Spark核心原理
1. 概要介绍
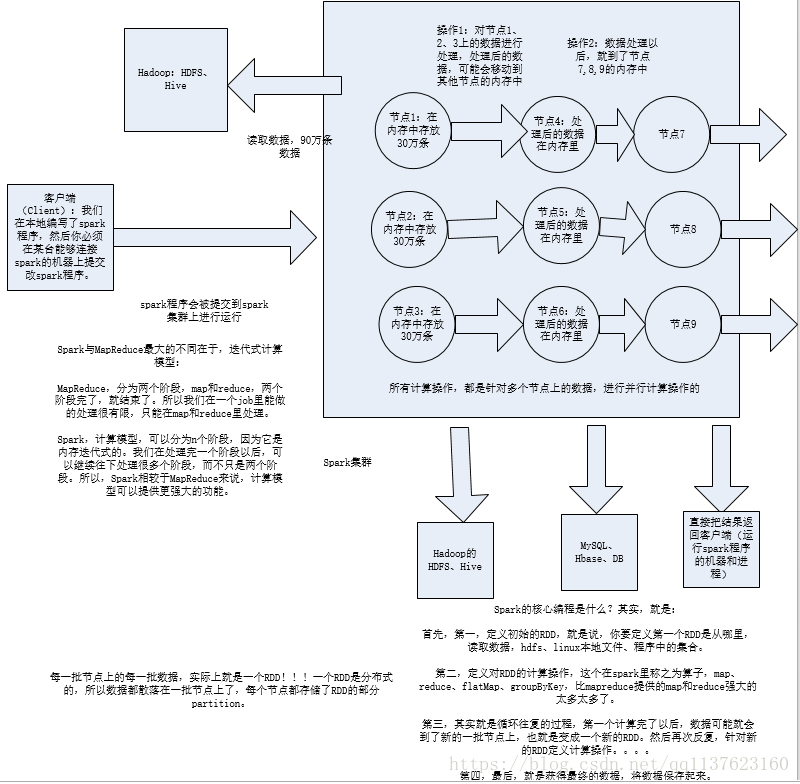
1.1 master节点和work节点
master和worker是物理节点
- spark集群有一个master节点和多个worker节点。Standalone模式下可以通过zookeeper对master做靠可用配置,当master宕机了之后重新选举一个master。
- master节点常驻master守护进程,负责管理worker节点,我们从master节点提交应用。
- worker节点常驻worker守护进程,与master节点通信,并且管理executor进程。
- 一台机器可以同时作为master和worker节点(举个例子:你有四台机器,你可以选择一台设置为master节点,然后剩下三台设为worker节点,也可以把四台都设为worker节点,这种情况下,有一个机器既是master节点又是worker节点)
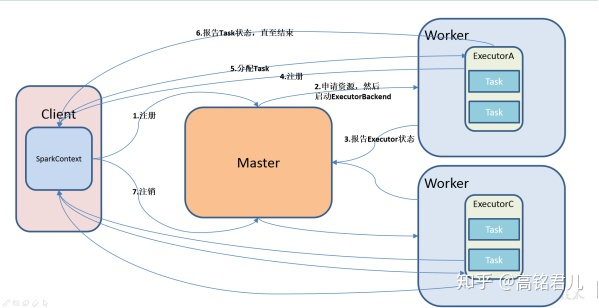
1.2 driver与executor
driver与executor是进程
driver进程就是应用的main()函数并且构建SparkContext对象,当我们提交了应用之后,便会启动一个对应的driver进程,driver本身会根据设置的参数占有一定的资源(主要指cpu core和memory)。
driver可以运行在master上,也可以运行worker上(根据部署模式的不同)。driver首先会向集群管理者(standalone、yarn,mesos)申请spark应用所需的资源,也就是executor,然后集群管理者会根据spark应用所设置的参数在各个worker上分配一定数量的executor,每个executor都占用一定数量的cpu和memory。在申请到应用所需的资源以后,driver就开始调度和执行我们编写的应用代码了。driver进程会将我们编写的spark应用代码拆分成多个stage,每个stage执行一部分代码片段,并为每个stage创建一批tasks,然后将这些tasks分配到各个executor中执行。
