docker 容器技术概述与简单用法
1. 简介
最初没有虚拟机,所有的应用都直接运行在物理机上,计算和存储资源都很难增减,并且在云服务中很难对用户资源/操作进行隔离,所以虚拟机出现了并被广泛适用,而物理机的使用场景被极大地压缩到了像数据库系统这样的特殊应用上.但现有的虚拟机技术方案,都无法避免两个主要的问题,一个是Hypervisor本身的资源消耗与磁盘I/O性能的降低,另一个是虚拟机仍然是一个独立的操作系统,对很多类型的应用来说都显得太重了(比如web服务).
所以,容器技术应运而生并逐渐火热,所有应用可以直接运行在物理机的操作系统上,可以直接读/写磁盘,应用之间通过计算、存储和网络资源的namespace 进行隔离,为每个应用形成一个逻辑上独立的"容器操作系统".
2. 容器技术框架

- 服务器层包含了容器runtime的两种场景,泛指容器运行的环境.
- 资源管理层的核心目标是对服务器和操作系统的资源进行管理,以支持上层的容器运行引擎.
- 运行引擎主要指常见的容器系统,包括Docker、rkt、Hyper、CRI-O,负责启动容器镜像、运行容器应用和管理容器实例.
- 运行引擎又可以分为:
- 管理程序(Docker Engine、OCID、hyperd、rkt、CRI-O等)
- 运行时环境(runC/Docker、runV/Hyper、runZ/Solaris等)
- 运行引擎是单机程序(类似于虚拟化中的KVM和Xen),运行于服务器操作系统之上,接受上层集群管理系统的管理.
- 容器的集群管理系统类似于针对虚拟机的集群管理系统,他们都是对一组服务器运行分布式应用来提供管理服务.常见的容器集群管理系统有Kubernetes、Docker Swarm、Mesos,其中Kubernetes是主流.
3. Docker
3.1. Docker 架构
Docker 使用Client-Server模型(mysql,etcd等也采用这种模型),Client接收用户的请求,然后发送给Server端,Server端收到消息后,执行相应的动作,包括编译、运行、发布容器等.其中,Client和Server既可以运行在相同的主机上,也可以运行在不同的主机上,他们之间可以通过RESTful API、socket等进行交互,Docker 架构如下图所示.
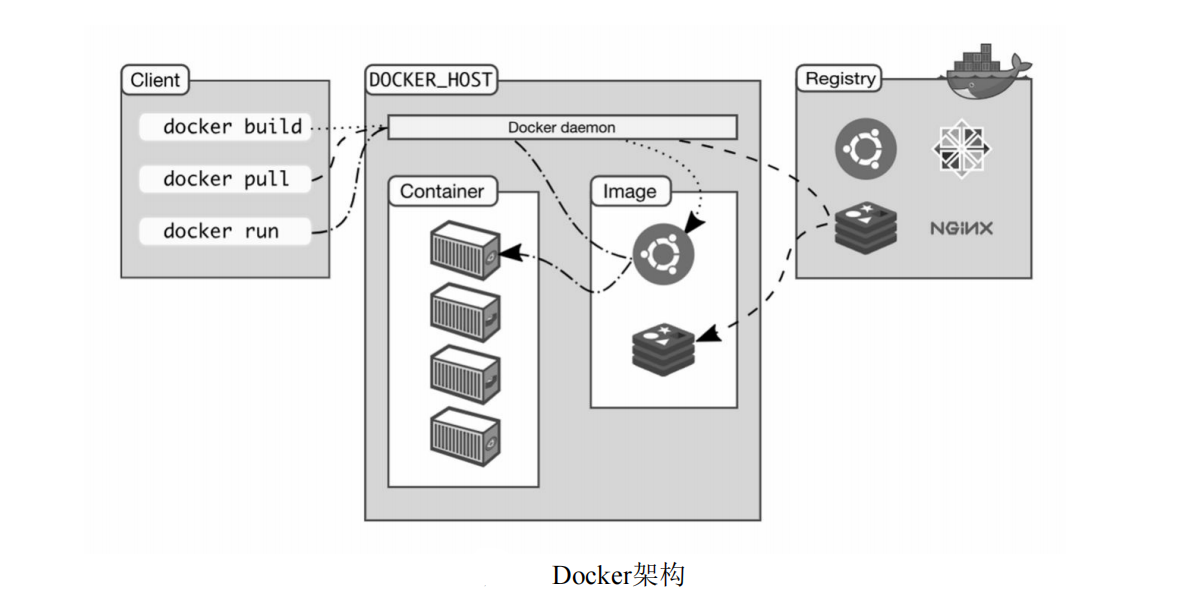
1)Docker Daemon
Docker Daemon(Dockerd)始终监听是否有新的请求到达.当用户调用某个命令或API时,这些调用将被转化为某种类型的请求发送给Daemon.Docker Daemon管理各种Docker对象,包括镜像(Image),容器(Container),网络(Network),卷(Volume)等.
