黑科技
前言
这里记录&总结一些平常 \(OI\) 竞赛中并不是很常用的毒瘤玩意。
黑科技
黑科技数据结构
1. 李超线段树
一种线段树维护某一类信息的方法。
支持区间加入一次函数,询问区间的一次函数最值。
修改复杂度为 \(O(log^2n)\) , 如果是全局加入就是\(O(log\;n)\)
查询复杂度为 \(O(log\;n)\)
维护的信息:
flag[u] 当前节点是否插入了一次函数
K[u],B[u] 表示当前节点区域中最优的一次函数
Min/Max[u] 区间的最小值或最大值,一般是在询问的是区间的时候才有必要维护
李超线段树维护信息的方法就是线段树的标记永久化 , 似乎不能支持删除。
对于一个区间修改 , 如果当前区间没有加入过直线 , 那么直接加入。
如果已有直线,比较两条直线,如果一条完全优于另外一条 , 那么替换或者是直接返回。
如果各有优劣,则看哪一条在当前区间内优势的部分较多,保留多的那一个,劣的继续往下递归。
由于一次函数的单调性 , 如果我们保留长的在当前区间 , 那么往下递归插入的一次函数只用插向一边,因为只会存在一个优劣转换的点,这样长度每次减半,复杂度就是 \(O(log\ n)\)
如果是区间插入 , 那么要先定位到 \(O(log\ n)\) 个区间,复杂度就是 \(O(log^2n)\) 了。
对于比较那个点的优势区间更长,可以采取算交点的方式,但我一般采用比较中点函数值的大小来推算,稍加讨论就行了。
\(Tips:\)
如果插入的一次函数并不是平常的连续一次函数 , 而是有实际意义的 , 那么一定要搞清楚到底 \(x\) 是什么 , 选好合适的 \(x\) 的含义来简化计算!
区间插入的模板:
void Modify(int u,int l,int r,int L,int R,ll k,ll b){
int mid=l+r>>1;
if(l>=L&&r<=R){
if(!T[u].flag) {T[u].Fill(k,b,l,r);return;}
ll yln=F(k,b,l),yrn=F(k,b,r),ylo=T[u].F(l),yro=T[u].F(r);
if(yln>=ylo&&yrn>=yro) return;
if(yln<=ylo&&yrn<=yro) return T[u].Fill(k,b,l,r);
else {
ll ymn=F(k,b,mid),ymo=T[u].F(mid);
if(ymn>=ymo) {
if(yln>=ylo) Modify(rs,mid+1,r,L,R,k,b);
else Modify(ls,l,mid,L,R,k,b);
}
else {
if(yln>=ylo) Modify(ls,l,mid,L,R,T[u].k,T[u].b),T[u].Fill(k,b,l,r);
else Modify(rs,mid+1,r,L,R,T[u].k,T[u].b),T[u].Fill(k,b,l,r);
}
T[u].Min=min(T[u].Min,min(T[ls].Min,T[rs].Min));
return;
}
if(l==r) return;
}
if(mid>=L) Modify(ls,l,mid,L,R,k,b);
if(mid< R) Modify(rs,mid+1,r,L,R,k,b);
T[u].Min=min(T[u].Min,min(T[ls].Min,T[rs].Min));
return;
}
2.后缀平衡树
用平衡树来动态维护 SA 数组,支持动态往前加入字符。
当前面新加入一个字符的时候,容易发现这只是一个普通的插入过程,我们只需要在平衡树上走并比较就行了。
所以我们只需要找到一种能够支持快速比较的方法。第一位直接比较,如果不同直接得出大小关系,相同时我们发现就是比较下一位的两个后缀。也就是说我们需要快速得到之前平衡树里另外节点的前后顺序关系。如果继续在平衡树中进行查找,那么时间复杂度多了一个 \(log\),不优秀。
解决方法是采用对于每一个节点赋权值的方式来完成快速比较。
一开始权值区间设为 (0,1) 根节点为 0.5,然后左右的范围分别变成 (0,0.5) , (0.5,1),节点权值取中点,以此类推。
这样的话写起来非常方便,但我们要求树高不能太高,所以我们使用替罪羊树来维护是再好不过的选择了。
板子题 BZOJ Phorni
黑科技算法
1.斯坦那树
其实只是一种解决一类状压dp的方法。
当我们需要进行有关联通性的状压 dp 时 , 只要求关键点连通且关键点较少 , 但是非关键点比较多的时候 , 可以用到斯坦那树。
其实是一类不要求所有点连通而只要求一部分点连通的 \(MST\) , 只能状压来求。
