些式子的意义。让我们从 \(\mathbf{\theta}^{\mathbf{T}} \mathbf{x} + \theta_0\) 这一部分下手。
我们发现这个是超平面的方程 \(\mathbf{\theta}^{\mathbf{T}} \mathbf{x} + \theta_0 = 0\) 的一部分,我们可以简单推导一下超平面的相关内容:
设超平面的法向量为 \(\mathbf{\theta}\),\(\mathbf{x}_0\) 是由原点为起点,终点为超平面上一点的一个向量。故超平面的方程为 \(\mathbf{\theta}^{\mathbf{T}} (\mathbf{x} - \mathbf{x}_0) = 0\),如果令 \(-\mathbf{\theta}^{\mathbf{T}} \mathbf{x}_0 = \theta_0\),则超平面的方程就为 \(\mathbf{\theta}^{\mathbf{T}} \mathbf{x} + \theta_0 = 0\)。
若 \(\mathbf{x}\) 为空间内任意一点,其到超平面的距离 \(d\) 即为向量 \(\mathbf{x} - \mathbf{x}_0\) 到法向量 \(\mathbf{\theta}\) 的投影的绝对值。即:
如果我们将 \(h_{\mathbf{\theta}}(\mathbf{x})\) 化作这样:
如果正类和负类的限制条件都加上绝对值,那么就是表明我们希望任意样本点 \(\mathbf{x}\) 到超平面 \(\mathbf{\theta}^{\mathbf{T}} \mathbf{x} + \theta_0 = 0\) 的距离至少为 \(\dfrac{1}{\vert \mathbf{\theta} \vert}\),而原式没有加绝对值,说明当 \(h_{\mathbf{\theta}}(\mathbf{x}) = 1\) 时,即 \(\mathbf{x}\) 为正类样本点时,我们还限制其在超平面上方,反之亦然。注意这里的上方是指 \(\mathbf{x} - \mathbf{x}_0\) 与超平面法向量 \(\mathbf{\theta}\) 的夹角为锐角。
所以若设 \(d = \dfrac{1}{\vert \mathbf{\theta} \vert}\),那么显然,最终训练出的分布应该是用一个超平面将正类和负类分开,并且这个超平面距离所有数据点的距离均要大于等于 \(d\)。在二维平面上就是下图的黑线:
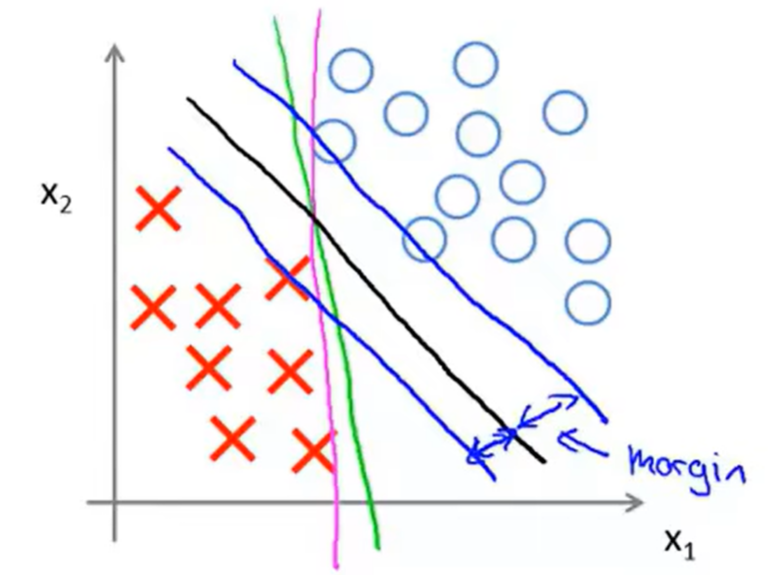
我们也称 \(d\) 为 SVM 的 margin。
我们再看代价函数的前一部分:
我们可以这样理解这个代价函数,即当一个数据为正类的时候,如果该数据点在我们当前由 \(\mathbf{\theta}\) 和 \(\theta_0\) 决定的超平面的下方的话,我们就会惩罚这个函数模型,反之亦然。而前面的常数 \(C\) 也表明了这样的惩罚最终被落实下来是多少。
下图表明了 \(C\) 的作用,如果我们将图中蓝色的圈看作一个正类数据,红色的叉看作负类数据,一开始我们的数据集没有左下角的那个负类数据时,我们训练出的 SVM 大概是黑线,但是如果我们向数据集添加了那个左下角的负类数据后,重新训练 SVM,这时候训练的结果就会受到 \(C\) 的影响。如果 \(C\) 过大,那么模型就会仅仅因为有一个负类数据点被分到了正类里面,而得到很大的惩罚,迫使其将训练结果调整为紫红色的线。反正若 \(C\) 较小,那么模型就不会过于受到这仅仅一个点的影响,最终的结果仍然和黑线接近。
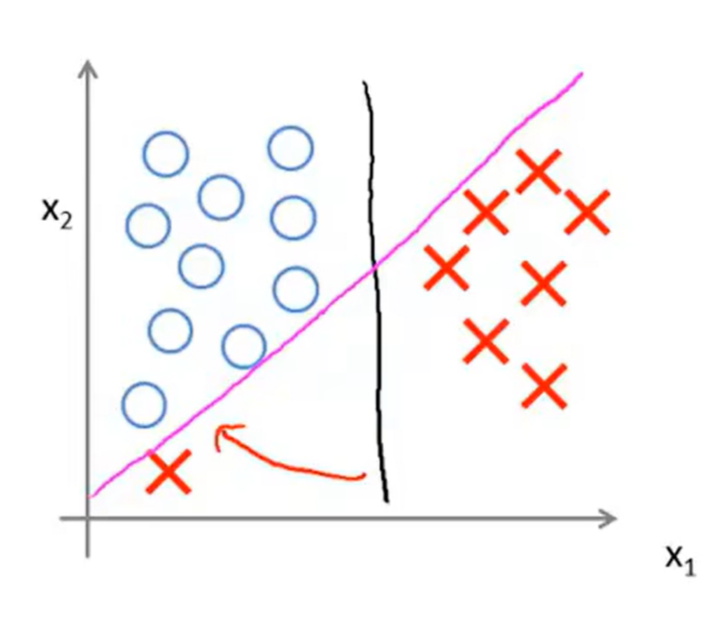
如果数据是近似线性可分的,那么最终得到的 \(\mathbf{\theta}, \theta_0\) 会使得代价函数前一部分的值不会太大,可以近似看作 0,进而代价函数的后一部分就需要重点考虑,即:
不难发现,其就是 \(\frac{1}{2} \vert \mathbf{\theta} \vert^2\),我们使它最小化,也就是使得 \(\vert \mathbf{\theta} \vert\) 最小化,进而使 \(d = \frac{1}{\vert \mathbf{\theta} \vert}\) 最大化。也就是说我们的代价还是在保证正负类在被分到平面的两侧的同时,还在使得间隔 \(d\) 尽可能大。这就是 SVM 的模型。
虽然 SVM 使用简单的超平面来分类,但是即使在实际情况中许多问题都不是线性可分的,SVM 仍然能做的很好。
