大数据乱入
以前谈及大数据,总会第一想到的是Hadoop,分布式,然后没了。而真正接触大数据的时候,发现这是一个很大的体系,大数据只是个概念,而真正的核心在于数据的操作上,从数据的收集,处理,存储,计算上来发现数据中潜藏的价值。
大数据,机器学习,深度学习,人工智能,这几个比较火热的话题,其实中间存在着千丝万缕的联系。机器学习,深度学习,都是服务于机器智能化,为人工智能提供了可能,同时也为发现数据的潜在价值提供了思路。
- 个人理解的粗略的大数据处理流程:
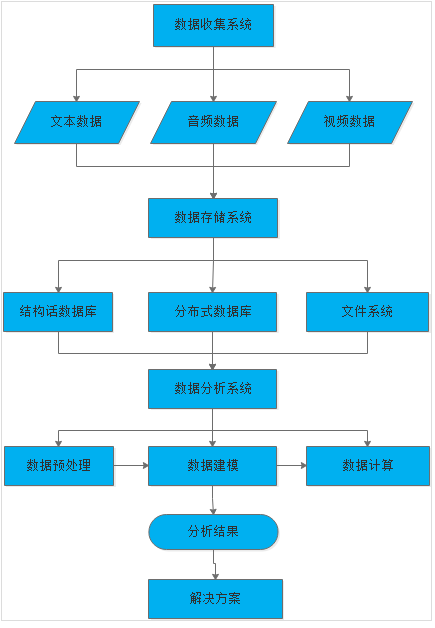
在我看来大数据的整个处理过程所为的目标不过是提供解决方案,当然,又到了先有鸡还是先有蛋的问题,有问题才有解决方案。大数据的终极目标是挖掘数据的潜在价值,所以说目前的大数据处理大部分还是在解决问题的层面上,真正没有根源的去从数据的各个维度去挖掘他的关系,发掘具有独特价值的部分,并没有成为当下大数据发展的主流。
- 数据收集系统:
- 平台化积累数据:
- 海量数据积累需要一个循序渐进的过程,没有一个好的平台是不可能完成,像国内的型电商平台(淘宝,京东。。)拥有海量的用户消费数据。腾讯平台拥有海量的用户娱乐数据。百度则拥有用户的搜索数据。链家网则拥有用户的购房数据。。。
- 大规模数据抓取:
- 没有平台化的数据积累,只有选择网络爬虫构建数据抓取系统,从互联网上抓取所需要的数据
- 平台化积累数据:
- 数据存储系统:
- 结构化数据库:oracle,mysql,sqlserver,等传统的结构化数据库
- 分布式数据库:
Redis: in memory key-value store,同时提供了更加丰富的数据结构和运算的能力,成功用法是替代memcached,通过checkpoint和commit log提供了快速的宕机恢复,同时支持replication提供读可扩展和高可用。
Mongodb: Document Store,分布式nosql,具备了区别mysql的最大亮点:可扩展性。mongodb 最新引人的莫过于提供了sql接口,是目前nosql里最像mysql的,只是没有ACID的特性,发展很快,支持了索引等特性,上手容易,对于数据量远超内存限制的场景来说,还需要慎重。
HBase: Column Table Store,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
- 文件系统:可以将数据存储在磁盘文件上
- 数据分析系统:数据的分析也是大数据的核心,
- 数据预处理
- 数据建模
- 数据计算
- 数据分析
针对不同的问题,建立所需的模型,模型的好坏直接决定着解决方案的效果。建模的过程说白了就是设计算法的过程,当然不同于以往的算法设计,更多的是运用到机器学习的算法结合实际问题所设计的算法方案。
❤如果这篇文章对你有一点点的帮助请给一份推荐! 谢谢!你们的鼓励是我继续前进的动力。更多内容欢迎访问我的个人博客
❤本博客只适用于研究学习为目的,大多为学习笔记,如有错误欢迎指正,如有误导概不负责(本人尽力保证90%的验证和10%的猜想)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号