

DHT(Distributed Hash Tables)
一. 前言
DHT 分布式哈希表是一个分布式系统,它提供了一个类似哈希表一样的查询服务:key-value 存储在 DHT 中,任何参与的节点都可以有效的检索给定key对应的value.key-value 的映射由网络中所有的节点维护,每个节点负责一小部分路由(其他节点的 ID 和 IP)和数据存储(文件的发布者).这样即使有节点加入或者离开,对整个网络的影响都很小,于是 DHT 可以扩展到非常庞大的节点(上千万).DHT 广泛应用于各种p2p 系统,用来存储节点的元数据
DHT 具有以下性质:
- 离散型: 构成系统的节点之间是对等的,没有中央控制机构进行协调
- 伸缩性: 不论系统有多少个节点,都要求高效工作
- 容错性: 节点加入或离开不会影响整个系统的工作
Kademlia 协议(以下简称 Kad)是 DHT 的一种实现,使用了异或算法为距离度量基础,建立了一种全新的 DHT 拓扑结构,相比于其他算法,大大提高了路由查询速度.
简单流程:
- 节点生成 ID,各个节点根据 ID 构建 K 桶
- x 节点发布文件
a. 计算文件 ID y
b. 找到节点 x 的 K 桶中和这个文件ID 距离最近的节点z
c. z 继续在自己的 K 桶中寻找和这个文件ID 距离最近的节点
d. 重复 b,c 直到和该文件距离最近的节点
e. 该节点存储发布这个文件的节点信息 - z 节点下载文件 y
a. 类似发布过程,找到与文件 y 的 ID 最近的节点
b. 从这个节点获取文件的发布者信息
c. 从发布者上下载文件 y
简单来说,就是网络中有 3 种身份,发布者,传播者,下载者,发布者提供源文件下载,传播者和文件 ID 绑定,来提供发布者的信息,下载者根据文件 ID 找到传播者,获取到发布者信息,在发布者那里下载
二. 结构
在Kad 网络中,所有节点和文件都有一个有 sha-1 生成的 160bit 位的 ID 值,所有的节点由其 ID 构建出一个前缀二叉树
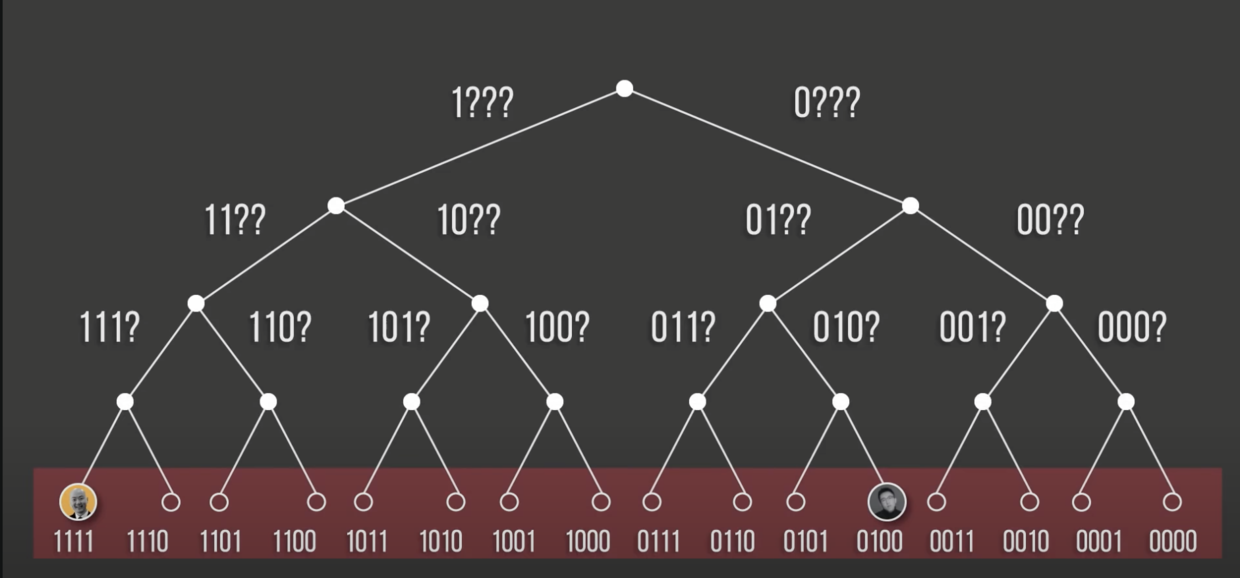
节点之间的距离由两个节点的 ID 异或操作后得到
$$(0111)_B \cdot (1010)_B = (1101)_B = 13$$
三. K 桶
将二叉树拆分为多个子树,每个节点在本地存储一颗子树的部分节点,想要找到一个具体的节点时,找到本地缓存的距离其最近的节点,然后通过这个节点找到目标的节点.
