[大数据]-hadoop2.8和spark2.1完全分布式搭建
一、前期准备工作:
1.安装包的准备:
- VMware(10.0版本以上) :
- 官方网站:https://www.vmware.com/cn.html
- 官方下载地址:http://www.vmware.com/products/player/playerpro-evaluation.html
- 10.0版本注册码:
-
v1Z0G9-67285-FZG78-ZL3Q2-234JG 4C4EK-89KDL-5ZFP9-1LA5P-2A0J0 HY086-4T01N-CZ3U0-CV0QM-13DNU
- 11.0版本注册码:
-
1F04Z-6D111-7Z029-AV0Q4-3AEH8
- 12.0版本注册码:
-
5A02H-AU243-TZJ49-GTC7K-3C61N
- ubuntu14.0系统:(64位)选择ubuntu纯属个人喜好,Liunx发行版有很多都支持Hadoop,而14.0版本是个比较稳定的版本,不算太新所以很多东西支持的比较好,重要的是支持CDH的hadoop生态系统构建。
- 官方地址:https://www.ubuntu.com/download/alternative-downloads选择14.0版本即可。
- jdk1.8安装包:
- scala2.11安装包:
- 官方下载:http://www.scala-lang.org/点击DownLoad即可下载。
- spark2.1安装包:
- 官方下载:http://spark.apache.org/downloads.html这里spark提供了和hadoop绑定的版本,但是由于没有提供2.8的hadoop绑定版,所以这里选择通用版spark-2.1.0-bin-without-hadoop 来进行下载。如下图:第一个是安装包。

2.辅助工具安装包:
- Putty:一个十分简洁的链接服务器的工具。因为虚拟机太卡了长期在上面操作的话会卡到爆。用Putty可以在主机用一个终端来操作虚拟机。
- FlashFxp:用于在宿主机上传和下载虚拟机的文件,当然VMware安装了tools之后可以随意拖拽很方便,但是还是考虑到卡爆的问题,虚拟机启动后我们完全不管他,就当作服务器来用。
3.系统基本配置:(未说明则均在主机rzxmaster上操作)
第一步:安装VMware,创建虚拟机Master,安装Vim,Mysql(mysql也可以暂且不装,但是考虑到后面组件的扩展还是先安上)。
第二步:克隆虚拟机(选择完全克隆)rzxmater,分别命名为rzxslave1,rzxslave2(这里的命名可以自行修改)。然后启动三个虚拟机。
-
-
- 分别修改hostsname主机名。(这里实例修改rzxmaster这台机器的主机名)。
- 输入: sudo vim /etc/hostname 回车进入hostname文件的编辑。
- 在hostname文件输入: rzxmaster 另外两台机器同理修改保存退出即可。
- 输入: source /etc/hostname 使配置立即生效。关闭终端重新打开即可看到主机名已经改变了。
-
第四步:静态Ip设置:
-
-
- 静态IP设置:http://blog.csdn.net/lv18092081172/article/details/52081859这篇博文介绍的很详细,但是其中有部分问题,不知道是16.0和14.0版本差异的问题还是教程本身的问题,一个是网络重启之后DNS配置丢失的问题。每次重启之后会发现配置的DNS文件恢复成了127.0.0.1这个问题是由于interface,networkManager两种网络管理冲突造成的。解决方法就是在编辑链接的时候将DNS也一起编辑。这样就不用再编辑DNS的配置文件。如下图所示:
-
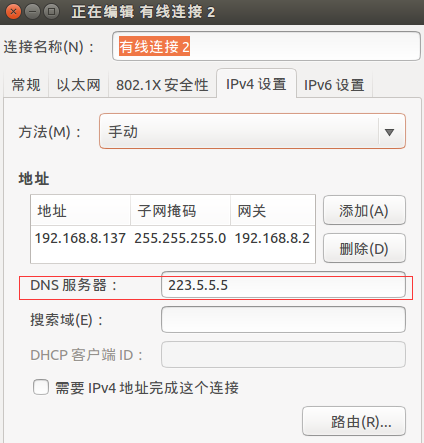
其他步骤按博文所说就可以完成静态IP的配置。
第五步:hosts配置,特别强调主机名称不要含有下划线"_",最好是纯英文。 因为hadoopXML配置的时候部分value不能有下划线,会报错。
-
- 修改hosts:添加主机名和IP的对应,目的是为了使用主机名的时候能够定位(通过IP)到不同的机器。
- 输入: sudo vim /etc/hosts
- 把三台机器的IP和主机名对应填入hosts文件,实例如下所示。填写完之后保存退出。
-
192.168.8.137 rzxmaster 192.168.8.136 rzxslave1 192.168.8.138 rzxslave2
- 输入: source /etc/hosts 使配置立即生效。
- 输入: ping rzxslave1 可以查看输出是否有对应的IP地址,这里先不考虑弄否ping通。实例如下:
- 修改hosts:添加主机名和IP的对应,目的是为了使用主机名的时候能够定位(通过IP)到不同的机器。