2)Docker Client
Docker Client是Docker用户与Daemon进行交互的主要方式.当我们在shell中输入docker命令时,Docker Client将封装消息并传递给Daemon,Daemon根据消息的类型来采取不同的行动.
3)Docker 仓库
Docker 仓库存储着Docker 镜像.Docker Hub和Docker Cloud是公共的Docker仓库,任何人都可以将自己本地镜像上传到公共仓库,或者下载公共仓库的镜像到本地.我们可以使用配置文件来指定Docker仓库的位置.
3.2. 容器与镜像
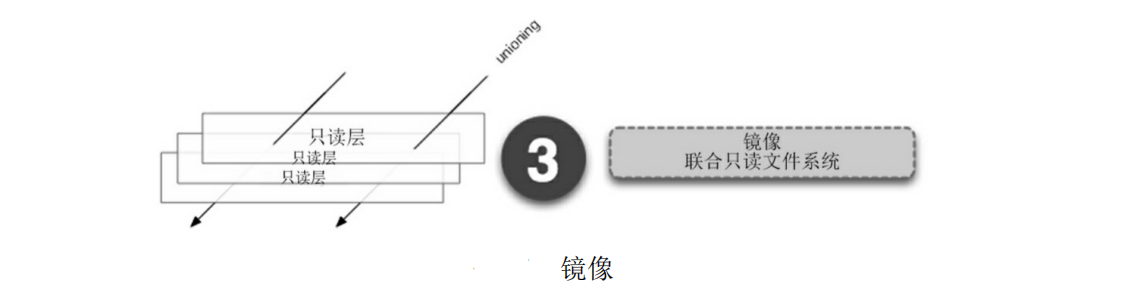
通过运行一个镜像(Image)来产生一个容器(Container).如下图所示,镜像就是一堆只读层(Read Layer)的叠加,每一层都有一个指针指向它的下一层.Docker通过联合文件系统(Union File System, UnionFS)技术将不同的层整合成一个文件系统,屏蔽了多层的存在,为用户提供了一个统一的视角--一个镜像只存在一个文件系统.
分层存储的特征使得镜像的复用、定制变得更为容易.甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像.
镜像除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数.但不包含任何动态数据,其内容在构建之后也不会被改变.
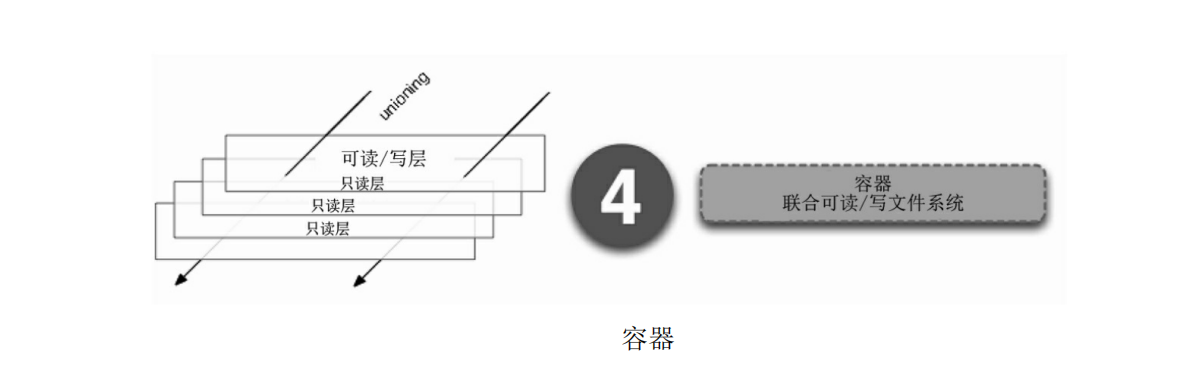
与镜像类似,容器也是一堆层的叠加,唯一的区别在于,容器最上面那一层是可读/写的.在容器存在的生命周期,任何修改都将被写在可写层,包括创建、修改、删除文件等,如下图所示.
