数据类型的内置方法
- 简介:内置方法可以简单的理解成是每个数据类型自带的功能(每个人的不同特长)
- 使用数据类型的内置方法统一采用句点符:数据类型.方法名()
| eg: |
| 'jason'.字符串具备的方法() |
| |
| name = 'jason' |
| name.字符串具备的方法() |
| ps:如何快速查看某个数据类型的内置方法 |
| 借助于编辑器自动提示 |
1.整型相关方法
1.1.整型
- 概念:整型就是整数,主要用于计算,没有内置方法
- 关键字:int()
1.2.类型转换
| age = input() |
| age = int(age) |
| print(type(int('123'))) |
| print(type(int('123a321'))) |
| print(type(int('123.33'))) |
1.3.进制转换
- 进制:二进制、八进制、十进制、十六进制
- 十进制转换其他进制:
- bin():将十进制转二进制 0b1100100 0b是二进制数的标识
- oct():将十进制转八进制 0o144 0o是八进制数的标识
- hex():将十进制转十六进制 0x64 0x是十六进制数的标识
| print(bin(100)) |
| print(oct(100)) |
| print(hex(100)) |
| |
| print(int(0b1100100)) |
| print(int(0o144)) |
| print(int(0x64)) |
| |
| print(int('0b1100100', 2)) |
| print(int('0o144', 8)) |
| print(int('0x64', 16)) |
2.浮点型相关方法
2.1.浮点型
- 概念:浮点型由整数部分与小数部分组成
- 关键字:float
2.2.类型转换
| print(float('123')) |
| print(type(float('123'))) |
| print(float('123a123')) |
| print(float('123.12')) |
| print(float('123.123.1.2.2.2.2.2.2')) |
2.3.针对布尔值的特殊情况
| print(float(True)) |
| print(float(False)) |
| print(int(True)) |
| print(int(False)) |
3.字符串相关方法
3.1.字符串
- 概念:双引号或者单引号中的数据,就是字符串
- 关键字:str
3.2.类型转换
| print(str(123), type(str(123))) |
| print(str(123.11), type(str(123.11))) |
| print(str([1, 2, 3, 4]), type(str([1, 2, 3, 4]))) |
| print(str({'name': 'jason'}), type(str({'name': 'jason'}))) |
| print(str(True), type(str(True))) |
| print(str((1, 2, 3, 4)), type(str((1, 2, 3, 4)))) |
| print(str({1, 2, 3, 4}), type(str({1, 2, 3, 4}))) |
3.3.需掌握的方法
| s1 = 'hello jason!' |
| print(s1[0]) |
| print(s1[-1]) |
| print(s1[-2]) |
- 切片取值:多个字符,支持负数,切片的顺序默认从左往右
| s1 = 'hello jason!' |
| print(s1[0:3]) |
| print(s1[-1:-4]) |
| print(s1[-1:-4:-1]) |
| print(s1[-4:-1]) |
| s1 = 'hello jason!' |
| print(s1[:]) |
| print(s1[::2]) |
| print(s1[0:5:1]) |
| print(s1[0:5:2]) |
| s1 = 'hello jason!' |
| print(len(s1)) # print(len('hello jason!')) 12 空格也算字符 |
| s1 = 'hello jason!' |
| username = input('username>>>:') |
| if username == 'jason': # 'jason ' == 'jason' |
| print('登录成功') |
| else: |
| print('你不是jason!') |
| |
| name = ' jason ' |
| print(len(name)) |
| print(name.strip(), len(name.strip())) |
| res = name.strip() |
| print(name, len(name)) |
| print(res, len(res)) |
| desc1 = '$$jason$$' |
| print(desc1.strip('$')) |
| print(desc1.lstrip('$')) |
| print(desc1.rstrip('$')) |
| |
| username = input('username>>>:') |
| username = username.strip() |
| username = input('username>>>:').strip() |
| if username == 'jason': |
| print('登录成功') |
| else: |
| print('你不是jason!') |
- 按照指定的字符切割字符串
- 当字符串中出现了连续的特征符号 应该考虑使用切割操作
| info = 'jason|123|read' |
| res = info.split('|') # 切割字符串之后结果是一个列表 |
| print(res, type(res)) # ['jason', '123', 'read'] <class 'list'> |
| name, pwd, hobby = info.split('|') # name, pwd, hobby = ['jason', '123', 'read'] |
| print(info.split('|', maxsplit=1)) # 从左往右 只切一次 ['jason', '123|read'] |