executor进程宿主在worker节点上,一个worker可以有多个executor。每个executor持有一个线程池,每个线程可以执行一个task,executor执行完task以后将结果返回给driver,每个executor执行的task都属于同一个应用。此外executor还有一个功能就是为应用程序中要求缓存的 RDD 提供内存式存储,RDD 是直接缓存在executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算
1.3 application与client
- 提交一次计算时,一般要提交一个jar包,包里会有一个main函数,这次计算任务叫application
- 提交任务所在的那个机器就是client,client可以不属于集群内的节点
spark-submit --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \ --queue thequeue \ examples/target/scala-2.11/jars/spark-examples*.jar 10
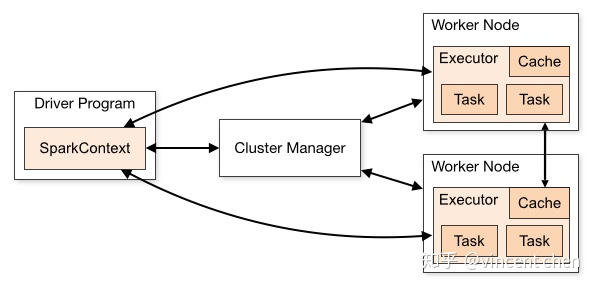
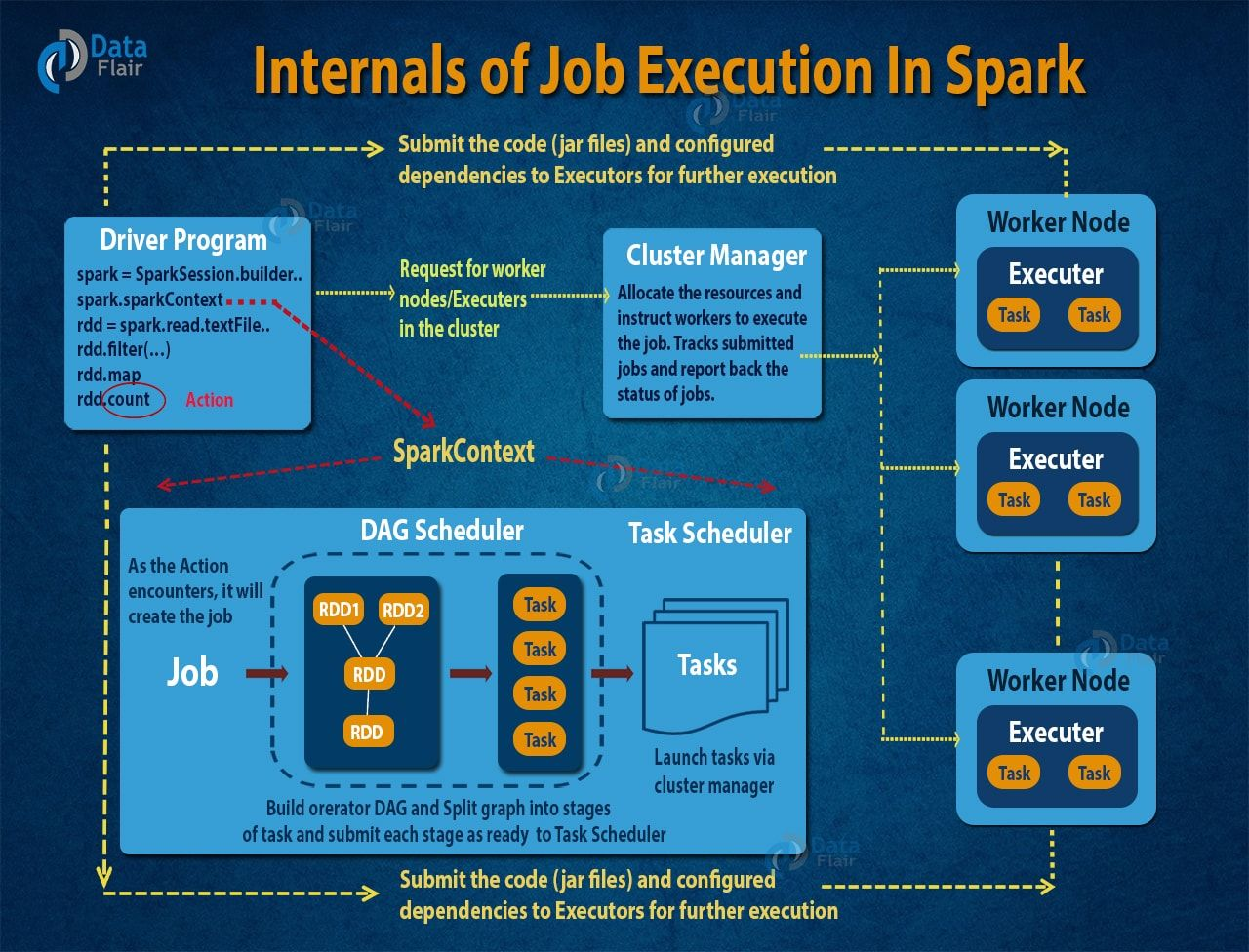
1.4 运行架构
Spark运行架构基本由三部分组成,包括SparkContext(驱动程序)、ClusterManager(集群资源管理器)和Executor(任务执行进程)。
其中,SparkContext用于负责与ClusterManager通信,进行资源的申请、任务的分配和监控等,负责作业执行的全生命周期管理。ClusterManager提供了资源分配和管理,在不同的运行模式下,担任的角色有所不同,在Local与Standalone模式下由Master提供,在YARN运行模式下由Resource Manager担任,在Mesos运行模式下由Mesos Manager负责。当SparkContext对运行的作业划分并分配资源之后,会把任务发送Executor进行运行。
每个应用程序获取专属的Executor进程,这些进程在应用程序运行的过程中一直驻留,并以多线程方式运行任务。这种机制使得Driver的调度与Executor运行在不同的JVM中,进行了隔离。也意味着Spark不能跨Executor共享数据,除非将数据写入到外部存储系统。
- Local运行模式:Spark运行在同一个进程中,该运行模式一般用于测试等用途。Spark默认就是Local运行模式。
