
列表内置方法
- 列表在调用内置方法之后不会产生新的值而是修改自身
1.统计列表数据值的个数
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
l2 = [77, 33, 22, 44, 55, 99, 88]
print(len(l2)) # 7
2.增加数据
2.1.尾部追加数据值
- append():括号内无论写什么数据类型都当成一个数据值追加
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
l2 = [77, 33, 22, 44, 55, 99, 88]
res = l1.append('owen')
print(res) # None 空
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry', 'owen']
s1 = '$hello$'
res1 = s1.strip('$')
print(res1) # hello
print(s1) # $hello$
l1.append([1, 2, 3, 4, 5])
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry', 'owen', [1, 2, 3, 4, 5]]
2.2.任意位置插入数据值
- insert():括号内无论写什么数据类型都当成一个数据值追加
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
l2 = [77, 33, 22, 44, 55, 99, 88]
l1.insert(0, '插队')
print(l1) # ['插队', 'jason', 'kevin', 'oscar', 'tony', 'jerry']
l1.insert(0, [1, 2, 3])
print(l1) # [[1, 2, 3], '插队', 'jason', 'kevin', 'oscar', 'tony', 'jerry']
2.3.扩展列表
- 方式1:
new_l1 = [11, 22, 33, 44, 55]
new_l2 = [1, 2, 3]
for i in new_l1:
new_l2.append(i)
print(new_l2) # [1, 2, 3, 11, 22, 33, 44, 55]
- 方式2:
new_l1 = [11, 22, 33, 44, 55]
new_l2 = [1, 2, 3]
print(new_l1 + new_l2) # [11, 22, 33, 44, 55, 1, 2, 3]
- 方式3(推荐使用):括号里面必须是支持for循环的数据类型(for循环+append())
new_l1 = [11, 22, 33, 44, 55]
new_l2 = [1, 2, 3]
new_l1.extend(new_l2)
print(new_l1) # [11, 22, 33, 44, 55, 1, 2, 3]
3.查询数据
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
print(l1) # ['jason', 'kevin', 'oscar', 'tony', 'jerry']
print(l1[0]) # jason
print(l1[1:4]) # ['kevin', 'oscar', 'tony']
4.修改数据
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
l1[0] = 'jasonNB'
print(l1) # ['jasonNB', 'kevin', 'oscar', 'tony', 'jerry']
5.删除数据
5.1.通用删除策略
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
del l1[0] # 通过索引即可
print(l1)
5.2.指名道姓删除
- 括号内必须填写明确的数据值
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
res = l1.remove('jason')
print(l1, res)
5.3.先取出数据值,再删除
- 默认取出列表尾部的的数据值然后再删除
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
res = l1.pop()
print(l1, res)
res = l1.pop(0)
