Redis 安装和使用
redis
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件
高速缓存介绍
高速缓存利用内存保存数据,读写速度远超硬盘。
高速缓存可以减少I/O操作,降低I/O压力。
安装和启动:
dnf list redis
dnf module install redis # 安装
redis-server # 启动
编译安装的优势是:
- 编译安装时可以指定扩展的module(模块),php、apache、nginx都是一样有很多第三方扩展模块,如mysql,编译安装时候,如果需要就定制存储引擎(innodb,还是MyIASM)
- 编译安装可以统一安装路径,linux软件约定安装目录在/opt/下面
- 软件仓库版本一般比较低,编译源码安装可以根据需求,安装最新的版本
1. 下载redis源码并解压
wget http://download.redis.io/releases/redis-4.0.10.tar.gz
tar -zxf redis-4.0.10.tar.gz
cd redis-4.0.10.tar.gz
2. 编译
yum -y install gcc gcc-c++ kernel-devel
make
3.安装
make PREFIX=/usr/local/redis install
mkdir /usr/local/redis/etc/
cp redis.conf /usr/local/redis/etc/
cd /usr/local/redis/bin/
cp redis-benchmark redis-cli redis-server /usr/bin/
redis可执行文件
- ./redis-benchmark //用于进行redis性能测试的工具
- ./redis-check-dump //用于修复出问题的dump.rdb文件
- ./redis-cli //redis的客户端
- ./redis-server //redis的服务端
- ./redis-check-aof //用于修复出问题的AOF文件
- ./redis-sentinel //用于集群管理
4.更改配置
vim /usr/local/redis/etc/redis.conf # 修改配置
# redis以守护进程的方式运行 # no表示不以守护进程的方式运行(会占用一个终端) daemonize yes # 客户端闲置多长时间后断开连接,默认为0关闭此功能 timeout 300 # 设置redis日志级别,默认级别:notice loglevel verbose # 设置日志文件的输出方式,如果以守护进程的方式运行redis 默认:"" # 并且日志输出设置为stdout,那么日志信息就输出到/dev/null里面去了 logfile stdout # 设置密码授权 requirepass <设置密码> # 监听ip bind 127.0.0.1
5.配置环境变量
vim /etc/profile
#在文档最后新增
export PATH="$PATH:/usr/local/redis/bin"
# 保存退出
# 让环境变量立即生效
`source /etc/profile`
6.配置启动脚本
#!/bin/bash #chkconfig: 2345 80 90 # Simple Redis init.d script conceived to work on Linux systems # as it does use of the /proc filesystem. PATH=/usr/local/bin:/sbin:/usr/bin:/bin REDISPORT=6379 EXEC=/usr/local/redis/bin/redis-server REDIS_CLI=/usr/local/redis/bin/redis-cli PIDFILE=/var/run/redis.pid CONF="/usr/local/redis/etc/redis.conf" case "$1" in start) if [ -f $PIDFILE ] then echo "$PIDFILE exists, process is already running or crashed" else echo "Starting Redis server..." $EXEC $CONF fi if [ "$?"