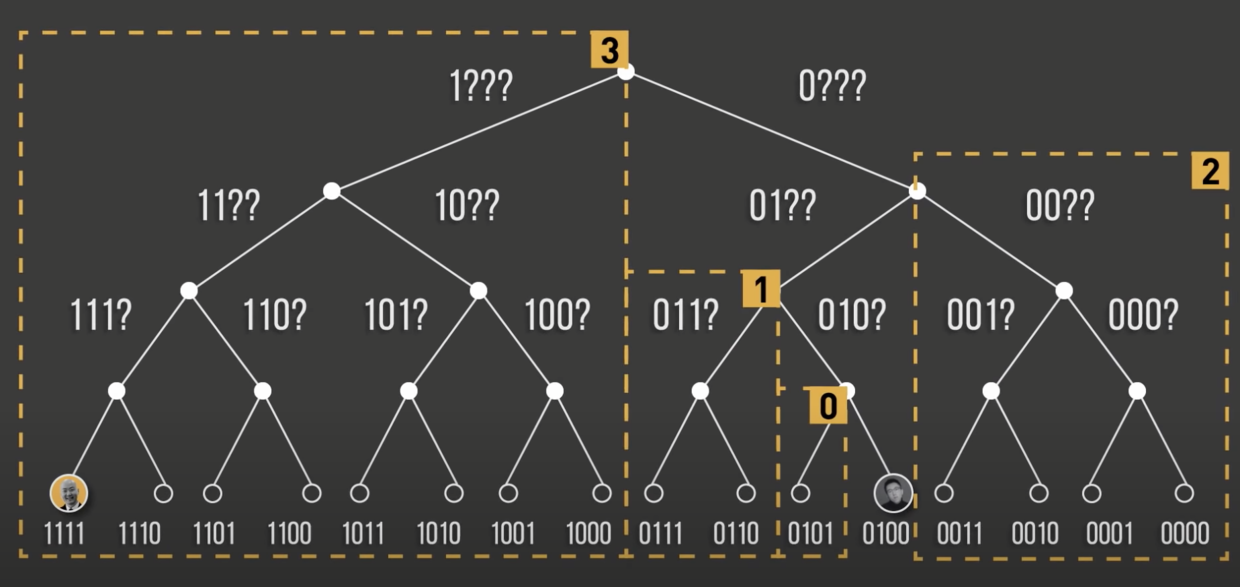
每一颗子树就是一个 K 桶,这也是 Kad 网络的路由表,
当节点 x 收到一个 PRC 消息时,发送者 y 的 IP 地址就被用来更新对应的 K 桶,具体步骤如下
- 计算自己和发送者的距离
- 通过距离 d 选择对应的 K 桶进行更新操作
- 如果 y 的 IP 地址已经存在于K 桶中,则把对应项移到该 K 桶的尾部
- 如果 y 的 IP 地址没有记录在 K 桶中
a. 如果该 K 桶的记录小于 k 个,则直接把 y 的信息插入队列尾部
b. 如果 该 K 桶的记录大于 k 个,则选择头部的记录项 z 进行 PRC_PING 操作
1. 如果 z 没有相应,则在 K 桶中移除 Z,并把 y 插入队尾
2. 如果 z 响应,则忽略 y,并把 z 的信息移到队尾
因为研究用户行为发现,节点的是小概率和在线时长成反比,所以通过优先保留老节点,来增加 Kad 网络的稳定性和减少网络维护成本
回形针有一期介绍了 BT 和 DHT,可以看一下 https://www.youtube.com/watch?v=jp0bF9Qu2Jw


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构