print(res, l1)
6.查看数据值对于的索引值
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
print(l1.index('jason'))
7.统计某个数据值出现的次数
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
l1.append('jason')
l1.append('jason')
l1.append('jason')
print(l1.count('jason'))
8.排序
- sort() 升序
- sort(reverse=True) 降序
l2 = [77, 33, 22, 44, 55, 99, 88]
l2.sort() # 升序
l2.sort(reverse=True) # 降序
print(l2)
9.翻转
- reverse() 前后颠倒
l1 = ['jason', 'kevin', 'oscar', 'tony', 'jerry']
l1.reverse() # 前后颠倒
print(l1)
10.比较运算
- 按照位置顺序一一比较
new_1 = [99, 11]
new_2 = [11, 22, 33, 44]
print(new_1 > new_2) # True 是按照位置顺序一一比较
- 不同数据类型之间默认无法直接作比较
new_1 = ['a', 11]
new_2 = [11, 22, 33, 44]
print(new_1 > new_2)
new_1 = ['a', 11] # a 97
new_2 = ['A', 22, 33, 44] # A 65
print(new_1 > new_2) # True
new_1 = ['你', 11] # a 97
new_2 = ['我', 22, 33, 44] # A 65
print(new_1 > new_2) # False
元组内置方法
- 类型转换
print(tuple(123))
print(tuple(123.11))
print(tuple('hello'))
- 支持for循环的数据类型都可以转元组
t1 = () # tuple
print(type(t1))
t2 = (1) # int
print(type(t2))
t3 = (11.11) # float
print(type(t3))
t4 = ('jason') # str
print(type(t4))
- 当元组内只有一个数据值,不能省略逗号,如果省略逗号,括号里是什么类型就是什么数据类型
- 遇到可以存储多个数据值的数据类型,如果里面只有一个数据值,逗号也加上
t1 = () # tuple
print(type(t1))
t2 = (1,) # tuple
print(type(t2))
t3 = (11.11,) # tuple
print(type(t3))
t4 = ('jason',) # tuple
print(type(t4))
- 元组的索引不能改变绑定的地址
t1 = (11, 22, 33, [11, 22])
t1[-1].append(33)
print(t1) # (11, 22, 33, [11, 22, 33])
1.索引相关操作
2.统计元组内数据值个数
t1 = (11, 22, 33, 44, 55, 66)
print(len(t1))
3.查与改
print(t1[0]) # 可以查
t1[0] = 222 # 不可以改
字典内置方法
- 类型转换了解就行,字典很少涉及到类型转换,都是直接定义使用
print(dict([('name', 'jason'), ('pwd', 123)]))
print(dict(name='jason', pwd=123))
- K是对V的描述性性质的信息,一般是字符串(K只要是不可变类型都可以)
- 字典内k:v键值对是无序的
1.取值操作
- get()字典取值建议使用get方法
print(info['username']) # 不推荐使用 键不存在会直接报错
print(info['xxx']) # 不推荐使用 键不存在会直接报错
print(info.get('username')) # jason
print(info.get('xxx')) # None
print(info.get('username', '键不存在返回的值 默认返回None')) # jason
print(info.get('xxx', '键不存在返回的值 默认返回None')) # 键不存在返回的值 默认返回None
