
《数据标注工程》第二章学习笔记及作业:数据采集与清洗(转)

《数据标注工程》第二章学习笔记及作业:数据采集与清洗
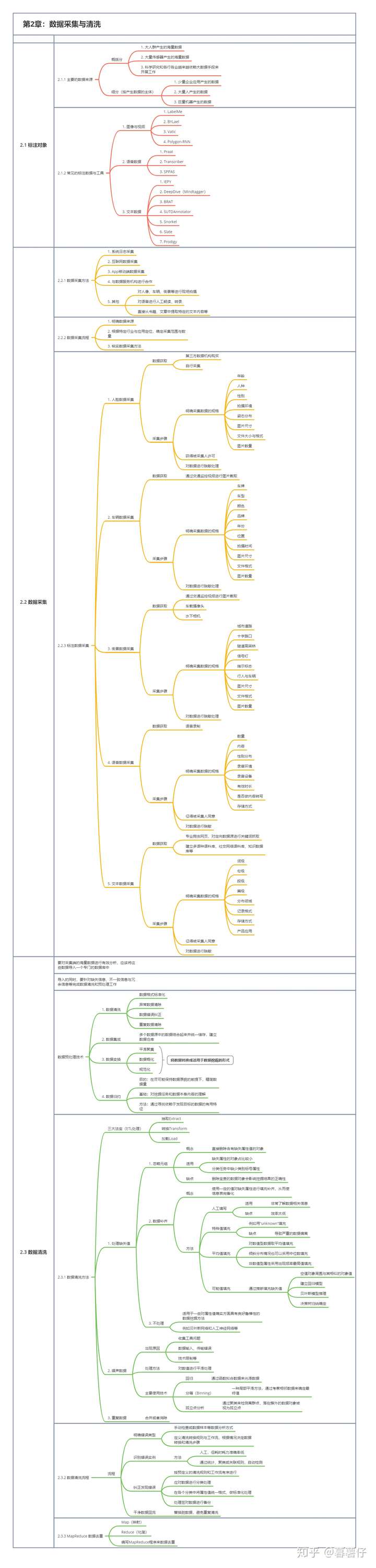
第二章:数据采集与清洗
数据采集与清洗是输出高质量数据标注成品的前提
一、标注对象
1、主要的数据来源
概括分为三大来源:
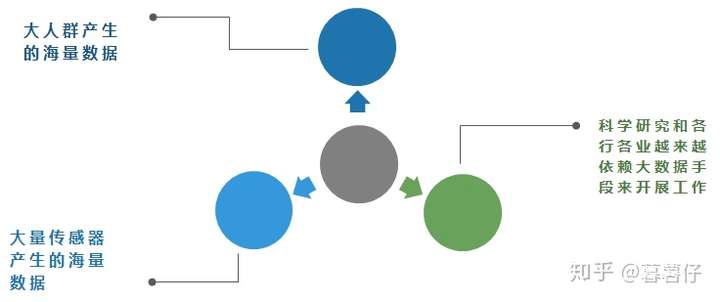 庞大数据的三大来源
庞大数据的三大来源
细分(按产生数据的主体分):
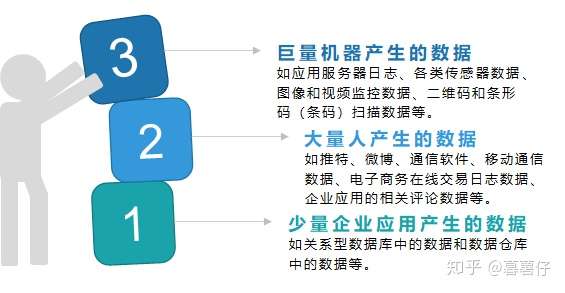 按产生数据的主题,具体可细分为图中3点
按产生数据的主题,具体可细分为图中3点
2、常见的标注数据与工具
- 图像与视频:LabelMe、BYLael、Vatic、Polygon-RNN
- 语音数据:Praat、Transcriber、SPPAS、
- 文本数据:IEPY、DeepDive(Mindtagger)、BRAT、SUTDAnnotator、Snorkel、Slate、Prodigy
二、数据采集
1、数据采集方法
- 系统日志采集(工具:Chukwa、Flume、Scribe等)
- 互联网数据采集(通过网络爬虫或公开API来获取,还可以使用DPI或DFI等贷款管理技术实现流量的采集)
- App移动端数据采集
- 与数据服务机构进行合作
- 其他:
- 对人像、车辆、街景等进行现场拍摄
- 对语音进行人工朗读、转录
- 直接从书籍、文章中提取特定的文本内容等
2、数据采集流程
 采集流程
采集流程
3、标注数据采集
①、人脸数据采集:
- 数据获取:第三方数据机构购买,或自行采集
- 采集步骤:明确采集数据的规格(年龄、人种、性别、拍摄环境、姿态分布、图片尺寸、文件大小与格式、图片数量等),获得被采集人许可,然后对数据进行脱敏处理。
②、车辆数据采集:
- 数据获取:通过交通监控视频进行图片截取
- 采集步骤:明确采集数据的规格(车牌、车型、颜色、品牌、年份、位置、拍摄时间、图片尺寸、文件格式、图片数量等),然后对数据进行脱敏处理。
③、街景数据采集:
- 数据获取:通过交通监控视频进行图片截取、车载摄像头、水下相机
- 采集步骤:明确采集数据的规格(城市道路、十字路口、隧道高架桥、信号灯、指示标志、行人与车辆、图片尺寸、文件格式、图片数量等)。
④、语音数据采集:
- 数据获取:语音录制
- 采集步骤:明确采集数据的规格(数量、内容、性别分布、录音环境、录音设备、有效时长、是否做内容转写、存储方式等),征得被采集人同意,最后对数据进行脱敏。
