分布式系统的数据冗余(复制集)
一. 简介
分布式系统中有大量机器,家用机器平时很难遇到的断电,断网,磁盘损坏,机器宕机等小概率问题乘以机器规模都是一个不容忽视的.因此保证数据不会丢失是分布式系统一个必须解决的问题.
为了避免因单点异常引发的系统可靠性和高可用问题,可行的办法就是数据冗余,也称为复制集.即将同一数据放置在不同机器,机架,数据中心甚至不同城市和国家.
复制集管理有两种,分别是去中心化复制集和中心化复制集
去中心化复制集的特点是,无中心节点,所有节点地位平等都可以进行读写请求,通过节点间的协商达到数据的一致.我们常见的区块链公链系统都是去中心化复制集,他们通过共识算法来达到数据的一致.通常这类系统的可用性很高,但是一致性很差,为了提供可用的服务通常设计要经过很长的时间才能达成共识,tps 很低,例如比特币每秒最多进行7 笔交易而支付宝是几十万.
中心化复制集的特点是,节点之间有主从逻辑关系,主节点负责所有请求的写操作,从节点复制主节点的数据,当主节点异常时在从节点中选举一个新的主节点.相对去中心化复制集他的 tps 大大提升,但是只能应用于小规模集群中,或者作为控制中心来管理其他节点,因为当节点数量很多时网络中会充斥着同步包.
去中心化复制集本质上和中心化复制集相同,可以理解为写操作和选主操作绑定在一起,现有的去中心化复制集共识算法可以容纳无限量的节点加入,也是一个不小的优势.
下图中的私链就是中心化复制集,公链是去中心化复制集,联盟链是各一半(这个一半只能意会了).

二. 中心化复制集
主流的后台,云应用中没有使用去中心化复制集的需求,还是需要使用中心化复制集.下面介绍这中心化复制集的三个关键点:
- 主节点和从节点之间的数据一致如何实现?方式是同步还是异步?
- 从节点能否提供数据读取数据,如果允许,如何保证客户端不会读取到重复或者过时的数据?
- 主节点的选举机制是怎么样的?
1. 主从节点数据更新流程
| 流程 | 特点 | |
|---|---|---|
| 同步更新 | 客户端写入主节点成功后不返回, 主节点向所有从节点复制成功后才向客户端返回 | 安全性高,但效率低 |
| 异步更新 | 客户端写入主节点成功后返回, 主节点在一个时间点向所有从节点复制 | 安全性低,主节点返回成功后宕机这个数据就会丢失,效率高 |
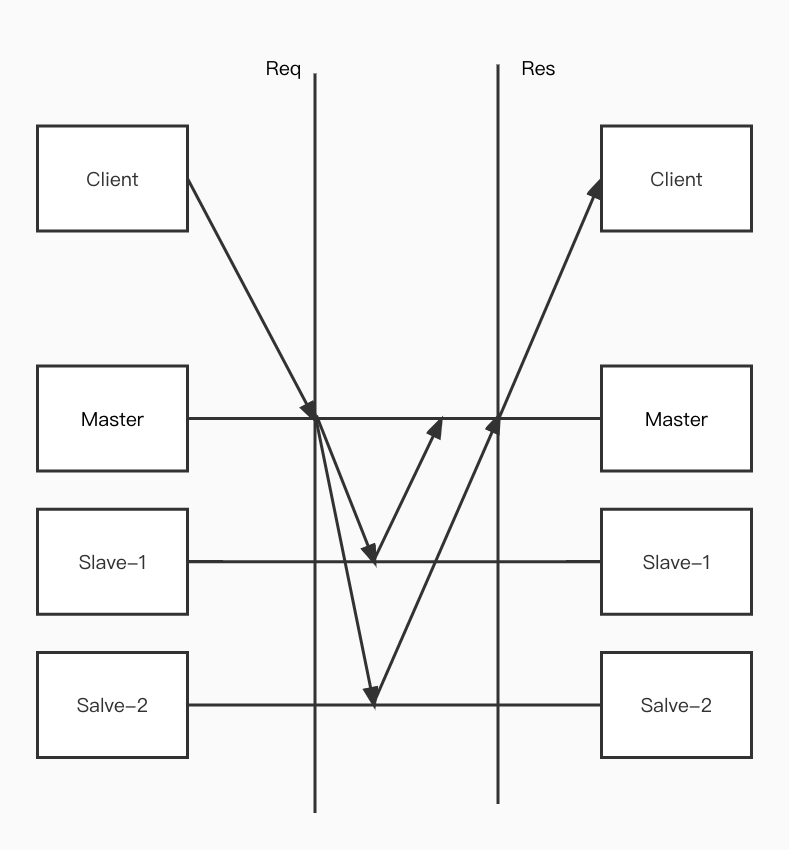

2. 数据更新具体方式
不论是异步还是同步数据最终还是要写入每个从节点的.有多种方式
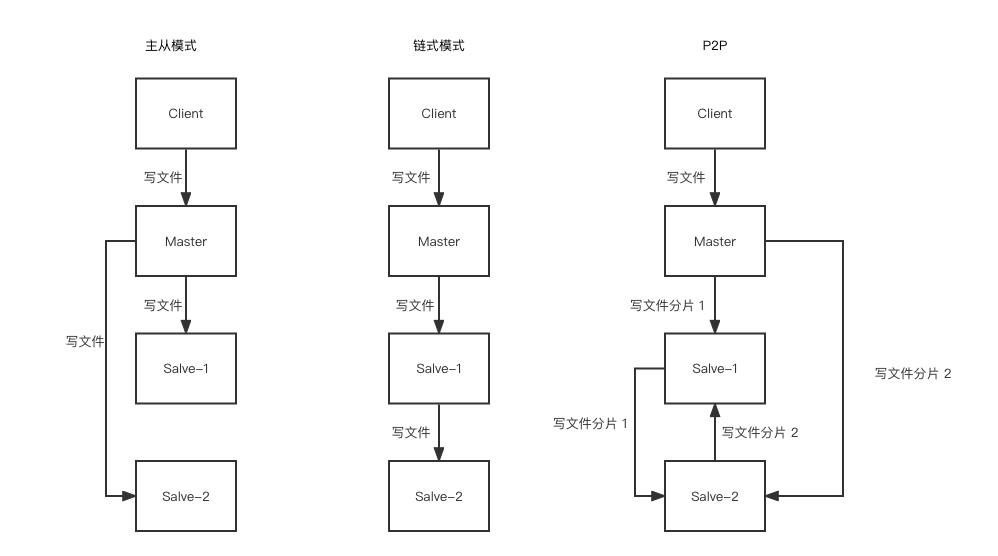
- 主从模式: 即从主节点复制到每个从节点,优点是结构简单,延迟小.缺点是主节点压力大
- 链式模式: 把从节点当成其他从节点的主节点.比如 A,B,C三个节点,A 是主节点,B 是从节点的同时也是 C 的主节点.优点是节点压力均衡,缺点是延迟大,结构复杂
- P2P 模式: 有 1 个主节点n 个从节点.将数据分为 n 片,主节点给每个从节点发一片,从节点轮询其他从节点交换分片.优点是节点压力均衡,延迟不高,缺点是结构复杂
所以一般使用主从模式和P2P 模式,不考虑链式模式
3. 部分节点写入失败