print(info.get('xxx', 123)) # 123
print(info.get('xxx')) # None
2.统计字典中键值对的个数
print(len(info))
3.修改数据
- 键存在是修改
info['username'] = 'jasonNB'
print(info)
4.新增数据
- 键不存在是新增
info['salary'] = 6
print(info) # {'username': 'jason', 'pwd': 123, 'hobby': ['read', 'run'], 'salary': 6}
5.删除数据
- 方式1:
del info['username']
print(info)
- 方式2:pop()删除指定的key对应的键值对,并返回值
es = info.pop('username')
print(info, res)
- 方式3:popitem()随机删除一组键值对,并将删除的键值放到元组内返回
info.popitem()
print(info)
6.快速获取键、值、键值对数据
- 获取字典所有的k值,结果当成是列表即可
print(info.keys())
- 获取字典所有的v值,结果当成是列表即可
print(info.values())
- 获取字典kv键值对数据,组织成列表套元组
print(info.items())
7.修改字典数据(键存在是修改,键不存在是新增)
info.update({'username':'jason123'})
print(info)
info.update({'xxx':'jason123'})
print(info)
8.快速构造字典
- 给的值默认情况下所有的键都用一个
res = dict.fromkeys([1, 2, 3], None)
print(res)
new_dict = dict.fromkeys(['name', 'pwd', 'hobby'], []) # {'name': [], 'pwd': [], 'hobby': []}
new_dict['name'] = []
new_dict['name'].append(123)
new_dict['pwd'].append(123)
new_dict['hobby'].append('read')
print(new_dict)
res = dict.fromkeys([1, 2, 3], 234234234234234234234)
print(id(res[1]))
print(id(res[2]))
print(id(res[3]))
9.键存在获取键对应的值,键不存在则设置新值并返回设置的新值
res = info.setdefault('username', 'jasonNB')
print(res, info)
res1 = info.setdefault('xxx', 'jasonNB')
print(res1, info)
集合内置方法
- set()
- 类型转换:支持for循环,数据是不可变类型
- 定义空集合需要使用关键字
- 集合内必须是不可变类型(整型int,浮点型float,字符串str,元组tuple,布尔值bool)
1.去重
- 集合去重复有局限性
- 只针对不可变类型
- 集合本身是无序的,去重之后无法保留原来的顺序
s1 = {1, 2, 12, 3, 2, 3, 2, 3, 2, 3, 4, 3, 4, 5, 4, 5, 4, 5, 4, 5, 4}
print(s1) # {1, 2, 3, 4, 5, 12}
l1 = ['jason', 'jason', 'tony', 'oscar', 'tony', 'oscar', 'jason']
s2 = set(l1)
l1 = list(s2)
print(l1)
- 针对不可变类型,去重,保留顺序
l=[2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
2.集合的关系运算
f1 = {'jason', 'tony', 'oscar', 'jerry'}
f2 = {'kevin', 'jerry', 'jason', 'lili'}
- 交集(&)求f1和f2的共同好友
print(f1 & f2) # {'jason', 'jerry'}
- 差集(-)求f1/f2独有好友
print(f1 - f2) # {'oscar', 'tony'}
print(f2 - f1) # {'lili', 'kevin'}
- 合集(|)求f1和f2所有的好友
print(f1 | f2) # {'jason', 'kevin', 'lili', 'oscar', 'jerry', 'tony'}
