谷歌大数据论文
链接:https://pan.baidu.com/s/1DoTQdLkaLzD45PtxFwL-uA
提取码:9fce
/本地文件系统
功能
将文件名字翻译到一个具体的磁盘位置,完成文件读写。
文件系统名字解析:
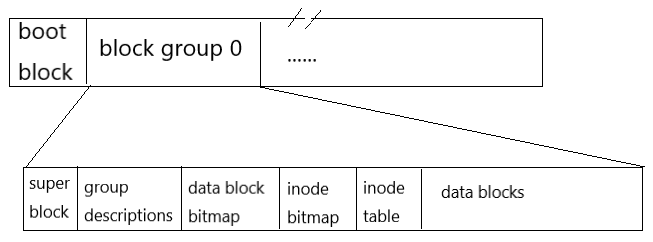
inode(owner name,ctime,(address.size))
文件系统设计
- 功能(文件系统的目录树)
- 解析(递归)
- 接口
- 缓存(时间局部性和空间局部性(待查文件附近的文件))
磁盘块大小:512B
块小,元数据增加;块大,空间浪费。
/分布式文件系统
发展阶段:
NFS-AFS(定位到1台服务器,1个文件放在1台服务器上)-GFS
GFS:
应用驱动->需要建立高效搜索引擎->
1.存储大量互联网数据
2.文件快速写入
3文件读取(倒排索引 )(延迟:建立索引消耗)
4.排序
分布式文件系统设计目标:
1.完成文件系统基本功能(目录树、文件读写(并发读写))
2.集群 负载均衡、可扩展
4.容错
5.设计简洁
1.google file system (2003)
1.数据块 64MB【减少元数据开销】
2.性能设计
3.可靠性 多副本
4.系统设计
master 保存元数据
| 块服务器 | 主服务器 | |
| 性能 | 1.负载均衡[1.访问 2存储]【master控制】 | 元数据管理【64MB-64B】 |
| 可靠性 | 1.块出现错误【master监控】2.块的恢复【各块并行恢复】 | 日志;shadow server;磁盘数据副本 |
| 一致性 | 租期;主副本的顺序定义 | |
| 放松的一致性 | 1.consisteng 3副本一致(写入数据不一定是客户端想要的数据(由于块的设计、多客户访问)) 2.defined 客户端数据明确性 | |
| 读写 | 单写;数据原子添加; | |
| 垃圾回收 | 惰性删除(安全保障);不能被master识别的被回收 |
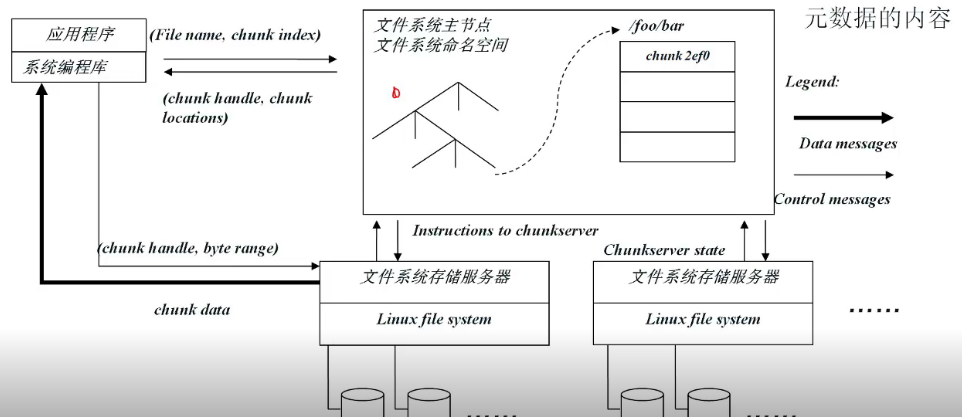
2.MapReduce(2004)
数据并行化dlp需要解决的问题?