⑤、文本数据采集:
- 数据获取:专业爬虫网页,对定向数据源进行关键词抓取,建立多语种语料库、社交网络语料库、知识数据库等
- 采集步骤:明确采集数据的规格(词级、句级、段级、篇级、分布领域、记录格式、存储方式、产品应用等),征得被采集人同意,最后对数据进行脱敏。
三、数据清洗
数据清洗即ETL处理(抽取Extract、转换Transform、加载Load),将采集端的原始数据导入一个专门的数据库中,以便进行有效分析。这些原始数据大体上是不完整、不一致的脏数据,无法直接进行数据挖掘,因此需要进行数据预处理。在导入的同时,应针对缺失信息、不一致信息与冗余信息等完成数据清洗和预处理工作。
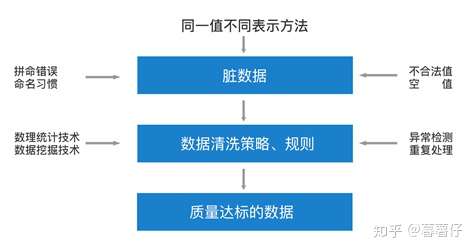 数据清洗的原理
数据清洗的原理
数据预处理有多种方法,包括:
①、数据清洗:
- 数据格式标准化
- 异常数据清除
- 数据错误纠正
- 重复数据清除
②、数据集成:
- 多个数据源中的数据结合起来并统一储存,建立数据仓库
③、数据变换:
- 平滑聚集
- 数据概化
- 规范化
④、数据归约:
- 目的:在尽可能保持数据原貌的前提下,精简数据量
- 基础:对挖掘任务和数据本身内容的理解
- 方法:通过寻找依赖于发现目标的数据的有用特征
1、数据清洗方法
1.1、缺失值:
①、忽略元组:直接删除含有缺失属性值的对象。适用于缺失属性的对象占比较小、分类任务中缺少类别标号属性的任务。但缺点是,删除宝贵的数据对象会影响挖掘结果的正确性
②、数据补齐:使用一定的值对缺失属性进行填充补齐,从而使信息表完备化。主要有以下四种方法进行数据补齐:
- 人工填写:适用于工作人员非常了解数据相关信息的情况,缺点是效率太低。
- 特殊值填充:例如用“unknown”填充,缺点是会导致严重的数据偏离。
- 平均值填充:对数值型数据取平均值填充,倾斜分布情况也可以采用中位数填充。非数值型属性采用出现频率最高值填充。
- 可能值填充:通过推断填充缺失值,空值对象周围与其相似的对象值,建立回归模型、贝叶斯模型推理、决策树归纳确定。
③、不处理:适用于一些对属性值确实方面具有良好鲁棒性的数据挖掘方法,例如贝叶斯网络和人工神经网络等。
1.2、噪声数据:
噪声数据的出现一般由于收集工具的问题,或数据输入、传输错误,或技术限制等原因,处理方法是对数值进行平滑处理,主要使用以下技术:
- 回归:通过函数拟合数据来光滑数据
- 分箱(Binning):一种局部平滑方法,通过考察相邻数据来确定最终值