分布式存储中的数据服务大多数是一种尽力而为的服务模型,不保证一定成功.保持原子性:要么都更新成功,要么都不更新,而不会出现部分节点更新成功的情况.这样的代价太大,所以一般是在数据安全和可用性中根据系统需求做出具体的处理.
比如可以在写入失败后重试,然后定期删除和迁移重复或位置错误的分片或副本.或有节点写入失败后直接向客户端返回失败,当然这样也需要定期删除重复或错误的副本.
4. 数据读取
从节点只是提供冗余功能保证数据不会丢失还是也要提供读功能降低主节点压力?
从节点提供读服务可能会出现同步不及时的数据不一致,需要强一致性的场合一定不能使用,比如在 GFS 中 master 只有主节点提供读服务.
在一致性需求不强烈的场景可以从节点也可以提供读功能,比如 Redis 缓存从节点很大可能和主节点不完全一致.
5. 主节点选举机制
中心化复制集的主节点选举机制一般有两种:上级指定或民主选举.
5.1. 上级指定主节点
Redis 集群的主从模式和哨兵模式都是采用的上级指定,当主节点宕机后手动(主从模式)或由哨兵节点(哨兵模式)将一个从节点提升至主节点
在 GFS 的写 Chunk 中使用 Lease 机制来选择主 Chunk,并且可以确保同一时刻只有一个主,可以简单理解为Master 指定任意一个 Chunk 副本获取了关于该Chunk 的带过期时间的全局锁,该 Chunk 的其他副本自然而然成为从节点, 具体描述可以参见分布式技术-Lease(租约) 机制.不过要强调一下,这个 Lease 是绑定的是 Chunk ,而不是节点.(和 Rust 的互斥锁类似)
5.2. 民主选举
Paxos 和 Raft是常用的去中心化选举协议, Zookeeper, Etcd, Kafka等分布式组件都是使用这些协议来自动推举主节点.一句话描述 Raft 就是少数服从多数, 所以缺点也是增加或减少节点需要重启集群,因为总数确定才能有多数和少数之分.
三. 去中心化复制集
以 BTC 为例, 每个节点都根据上一个区块(相当于链表的 Node)的信息加一个无意义字符串计算一个哈希值,这个 hash 有很小的概率以若干个 0开始(0 越多难度越大).通常要很多次计算才能算出一个答案,算出答案的节点就有了打包下一个区块的权利,人们只需要一次 hash 计算就可以验证它的答案是否正确.但是可能会因为网络问题,多个人都算出了自己的答案.
这时区块链就在此分叉了. 接下来每个人都任意选择一条链并以此为准继续计算.但总会有一个时刻这些链条的长度(区块的数量) 会有很大的差异,而人们总会以最长的链条作为最好的,并在最长链条后继续工作.所以最终所有人还是会达成一致.这也就是最终一致性.
在上面的例子中,计算答案就相当于中心化复制集的主节点选举,打包下一个区块就相当于主节点对整个网络的一次写操作.因为一个时刻可能会有多个主,所以去中心化复制集的一致性弱于中心化复制集.但人们通过选择最长的链条达成了最终一致性.
总结
本文介绍了分布式系统中使用广泛的中心化复制集和去中心化复制集,结合了网络上的资料和自己的一些思考,总体来看协议不是很复杂,但在工程实践中还是要注意细节.限于本文的作者水平,文中的错误在所难免,恳请大家批评指正.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号