[Lucene]-Lucene基本概述以及简单实例
一、Lucene基本介绍:
- 基本信息:Lucene 是 Apache 软件基金会的一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
- 文件结构:自上而下树形展开,一对多。
- 索引Index:相当于库或者表。
- 段Segment:相当于分库或者分表。
- 文档Document:相当一条数据 ,如小说吞噬星空
- 域Field:一片文档可以分为多个域,相当于字段,如:小说作者,标题,内容。。。
- 词元Term:一个域又可以分为多个词元,词元是做引搜索的最小单位,标准分词下得词元是一个个单词和汉字。
- 正向信息:
- 索引->段->文档->域->词
- 反向信息:
- 词->文档。
二、Lucene全文检索:
1、数据分类:
- 结构化数据:数据库,固定长度和格式的数据。
- 半结构化数据:如xml,html,等..。
- 非结构化数据:长度和格式都不固定的数据,如文本...
2、检索过程:Luncene检索过程可以分为两个部分,一个部分是上图左侧结构化,半结构化,非结构化数据的索引建立过程,另一部分是右侧索引查询过程。
- 索引过程:
- 有一系列被索引文件
- 被索引文件经过语法分析和语言处理形成一系列词(Term)。
- 经过索引创建形成词典和反向索引表。
- 通过索引存储将索引写入硬盘/内存。
- 搜索过程:
- 用户输入查询关键字。
- 对查询语句经过语法分析和语言分析得到一系列词(Term)。
- 通过语法分析得到一个查询树。
- 通过索引存储将索引读入到内存。
- 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
- 将搜索到的结果文档对查询的相关性进行排序。
- 返回查询结果给用户。

3、反向索引:
luncene检索关键词,通过索引可以将关键词定位到一篇文档,这种与哦关键词到文档的映射是文档到字符串映射的方向过程,所以称之为方向索引。
4、创建索引:
- document:索引文档,
- 分词技术:各种分词技术,标准分词:中文分成单个汉字,英文单个单词。
- 索引创建:得到一张索引表。
5、索引检索:
- 四个步骤:关键词(keyword)->分词方法(analyzer)->检索索引(searchIndex)->返回结果(result)
- 详细步骤:输入一个关键词,使用分词方法进行分词得到词元,到索引表中去检索这些词元,找到包含所有词源的文档,并将其返回。
三、Lucene的数学模型:
1、关键名词:
- 文档:一篇文章是一篇文档。
- 域:文档有可以分错多个域:如文档名,文档作者,文档时间,文档内容。
- 词元:一个域可以分为多个词元,比如说文档名为中华古诗词简介,通过分词可以得到词元:中,华,古,诗,词,简,介。这个是用标准分词得到,词元是搜索的最小单位。
2、权重计算:
- TF:Term Frequency,词元在这个文档中出现的次数,tf值越大,词越重要。
- DF:Document Frequency,有多少文档包含这个词元,df越大,那么词就越不重要。
- 权重计算公式:Wt,d=TFt,d * log(n/DFt),TFt,d表示词元t在文档d出现的次数,n表示文档数,DFt表示包含词元t的文档数。
3、空间向量模型:
- 用一篇文档的每次词元的权重构成一个向量(每个词元的权重值作为向量的维度)来表示这篇文档,这样所有的文档都可以表示成一个N维的空间向量。N表示所有文档分词后的词元集合的词元总数。实例如下:
- 检索过程:m篇文档我们得到了m个N维的空间向量,搜索词我们分词得到x个词元,计算这x个词元的权重,得到一个N维的向量XV,通过计算XV和m个N维向量的相似度(余玄夹角)来表示相关性。Lucene通过这个相关性打分机制来得到返回的文档。
四、官方示例Demo:
- 下载源代码和jar:http://lucene.apache.org/core/
- 核心jar包如下:

-
运行源代码中的demo实例文件和LucenecoreAPI中示例,来看看luncene是如何创建Index和检索的。
- 用Idea构建了一个java项目:如下所示添加这6个核心包,和示例文件。
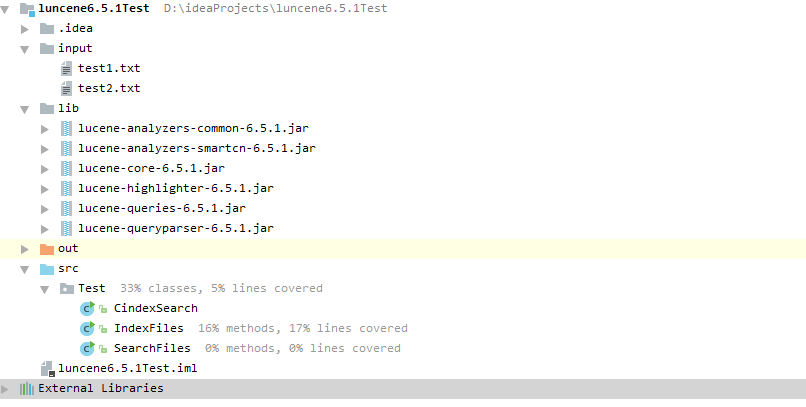
- IndexFiles,SearchFiles分别是遍历一个文件目录创建索引和手动输入关键词检索返回命中文件。CindexSrarch是实例一个内存索引创建并添加文档,最终检索的过程。
-
package Test; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.TextField; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.store.Directory; import org.apache.lucene.store.RAMDirectory; import java.io.IOException; /** * Created by rzx on 2017/6/1. */ public class CindexSearch { public static void createIndexANDSearchIndex() throws Exception{ Analyzer analyzer = new StandardAnalyzer();//标准分词器 //RAMDirectory内存字典存储索引 Directory directory = new RAMDirectory(); //Directory directory = FSDirectory.open("/tmp/testindex");磁盘存储索引 IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter writer = new IndexWriter(directory,config); Document document = new Document(); String text = "hello world main test"; document.add(new Field("filetest",text, TextField.TYPE_STORED)); //将域field添加到document中 writer.addDocument(document); writer.close(); DirectoryReader directoryReader = DirectoryReader.open(directory); IndexSearcher isearch = new IndexSearcher(directoryReader); QueryParser parser = new QueryParser("filetest",new StandardAnalyzer()); Query query = parser.parse("main");//查询main关键词 ScoreDoc [] hits = isearch.search(query,1000).scoreDocs; for (int i = 0; i <hits.length ; i++) { Document hitdoc =isearch.doc(hits[i].doc); System.out.print("命中的文件内容:"+hitdoc.get("filetest")); } directoryReader.close(); directory.close(); } public static void main(String[] args) { try { createIndexANDSearchIndex(); } catch (Exception e) { e.printStackTrace(); } } }
运行结果:
-

-
input目录中创建了两个文件test1.txt,test2.txt,内容分别是:hello world和hello main man test。运行IndexFiles读取input目录,并自动创建一个testindex索引目录,结果如下:


-
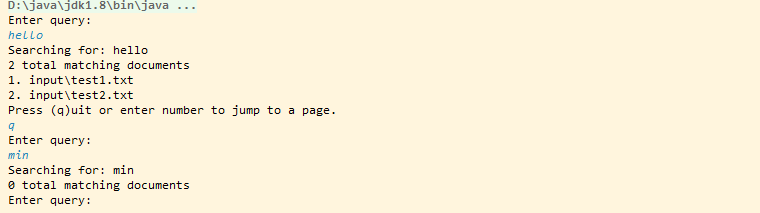
目录中创建了testindex文件,里面存储索引相关信息。运行SearchFiles如下:分别在控制台输入检索关键字:hello,min
五、核心类:
-
建立索引:Analyzer,Director(RAMDirectory,FSDirectory),IndexWriterConfig,IndexWriter,Document
-
* Analyzer analyzer = new StandardAnalyzer(); //实例化分词器 * Directory directory = new RAMDirectory(); //初始化内存索引目录 * Directory directory = FSDirectory.open("indexpath");//初始化磁盘存储索引 * IndexWriterConfig config = new IndexWriterConfig(analyzer); //索引器配置 * IndexWriter writer = new IndexWriter(directory,config); //索引器 * Document document = new Document(); //初始化Document,用来存数据。
- 查询索引:DirectoryReader,IndexSearch,QueryParser,MutilFieldQueryParser,
-
* DirectoryReader directoryReader = DirectoryReader.open(directory); //索引目录读取器 * IndexSearcher isearch = new IndexSearcher(directoryReader); //索引查询器 *多种检索方式: * QueryParser单字段<域>绑定: QueryParser qparser = new QueryParser("filed",new StandardAnalyzer()); //查询解析器:参数Field域,分词器 Query query = qparser.parse("main") //查询关键词 * MultiFieldQueryParser多字段<域>绑定(): QueryParser qparser2 = new MultiFieldQueryParser(new String[]{"field1","field2"},new StandardAnalyzer());//多字段查询解析器 Query query = qparser2.parse("main") //查询关键词 * Term绑定字段<域>查询:new Term(field,keyword); Term term =new Term("content","main"); Query query = new TermQuery(term); *更多方法:参照http://blog.csdn.net/chenghui0317/article/details/10824789 * ScoreDoc [] hits = isearch.search(query,1000).scoreDocs; //查询你命中的文档以及评分和所在分片
- 高亮显示:SimpleHTMLFormatter,Highlighter,SimpleFragmenter
-
SimpleHTMLFormatter formatter=new SimpleHTMLFormatter("<b><font color='red'>","</font></b>"); Highlighter highlighter=new Highlighter(formatter, new QueryScorer(query)); highlighter.setTextFragmenter(new SimpleFragmenter(400)); String conten = highlighter.getBestFragment(new StandardAnalyzer(),"contents","hello main man test");
- 内置分词器:Lucene中实现了很多分词器,有针对性的应用各个场景和各种语言。
-
QueryParser qparser = new QueryParser("content",new SimpleAnalyzer()); QueryParser qparser = new QueryParser("content",new ClassicAnalyzer()); QueryParser qparser = new QueryParser("content",new KeywordAnalyzer()); QueryParser qparser = new QueryParser("content",new StopAnalyzer()); QueryParser qparser = new QueryParser("content",new UAX29URLEmailAnalyzer()); QueryParser qparser = new QueryParser("content",new UnicodeWhitespaceAnalyzer()); QueryParser qparser = new QueryParser("content",new WhitespaceAnalyzer()); QueryParser qparser = new QueryParser("content",new ArabicAnalyzer()); QueryParser qparser = new QueryParser("content",new ArmenianAnalyzer()); QueryParser qparser = new QueryParser("content",new BasqueAnalyzer()); QueryParser qparser = new QueryParser("content",new BrazilianAnalyzer()); QueryParser qparser = new QueryParser("content",new BulgarianAnalyzer()); QueryParser qparser = new QueryParser("content",new CatalanAnalyzer()); QueryParser qparser = new QueryParser("content",new CJKAnalyzer()); QueryParser qparser = new QueryParser("content",new CollationKeyAnalyzer()); QueryParser qparser = new QueryParser("content",new CustomAnalyzer(Version defaultMatchVersion, CharFilterFactory[] charFilters, TokenizerFactory tokenizer, TokenFilterFactory[] tokenFilters, Integer posIncGap, Integer offsetGap)); QueryParser qparser = new QueryParser("content",new SmartChineseAnalyzer());//中文最长分词
六、高亮示例:
- 读取indexfile创建的索引testindex,并查询关键字main并高亮。出现异常:Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/lucene/index/memory/MemoryIndex需要导入:lucene-memory-6.5.1.jar,这个包用来处理存储位置的偏移量,可以让我们在文本中定位到关键词元.
-
public static void searchByIndex(String indexFilePath,String keyword) throws ParseException, InvalidTokenOffsetsException { try { String indexDataPath="testindex"; String keyWord = "main"; Directory dir= FSDirectory.open(new File(indexDataPath).toPath()); IndexReader reader= DirectoryReader.open(dir); IndexSearcher searcher=new IndexSearcher(reader); QueryParser queryParser = new QueryParser("contents",new StandardAnalyzer()); Query query = queryParser.parse("main"); TopDocs topdocs=searcher.search(query,10); ScoreDoc[] scoredocs=topdocs.scoreDocs; System.out.println("最大的评分:"+topdocs.getMaxScore()); for(int i=0;i<scoredocs.length;i++){ int doc=scoredocs[i].doc; Document document=searcher.doc(doc); System.out.println("====================================="); System.out.println("关键词:"+keyWord); System.out.println("文件路径:"+document.get("path")); System.out.println("文件ID:"+scoredocs[i].doc); //开始高亮 SimpleHTMLFormatter formatter=new SimpleHTMLFormatter("<b><font color='red'>","</font></b>"); Highlighter highlighter=new Highlighter(formatter, new QueryScorer(query)); highlighter.setTextFragmenter(new SimpleFragmenter(400)); String conten = highlighter.getBestFragment(new StandardAnalyzer(),"contents","hello main man test"); //String conten = highlighter.getBestFragment(new StandardAnalyzer(),"contents",document.get("content")); System.out.println("文件内容:"+conten); System.out.println("相关度:"+scoredocs[i].score); } reader.close(); } catch (IOException e) { e.printStackTrace(); } }
输出结果:

源代码:https://codeload.github.com/NextNight/luncene6.5.1Test/zip/master
❤如果这篇文章对你有一点点的帮助请给一份推荐! 谢谢!你们的鼓励是我继续前进的动力。更多内容欢迎访问我的个人博客
❤本博客只适用于研究学习为目的,大多为学习笔记,如有错误欢迎指正,如有误导概不负责(本人尽力保证90%的验证和10%的猜想)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号