- Local-Cluster运行模式:Spark运行在同一台机器的多个进程中模拟集群,伪分布式运行流程同Standalone运行模式。
- Standalone运行模式:正式的集群管理,资源调度由Master来完成,轻量。
- YARN运行模式:YARN是大数据家族中专门用于资管管理的组件,YARN是集群模式比较重,Spark兼容了YARN的资源管理
- Mesos运行模式:Apache旗下开源的类似YARN的资源管理组件,Mesos本身也是Master/Slave的集群模式
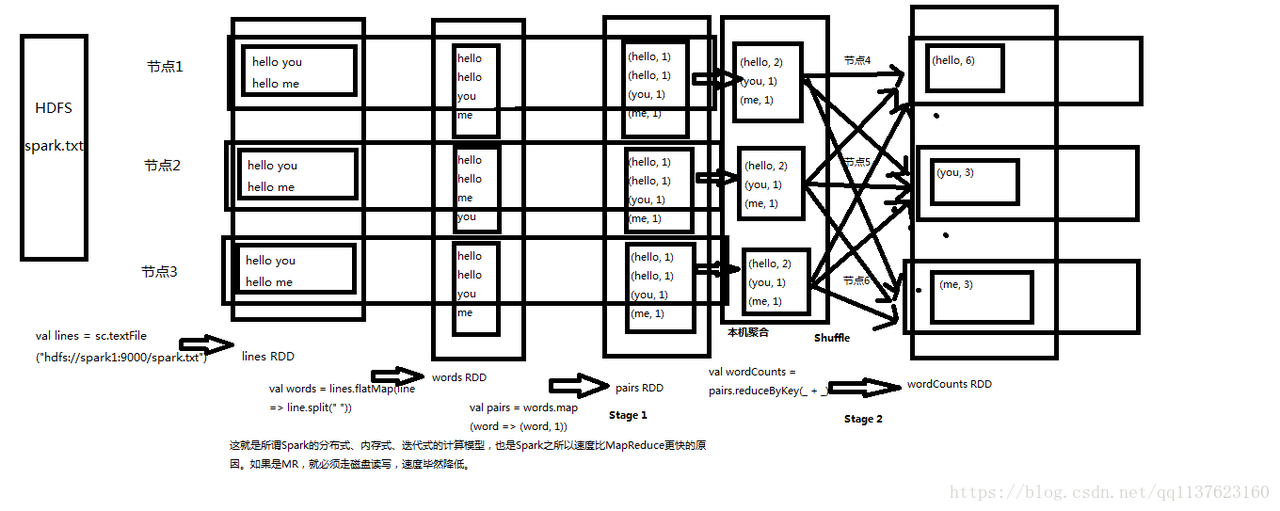
2 DEMO: WordCount
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object sparkTest { def main(args: Array[String]): Unit = { //1.创建sparkConf val sparkConf = new SparkConf().setMaster("spark://192.168.17.151:7077") .setAppName("WordCount") //2.创建sparkContext,代表一个application,会在一个driver上运行(不一定是master) val sc = new SparkContext(sparkConf) //3.读取数据 var rdd0:RDD[String] = sc.textFile("hdfs://192.168.17.151:9000/word.txt") //4.执行分布式计算 var result:Array[(String,Int)] = rdd0.flatMap(_.split(" ")) .map((_,1)) .reduceByKey(_+_) .sortBy(_._2, false) .collect() //8.打印结果 result.foreach(println(_)) } }
下面把第4步计算过程拆开(4-8步骤)
//1.创建sparkConf val sparkConf = new SparkConf().setMaster("spark://192.168.17.151:7077") .setAppName("WordCount") //2.创建sparkContext,代表一个application,会在一个driver上运行(不一定是master) val sc = new SparkContext(sparkConf) //3.