第六步:SSH免密码登录:
-
-
1 sudo apt-get update //更新源 2 sudo apt-get install openssh-server //安装ssh服务器 3 sudo ps -e |grep ssh //查看ssh服务是否启动 4 sudo service ssh start //开启ssh服务 5 ssh-keygen -t rsa //生成公钥密钥 一路enter就行了 6 cat /home/cxin/.ssh/id_rsa.pub >>/home/cxin/.ssh/authorized_keys //将公钥添加到用户公钥文件。
ssh的配置比较简单教程也很多。不外乎以上几条命令。在三台机子上都进行了如下操作之后,要是rzxmaster免密码登录到rzxslave1,rzxslave2。需要把master的公钥放到slave1,2的authorized_keys文件中,这里只需要拷贝然后打开rzxslave1,2的authorized_keys文件粘贴上即可。保存之后重启虚拟机。重启之后在rzxmaster,输入 ssh rzxslave1 如果不需要密码就能登陆到rzxslave1说明成功,同理实验rzxslave2。rzxmaster可以登录到所有slave节点则SSH设置完毕。
-
二、集群搭建
通过前面的准备工作我们已经获取到了所有需要的安装包,设置好了静态IP,配好了ssh免密码登录,接下就是集群的安装了。首先我所有的包都是安装在当前用户的根目录下,也就是终端打开的目录(一般是: /home/username username是当前的用户名),这个目录是当亲前用户的工作空间我把这个目录的位置记作 basePath=/home/username .这个basePath可以根据自己的喜好安装到别的目录下。(basePath=="~"==/home/cxin,我这里的basePath=/home/cxin)
三台虚拟机分别如下:rzxmaster是主节点(datanode),rzxslave1,rzxslave2是分支节点(namenode)
192.168.8.137 rzxmaster
192.168.8.136 rzxslave1
192.168.8.138 rzxslave2
为了方便管理这里在主目录建了三个文件夹:Java,spark,hadoop. mkdir Java spark hadoop
现在将jdk,hadoop,scala,spark的安装包分别传到路径basePath/Java,basePath/hadoop,basePah/spark下,(scala和spark的压缩包都放在spark文件夹下)。

1.Jdk配置:
-
cxin@rzxmaster:~$ cd ~ cxin@rzxmaster:~$ pwd /home/cxin cxin@rzxmaster:~$ cd Java/ cxin@rzxmaster:~/Java$ tar -zxvf jdk-8u11-linux-x64.tar.gz cxin@rzxmaster:~/Java$ mv jdk-8u11-linux-x64 jdk1.8
cxin@rzxmaster:~/Java$ ls jdk1.8 cxin@rzxmaster:~/Java$ cd jdk1.8/ cxin@rzxmaster:~/Java/jdk1.8$ ls bin include lib README.html THIRDPARTYLICENSEREADME-JAVAFX.txt COPYRIGHT javafx-src.zip LICENSE release THIRDPARTYLICENSEREADME.txt db jre man src.zip cxin@rzxmaster:~/Java/jdk1.8$ pwd /home/cxin/Java/jdk1.8
解压并修改了名称,pwd命令获取到了JAVA_HOME路径: /home/cxin/Java/jdk1.8 下面配置环境变量:
- sudo vim /etc/profile 在文件末尾添加如下代码:
-
#java export JAVA_HOME=/home/cxin/Java/jdk1.8 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
-
保存退出之后:输入 source /etc/profile 使配置立即生效。
- java -version 查看是否配置成功,结果如下图,则成功,否则检查配置是否存在问题。

