
java集合框架-List集合ArrayList和LinkedList详解
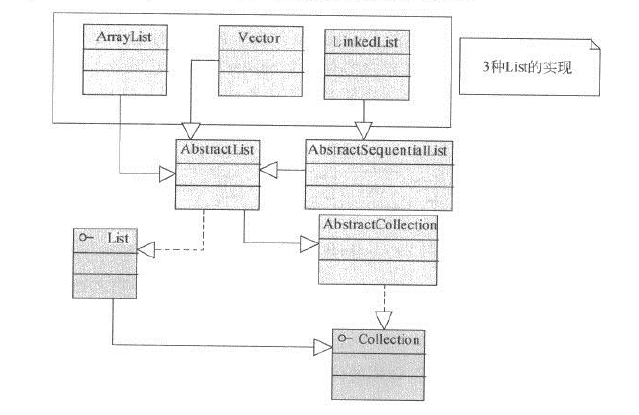
List 集合源码剖析
✅ ArrayList
底层是基于数组,(数组在内存中分配连续的内存空间)是对数组的升级,长度是动态的。
数组默认长度是10,当添加数据超越当前数组长度时,就会进行扩容,扩容长度是之前的1.5倍,要对之前的数组对象进行复制,所以只有每次扩容时相对性能开销大一些。
源码(jdk 1.8):
1. 添加元素(非指定位置)
// 1. 添加元素
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 每次添加元素都要对容量评估
elementData[size++] = e;
return true;
}
// 2. 评估容量
private void ensureCapacityInternal(int minCapacity) {
// 若果数组对象还是默认的数组对象
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
// 3. 进一步评估是否要进行扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++; // 记录ArrayList结构性变化的次数
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
步骤3中
if (minCapacity - elementData.length > 0) grow(minCapacity);
当 minCapacity 大于当前数组对象长度时 才进行扩容操作,也就是执行步骤 4的代码
// 4.复制产生新的数组对象并扩容
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
2. 指定位置添加元素
public void add(int index, E element) {
// 1
rangeCheckForAdd(index);
// 2
ensureCapacityInternal(size + 1);
// 3
System.arraycopy(elementData, index, elementData, index + 1,size - index);
// 4
elementData[index] = element;
// 5
size++;
}
-
rangeCheckForAdd(index);评估插入元素位置是否合理 -
ensureCapacityInternal(size + 1);检查数组容量是否有当前元素数量 size +1 个大,因为后续进行数组复制要多出一个元素 -
数组复制
System.arraycopy(elementData, index, elementData, index + 1,size - index);
System.arraycopy(src, srcPos, dest, destPos , length);
src:源数组;srcPos:源数组要复制的起始位置;index 是要插入元素的位置,所以要从当前开始复制
dest:目的数组; destPos:目的数组放置的起始位置;复制好的元素要放在插入位置的后面 所以 index+1
length:复制的长度。包括插入位置和后面的元素 = 当前元素数 - 插入位置
-
步骤执行元素赋值
-
步骤元素长度+1
如果ArrayLisy集合不指定位置添加元素,默认往数组对象的后面追加,所以数组对象的其他元素位置不变,没有什么性能开销,如果元素插入到数组对象的前面,而且是越往前,重新排序的数组元素就会越多性能开销越大,当然通过上述源码介绍中看到,通过数组复制的方式排序对性能影响也不大,
3.查找元素
// 获取指定位置元素的源码
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
直接返回当前查找位置的数组对象对应的下标位置的元素,高性能,速度很快。
4. ArraList 和 Vector
ArraList 和 Vector 都是基于数组实现,它俩底层实现原理几乎相同,只是Vector是线程安全的,ArrayLsit不是线程安全的,它俩的性能也相差无几。
✅ LinkedList
- LinkedList使用循环双向链表数据结构,它和基于数组的List相比是截然不同的,在内存中分配的空间不是连续的。
- LinkedList是由一系列表项组成的,包括数据内容、前驱表项、后驱表项,或者说前后两个指针
- 不管LinkedList集合是否为空,都有一个header表项。(前驱表项指向 最后一个 元素,后驱表项指向 第一个元素)
双向链表
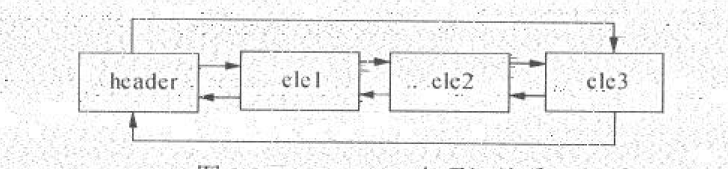
表项