="0" ] then echo "Redis is running..." fi ;; stop) if [ ! -f $PIDFILE ] then echo "$PIDFILE does not exist, process is not running" else PID=$(cat $PIDFILE) echo "Stopping ..." $REDIS_CLI -p $REDISPORT SHUTDOWN while [ -x ${PIDFILE} ] do echo "Waiting for Redis to shutdown ..." sleep 1 done echo "Redis stopped" fi ;; restart|force-reload) ${0} stop ${0} start ;; *) echo "Usage: /etc/init.d/redis {start|stop|restart|force-reload}" >&2 exit 1 esac
7.开启自启动设置
# 复制脚本文件到init.d目录下 cp redis /etc/init.d/ # 给脚本增加运行权限 chmod +x /etc/init.d/redis # 查看服务列表 chkconfig --list systemctl list-dependencies redis #或這個 # 添加服务 chkconfig --add redis # 配置启动级别 chkconfig --level 2345 redis on
8.启动测试
systemctl start redis #或者 /etc/init.d/redis start systemctl stop redis #或者 /etc/init.d/redis stop # 查看redis进程 ps -el|grep redis # 端口查看 netstat -an|grep 6379
自己编译安装真累。。。。。
启动redis服务端
启动redis非常简单,直接./redis-server就可以启动服务端了,还可以用下面的方法指定要加载的配置文件:
redis-server redis.conf
默认情况下,redis-server会以非daemon的方式来运行,且默认服务端口为6379。
使用redis客户端
#执行客户端命令即可进入
./redis-cli
#测试是否连接上redis
127.0.0.1:6379 > ping
返回pong代表连接上了
//用set来设置key、value
127.0.0.1:6379 > set name "anna" # key可以用引号,也可以不用引号
OK
//get获取name的值
127.0.0.1:6379 > get name
"anna"
redis发布订阅
redis提供了发布(publish)订阅(subbscribe)功能
- Subscriber:收音机,可以受到多个频道,并且以队 列方式接收
- Publisher:电台,可以发往不同的FM频道
- Channel:不同的FM频道
一个Publisher对应多个Subscriber模型:

发布订阅的命令
PUBLISH channel msg
将信息 message 发送到指定的频道 channel
SUBSCRIBE channel [channel ...]
订阅频道,可以同时订阅多个频道
UNSUBSCRIBE [channel ...]
取消订阅指定的频道, 如果不指定频道,则会取消订阅所有频道
PSUBSCRIBE pattern [pattern ...]
订阅一个或多个符合给定模式的频道,每个模式以 * 作为匹配符,比如 it* 匹配所 有以 it 开头的频道( it.news 、 it.blog 、 it.tweets 等等), news.* 匹配所有 以 news. 开头的频道( news.it 、 news.global.today 等等),诸如此类
PUNSUBSCRIBE [pattern [pattern ...]]
退订指定的规则, 如果没有参数则会退订所有规则
PUBSUB subcommand [argument [argument ...]]
查看订阅与发布系统状态
注意:使用发布订阅模式实现的消息队列,当有客户端订阅channel后只能收到后续发布到该频道的消息,之前发送的不会缓存,必须Provider和Consumer同时在线。
实例(两个窗口实验):
subscribe diantai1 # 收听电台1
publish diantai1 'Hello! anna' # 广播电台1,信息为Hello! anna