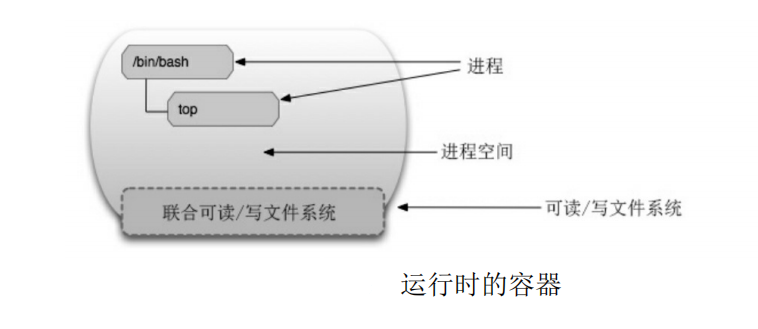
容器进程运行于属于自己的独立的namespace。因此容器可以拥有自己的root文件系统、自己的网络配置、自己的进程空间,甚至自己的用户ID空间。容器内的进程是运行在一个隔离的环境里。
3.3. Docker 常用操作
3.3.1 镜像 Image 相关
-
列出本地镜像
docker images -
获取远端镜像
docker pull [OPTIONS] NAME[:TAG|@DIGEST] -
删除本地镜像
docker rmi [OPTIONS] IMAGE [IMAGE...] -
创建镜像
- 从已经创建的容器中更新镜像,并提交这个镜像
docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
- 使用Dockerfile 创建一个镜像
docker build [OPTIONS] PATH | URL | -
- 从已经创建的容器中更新镜像,并提交这个镜像
-
查看镜像历史
docker history [OPTIONS] IMAGE -
导入容器快照
docker import [OPTIONS] file|URL|- [REPOSTITORY[:TAG]]
3.3.2 容器 Container 相关
- 查看容器修改
docker diff CONTAINER - 在新容器运行COMMAND
docker run [OPTIONS] IMAGE [COMMAND] [ARG...]示例
docker run -it ubuntu /bin/bash-i交互式操作-t分配一个伪ttyubuntu镜像名/bin/bashcommand,表示容器启动命令
- 列出容器
docker ps [OPTIONS] - 启动若干个停止的容器
docker start [OPTIONS] CONTAINER [CONTAINER...] - 停止若干个运行中的容器
docker stop [OPTIONS] CONTAINER [CONTAINER...] - 重启若干个容器
docker restart [OPTIONS] CONTAINER [CONTAINER...] - 删除若干个容器
docker rm [OPTIONS] CONTAINER [CONTAINER...] - 将容器导出快照为tar存档
docker export [OPTIONS] CONTAINER - 查看容器日志
docker logs [OPTIONS] CONTAINER - 查看容器端口映射
docker port CONTAINER [PRIVATE_PORT[/PROTO]]
3.4. Dockerfile
我们下载开源软件时可以下载源码并编译或直接下载安装包,下载源码可以减少我们的流量,但编译的过程对绝大多数人不太友好,很多软件对编译环境的要求很苛刻,通常需要耗费很多精力才能完成,所以我们一般都选择直接下载安装包.
Docker 完美解决了这个问题,每个Docker Image 都开始于一个洁净的操作系统,只需要Dockerfile(相当于之前的源码)就可以自动完成应用的构建,在此期间我们只需要下载若干kb的Dockerfile(在第一次构建时需要下载操作系统)而不需要手动搭建环境和下载可能很大安装包.因为初始的操作系统是相同的,所以不论在任何环境下都能正确的获得我们想要的结果.
3.4.1. 基础命令
LABEL & MAINTAINER
LABEL 相当于注释
MAINTAINER 来标识组织或个人
FROM
导入基准镜像, 开始必须是FROM,可以使用多个FROM
RUN
执行命令,尽量将多条命令使用&&和 \ 合并成一行,减少无意义的分层.
WORKDIR
指定工作目录
ADD & COPY
将文件复制到容器指定路径,ADD是COPY的升级版,源路径可以是URL,并且会自动解压tar至目标路径.大部分情况COPY优于ADD
ENV
设置环境变量
EXPOSE
声明端口,在运行时使用-P随机端口映射时,会自动随机映射EXPOSE的端口,
要和-p <主机端口:容器端口> 区分开,-p是映射主机端口和容器端口,换句话说,就是将容器的对应端口服务公开给外界访问,而 EXPOSE 仅仅是声明容器打算使用什么端口而已,并不会自动在宿主进行端口映射。
USER
指定当前用户
VOLUME
指定容器挂载目录
CMD
用于指定默认的容器主进程的启动命令, 如果存在多个CMD,仅最后一个生效
ENTRYPOINT
设置程序入口点,指定 ENTRYPOINT后不会被docker run的命令行参数或CMD指定的指令或所覆盖,而且这些参数会被当作参数传递给ENTRYPOINT指令指定的程序.