- 共享?(吞吐量【多个进程同时改变数据】;同步问题)
- 小粒度通讯复杂化元数据管理
- 某个机器失败怎么办,是否要重算
数据并行的分治策略
map:splits;处理输入的键值对->生成中间结果集。
reduce:对于某一个键,合并它所有的值->生成合并后的结果值集合。
splits:分块,在每个块上分布式调用map。16MB或者64MB,取决于GFS数据块大小。
M和R数量选择
M>>servers[有助于负载均衡]; R>servers【R不应该太多,每个reduce()调用会对应一个单独的文件】
shuffle 通过key分组
map1 partition成R组 ->
i数据传输到R i 【RPC】->
R对相同key排序【归并排序】->
调用reduce函数
mapreduce数据流
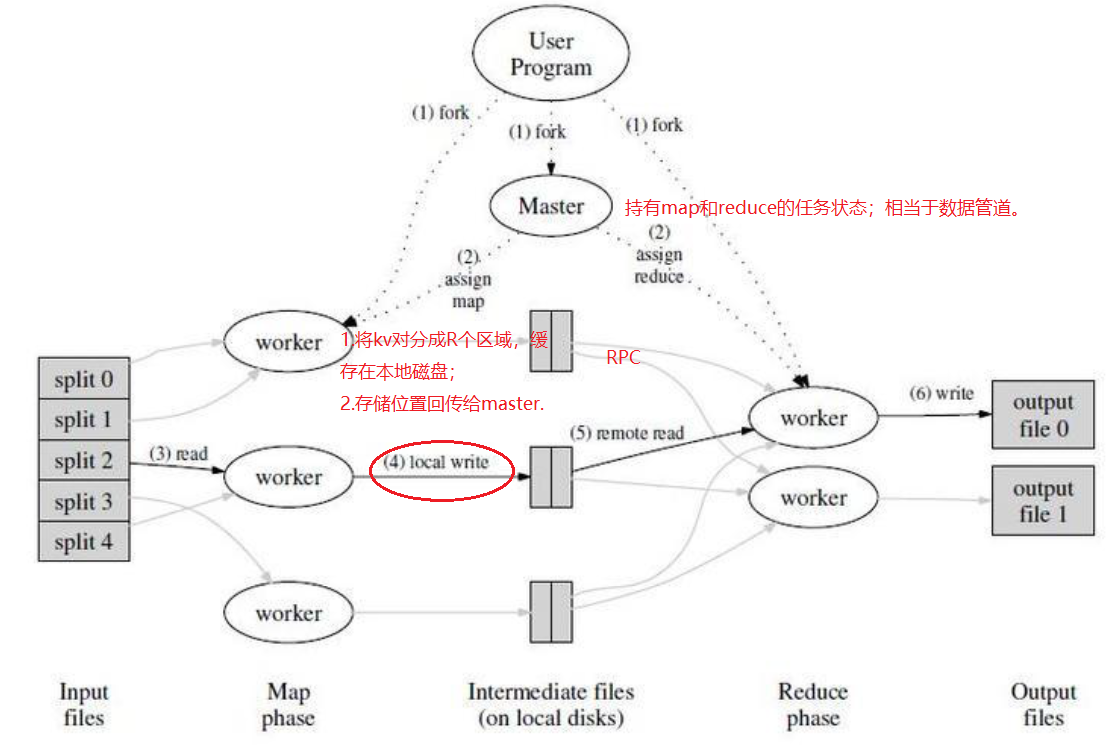
Mapreduce其他细节
| 冗余执行backup | 在任务接近结束,生成备用任务(任务的幂等性idempotent),缩短任务执行时间,速度提高30% | |
| 容错 |
对于worker:1.master周期ping worker; |
对于master:checkpoint |
| 适用条件 |
重复操作;操作幂等; |
缺点:严格数据流;常见操作也要手写很多代码 |
为什么mapreduce的结果要放在磁盘上?
mr用来处理大数据集,内存可能放不下。
.......
3.Bigtable(2006)
其他论文:
4.percolator(2010)
5. Dremel(2010)
6.Pregel(2010)
7.Spanner(2012)
------------恢复内容结束------------
------------恢复内容结束------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号