- 至此jdk已经配置完成了。
2.Hadoop配置:
- 解压并修改名称.(过程同jdk一样)
- 配置环境变量:sudo vim /etc/profile ,添加如下代码:
-
#Hadoop export HADOOP_HOME=/home/cxin/hadoop export CLASSPATH=.:$HADOOP_HOME/lib:$CLASSPATH export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_ROOT_LOGGER=INFO,console export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
- 保存退出,输入 source /etc/profile
- 修改hadoop的四个配置文件: cd hadoop/etc/hadoop 新版本的配置文件在etc/hadoop目录下,配置分两2个部分:Hadoop守护进程(Hadoop Daemons)的环境配置和守护进程的详细配置。
- hadoop-env.sh:hadoop守护进程[Hadoop守护进程指NameNode/DataNode 和JobTracker/TaskTracker。JobTracker/TaskTracker是较低版本的资源管理调度模式,已经被yarn所取代。]的运行环境配置,这里只设置JAVA_HOME。编辑hadoop-env.sh并添加如下代码: export JAVA_HOME=/home/cxin/Java/jdk1.8
-
- core-site.xml:
-
<configuration> <!-- 指定hdfs的namenode为rzxmaster --> <property> <name>fs.defaultFS</name> <value>hdfs://rzxmaster:9000</value> </property> <!-- Size of read/write buffer used in SequenceFiles. --> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <!-- 指定hadoop临时目录,自行创建 --> <property> <name>hadoop.tmp.dir</name> <value>/home/cxin/hadoop/tmp</value> </property> </configuration> - hdfs-site.xml:配置namenode和datanode存储命名空间和log的路径
-
<configuration> <!-- 备份数:默认为3--> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- namenode--> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/cxin/hadoop/dfs/name</value> </property> <!-- datanode--> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/cxin/hadoop/dfs/data</value> </property> <!--权限控制:false:不做控制即开放给他用户访问 --> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> - mapred-site.xml:配置MapReduce。
-
<configuration> <!-- mapreduce任务执行框架为yarn--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- mapreduce任务记录访问地址--> <property> <name>mapreduce.jobhistory.address</name> <value>rzxmaster:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>rzxmaster:19888</value> </property> </configuration>其中还有很多具体应用需要的配置暂且不做配置。参数如下:
mapreduce.map.memory.mb 1536 Larger resource limit for maps. mapreduce.map.java.opts -Xmx1024M Larger heap-size for child jvms of maps. mapreduce.reduce.memory.mb 3072 Larger resource limit for reduces. mapreduce.reduce.java.opts -Xmx2560M Larger heap-size for child jvms of reduces. mapreduce.task.io.sort.mb 512 Higher memory-limit while sorting data for efficiency. mapreduce.task.io.sort.factor 100 More streams merged at once while sorting files. mapreduce.reduce.shuffle.parallelcopies 50 Higher number of parallel copies run by reduces to fetch outputs from very large number of maps.