| print(info.rsplit('|', maxsplit=1)) # 从右往左 只切一次 ['jason|123', 'read'] |
| s2 = 'HeLLo Big BAby 666 你过的还好吗' |
| print(s2.lower()) |
| print(s2.upper()) |
| print(s2.islower()) |
| print(s2.isupper()) |
| print('aaa'.islower()) |
| print('AAA'.isupper()) |
| |
| code = 'JaSon666' |
| print('这是网页给你返回的随机验证码:%s' % code) |
| confirm_code = input('请输入验证码>>>:') |
| |
| code_upper = code.upper() |
| confirm_code_upper = confirm_code.upper() |
| if code_upper == confirm_code_upper: |
| print('验证码正确') |
| else: |
| print('验证码错误') |
| |
| res1 = 'my name is {} my age is {}' |
| print(res1.format('jason', 18)) |
| |
| res2 = 'my name is {0} my age is {1} {0} {1} {1} {1}' |
| print(res2.format('jason', 18)) |
| |
| res3 = '{name} {name} {age} my name is {name} my age is {age}' |
| print(res3.format(name='jason', age=18)) |
| # 方式4:推荐使用 |
| name = 'jason' |
| age = 18 |
| print(f'my name is {name} my age is {age} {name} {age}') |
| res = 'sdashdjasdwjjkashdjasdjqwhasjdjahdjwqhdjkasdhwsdaadadadaprint(res.count('j')) |
| print(res.count('ad')) |
| res = 'jason say ha ha ha heiheihei' |
| print(res.startswith('jason')) |
| print(res.startswith('j')) |
| print(res.startswith('b')) |
| print(res.endswith('heiheihei')) |
| print(res.endswith('hei')) |
| print(res.endswith('h')) |
| res = 'jason jason jason SB SB SB' |
| print(res.replace('jason', 'tony')) |
| print(res.replace('jason', 'tony', 1)) |
- 字符串的拼接
- 字符串支持加号拼接
- 字符串支持乘号重复
- join方法拼接
- 列表中的数据都必须是字符串类型
| res1 = 'hello' |
| res2 = 'world' |
| print(res1 + res2) |
| print(res1 * 10) |
| print(''.join(['hello', 'world', 'hahaha'])) |
| print('|'.join(['hello', 'world', 'hahaha'])) |
| print('$'.join(['jason', 'say', 666])) |
| print('123'.isdigit()) |
| print('123a'.isdigit()) |
| print(''.isdigit()) |
| res = 'hello world jason' |
| print(res.index('d')) |
| print(res.find('d')) |
| |
| print(res.index('d',0,5)) |
| |
| print(res.find('d',0,5)) |
| res = 'my name is jason' |
| print(res.title()) |
| print(res.capitalize()) |
4.列表相关方法
4.1.列表
- 概念:存储多个数据,能方便获取整体或者局部
- 关键字:list
4.2.类型转换
| print(type(list(123))) |
| print(type(list(123.22))) |
| print(type(list('123243jasdsad')), list('123243jasdsad')) |
| print(type(list({'name':"jason",'pwd':123})), list({'name':"jason",'pwd':123})) |
4.3.需掌握的方法
| l1 = ['jason', 'kevin', 'oscar', 'tony'] |
| print(l1[0]) |
| print(l1[-1]) |
| l1 = ['jason', 'kevin', 'oscar', 'tony'] |
| print(l1[0:3]) |
| print(l1[:]) |
| print(l1[-4:-1]) |
| l1 = ['jason', 'kevin', 'oscar', 'tony'] |
| print(l1[::2]) |
| l1 = ['jason', 'kevin', 'oscar', 'tony'] |
| print(len(l1)) |
作业
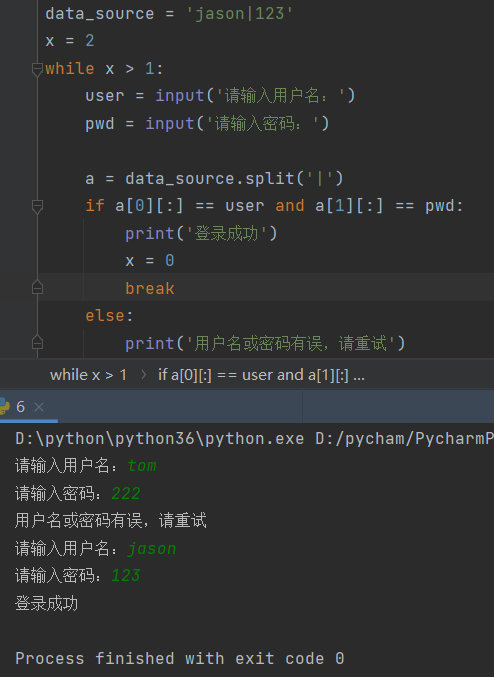
1.基于字符串充当数据库完成用户登录(基础练习)
data_source = 'jason|123' # 一个用户数据
获取用户用户名和密码 将上述数据拆分校验用户信息是否正确
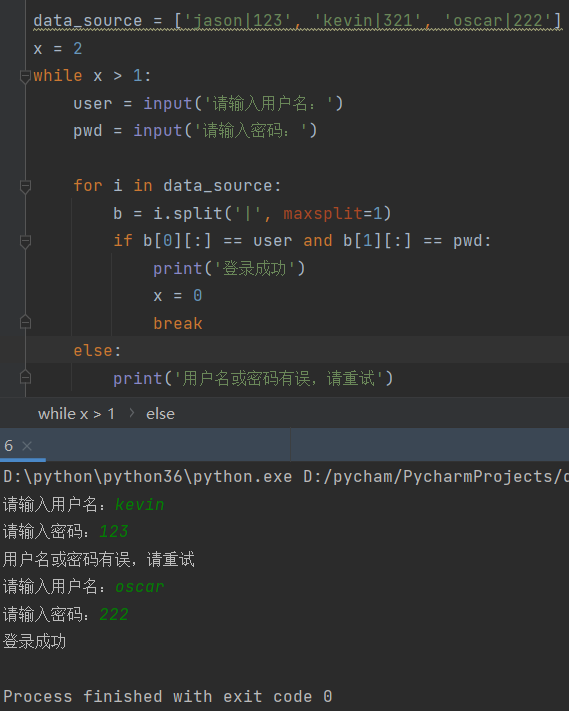
2.基于列表充当数据库完成用户登录(拔高练习) # 多个用户数据
data_source = ['jason|123', 'kevin|321','oscar|222']




 posted on
posted on

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)