# Dockerfile
FROM ubuntu:18.04
RUN apt-get update \
&& apt-get install -y curl \
&& rm -rf /var/lib/apt/lists/*
ENTRYPOINT [ "curl", "-s", "http://myip.ipip.net" ]
# 启动容器
docker run myip -i //-i不会替代curl,而是传给curl
3.4.2. Dockerfile 示例
很多开源软件都编写了自己的Dockerfile,其中大部分都写得很好.我找了一个比较全面的Dockerfile放在这里,供大家参考.
FROM ubuntu:18.04 AS builder
ENV RUSTUP_HOME=/usr/local/rustup \
CARGO_HOME=/usr/local/cargo \
PATH=/usr/local/cargo/bin:$PATH \
DEBIAN_FRONTEND=noninteractive
RUN set -eux ; \
apt-get update -y && \
apt-get dist-upgrade -y && \
apt-get install -y --no-install-recommends \
ca-certificates \
gcc \
libc6-dev \
wget \
build-essential \
clang \
gcc \
libssl-dev \
make \
pkg-config \
xz-utils && \
dpkgArch="$(dpkg --print-architecture)"; \
case "${dpkgArch##*-}" in \
amd64) rustArch='x86_64-unknown-linux-gnu' ;; \
arm64) rustArch='aarch64-unknown-linux-gnu' ;; \
*) echo >&2 "unsupported architecture: ${dpkgArch}"; exit 1 ;; \
esac; \
\
url="https://static.rust-lang.org/rustup/dist/${rustArch}/rustup-init"; \
wget "$url"; \
chmod +x rustup-init; \
./rustup-init -y --no-modify-path --default-toolchain stable; \
rm rustup-init; \
chmod -R a+w $RUSTUP_HOME $CARGO_HOME; \
rustup --version; \
cargo --version; \
rustc --version; \
apt-get remove -y --auto-remove wget && \
apt-get purge -y --auto-remove -o APT::AutoRemove::RecommendsImportant=false && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*;
WORKDIR /usr/src/snarkOS
COPY . .
RUN cargo build --release
FROM ubuntu:18.04
SHELL ["/bin/bash", "-c"]
VOLUME ["/aleo/data"]
RUN set -ex && \
apt-get update && \
DEBIAN_FRONTEND=noninteractive apt-get dist-upgrade -y -o DPkg::Options::=--force-confold && \
DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends ca-certificates && \
apt-get purge -y --auto-remove -o APT::AutoRemove::RecommendsImportant=false && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
mkdir -p /aleo/{bin,data} && \
mkdir -p /aleo/data/params/{git,registry} && \
mkdir -p /usr/local/cargo/git/checkouts/snarkvm-f1160780ffe17de8/ef32edc/parameters/src/ && \
mkdir -p /usr/local/cargo/registry/src/github.com-1ecc6299db9ec823/snarkvm-parameters-0.7.9/src/ && \
ln -s /aleo/data/params/git /usr/local/cargo/git/checkouts/snarkvm-f1160780ffe17de8/ef32edc/parameters/src/testnet1 && \
ln -s /aleo/data/params/registry /usr/local/cargo/registry/src/github.com-1ecc6299db9ec823/snarkvm-parameters-0.7.9/src/testnet1
COPY --from=builder /usr/src/snarkOS/target/release/snarkos /aleo/bin/
CMD ["bash", "-c", "/aleo/bin/snarkos -d /aleo/data"]
4. Docker 进阶概念
- Namespace: Linux 内核特性, 资源隔离
- Cgroups: Linux 内核特性, 资源限制
- OCI: 开放容器计划, 提供容器标准文档
- runC: docker 容器运行时实现, 负责容器启停、资源隔离等功能.