订阅一个或者多个符合模式的频道
启动redis-cli窗口订阅 wang*频道(channel)
127.0.0.1:6379> PSUBSCRIBE wang*
可以接收wangwu,wangna等多个频道
redis持久化rdb与aof
Redis是一种内存型数据库,一旦服务器进程退出,数据库的数据就会丢失,为了解决这个问题,Redis提供了两种持久化的方案,将内存中的数据保存到磁盘中,避免数据的丢失。
RDB持久化
redis提供了RDB持久化的功能,这个功能可以将redis在内存中的的状态保存到硬盘中,它可以手动执行。
也可以redis.conf中配置,定期执行。
RDB持久化产生的RDB文件是一个经过压缩的二进制文件,这个文件被保存在硬盘中,redis可以通过这个文件还原数据库当时的状态。
在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)
优点:速度快,适合做备份,主从复制就是基于RDB持久化功能实现
rdb通过在redis中使用save命令触发 rdb
redis持久化之RDB实践:
- redis的rdb配置:
daemonize yes # 守护进程,后台运行 port 6379 logfile /var/log/redis/redis.log dir /var/lib/redis #定义持久化文件存储位置 dbfilename dbmp.rdb #rdb持久化文件 bind 127.0.0.1 #redis绑定地址 requirepass anna #redis登录密码 save 900 1 #rdb机制 每900秒内如果至少有1个key的值变化,则保存 save 300 10 #每300秒 10个修改记录 save 60 10000 #每60秒内 10000修改记录
- 启动redis服务端
3.登录redis设置一个key
redis-cli -a anna- 此时检查目录,/var/lib/redis底下没有dbmp.rdb文件
- 通过save触发持久化,将数据写入RDB文件
127.0.0.1:6379> set age 18 OK 127.0.0.1:6379> save OK
redis持久化之AOF
AOF(append-only log file)
记录服务器执行的所有变更操作命令(例如set del等),并在服务器启动时,通过重新执行这些命令来还原数据集
AOF 文件中的命令全部以redis协议的格式保存,新命令追加到文件末尾。
- 优点:最大程序保证数据不丢
- 缺点:日志记录非常大
redis-client 写入数据> redis-server同步命令>AOF文件
配置参数
appendonly yes
appendfsync always 总是修改类的操作
everysec 每秒做一次持久化
no 依赖于系统自带的缓存大小机制
1.准备aof配置文件 redis.conf
daemonize yes
port 6379
logfile /var/log/redis/redis.log
dir /var/lib/redis
dbfilename dbmp.rdb
requirepass anna
save 900 1
save 300 10
save 60 10000
appendonly yes
appendfsync everysec
2.启动redis服务
redis-server /etc/redis.conf
3.检查redis数据目录/var/lib/redis是否产生了aof文件
ls /var/lib/redis
appendonly.aof dbmp.rdb redis.log
4.登录redis-cli,写入数据,实时检查aof文件信息
tail -f appendonly.aof
5.设置新key,检查aof信息,然后关闭redis,检查数据是否持久化
redis-cli -a anna shutdown
redis-server /etc/redis.conf
redis-cli -a anna
区别:
rdb:基于快照的持久化,速度更快,一般用作备份,主从复制也是依赖于rdb持久化功能
aof:以追加的方式记录redis操作日志的文件。可以最大程度的保证redis数据安全,类似于mysql的binlog
RDB持久化切换AOF持久化:
确保redis版本在2.2以上
redis-server -v备份rdb,保证数据安全:
