Raft 一致性协议
1 简介
在分布式系统的数据冗余(复制集)中我们提到在中心化复制集中主节点选举是非常重要的一个步骤.最初所有节点都是普通节点,经过选举/指定操作后有了主节点才能对外提供服务,并且当主节点失效时能够快速的在所有机器中重新选择一个主节点.
RAFT 是一个简单实用的一致性协议(在区块链中一般称为共识协议),RAFT 经过一段时间在集群中选举出 Master 节点,并且当任意节点失效时也总能快速恢复.共识协议总是少数服从多数的,不论是RAFT 还是PBFT(他们对集群中错误节点容错不同,分别为1/2 和 1/3, 这个数字是经过证明的,具体过程需要搜索拜占庭将军问题深入探讨).所以RAFT 有几个问题待讨论:
- 错误节点数量超过正确节点数量时系统就不能正确运行
- 一般RAFT节点数量选择3,5...
- RAFT 节点数量需要事先确认,不能随意更改
RAFT 中有三种角色,分别是leader(主节点), follower(从节点), candidate.正常情况时系统中只有一个leader,其他都是follower.
RAFT 将共识问题分为三个子问题:
leader election 领导选举: 有且仅有一个leader 节点,如果 leader 宕机,通过选举机制选出新的 leader;log replication 日志复制: leader 从客户端接收数据更新/删除请求,然后日志复制到follower 节点,从而保证集群数据的一致性.safety 安全性: 通过安全性原则来处理一些特殊case,保证 Raft算法的完备性
Raft算法核心流程可以归纳为:
- 选举leader, 由 leader 负责接收外部的数据更新/删除请求
- leader 将日志复制到其他 follower 节点,同时通过安全性的准则来保证整个日志复制的一致性
- 遇到leader 故障, followers 重新发起选举得到新的leader
RAFT 算法流程简单描述
2.1 Leader election 领导选举
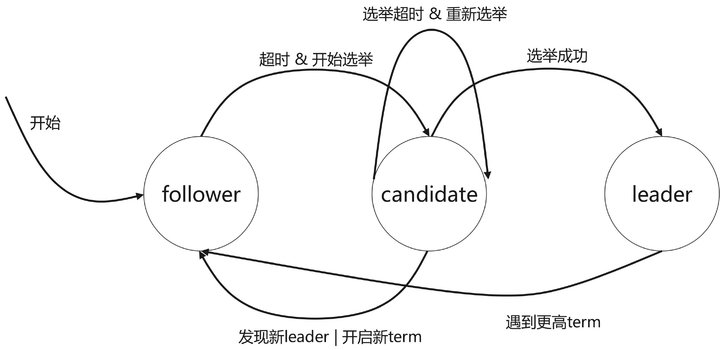
raft leader 选举流程:
- 最初所有节点都为 follower 状态
- follower 一定时间后没有收到leader 心跳,那么他们可以变为 condidate,并进入新任期
- condidate 向其他节点拉票
- followers 向condidate 投票
- condidate 获得了半数以上的投票,状态变为leader
- 如果condidate 投票失败(所有condidate票数不够半数),那进入新term,重新开始选举
注: term是RAFT 对时间的划分,每个term 有唯一的编号,term id 单调递增.每个leader 在任期内周期性的向follower发送心跳,当任期结束或follower 接收心跳超时后,重新开始选举流程.如果集群内有多个leader, 以term id 大的为准
节点状态变化如下图所示
2.2 Log replication 日志复制
日志复制流程:
- client 通过 leader 内更新log
- leader 通知所有 follower 此次更新
- 半数以上follower 同意此次更新, 则该log 从uncommitted变为committed 状态
2.3 Safety 安全性
- Election Safety 选举安全性
在任意Term内,最多选举出一个leader
- Leader Append-Only 日志修改原则
Leader 不会覆盖或删除log,只会追加log
- Log Matching 日志匹配
如果两个节点上的日之项拥有相同的index 和 term,name这两个节点[0, index]范围内的log完全一致
- leader Completeness 选举完备性
拥有最新日志项的follower才会被选为leader
- State Machine Safety 状态机安全性
一旦某个server将某个log应用于本地状态机,以后所有server 对于该偏移都将应用相同日志项
2.4 解释
直观解释:
为了便于大家理解Raft算法的正确性,这里对于上述性质进行一些非严格证明。
“ElectionSafety”:反证法,假设某个Term同时选举产生两个LeaderA和LeaderB,根据选举过程定义,A和B必须同时获得超过半数节点的投票,至少存在节点N同时给予A和B投票,矛盾
LeaderAppend-Only: Raft算法中Leader权威至高无上,当Follower和Leader产生分歧的时候,永远是Leader去覆盖修正Follower
LogMatching:分两步走,首先证明具有相同Index和Term的日志项相同,然后证明所有之前的日志项均相同。第一步比较显然,由Election Safety直接可得。第二步的证明借助归纳法,初始状态,所有节点均空,显然满足,后续每次AppendEntries RPC调用,Leader将包含上一个日志项的Index和Term,如果Follower校验发现不一致,则拒绝该AppendEntries请求,进入修复过程,因此每次AppendEntries调用成功,Leader可以确信Follower已经追上当前更新
LeaderCompleteness:为了满足该性质,Raft还引入了一些额外限制,比如,Candidate的RequestVote RPC请求携带本地日志信息,若Follower发现自己“更完整”,则拒绝该Candidate。所谓“更完整”,是指本地Term更大或者Term一致但是Index更大。有了这个限制,我们就可以利用反证法证明该性质了。假设在TermX成功commit某日志项,考虑最小的TermY不包含该日志项且满足Y>X,那么必然存在某个节点N既从LeaderX处接受了该日志项,同时投票同意了LeaderY的选举,后续矛盾就不言而喻了
StateMachine Safety:由于LeaderCompleteness性质存在,该性质不言而喻
3 总结
本文只对Raft 算法流程进行大致的描述,因为个人认为所有一致性算法就是简单的是少数服从多数,其中的设计细节无非是某一类问题的特殊解决方法,比如RAFT 可以容纳少于1/2 的节点出错,这是因为它的应用场景一般是内部网络,不会有节点作恶的情况.而PBFT 应用于多方分布式集群中,因为拜占庭将军问题,所以它只能容纳少于1/3的拜占庭节点.
其他的比如选举时的随机定时可以减少内耗,防止所有follower在leader失效时同时选举.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号