-
- yarn-site.xml:配置resourcesmanager和nodemanager
-
<configuration> <property> <description>The hostname of the RM.</description> <name>yarn.resourcemanager.address</name> <value>rzxmaster:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>rzxmaster:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>rzxmaster:8031</value> </property> <property>
<name>yarn.resourcemanager.admin.address</name> <value>rzxmaster:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>rzxmaster:8088</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration> - slaves:配置集群的DataNode节点,这些节点是slaves,NameNode是Master。在conf/slaves文件中列出所有slave的主机名或者IP地址,一行一个。配置如下:
-
rzxslave1 rzxslave2
- 以上的操作把基本的配置工作都完成了。至此已经完成了hadoop和jdk的配置,将Java和hadoop文件夹发送到其他节点的主机上。(使用scp命令)
-
cxin@rzxmaster:~/hadoop/etc/hadoop$ cd ~ cxin@rzxmaster:~$ ls Desktop Downloads hadoop Music Public Templates Documents examples.desktop Java Pictures spark Videos //将java目录发送到rzxslave1主机的主目录下 cxin@rzxmaster:~$ scp -r Java cxin@rzxslave1:/home/cxin/ //将hadoop目录发送到rzxslave1主机的主目录下 cxin@rzxmaster:~$ scp -r hadoop cxin@rzxslave1:/home/cxin/
- 同理将java,hadoop发送到rzxslave2目录下。
- 最后一步在rzxslave1,rzxslave2环境变量中添加上rzxmaster中配置的java,hadoop的环境变量(可直接复制粘贴,因为三台机器的配置路径是相同的)
- 至此,hadoop集群就搭建完成了。
3.hadoop集群启动:(pwd=/home/cxin/hadoop)
- 格式化文件系统:/bin/hdfs namenode -format
- 启动服务: sbin/satrt-all.sh
- 查看服务: jps 结果如下:则说明服务启动成功。(具体是否启动还要按启动日志是否报错,有时候未启动成功守护进程也会存在)
- master:rzxmaster
-
16002 Jps 7764 NameNode 7992 SecondaryNameNode 8152 ResourceManager
- slave:rzxslave1,rzxslave2
-
4529 NodeManager 6968 Jps 4383 DataNode
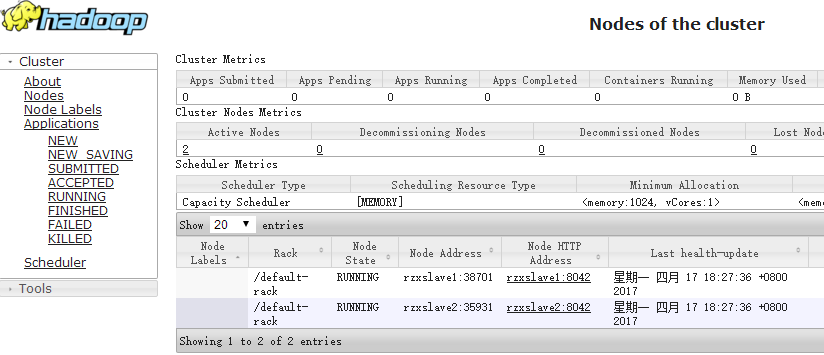
- 页面访问:192.168.8.137:8088,如果启动成功可以看到存活的节点如下:
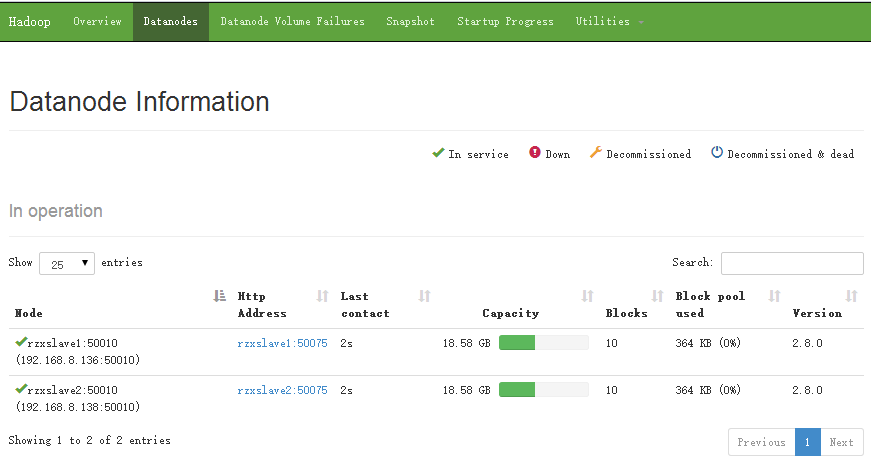
- 访问50070端口:192.168.8.137:50070
4.Spark配置:
spark是依赖与scala和java,hadoop的,前面配置好了java,hadoop,这里需要配置scala和spark的环境以及spark的详细信息。
- scala和spark的环境变量配置:(前面已经将scala和spark的安装包放到了spark文件夹下)
- 解压缩并重命名(参考jdk的配置),结果如下:

- 配置环境变量 vim /etc/profile ,添加如下代码
-
#scala export SCALA_HOME=/home/cxin/spark/scala2.11.8 export PATH=$SCALA_HOME/bin:$PATH #spark export SPARK_HOME=/home/cxin/spark/spark2.1
- 保存退出,输入 scala 如下图则证明sala配置成功

- spark的详细配置:修改spark的配置文件(spark根目录的conf目录下: pwd=/home/cxin/spark/spark2.1/conf )
- spark-env.sh:spark执行任务的环境配置,需要根据自己的机器配置来设置,内存和核心数配置的时候主要不要超出虚拟机的配置,尤其是存在默认值的配置需要仔细查看,修改。
-
export SPARK_DIST_CLASSPATH=$(/home/cxin/hadoop/bin/hadoop classpath) #rzx----config SPARK_LOCAL_DIRS=/home/cxin/spark/spark2.1/local #配置spark的local目录 SPARK_MASTER_IP=rzxmaster #master节点ip或hostname SPARK_MASTER_WEBUI_PORT=8085 #web页面端口 #export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=4" #spark-shell启动使用核数 SPARK_WORKER_CORES=1 #Worker的cpu核数 SPARK_WORKER_MEMORY=512m #worker内存大小 SPARK_WORKER_DIR=/home/cxin/spark/spark2.1/worker #worker目录 SPARK_WORKER_OPTS="-Dspark.worker.cleanup.enabled=true -Dspark.worker.cleanup.appDataTtl=604800" #worker自动清理及清理时间间隔 SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://rzxmaster:9000/spark/history" #history server页面端口>、备份数、log日志在HDFS的位置 SPARK_LOG_DIR=/home/cxin/spark/spark2.1/logs #配置Spark的log日志 JAVA_HOME=/home/cxin/Java/jdk1.8 #配置java路径 SCALA_HOME=/home/cxin/spark/scala2.11.8 #配置scala路径 HADOOP_HOME=/home/cxin/hadoop/lib/native #配置hadoop的lib路径 HADOOP_CONF_DIR=/home/cxin/hadoop/etc/hadoop/ #配置hadoop的配置路径
-
- spark-default.conf:
-
spark.master spark://rzxmaster:7077 spark.eventLog.enabled true spark.eventLog.dir hdfs://rzxmaster:9000/spark/history spark.serializer org.apache.spark.serializer.KryoSerializer spark.driver.memory 1g spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
- slaves:配置worker节点
-
rzxmaster rzxslave1 rzxslave2
- 至此spark已经配置完成了,将spark文件夹(包含scala和spark)发送到其他节点:
- scp -r spark cxin@rzxslave1:/home/cxin
- scp -r spark cxin@rzxslave2:/home/cxin
- 在slave节点配置scala,spark的环境变量,最终三台主机的环境变量配置如下:
-
#java export JAVA_HOME=/home/cxin/Java/jdk1.8 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH #Hadoop export HADOOP_HOME=/home/cxin/hadoop export CLASSPATH=.:$HADOOP_HOME/lib:$CLASSPATH export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_ROOT_LOGGER=INFO,console export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" #scala export SCALA_HOME=/home/cxin/spark/scala2.11.8 export PATH=$SCALA_HOME/bin:$PATH #spark export SPARK_HOME=/home/cxin/spark/spark2.1 export PATH=$SPARK_HOME/bin:$PATH
- 启动spark服务: sbin/start-all.sh