cp /var/lib/redis/dbmp.rdb /opt/执行命令,开启AOF持久化
127.0.0.1:6379> CONFIG set appendonly yes #开启AOF功能 OK 127.0.0.1:6379> CONFIG SET save "" #关闭RDB功能 OK查看AOF文件:
ll /var/lib/redis/
确保数据库的key数量正确
127.0.0.1:6379> keys * 1) "addr" 2) "age"确保插入新的key,AOF文件会记录
127.0.0.1:6379> set title golang OK此时RDB已经正确切换AOF,注意还得修改redis.conf添加AOF设置,不然重启后,通过config set的配置将丢失.
redis主从同步
- Redis集群中数据库复制是通过主从同步实现的
- 主节点(Master)把数据分发给从节点(Slave)
- 主从同步的好处在于高可用,Redis节点有冗余设计
原理:
- 从服务器向主服务器发送 SYNC 命令。
- 接到 SYNC 命令的主服务器会调用BGSAVE 命令,创建一个 RDB 文件,并使用缓冲区记录接下来执行的所有写命令。
- 当主服务器执行完 BGSAVE 命令时,它会向从服务器发送 RDB 文件,而从服务器则会接收并载入这个文件。
- 主服务器将缓冲区储存的所有写命令发送给从服务器执行。
- 在开启主从复制的时候,使用的是RDB方式的,同步主从数据的
- 同步开始之后,通过主库命令传播的方式,主动的复制方式实现
- 2.8以后实现PSYNC的机制,实现断线重连
redis主从同步配置
步骤一、准备一主两从的数据库实例
主节点:6380。从节点:6381、6382
1、环境:
准备两个或两个以上redis实例
mkdir /data/638{0..2}#创建6380 6381 6382文件夹配置文件示例:
vim /data/6380/redis.conf
6380.confport 6380 daemonize yes pidfile /data/6380/redis.pid loglevel notice logfile "/data/6380/redis.log" dbfilename dump.rdb dir /data/6380 protected-mode no6381.conf
vim /data/6381/redis.conf port 6381 daemonize yes pidfile /data/6381/redis.pid loglevel notice logfile "/data/6381/redis.log" dbfilename dump.rdb dir /data/6381 protected-mode no6382.conf
port 6382 daemonize yes pidfile /data/6382/redis.pid loglevel notice logfile "/data/6382/redis.log" dbfilename dump.rdb dir /data/6382 protected-mode no启动三个redis实例
redis-server /data/6380/redis.conf redis-server /data/6381/redis.conf redis-server /data/6382/redis.conf步骤二、配置主从同步
6381/6382命令行
redis-cli -p 6381 SLAVEOF 127.0.0.1 6380 #指明主的地址 redis-cli -p 6382 SLAVEOF 127.0.0.1 6380 #指明主的地址检查主从状态
从库:
127.0.0.1:6382> info replication 127.0.0.1:6381> info replication主库:
127.0.0.1:6380> info replication测试写入数据,主库写入数据,检查从库数据
主 127.0.0.1:6380> set name chaoge 从 127.0.0.1:6381>get name手动进行主从复制故障切换
#关闭主库6380 redis-cli -p 6380 shutdown检查从库主从信息,此时
master_link_status:downredis-cli -p 6381 info replication redis-cli -p 6382 info replication既然主库挂了,就要在6381 6382之间选一个新的主库