4.1. Namespace
Linux Namespace是Linux 内核用来隔离内核资源的方法.通过namespace可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与他们自己相关的资源,这两拨进程根本就感觉不到对方的存在。
Linux namespace 是对全局系统资源的一种封装隔离,使得处于不同namespace的进程拥有独立的全局系统资源,改变一个namespace中的系统资源只会影响当前namespace里的进程。
4.1.1. Namespace 支持隔离的系统资源类型
- Mount: 隔离文件系统挂载点
- UTS: 隔离主机名和域名信息
- IPC: 隔离进程间通讯
- PID: 隔离进程的ID
- NetWork: 隔离网络资源
- User: 隔离用户和用户组的ID
4.1.2. shell 命令
ip netns
ip netns 用来管理 network Namespace
$ ip netns help
Usage: ip netns list
ip netns add NAME
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]
ip netns identify [PID]
ip netns pids NAME
ip [-all] netns exec [NAME] cmd ...
ip netns monitor
ip netns list-id
unshare
unshare 用来启动程序,并可以与父进程隔离某些 Namespace
$ unshare -h
Usage:
unshare [options] [<program> [<argument>...]]
Run a program with some namespaces unshared from the parent.
Options:
-m, --mount[=<file>] unshare mounts namespace
-u, --uts[=<file>] unshare UTS namespace (hostname etc)
-i, --ipc[=<file>] unshare System V IPC namespace
-n, --net[=<file>] unshare network namespace
-p, --pid[=<file>] unshare pid namespace
-U, --user[=<file>] unshare user namespace
-C, --cgroup[=<file>] unshare cgroup namespace
-f, --fork fork before launching <program>
--mount-proc[=<dir>] mount proc filesystem first (implies --mount)
-r, --map-root-user map current user to root (implies --user)
--propagation slave|shared|private|unchanged
modify mount propagation in mount namespace
-s, --setgroups allow|deny control the setgroups syscall in user namespaces
-h, --help display this help
-V, --version display version
4.2. cgroups
cgroup 即control groups,是linux 内核提供的一个特性,用于限制和隔离一组进程对系统资源的使用,这些资源主要包括CPU,内存,block I/O和网络带宽.
cgroups 主要功能:
- 资源限制: cgroup可以对进程组使用的资源总额进行限制
- 优先级分配: 通过分配的CPU时间片数量及硬盘IO带宽大小,实际上就相当于控制了进程的运行的优先级
- 资源统计: cgroups可以统计系统的资源使用量,如CPU使用市场,内存用量等.
- 进程控制: cgroups可以对进程组执行挂起、恢复等操作
以CPU和内存为例
# 创建cgroups 限制策略组
# mygroup 可以使用编号0-1的cpu和numa node 0 的内存
mkdir /sys/fs/cgroup/cpuset/mygroup
echo "0-1" > /sys/fs/cgroup/cpuset/mygroup/cpuset.cpus
ehco 0 > /sys/fs/cgroup/cpuset/mygroup/cpuset.mems
# 将需要限制的进程加入进程组
ps -aux | grep "进程名"
echo $进程号 >> /sys/fs/cgroup/cpuset/mygroup/cgroup.procs
4.3. bocker bash 中100行代码的docker 实现
使用本章介绍的技术就可以在shell 中实现一个较为简单的docker,docker 本身也是基于这些技术的,不过他使用的是操作系统提供的系统调用接口.下面的代码是github上的bocker项目,该项目使用约100行bash代码实现了一个简单的docker.