- 孤立点分析:通过聚类来检测离群点,落在簇外的数据对象被视为孤立点
1.3、重复数据:
一般直接合并或者消除
2、数据清洗流程

①、明确错误类型
- 手动检查或数据样本等数据分析方式
- 定义清洗转换规则与工作流,根据情况决定数据转换和清洗步骤
②、识别错误实例
- 人工,但耗时耗力准确率低
- 通过统计、聚类或关联规则,自动检测
③、纠正发现错误
- 按预定义的清洗规则和工作流有序进行
- 应对数据进行分类处理
- 在各个分类中将属性值统一格式、做标准化处理
- 处理签对数据进行备份
④、干净数据回流
- 替换脏数据,避免重复清洗
3、MapReduce 数据去重
数据去重的过程主要是编写MapReduce程序,可以通过Map(映射)、Reduce(化简)的过程予以实现。
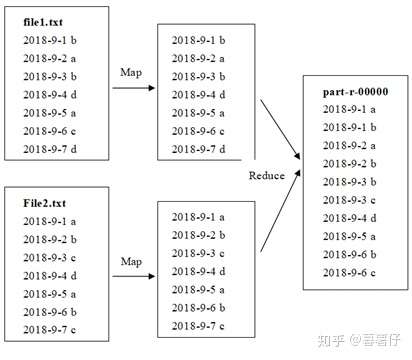 基于MapReduce的数据清洗流程
基于MapReduce的数据清洗流程
四、本章知识点架构
五、作业与练习
1、数据主要有哪三大来源?
答:①、大人群产生的海量数据;
②、大量传感器产生的海量数据;
③、科学研究和各行各业越来越依赖大数据手段来开展工作。
2、数据采集方法有哪些?
答:①、系统日志采集
②、互联网数据采集
③、App移动端数据采集
④、与数据服务机构进行合作
3、数据采集流程是怎样的?
答:首先要明确数据的来源,然后根据行业和应用的定位,来确定采集的数据范围和数量,并通过核实的数据采集方法,来开展后续的数据采集工作。
4、如何看待基于Flume的数据采集?
答:Flume是Cloudera提供的分布式的海量日志采集、聚合和传输的系统,在日志收集简单处理方面有重要应用。它收集来自各个服务器的外部数据,并以封装后的event(单元)流动,其间经过channel(缓冲区),最终到达sink(目的地),经过上述数据流向,最终达到日志数据采集的目的。
5、针对不同的业务需求,数据清洗的方法有哪些?
答:可以通过忽略元组、数据补齐或不处理的方法处理缺失值,通过回归、分箱或孤立点分析来处理噪声数据,通过合并或者消除来处理重复数据。
6、如何看待基于MapReduce的数据清洗?
答:MapReduce程序的编写主要是通过映射与化简的过程来实现数据去重的,对两种文件中的每行数据都可以看做是Map和Reduce函数处理后的Key值,当出现重复的Key值时,就将其合并在一起,从而达到去重的目的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号