- 查看服务(rzxmaster): jps 由于在配置文件slaves中添加了rzxmaster,所以在此处有一个Worker进程。

-
查看服务(rzxslave1,rzxslave2): jps

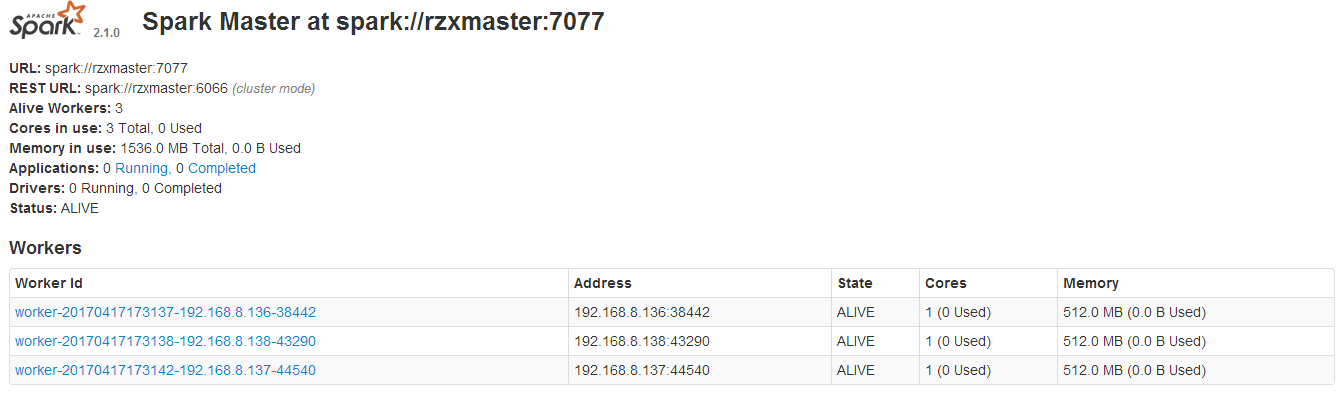
- 页面查看:访问192.168.8.137:8085(8085端口是设置在spark-env.sh中的SPARK_MASTER_WEBUI_PORT,可自行设置),结果如下:则说明成功了.
-
spark示例运行: ./bin/run-example SparkPi 2>&1 | grep "Pi is roughly" 计算圆周率。如下图所示

- 在8085端口可以看到运行的任务:

-
至此说明spark配置成功,当然其他的内容需要在使用的时候去排除bug,如果出现问题需要查看日志信息找到问题出现的原因,然后修改配置。
5.配置总结:
在配置的过程中出现了很多的问题,包括:namenode,datanode启动失败,伪成功(存在守护线程但是实际服务为启动),spak-shell启动失败爆出资源无法分配。由于在配置的时候没有做好问题的记录,所以这里列不出具体的异常信息。这里一部分异常是由于IP的设置和hosts中的配置不对应,一部分是ssh连接失败,资源配置没有根据虚拟机的配置做匹配。建议不要多次格式化namenode,每次格式化都会生成一个clusterID,多个clusterID导致启动报错,如需格式化就必须清除dfs/name,dfs/data下的文件。
hadoop,spark只是基础组建,提供文件系统和数据运算,hadoop生态还包括hive,habse,kafka...等数据存储和分析的组件,后面可以在此基础上一步步安装。
❤如果这篇文章对你有一点点的帮助请给一份推荐! 谢谢!你们的鼓励是我继续前进的动力。更多内容欢迎访问我的个人博客
❤本博客只适用于研究学习为目的,大多为学习笔记,如有错误欢迎指正,如有误导概不负责(本人尽力保证90%的验证和10%的猜想)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号