状压关键点的连通性 , 并确定一个点已经在树中 , 那么在不影响关键点的状态 , 也就是相同状态中可以用最短路来转移 , 而不同状态一般固定一个点 , 枚举子集然后合并。
通过最短路巧妙解决了非关键之间连边的决策。
2.朱刘算法
最小树形图:
求解步骤:
首先要明确的一点是每一个点只会有一条入边。
- 为所有点找到一个最小的入边。
- 把这些边的权值加入答案 , 然后判断图中是否存在环。
- 不存在环那么算法结束 , 否则缩环(直接往入边方向跳即可,不要tarjan) , 并把所有不在环内边的边的权值减去指向点的最小入边(之前的环不合法 , 其中要去掉一条边 , 这里减去原入边边权就是在之后选择新的边的时候考虑了这个权值的变化)
代码:
#include<bits/stdc++.h>
using namespace std;
template<class T>inline void init(T&x){
x=0;char ch=getchar();bool t=0;
for(;ch>'9'||ch<'0';ch=getchar()) if(ch=='-') t=1;
for(;ch>='0'&&ch<='9';ch=getchar()) x=(x<<1)+(x<<3)+(ch-48);
if(t) x=-x;return;
}
const int M=1e4+10;
const int N=101;
namespace Directed_MST{
struct edge{int u,v,w;edge(){u=v=w=0;}edge(int a,int b,int c){u=a,v=b,w=c;}}a[M],b[M];
int cnt=0;
int ans=0;
int In[N],bel[N],vis[N];
int n,m,r,bcc=0;
inline int MST(){
for(int i=1;i<=n;++i) In[i]=bel[i]=vis[i]=0;bcc=0;
for(int i=1;i<=m;++i) {// find minum_weight in_edge
int u=a[i].u,v=a[i].v,w=a[i].w;
if((!In[v])||a[In[v]].w>w) In[v]=i;
}
for(int u=1;u<=n;++u) {// judge circle and shrink them , sum the cost
if(!In[u]&&u!=r) return -1;
if(u!=r) ans+=a[In[u]].w;
if(vis[u]) continue;
int v=u;
for(;v^r&&vis[v]^u&&!bel[v];v=a[In[v]].u) vis[v]=u;// root needn't go back
if(v^r&&!bel[v]) {// is a circle
int s=v;bel[s]=++bcc;
for(s=a[In[s]].u;v^s;s=a[In[s]].u) bel[s]=bcc;
}
}if(!bcc) return 0;
for(int i=1;i<=n;++i) if(!bel[i]) bel[i]=++bcc;// other node
cnt=0;
for(int i=1;i<=m;++i){// shrink circle , create new edge
int u=a[i].u,v=a[i].v,w=a[i].w;
if(bel[u]==bel[v]) continue;
int goi=a[In[v]].w;
b[++cnt]=edge(bel[u],bel[v],w-goi);
}
for(int i=1;i<=cnt;++i) a[i]=b[i];m=cnt,cnt=0;
n=bcc;return 1;
}
void work(){
init(n),init(m);init(r);
int u,v,w;
for(int i=1;i<=m;++i) {init(u),init(v),init(w);if(u==v) --i,--m;else a[i]=edge(u,v,w);}
int ret;
while((ret=MST())==1) r=bel[r];
if(~ret) printf("%d\n",ans);
else puts("-1");
}
}
int main(){Directed_MST::work();}
3.最小割树
\(Gemory-Hu\; Tree\)算法