读取数据 var rdd0:RDD[String] = sc.textFile("hdfs://192.168.17.151:9000/word.txt") //4.拆分数据 var rdd1:RDD[String] = rdd0.flatMap(_.split(" ")) //5.map var rdd2:RDD[(String,Int)] = rdd1.map((_,1)) //6.根据单词进行reduce,会执行shuffle操作 var rdd3:RDD[(String,Int)] = rdd2.reduceByKey(_+_) //7.根据单词量排序 var rdd4:RDD[(String,Int)] = rdd3.sortBy(_._2, false) //8.rdd的记录转成list发给driver,是一个action算子 var result:Array[(String,Int)] = rdd4.collect() // 还可以 rdd4.saveAsTextFile("/output") //9.打印结果 result.foreach(println(_))
3. 编程模型
|
编号
|
概念
|
解释
|
|
01
|
RDD
|
|
|
02
|
Operation
RDD操作
|
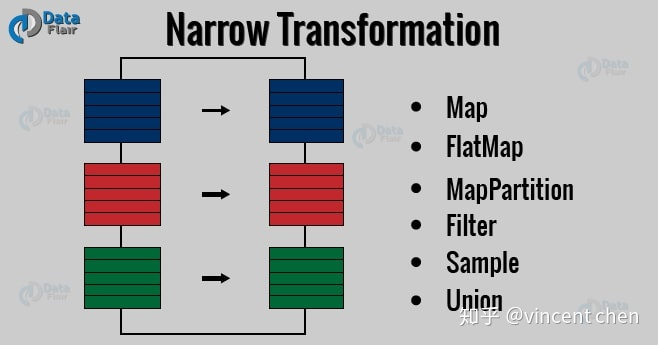
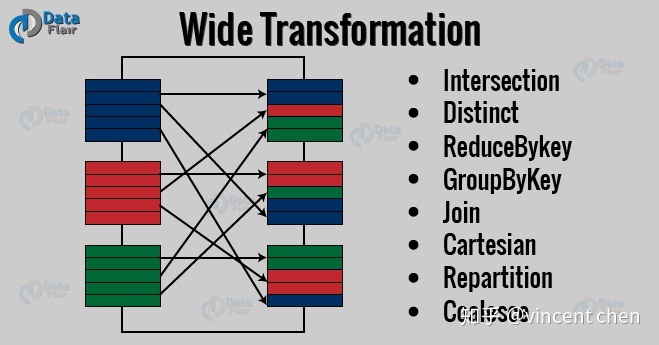
RDD有四类操作(Operation):
|
|
03
|
分区
(partition)
|
|
|
04
|
算子
|
RDD四种操作中的Transformation与Action,spark中提供80多种算子
|
|
05
|
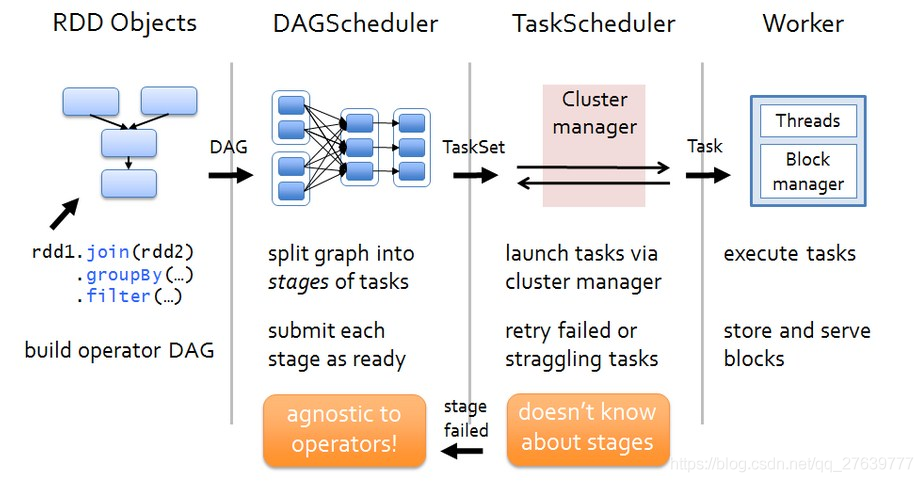
DAGScheduler
|
|
|
06
|
Job
|
|
|
07
|
Stage
|
|
|
08
|
Task
|
|
4 Spark SQL
SparkSQL产生的背景
RDD的API对于初学者来说复杂;数据分析人员所熟悉传统的R和Pandas工具API更直观,但是只能处理单机任务。基于上述两点,Spark提供了DataFrame与DataSet支持分布式大数据处理
Spark SQL相对于RDD的优点
