


绝对导入与相对导入
只要涉及到模块的导入,那么sys.path永远以执行文件为准
绝对导入
- 定义:绝对导入就是以执行文件所在的sys.path为起始路径往下一层层查找
from ccc import b from ccc.ddd.eee import b
- 由于pycharm会自动将项目根目录添加到sys.path中,所以查找模块肯定不报错的方法就是永远从根目录往下一层层找
注意:如果不是用pycharm运行,则需要将项目根目录添加到sys.path(针对项目根目录的绝对路径有os模块可以帮助我们获取)
import os.path path = os.path.abspath('aaa') print(path) # D:\pycham\PycharmProjects\day23\aaa
相对导入
- 定义:可以不参考执行文件所在的路径,直接以当前模块文件路径为准
- 储备知识:
- .在路径中意思是当前路径
- ..在路径中意思是上一层路径
- ../..在路径中意思是上上一层路径
- 注意:
- 相对导入只能在模块文件中使用,不能在执行文件中使用
- 相对导入在项目比较复杂的情况下可能会出错
- 相对导入尽量少用,推荐使用绝对导入
包的概念
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。简单来说,包就是文件夹,但该文件夹下必须存在 __ init__ .py 文件, 该文件的内容可以为空。__ init__ .py 用于标识当前文件夹是一个包。
包的作用
内部存放多个py文件(模块文件),是为了更方便管理模块文件
包的使用
-
import 包名
-
导入包名其实导入的是里面的__ init__ .py文件(里面有什么就用什么),也可以跨过__ init__.py文件直接导入包里面的模块文件
注意
-
针对python3解释器,其实文件夹里面有没有__ init__ .py文件无所谓,都是包
-
针对python2解释器,文件下面必须要有__ init__ .py文件才能被当做包
编程思想的转变
小白阶段
按照需求从上往下堆叠代码(单文件),相当于将所有的 文件全部存储在C盘并且不分类
函数阶段
将代码按照功能的不同封装成不同的函数(单文件),相当于将所有的文件在C盘下分类存储
模块阶段
-
根据功能的不同拆分不同的模块软件(多文件),相当于将所有的文件按照功能的不同分类到不同的盘里
-
目的:更方便快捷高效的管理资源
软件开发目录的规范
为了提高程序的可读性和可维护性,我们应该为软件设计良好的目录结构,这与规范的编码风格同等重要。软件的目录规范并无硬性标准,只要清晰可读即可。
目录的规范优点
1.可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
2.可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
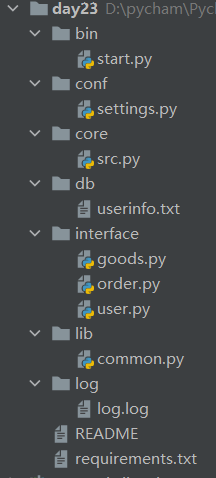
文件分类详细
1.bin文件夹:
- 用于存储程序的启动文件>>>>>start.py
2.conf文件夹:
- 用于存储程序的配置文件>>>>>settings.py
3.core文件夹:
- 用于存储程序的核心逻辑>>>>>src.py
4.lib文件夹:
- 用于存储程序的公共功能>>>>>common.py
5.db文件夹:
- 用于存储程序的数据文件>>>>>userinfo.txt
6.log文件夹:
- 用于存储程序的日志文件>>>>>log.log
7.interface文件夹:
- 用于存储程序的接口文件>>>>>user.py order.py goods.py
8.README文件(文本文件):
- 用于存储程序的说明、介绍、广告(类似于产品说明书)
9.requirements.txt文件:
- 用于存储程序所需的第三方模块名称和版本
README文件说明
-
README文件是每个项目都应该有的一个文件
-
目的:能简要描述该项目的信息,让读者快速了解这个项目
-
需要说明以下几个事项:
- 软件定位,软件的基本功能
- 运行代码的方法:安装环境、启动命令等
- 简要的使用说明
- 代码目录结构说明,更详细点可以说明软件的基本原理
- 常见的问题说明
requirements.txt文件说明
- 这个文件的存在是为了方便开发者,维护软件的依赖库,我们需要的第三方库都可以写进去,pycharm非常智能,会通过识别版本号以及包名导入,这样也方便我们查看使用了哪些python包。
注意:在编写软件的时候,可以不完全遵循上面的文件名
- start.py可以放在bin文件夹下也可以直接放在项目根目录下
- db文件夹等学到真正的项目会被数据库软件替代
- log文件夹等学到真正的项目会被专门的日志服务替代
常见的内置模块
collection模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
- namedtuple:生成可以使用名字来访问元素内容的元组
- deque:双端队列,可以快速的从另一侧追加和推出对象
- Counter:计数器,主要用来计数
- OrderedDict:有序字典
- defaultdict:带有默认值的字典
namedtuple
from collections import namedtuple Point = namedtuple('二维坐标系', ['x', 'y']) res1 = Point(1, 3) res2 = Point(10, 49) print(res1, res2) # 二维坐标系(x=1, y=3) 二维坐标系(x=10, y=49) print(res1.x) # 1 print(res1.y) # 3 Point = namedtuple('三维坐标系', 'x y z') res1 = Point(1, 3, 44) res2 = Point(10, 49, 55) print(res1, res2) # 三维坐标系(x=1, y=3, z=44) 三维坐标系(x=10, y=49, z=55) p = namedtuple('扑克牌', ['花色', '点数']) res1 = p('♥', 'A') res2 = p('♠', 'A') print(res1) # 扑克牌(花色='♥', 点数='A') print(res2) # 扑克牌(花色='♠', 点数='A')