1.关闭6381的从库身份
redis-cli -p 6381 info replication slaveof no one2.将6382设为6381的从库
6382连接到6381: [root@db03 ~]# redis-cli -p 6382 127.0.0.1:6382> SLAVEOF no one 127.0.0.1:6382> SLAVEOF 127.0.0.1 6381 3.检查6382,6381的主从信息:`info replication`
redis 哨兵(redis-Sentinel)
- Redis-Sentinel是redis官方推荐的
高可用性解决方案, - 当用redis作master-slave的高可用时,如果master本身宕机,redis本身或者客户端都没有实现主从切换的功能。
- 而redis-sentinel就是一个独立运行的进程,用于监控多个master-slave集群,
- 自动发现master宕机,进行自动切换slave > master。
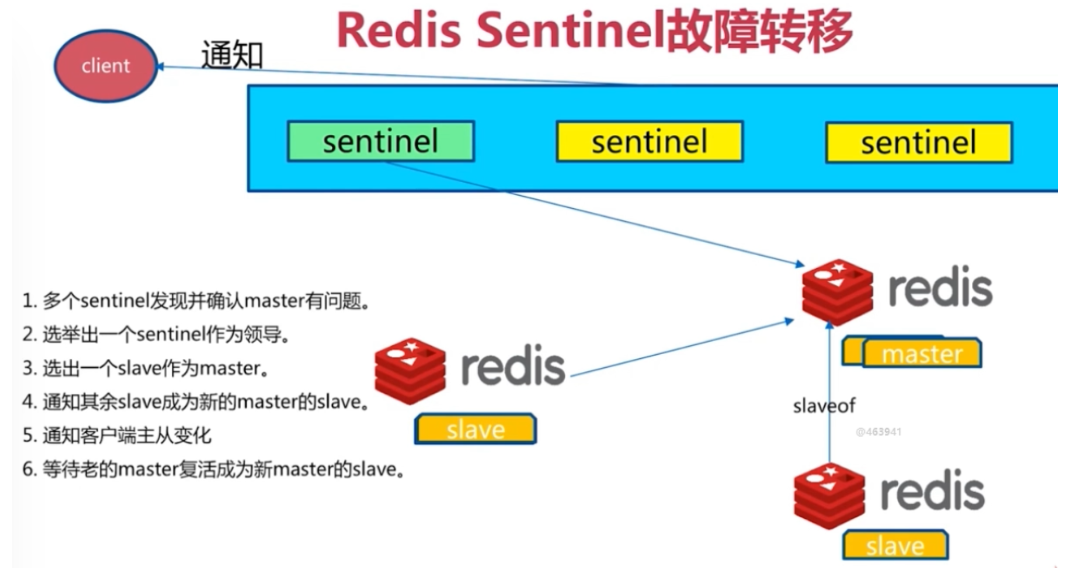
sentinel主要功能如下:
- 不时的监控redis是否良好运行,如果节点不可达就会对节点进行下线标识
- 如果被标识的是主节点,sentinel就会和其他的sentinel节点“协商”,如果其他节点也认为主节点不可达,就会选举一个sentinel节点来完成自动故障转义
- 在master-slave进行切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换
Redis-sentinel工作机制
- 每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。
- 如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
- 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线
- 在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令
- 当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次
- 若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。
- 若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
- 主观下线和客观下线
- 主观下线:Subjectively Down,简称 SDOWN,指的是当前 Sentinel 实例对某个redis服务器做出的下线判断。
- 客观下线:Objectively Down, 简称 ODOWN,指的是多个 Sentinel 实例在对Master Server做出 SDOWN 判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的Master Server下线判断,然后开启failover.
- SDOWN适合于Master和Slave,只要一个 Sentinel 发现Master进入了ODOWN, 这个 Sentinel 就可能会被其他 Sentinel 推选出, 并对下线的主服务器执行自动故障迁移操作。
- ODOWN只适用于Master,对于Slave的 Redis 实例,Sentinel 在将它们判断为下线前不需要进行协商, 所以Slave的 Sentinel 永远不会达到ODOWN。
redis主从复制背景问题
Redis主从复制可将主节点数据同步给从节点,从节点此时有两个作用:
- 一旦主节点宕机,从节点作为主节点的备份可以随时顶上来。
- 扩展主节点的读能力,分担主节点读压力。
但是问题是:
一旦主节点宕机,从节点上位,那么需要人为修改所有应用方的主节点地址(改为新的master地址),还需要命令所有从节点复制新的主节点
那么这个问题,redis-sentinel就可以解决了
redis sentinel架构图
redis的一个进程,但是不存储数据,只是监控redis.
发现新的sentinel:
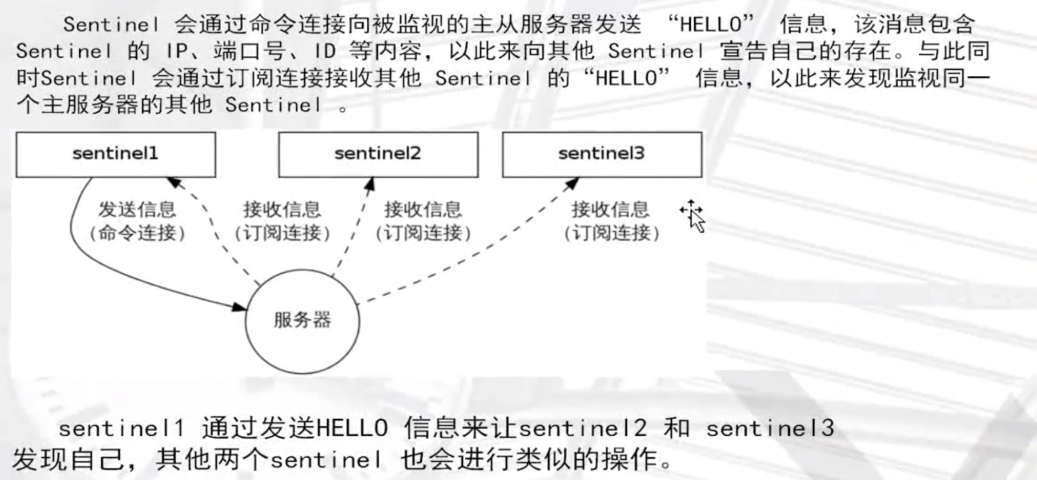

安装配置redis哨兵
本实验是在测试环境下,因此只准备一台linux服务器用作环境!!