function bocker_run() { #HELP Create a container:\nBOCKER run <image_id> <command>
uuid="ps_$(shuf -i 42002-42254 -n 1)"
[[ "$(bocker_check "$1")" == 1 ]] && echo "No image named '$1' exists" && exit 1
[[ "$(bocker_check "$uuid")" == 0 ]] && echo "UUID conflict, retrying..." && bocker_run "$@" && return
cmd="${@:2}" && ip="$(echo "${uuid: -3}" | sed 's/0//g')" && mac="${uuid: -3:1}:${uuid: -2}"
ip link add dev veth0_"$uuid" type veth peer name veth1_"$uuid"
ip link set dev veth0_"$uuid" up
ip link set veth0_"$uuid" master bridge0
ip netns add netns_"$uuid"
ip link set veth1_"$uuid" netns netns_"$uuid"
ip netns exec netns_"$uuid" ip link set dev lo up
ip netns exec netns_"$uuid" ip link set veth1_"$uuid" address 02:42:ac:11:00"$mac"
ip netns exec netns_"$uuid" ip addr add 10.0.0."$ip"/24 dev veth1_"$uuid"
ip netns exec netns_"$uuid" ip link set dev veth1_"$uuid" up
ip netns exec netns_"$uuid" ip route add default via 10.0.0.1
btrfs subvolume snapshot "$btrfs_path/$1" "$btrfs_path/$uuid" > /dev/null
echo 'nameserver 8.8.8.8' > "$btrfs_path/$uuid"/etc/resolv.conf
echo "$cmd" > "$btrfs_path/$uuid/$uuid.cmd"
cgcreate -g "$cgroups:/$uuid"
: "${BOCKER_CPU_SHARE:=512}" && cgset -r cpu.shares="$BOCKER_CPU_SHARE" "$uuid"
: "${BOCKER_MEM_LIMIT:=512}" && cgset -r memory.limit_in_bytes="$((BOCKER_MEM_LIMIT * 1000000))" "$uuid"
cgexec -g "$cgroups:$uuid" \
ip netns exec netns_"$uuid" \
unshare -fmuip --mount-proc \
chroot "$btrfs_path/$uuid" \
/bin/sh -c "/bin/mount -t proc proc /proc && $cmd" \
2>&1 | tee "$btrfs_path/$uuid/$uuid.log" || true
ip link del dev veth0_"$uuid"
ip netns del netns_"$uuid"
}
4.4. OCI
2015年6月,Docker公司与Linux基金会等联合推出开放容器标准(Open Container Initiative, OCI).总的来说,如果容器以Docker作为标注,那么Docker接口的变化将导致社区中所有相关工具都要更新,不然就无法正常使用;如果没有标注,这将导致容器实现的碎片化,出现大量的冲突和冗余.OCI就是在这个背景下出现的,它的使命就是推动容器标准化,使容器能够运行在任何的硬件和操作系统上,相关的组件也不比绑定在任何的容器运行时上.
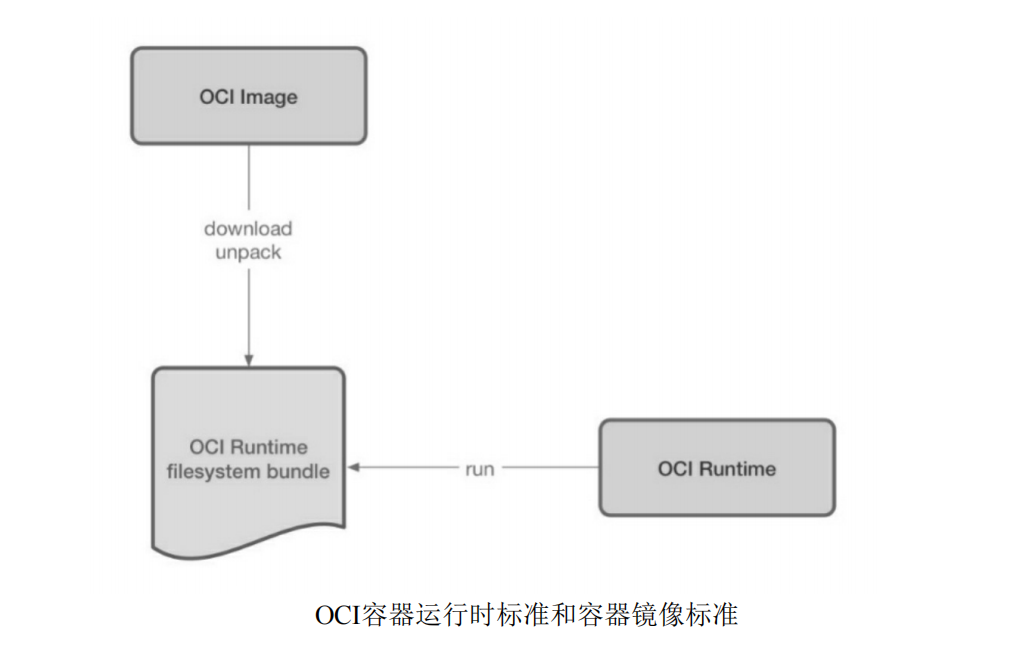
目前OCI主要由两个标准文档:容器运行时标准(Runtime Spec)和容器镜像标准.如下图所示,这两个协议通过OCI Runtime filesystem bundle的标准格式连接在一起,OCI镜像可以通过工具转化成bundle,然后OCI容器引擎通过识别这个bundle来运行容器.
4.5. RunC
RunC 是从Docker的libcontainer中迁移而来的,实现了容器启停、资源隔离(和3.3的内容类似)等功能.Docker 将RunC捐赠给OCI作为OCI容器运行时标准(Runtime Spec)的参考实现.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号