对于一个 \(n\) 个节点的图 , 图中所有点对不同的最小割数目最多只有 \(n-1\) 个 , 可以证明存在一棵树 , 使得两点在这棵树上的最小割即为原图中的最小割 。
考虑3个点两两之间的最小割 \(C_{u,v},C_{u,t},C_{v,t}\) , 我们已知 \(C_{u,t},C_{v,t}\) , 假设在\(C_{u,v}\)中 ,不妨假设 \(t\) 被分在了与 \(v\) 在一起的割集 。由于在一个割中一个点一定被分在源点或者汇点的一侧割集 , 那么可以推出 \(C_{u,v}\leq C_{u,t}\) , 如果不是那么显然直接割掉 \(u,t\) 就能达到割掉 \(u,v\) 的目的而使最小割变小。
类似的可以得出 \(C_{u,v}\geq C_{u,t}\) , 那么只能是 \(C_{u,v}=C_{u,t}\) 。
用归纳法可以得到一个 \(n\) 个点的图中最多只有 \(n-1\) 个不同的最小割。
如何构建最小割树?
采用递归的策略 , 对于当前点集 , 任意取两个点做最小割(注意这里是对原图跑最小割) , 然后给这两个点连边 , 权值为最小割大小。
然后就把参与网络中与源点可达的点与源点扔在一起 , 与其他的和汇点扔在一起。两边递归即可。
正确性就是证明只有 \(n-1\) 个不同的最小割中的道理相同 , 考虑某一个点被划分在哪个集合从而保证了正确性。
模板题code:
#include<bits/stdc++.h>
using namespace std;
#define Set(a,b) memset(a,b,sizeof(a))
#define Copy(a,b) memcpy(a,b,sizeof(a))
template<class T>inline void init(T&x){
x=0;char ch=getchar();bool t=0;
for(;ch>'9'||ch<'0';ch=getchar()) if(ch=='-') t=1;
for(;ch>='0'&&ch<='9';ch=getchar()) x=(x<<1)+(x<<3)+(ch-48);
if(t) x=-x;return;
}
const int M=1520;
const int N=520,INF=2e9;
int n,m;
int dis[N][N];
struct edge{
int to,next,cap,flow;
}a[M<<1];
int cnt=0,head[N],cur[N];
inline void add(int x,int y,int z){a[cnt]=(edge){y,head[x],z,z};head[x]=cnt++;}
int d[N];
int que[N],tail=0,bel[N];
inline void Return(){for(int i=0;i<cnt;++i) a[i].cap=a[i].flow;for(int i=0;i<=n;++i) bel[i]=0;}
queue<int>Q;
int S,T;bool had[N];
inline bool bfs(){
Set(d,0);
while(!Q.empty()) Q.pop();
Q.push(S);d[S]=1;
while(!Q.empty()){
int u=Q.front();Q.pop();
for(int v,i=head[u];~i;i=a[i].next){
v=a[i].to;if(d[v]||!a[i].cap) continue;
d[v]=d[u]+1;Q.push(v);
}
}
return d[T];
}
int dfs(int u,int flow){
if(u==T) return flow;
int rest=flow;
for(int v,&i=cur[u];~i;i=a[i].next){
v=a[i].to;if(d[v]!=d[u]+1||!a[i].cap) continue;
int f=dfs(v,min(a[i].cap,rest));
if(!f) d[v]=0;
a[i].cap-=f,a[i^1].cap+=f;
rest-=f;if(!rest) break;
}
return (flow-rest);
}
inline int Dinic(){
int flow=0;
while(bfs()) Copy(cur,head),flow+=dfs(S,INF);
return flow;
}
void Dfs(int u){bel[u]=1;for(int v,i=head[u];~i;i=a[i].next){v=a[i].to;if(!a[i].cap||bel[v]) continue;Dfs(v);}return;}
