HashMap笔记
1、HashMap的简单使用
2、HashMap的核心思想
3、HashMap的源码解读

这个位置就算告诉我们容量必须是2的4次幂,默认16,负载因子0.75。这个位置也可以写成16。在java中的位移操作,用位移肯定要比直接写16要快的多,这是一个底层的运算。Java的底层是C语言,而C语言往下走接近于汇编语言,而汇编语言再往下走就接近于二进制机器语言。这里我们的效率就会越来越高。再一个这里如果直接写成16,那么它还需要转换成2进制,那么还不如直接写成二进制。那么为什么初始的容量是16,而不是8或者4?其实这是经过权衡过的才设置的默认值,在索引中它是0-15,二进制的十进制数%16最后得到的结果一定是0-15的结果,而java的底层是C语言,C的底层是汇编语言,汇编语言都是16进制的所有它是16。在java中,我们类的访问修饰符,所有的定义全都是十六进制的:0x00001,0x00004(Moderfiler)。
1.1HashMap是如何储存的?
在HashMap中,有一个叫

在entry中有

进来之后,它会把它封装成Node对象,

1.2HashMap是如何解决Hahs冲突/碰撞的?
1、使用单向链表
next指向的是一个Null,当出现了碰撞问题,就开始判断next是否为空。当然,它的hash值会自动帮它算好,对应一个next,现在存储进去了一个值,那么这个next就会改变成当前元素(键、值、Hash值)内存当中分配的地址。
注意:next指向的是一个Node里面的entry地址,jdk1.7的时候没有红黑树的概念。它可以一直挂到16,但是在jdk1.8以后,它进行了一个优化,它只能挂到7个,挂到第八个的时候,转变为红黑树。jdk1.8还作了一个优化,当下挂的节点小于等于6时,又会转变成链表。
为什么要转变成红黑树来存储?原因很简单方便,查找元素的效率变高了,原来jdk1.8之前的算法时间复杂度为O(n),现在的时间复杂度就是O。当然,如果我们当前的红黑树是8个,就要用到另一种形式进行拆分了。
1.2HashMap扩容是怎么操作的?并且容量扩容后的元素是如何保障均匀的分布?
(jdk1.8之前,jdk1.7处理hash冲突,使用链表、rehash(),后是使用红黑树)
非常巧妙的处理:
101010101010100 1010
000000000000001 0000 =32 (原来的容量是16,扩容后的就是32)
相当于定义了一个bit 1 (当前的位置+原来的容量)
0 原位置不动
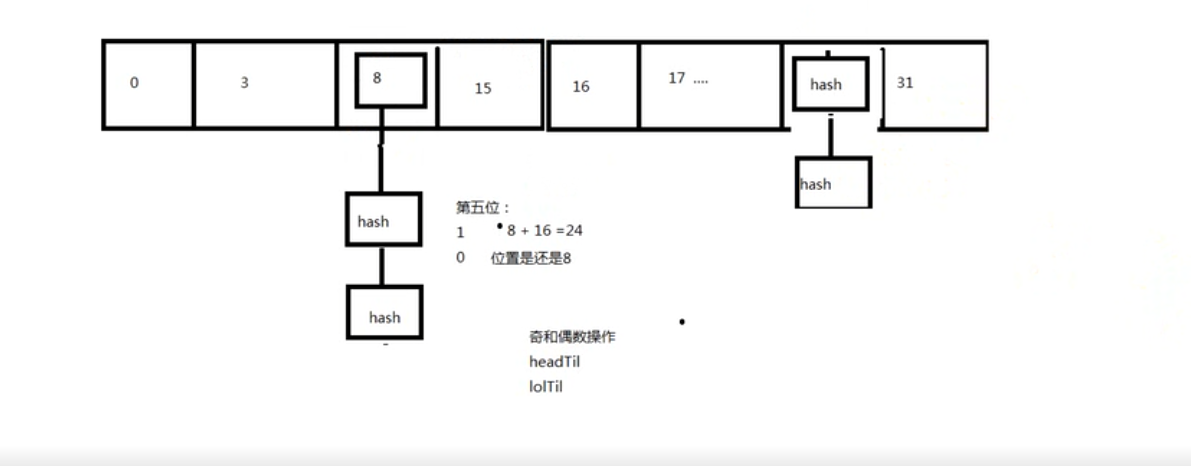

默认的一个扩容因子为0.75,
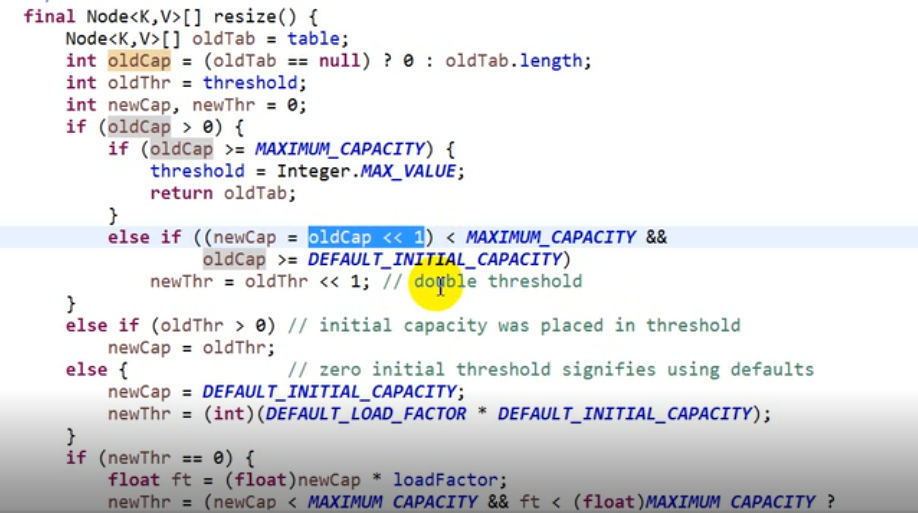
这个位置有一个扩容的效果,相当于扩容原来的两倍。
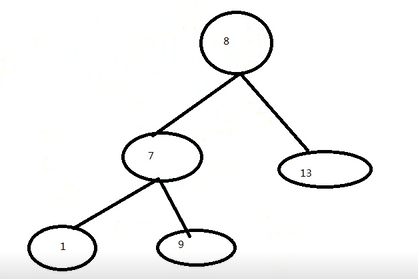
HashMap=(数组+链表+红黑树)(红黑树在1.8之后加上去的)
特点:这里变成了一个自平衡的二叉查找树,右指数的永远要比左指数的要大,如下图。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号