1. 添加元素
//1. 添加元素,不指定位置会添加到最后一个
public boolean add(E e) {
linkLast(e);
return true;
}
//2. 添加到最后一位(每次添加插入元素都会创建一个Node对象)
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null); // 双向链表的最后一个表项没有 后驱指针
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
//3. 创建表项
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
2. 添加指定位置元素
public void add(int index, E element) {
checkPositionIndex(index); // 检查位置是否合理
if (index == size)
linkLast(element); // 如果插入位置等于集合元素长度就往后追加
else
linkBefore(element, node(index)); // 否则在当前位置元素前面创建新节点
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
// 步骤一
final Node<E> pred = succ.prev;
// 步骤二
final Node<E> newNode = new Node<>(pred, e, succ);
// 步骤三
succ.prev = newNode;
// 步骤四
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
步骤一:获取当前元素(未插入目前要插入的元素前)前指针指向的节点
步骤二:创建新节点,一个表项,前驱表项是前面的节点 步骤一得到,后驱表项指向的时当前位置的节点(未插入目前要插入的元素前)
步骤三:重新设置当前位置的节点(未插入目前要插入的元素前)的前驱指针指向的节点,也就是刚插入的创建的新节点
步骤四:是对创建新节点的前置节点的后驱表项进行修改设置
总结:对应LinkedList插入任意位置元素 我们只需创建一个新元素节点和移动前后两个表项的指针,其他表项无需任何操作,性能高;
3. LinkedList集合中的第一个和最后一个元素位置是确定的
最后一个元素和第一个元素的位置不需要遍历整个链表获取,每个LinkedList集合无论是否为空,都会有一个Header表项,Header表项的前驱指针始终指向最后一个元素,后驱指针指向第一个元素,所以可以说LinkedList集合中的第一个和最后一个元素位置是确定的。
4. 查找删除元素
循环双向链表结构中节点位置的确定需要根据前面的元素往后遍历查找或者后面的元素往前遍历查找
// 1. 获取指定位置元素
public E get(int index) {
checkElementIndex(index); // 首先判断位置是否有效
return node(index).item;
}
// 2. 根据位置对节点遍历查找
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) { // 如果下标位置在总长度中间之前,则从前往后遍历查找
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { // 如果下标位置在总长度中间之后,则从后往前遍历查找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
从上面的源码中可以看出如果LinkedList集合的长度很大,则每次查找元素都会遍历很多次,性能影响也会更大
删除任意位置的元素,是先要找到该元素,所以需要上一步提到的查找操作
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index)); // node(index) 是查找元素
}
ArrayList和LinkedLisy对比
🍡 实现方式
ArrayList 是基于数组实现,内存中分配连续的空间,需要维护容量大小。
LinkedList 是基于循环双向链表数据结构,不需要维护容量大小。
🍪 添加插入删除元素
ArrayList不自定义位置添加元素和LinkedList性能没啥区别,ArrayList默认元素追加到数组后面,而LinkedList只需要移动指针,所以两者性能相差无几。
如果ArrayList自定义位置插入元素,越靠前,需要重写排序的元素越多,性能消耗越大,LinkedList无论插入任何位置都一样,只需要创建一个新的表项节点和移动一下指针,性能消耗很低。
频繁插入删除元素 -> 使用 LinkedList 集合
🚓 遍历查看元素
ArrayList是基于数组,所以查看任意位置元素只需要获取当前位置的下标的数组就可以,效率很高,然而LinkedList获取元素需要从最前面或者最后面遍历到当前位置元素获取,如果集合中元素很多,就会效率很低,性能消耗大。
频繁遍历查看元素 -> 使用 ArrayList 集合
🍝 ArrayList和LinkedList 都时线程不安全的
更多内容:

- NiceCui CONSTANT DRIPPING WEARS AWAY THE STONE - 滴水穿石
- 本文属于本人原创作品,没有经过本人同意不得转载
- 个人博客主页:https://www.kazhikazhi.com/NiceCui

 浙公网安备 33010602011771号
浙公网安备 33010602011771号