- 对称差集(^)求f1和f2各自独有的好友(排除共同好友)
print(f1 ^ f2) # {'kevin', 'lili', 'tony', 'oscar'}
- 父集子集
s1 = {1, 2, 3, 4, 5, 6, 7}
s2 = {3, 2, 1}
print(s1 > s2) # s1是否是s2的父集 s2是不是s1的子集
print(s1 < s2)
可变类型与不可变类型
1.可变类型(list)
- 值发生改变,内存地址不变,id不变,证明在改变原值
- 列表
l1 = [11, 22, 33]
print(id(l1)) # 1931283911552
l1.append(44) # [11, 22, 33, 44]
print(id(l1)) # 1931283911552
# 对列表的值进行操作时,值改变但内存地址不变,所以列表是可变数据类型
2.不可变类型(str int float)
- 不可变类型:值发生改变,内存地址也发生改变,id也变,证明是没有改变原值,产生了新的值数字类型
s1 = '$hello$'
print(id(s1))
s1 = s1.strip('$')
print(id(s1))
ccc = 666
print(id(ccc))
ccc = 990
print(id(ccc))
- 数字类型:
x = 10
print(id(x)) # 1855614720
x = 20
print(id(x)) # 1855615040
# 内存地址改变了,说明整型是不可变数据类型,浮点型也一样
- 字符串
x = "Jason"
print(id(x)) # 2279157630376
x = "Ricky"
print(id(x)) # 2279157630544
# 内存地址改变了,说明字符串是不可变数据类型
- 元组
t1 = ("tom","jack",[1,2])
t1[0]='TOM' # 报错:TypeError
t1.append('lili') # 报错:TypeError
# 元组内的元素无法修改,指的是元组内索引指向的内存地址不能被修改
t1 = ("tom", "jack", [1, 2])
print(id(t1[0]), id(t1[1]), id(t1[2])) # 3097607767632 3097608728848 3097610495240
t1[2][0] = 111 # 如果元组中存在可变类型,是可以修改,但是修改后的内存地址不变
t1 = ('tom', 'jack', [111, 2])
print(id(t1[0]), id(t1[1]), id(t1[2])) # 查看id仍然不变 3097607767632 3097608728848 3097610495240
- 字典
dic = {'name': 'oscar', 'sex': 'male', 'age': 18}
# print(id(dic)) # 1817372193056
dic['age'] = 19
dic = {'age': 19, 'sex': 'male', 'name': 'oscar'}
print(id(dic)) # 1817372193056
# 对字典进行操作时,值改变的情况下,字典的id也是不变,即字典也是可变数据类型
作业
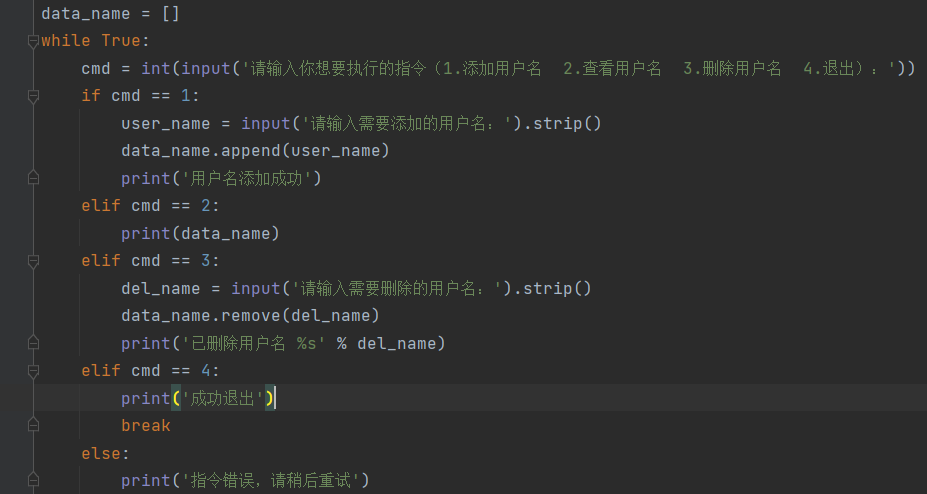
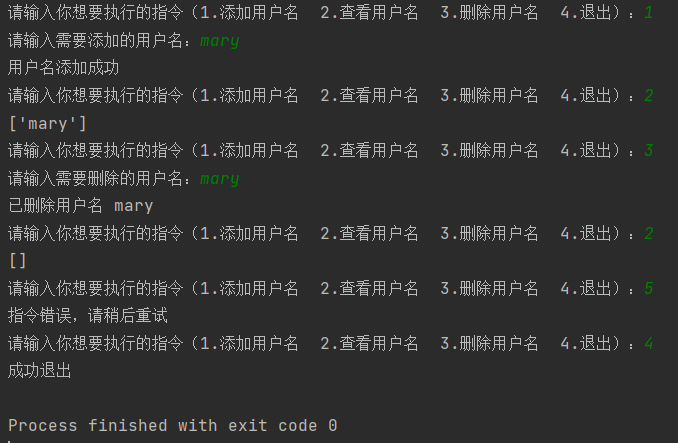
1.利用列表编写一个员工姓名管理系统
输入1执行添加用户名功能
输入2执行查看所有用户名功能
输入3执行删除指定用户名功能
ps:思考如何让程序循环起来并且可以根据不同指令执行不同操作
提示: 循环结构 + 分支结构
拔高: 是否可以换成字典或者数据的嵌套使用完成更加完善的员工管理而不是简简单单的一个用户名(能写就写 不会没有关系)
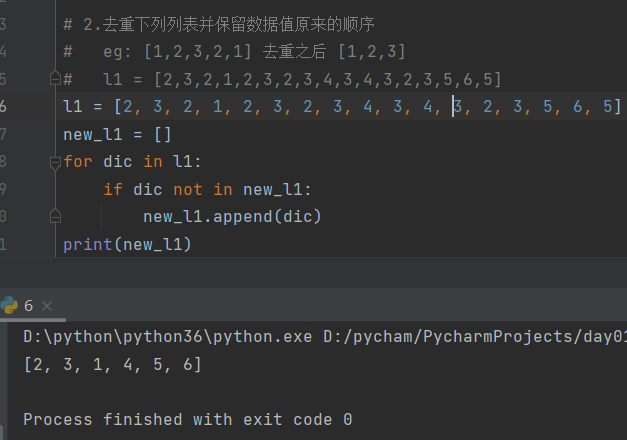
2.去重下列列表并保留数据值原来的顺序
eg: [1,2,3,2,1] 去重之后 [1,2,3]
l1 = [2,3,2,1,2,3,2,3,4,3,4,3,2,3,5,6,5]
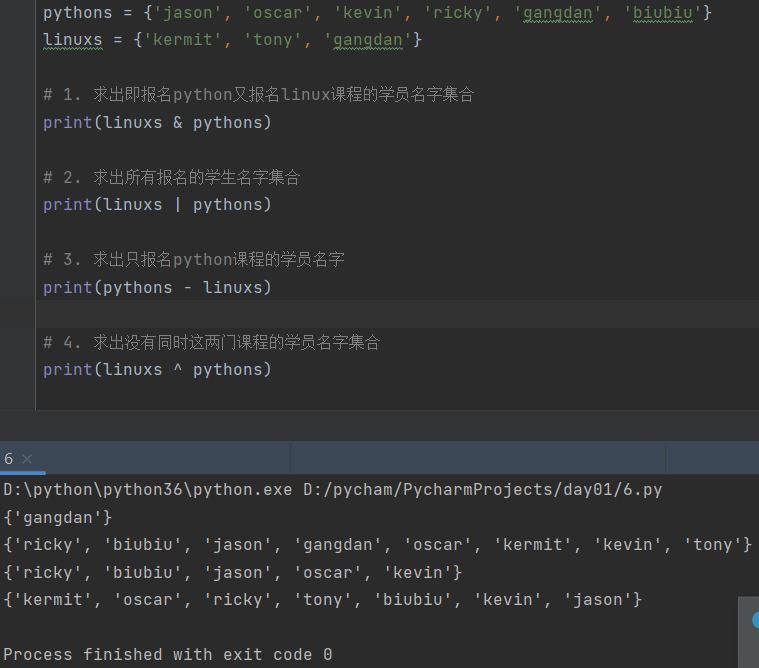
3.有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons={'jason','oscar','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号