namespace Gomory_Hu_Tree{
struct edge{
int to,next,w;
}a[N<<1];int head[N],cnt=0;
inline void add(int x,int y,int z){a[++cnt]=(edge){y,head[x],z};head[x]=cnt;}
int tmp[N];
inline void Divide(int l,int r){
if(l>=r) return;int u;
S=que[l],T=que[r];Return();int Flow=Dinic();Dfs(S);
int L=l-1,R=r+1;add(S,T,Flow),add(T,S,Flow);
for(int i=l;i<=r;++i) {
u=que[i];if(bel[u]==1) tmp[++L]=u;else tmp[--R]=u;}for(int i=l;i<=r;++i) que[i]=tmp[i];
Divide(l,L);Divide(R,r);
return;
}
void DFS(int u,int fr,int fa,int Mi){
dis[fr][u]=dis[u][fr]=Mi;
for(int v,i=head[u];i;i=a[i].next){
v=a[i].to;if(v==fa) continue;
DFS(v,fr,u,min(Mi,a[i].w));
}
return;
}
inline void Work(){
for(int i=0;i<=n;++i) que[++tail]=i;
Divide(1,tail);return;
}
}using Gomory_Hu_Tree::DFS;
int main()
{
init(n),init(m);
int u,v,w;Set(head,-1);
for(int i=1;i<=m;++i) {
init(u),init(v),init(w);
add(u,v,w),add(v,u,w);
}
Gomory_Hu_Tree::Work();
int Q;init(Q);
while(Q--){
init(u),init(v);
if(!had[u]&&!had[v]) DFS(u,u,0,INF),had[u]=1;
printf("%d\n",dis[u][v]);
}
return 0;
}
4.灭绝树&支配树
如果钦定一个起点 \(S\) , 对于点 \(u\) 来说 , 如果点 \(p\) ,存在于任意一条从 \(S\) 到 \(u\) 的路径上 , 也就是从 \(S\) 到 \(u\) 必定经过点 \(p\) , 那么称 \(p\) 支配 \(u\) , 如果点 \(p\) 支配了 \(u\) 且不存在一个点 \(q\) 支配 \(u\) 且被 \(p\) 支配 , 那么称 \(p\) 是 \(u\) 的支配点。
这样子一个点的支配点只有一个 , 就形成了一个树形结构。
-
树的支配树
树的本身就是自己的支配树。 -
\(DAG\) 的支配树
也叫灭绝树。
求解方法:
增量法构造。一开始只有根节点。
对原图进行拓扑排序 , 按照拓扑序 , 取出一个点时 , 所有和该点有边直接相连的点在已经构建好的支配树上的 \(LCA\) 就是这个点在支配树上的父亲。
要求动态加叶子节点并维护 \(LCA\) , 动态处理倍增数组即可 , 当然你也可以写一个 \(LCT\) 。
证明画个图很好理解。
因为考虑了所有可能到达该点的点 , 求个 \(LCA\) 显然就是所有到达该点的必经点了。 -
一般有向图的支配树
这里是一种转成 \(DAG\) 然后照着 \(DAG\) 的方法做的方法。
我们定义半支配点:
令 \(semi[v]=min_{dfn}\{u| \exists path(u,v_1,v_2,v_3,\dots,v) \forall i,dfn[v_i]>dfn[v] \}\)
显然点 \(v\) 在 \(dfs\)树 上的父亲已经满足了条件 , 但由于 \(dfs\) 序不是最小的所以不一定是它的半支配点。不过这也说明了一个点的半支配点的 \(dfs\) 序一定小于该点的 \(dfs\) 序。
如图:
\(dfs\) 访问顺序 :
\(dfn[\ ]=\{1,7,2,3,4,5,6,8,9\}\)
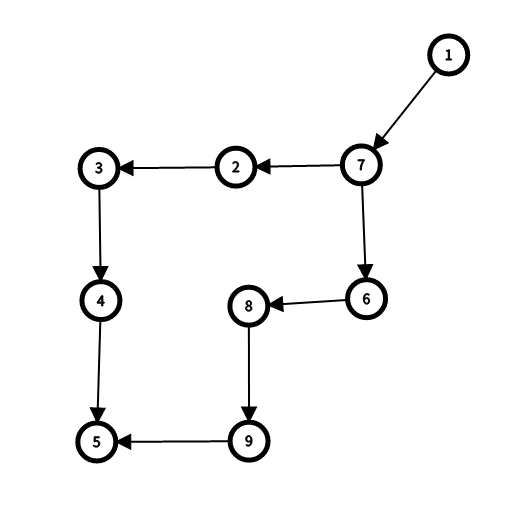
那么 \(5\) 号点的半支配点就是 \(7\) 号点 , 而其他点的半支配点都是 \(dfs\) 树上的父亲。
那么怎么求解半支配点?