- 学习成本低
基于SQL学习成本低
- 执行效率高
RDD基于不可变对象,每个变形都会产生新的RDD,使得Spark在运行过程中会产生大量的临时对象,对GC造成压力大。基于DataFrame打破了不变性,所以产生临时对象更少。
特别是基于Python RDD API操作时,因为Spark是使用scala语言开发的,要进行python VM与JVM需要进行大量的跨进程交换,而使用DataFrame API实际上仅仅组装了一段体积小巧的逻辑查询计划,Python只需要将查询计划发送到JVM端即可。
- 减少数据读取
DataFrame使用Row和Column来表示数据,那么就可以做更多的存取优化,比如使用列式的存储,索引效率更高。
4.1 DataFrame
DataFrame的每行数据记录类型是Row
val spark = SparkSession.builder().appName("Spark SQL basic example")
.enableHiveSupport()
.getOrCreate()
import spark.implicits._ val
val df = spark.read.format("jdbc")
.option("url", "jdbc:mysql://localhost:3306/test" )
.option("user", "root")
.option("password", "admin")
.option("dbtable", "pivot")
.load()
df.select("user","type").show()
df.filter("user=1 or type ='助手1'").show()
df.orderBy(df("visittime").desc).show(false)
df.groupBy("user")
4.2 DataSet
DataSet每行数据记录类型是自定义实体类
//样例类 case class Person(name: String, age: Int, height: Int) case class People(age: Int, names: String) case class Score(name: String, grade: Int) //1、DataSet存储类型 val seq1 = Seq( Person("xzw", 24, 