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
from collections import deque q = deque() q.append(111) q.append(222) q.append(333) q.append(444) q.appendleft(555) print(q) # deque([555, 111, 222, 333, 444])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
Counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
res = 'abcdeabcdabcaba' # {'a': 2, 'b': 5 } new_dict = {} for i in res: if i not in new_dict: new_dict[i] = 1 else: new_dict[i] += 1 print(new_dict) # {'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1} from collections import Counter res = 'abcdeabcdabcaba' # {'a':2,'b':5 } res1 = Counter(res) print(res1) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
from collections import OrderedDict d = dict([('a', 1), ('b', 2), ('c', 3)]) print(d) # {'a': 1, 'b': 2, 'c': 3} od = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) print(od) # OrderedDict([('a', 1), ('b', 2), ('c', 3)])
defaultdict
l1 = [11, 22, 33, 44, 55, 66, 77, 88, 99, 100] res = {'k1': [], 'k2': []} for i in l1: if i < 66: res.get('k1').append(i) else: res.get('k2').append(i) print(res) # {'k1': [11, 22, 33, 44, 55], 'k2': [66, 77, 88, 99, 100]} from collections import defaultdict res = defaultdict(k1=[i for i in l1 if i < 66], k2=[i for i in l1 if i >= 66]) print(res) # defaultdict(None, {'k1': [11, 22, 33, 44, 55], 'k2': [66, 77, 88, 99, 100]})
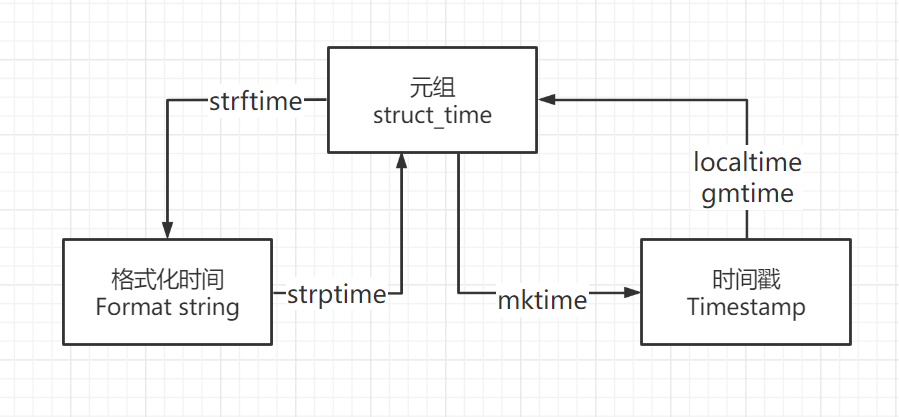
时间模块-time模块
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
1.时间戳(Timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
2.格式化的时间字符串(Format String): ‘1999-12-06’
- python中时间日期格式化符号:"%Y-%m-%d %H:%M:%S" 或 "%Y-%m-%d %X"
3.元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
时间戳
- time.time()
import time # 导入时间模块 # time.time()时间戳 print(time.time()) # 1657796870.4282327
格式化时间
-
time.strftme()
-
格式化符号:"%Y-%m-%d %H:%M:%S" 或 "%Y-%m-%d %X"
import time # 导入时间模块 # time.strftme格式化时间 print(time.strftime("%Y-%m-%d %X")) # 2022-07-14 19:11:59 print(time.strftime("%Y-%m-%d %H:%M:%S")) # 2022-07-14 19:11:59
结构化时间
- time.gmtime
import time # 导入时间模块 # time.gmtime结构化时间 print(time.gmtime) # time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=11, tm_min=22, tm_sec=17, tm_wday=3, tm_yday=195, tm_isdst=0)
格式化转结构化
- time.strptime
import time # 导入时间模块 print(time.strptime('2022-7-14 19:44:22', "%Y-%m-%d %H:%M:%S")) # time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=19, tm_min=44, tm_sec=22, tm_wday=3, tm_yday=195, tm_isdst=-1)
几种格式间的转换

 posted on
posted on

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)