

1.KNN思想:
俗称k-近邻算法,原理就是采用测量不同特征值之间的距离方法进行分类。工作原理:存在一个样本数据集合,也叫做训练样本集。样本中每个数据都有对应的标签,即我们清楚每一个数据所属分类。现在有一个新的未分类数据,我们要将新数据的特征值与样本集中每个数据对应的特征值进行比较,最后提取出样本集中特征最相似的标签作为新数据的标签。
2.分类器
数据和数据之间的距离有很多计算方式,最常用的是欧式距离,比如二维坐标计算两点的距离就是欧式距离(网页编辑不出公式。。。可以自行百度),通过以下代码可以实现一个分类器。
def classify0(inX,dataSet,labels,x): #建立一个分类器,x代表前几个值 dataSize = dataSet.shape[0] diffMat= np.tile(inX,(dataSize,1))-dataSet #建造一个矩阵,存储的是每个向量与初始向量的差向量 # print(diffMat) sqDiffMat=diffMat**2 #求得差的平方矩阵 # print(sqDiffMat) sqDistance=sqDiffMat.sum(axis=1) #求和 # print(sqDistance) distance = sqDistance**0.5 # print(distance) sortedDistance = distance.argsort()#获取数组从小到大的索引 # print(sortedDistance) classCount ={} for i in range(x): voteLabel = labels[sortedDistance[i]] classCount[voteLabel] = classCount.get(voteLabel,0)+1 sortedClassCoount = sorted(classCount.items(),key= lambda x:x[1],reverse = True) print(sortedClassCoount) return sortedClassCoount[0][0]
3.小例子
group=np.array([[1,1.1],[1,1],[2,2.1],[2,2]]) labels =['A','A','B','B'] print(classify0([0,0],ar,labels,3))
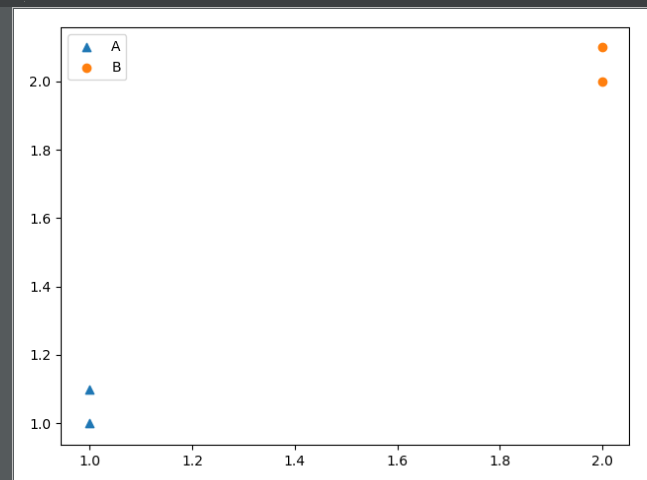
代码会输出(0,0)所属的分类'A',从图中看,(0,0)坐标的确离A分类更近