总体redis配置文件如下,6379为master,6380和6381为slave
先创建redis.conf:
touch /etc/redis-63{79..81}.conf主节点master的redis-6379.conf
port 6379 daemonize yes logfile "6379.log" dbfilename "dump-6379.rdb" dir "/var/lib/redis/"从节点slave的redis-6380.conf
port 6380 daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/var/lib/redis/" // 从属主节点 slaveof 127.0.0.1 6379从节点slave的redis-6381.conf
port 6381 daemonize yes logfile "6381.log" dbfilename "dump-6381.rdb" dir "/var/lib/redis/" // 从属主节点 slaveof 127.0.0.1 6379启动redis主节点:
redis-server /etc/redis-6379.conf测试redis主节点是否通信:
redis-cli ping启动两slave节点:
redis-server /etc/redis-6380.conf redis-server /etc/redis-6381.conf验证从节点的redis服务
ps aux | grep redis检测主从关系
在主节点上查看主从通信关系[root@master ~]# redis-cli -p 6379 info replication # Replication role:master connected_slaves:2 slave0:ip=192.168.119.10,port=6380,state=online,offset=407,lag=0 slave1:ip=192.168.119.10,port=6381,state=online,offset=407,lag=0 ......在从节点上查看主从关系(6380、6379)
[root@slave 192.168.119.11 ~]$redis-cli -p 6380 info replication # Replication role:slave master_host:192.168.119.10 master_port:6379 master_link_status:up ......
此时可以在master上写入数据,在slave上查看数据,此时主从复制配置完成配置redis sentinel环境
创建sentinel文件:
touch /etc/redis-sentinel-263{79..81}.conf
vim /etc/redis-sentinel-26379.confredis-sentinel-26379.conf配置文件写入如下信息
# Sentinel节点的端口 port 26379 dir /var/lib/redis/ logfile "26379.log" # 当前Sentinel节点监控 192.168.32.131:6379 这个主节点 # 2代表判断主节点失败至少需要2个Sentinel节点节点同意 # mymaster是主节点的别名 sentinel monitor mymaster 192.168.32.131 6379 2 # 每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过30000毫秒30s且没有回复,则判定不可达 sentinel down-after-milliseconds mymaster 30000 # 当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点, 原来的从节点会向新的主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为1 sentinel parallel-syncs mymaster 1 # 故障转移超时时间为180000毫秒 sentinel failover-timeout mymaster 180000redis-sentinel-26380.conf redis-sentinel-26381.conf的配置仅仅差异是port,logfile的不同。然后启动三个sentinel哨兵
redis-sentinel /etc/redis-sentinel-26379.conf redis-sentinel /etc/redis-sentinel-26380.conf redis-sentinel /etc/redis-sentinel-26381.conf此时查看哨兵是否成功通信
[root@master ~]# redis-cli -p 26379 info sentinel # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=mymaster,status=ok,address=192.168.119.10:6379,slaves=2,sentinels=3 #看到最后一条信息正确即成功了哨兵,哨兵主节点名字叫做mymaster,状态ok,监控地址是192.168.119.10:6379,有两个从节点,3个哨兵
redis高可用故障实验
大致思路
- 杀掉主节点的redis进程6379端口,观察从节点是否会进行新的master选举,进行切换
- 重新恢复旧的“master”节点,查看此时的redis身份
首先查看三个redis的进程状态
ps -ef|grep 6380結束6379端口的redis(kill master!!!)
查看兩個slave狀態:精髓就是查看一个参数:
master_link_down_since_seconds:13過一會检查三个节点的身份状态(等待其他两个节点是否能自动被哨兵sentienl,切换为master节点)
此时查看两个slave的状态
redis-cli -p 6380 info replication redis-cli -p 6381 info replication稍等片刻之后,发现slave节点成为master节点!!