183), Person("yxy", 24, 178), Person("lzq", 25, 168)) val ds1 = spark.createDataset(seq1) ds1.show() ds1.checkpoint() ds1.cache() ds1.persist() ds1.count() ds1.unpersist(true) //2、DataSet结构属性 ds1.columns ds1.dtypes ds1.explain() //3、DataSet rdd数据互换 val rdd1 = ds1.rdd val ds2 = rdd1.toDS() ds2.show() val df2 = rdd1.toDF() df2.show() //4、保存文件 df2.select("name", "age", "height").write.format("csv").save("./save")
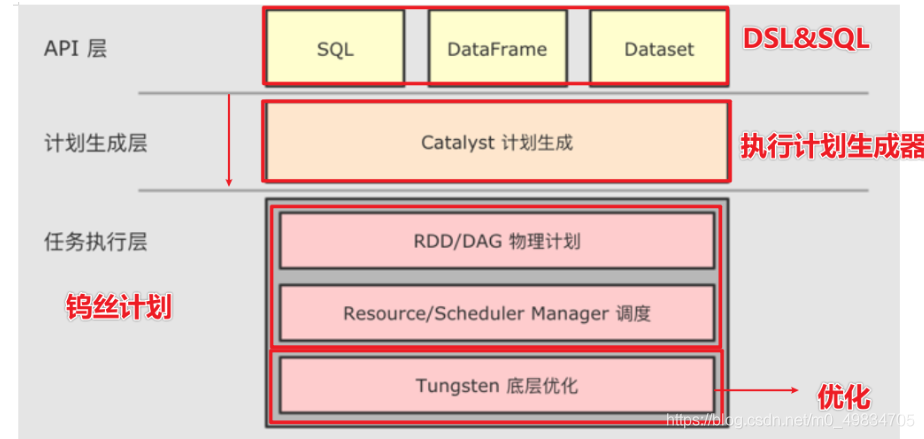
4.3 Spark SQL运行架构
4.3.1与RDD的区别
Spark SQL不使用DAGScheduler,而是使用Catalyst优化器生成执行计划
RDD运行流程
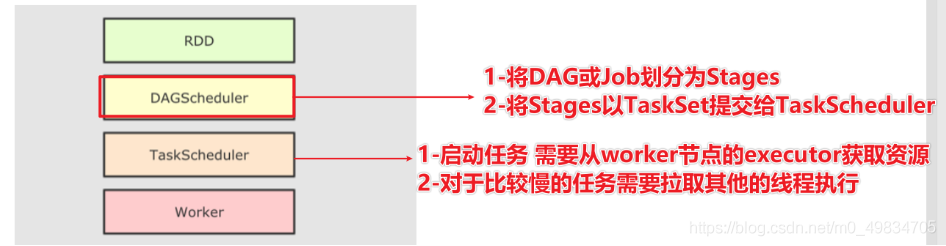
Spark SQL运行流程
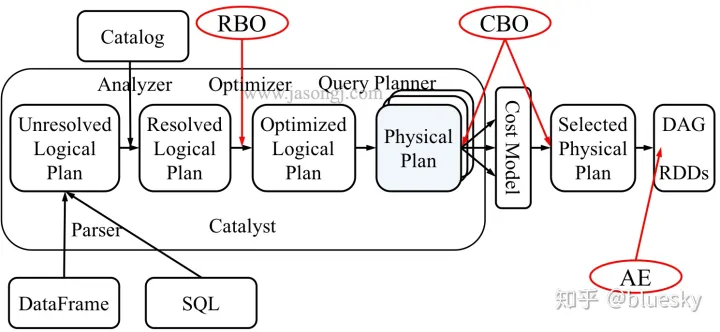
4.3.2 Catalyst优化器
- 基于规则优化/Rule Based Optimizer/RBO;
- 基于代价优化/Cost Based Optimizer/CBO;
参考资料
- Spark基本工作原理与RDD及wordcount程序实例和原理深度剖析_闵浮龙的博客-CSDN博客_wordcount原理简述
- https://zhuanlan.zhihu.com/p/50739283
- https://blog.csdn.net/qq_27639777/article/details/89305674
- Anrlr4 生成C++版本的语法解析器 - 范振勇 - 博客园 (cnblogs.com)
- SparkSQL底层执行的原理详解(面试必备)_LBJ_小松鼠的博客-CSDN博客
作者 :秋时
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号