[root@localhost ~]# redis-cli -p 6380 info replication # Replication role:master connected_slaves:1 ......大功告成!!
redis-cluster
为什么要用redis-cluster?
-
并发问题
- redis官方生成可以达到 10万/每秒,每秒执行10万条命令,假如业务需要每秒100万的命令执行呢?
-
数据量太大
-
一台服务器内存正常是16~256G,假如你的业务需要500G内存,你怎么办?
-
新浪微博作为世界上最大的redis存储,就超过1TB的数据,去哪买这么大的内存条?正确的应该是分布式,加机器,把数据分到不同的位置,分摊集中式的压力,一堆机器做一件事
-
客户端分片
redis实例集群主要思想是将redis数据的key进行散列,通过hash函数``特定的key会映射到指定的redis节点上
分布式数据库首要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整个数据的一个子集。
常见的分区规则有哈希分区和顺序分区。Redis Cluster采用哈希分区规则,因此接下来会讨论哈希分区规则。
- 节点取余分区
- 一致性哈希分区
- 虚拟槽分区(redis-cluster采用的方式)
顺序分区
1~33 34~66 67~100
哈希分區(取模,再根据余数分区)
1,4,10..,100 2,5,11..,98 3,6,9..,99
虚拟槽分区
Redis Cluster采用虚拟槽分区
虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有的数据映射到一个固定范围内的整数集合,整数定义为槽(slot)。
Redis Cluster槽的范围是0 ~ 16383。
槽是集群内数据管理和迁移的基本单位。采用大范围的槽的主要目的是为了方便数据的拆分和集群的扩展,
每个节点负责一定数量的槽。
如何搭建redis-cluster
搭建集群分为:
- 准备节点(几匹马儿)
- 节点通信(几匹马儿分配主从)
- 分配槽位给节点(slot分配给马儿)
redis-cluster集群架构
- 多个服务端,负责读写,彼此通信,redis指定了16384个槽。
- 多匹马儿,负责运输数据,马儿分配16384个槽位,管理数据。
- ruby的脚本自动就把分配槽位这事做了
安装方式
官方提供通过ruby语言的脚本一键安装
步骤一、通过配置,redis.conf开启redis-cluster
创建redis-cluster配置文件目录:mkdir -p /opt/redis/config
redis支持多实例的功能,我们在单机演示集群搭建,需要6个实例,三个是主节点,三个是从节点,数量为6个节点才能保证高可用的集群。
创建redis-cluster配置文件:touch /opt/redis/config/redis-{7000..7005}.conf
port 7000
daemonize yes
dir "/opt/redis/data"
logfile "7000.log"
dbfilename "dump-7000.rdb"
cluster-enabled yes #开启集群模式
cluster-config-file nodes-7000.conf #集群内部的配置文件
cluster-require-full-coverage no #redis cluster需要16384个slot都正常的时候才能对外提供服务,换句话说,只要任何一个slot异常那么整个cluster不对外提供服务。 因此生产环境一般为no
每个节点仅仅是端口的不同!确保每个配置文件中的port,cluster-config-file修改!!
步骤二、运行redis实例
创建6个节点的redis实例
redis-server redis-7000.conf
redis-server redis-7001.conf
redis-server redis-7002.conf
redis-server redis-7003.conf
redis-server redis-7004.conf
redis-server redis-7005.conf
步骤三、开启redis-cluster
创建集群:
旧版本中的redis-trib.rb已经废弃了,直接用–cluster命令。注意用绝对IP,不要用127.0.0.1
#每个主节点,有一个从节点,代表--replicas 1
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
#集群自动分配主从关系 7000、7001、7002为 7003、7004、7005 主动关系
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:7003 to 127.0.0.1:7000
Adding replica 127.0.0.1:7004 to 127.0.0.1:7001
Adding replica 127.0.0.1:7005 to 127.0.0.1:7002
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 85b21a7ce4c6521e5ee34eea8756d26bcd53076c 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
M: d0db38c59a812ede8a8e03fb851f44b3955b965d 127.0.0.1:7001
slots:[5461-10922] (5462 slots) master
M: 69c5e7190dd89d2f8575cbe207f8d1379093a610 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
......
注意看slot的分布:
slots:[0-5460] (5461 slots) master # (5461个槽)
slots:[5461-10922] (5462 slots) master
slots:[10923-16383] (5461 slots) master
查看集群状态
redis-cli -p 7000 cluster info
redis-cli -p 7000 cluster nodes #等同于查看nodes-7000.conf文件节点信息
集群主节点状态
redis-cli -p 7000 cluster nodes | grep master
集群从节点状态
redis-cli -p 7000 cluster nodes | grep slave
写入redis-cluster集群数据
安装完毕后,检查集群状态
[root@yugo /opt/redis/src 18:42:14]#redis-cli -p 7000 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
......
测试写入集群数据,登录集群必须使用redis-cli -c -p 7000必须加上-c参数
127.0.0.1:7000> set name chao
-> Redirected to slot [5798] located at 127.0.0.1:7001
OK
127.0.0.1:7001> exit
[root@yugo /opt/redis/src 18:46:07]#redis-cli -c -p 7000
127.0.0.1:7000> ping
PONG
127.0.0.1:7000> keys *
(empty list or set)
127.0.0.1:7000> get name
-> Redirected to slot [5798] located at 127.0.0.1:7001
"chao"
如果沒重置redis-cluster ,可能會報錯:
[ERR] Node 127.0.0.1:7001 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.清楚集群節點:
$redis-cli -p 7000 127.0.0.1:7000> flushall 127.0.0.1:7000> cluster reset 127.0.0.1:7000> exit
redis-python api
1、对redis的单实例进行连接操作
python3
>>>import redis
>>>r = redis.StrictRedis(host='localhost', port=6379, db=0,password='root')
>>>r.set('lufei', 'guojialei')
True
>>>r.get('lufei')
'bar'
--------------------
2、sentinel集群连接并操作
[root@db01 ~]# redis-server /etc/redis-6379.conf
[root@db01 ~]# redis-server /etc/redis-6380.conf
[root@db01 ~]# redis-server /etc/redis-6381.conf
[root@localhost ~]# redis-sentinel /etc/redis-sentinel-26379.conf
[root@localhost ~]# redis-sentinel /etc/redis-sentinel-26380.conf
[root@localhost ~]# redis-sentinel /etc/redis-sentinel-26381.conf
**********************************************
## 导入redis sentinel包
>>> from redis.sentinel import Sentinel
##指定sentinel的地址和端口号
>>> sentinel = Sentinel([('localhost', 26380)], socket_timeout=0.1)
##测试,获取以下主库和从库的信息
>>> sentinel.discover_master('mymaster')
('127.0.0.1', 6380)
>>> sentinel.discover_slaves('mymaster')
[('127.0.0.1', 6379), ('127.0.0.1', 6381)]
##配置读写分离
>>> master = sentinel.master_for('mymaster', socket_timeout=0.1)
>>> slave = sentinel.slave_for('mymaster', socket_timeout=0.1)
###读写分离测试
>>> master.set('age', '18')
True
>>> slave.get('age')
b'18'
----------------------
redis cluster的连接并操作(python2.7.2以上版本才支持redis cluster,我们选择的是3.5)
https://github.com/Grokzen/redis-py-cluster
3、python连接rediscluster集群测试
python3
>>> from rediscluster import RedisCluster
>>> startup_nodes = [{"host": "127.0.0.1", "port": "7000"}]
>>> rc = RedisCluster(startup_nodes=startup_nodes, decode_responses=True)
>>> rc.set("foo", "bar")
True
>>> rc.get('foo')
'bar'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号