首先要知道一些性质:
- \(dfs\)树有一个好的性质 , 就是没有被走过的边一定是由 \(dfn\) 大的指向 \(dfn\) 小的。
- 一个点的半支配点一定是该点在 \(dfs\) 树上的祖先 。 因为 \(dfs\) 树没有横叉边 , 而半支配点的 \(dfs\) 序要小于该点 , 那么只能是其祖先。
- 建立一个新图 , 保留 \(dfs\) 树后 , 从一个点的半支配点向该点连有向边形成一个 \(DAG\) , 在这张图上支配关系不发生改变。
感性理解:
首先为什么一个点的半支配点不一定是他的支配点?
我们假设 \(semi[v]=u\) , 即 \(u\) 是 \(v\) 的半支配点
因为 \(u\) 只考虑了到达自己以后再到 \(v\) 这一段路 , 而有可能从该点的 \(dfs\) 树上的祖先能够通过其他路径到达 \(v\) , 因此可能存在它的祖先也能到达该点 。
在之后 , 半支配点意味着从该点出发 , 出去一开始搜到的路径 , 当路径长度大于 2 时 , 还存在另外几条路径到达点 \(v\)。
由于我们半支配点取的是 \(dfs\) 树上最浅的点(\(dfs\)序最小) , 这样相当于把这些需要考虑的路径压缩在了一起 , 支配关系就是不变的。
正因为如此 , 所以我们的 \(DAG\) 还要保留原来的 \(dfs\) 树。以求出真正的支配点。
求解方法 , 先求出 \(dfs\) 序。
然后按照 \(dfs\) 序从大往小做。
要求一个点的半支配点 , 无非就是 \(dfs\) 树上的父亲或者是 , 走的是 \(dfs\) 序大于该点的一个路径的那个第一个还没有被考虑过的节点(就是 \(u\) 啦)。
\(dfs\)树好弄 , 那么怎么找回去的路?
我们枚举所有有指向 \(v\) 的边的那些点。
如果其 \(dfs\) 序小于 \(v\) , 那么肯定是 \(dfs\) 树上的祖先 , 直接用于更新半支配点(注意\(dfs\)序要最小) 。
如果不是那么之前一定已经考虑过了 , 容易发现半支配点是可以通过编号比自己大的点传递的 , 那么我们希望找到这条返回路径的开端 。 我们维护一个带权并查集 , 每次求完一个点后 , 把它与在 \(dfs\) 树上的祖先合并 , 这样就能找到反祖的路线 , 并且没有被考虑过的点不会合并到祖先上去 , 那么显然它就是路径的开端了 , 维护集合中 半支配点 \(dfs\)序 最小的点即可。
为什么要维护这个?图。
\(dfn[]=\{1,4,5,2,3\}\)
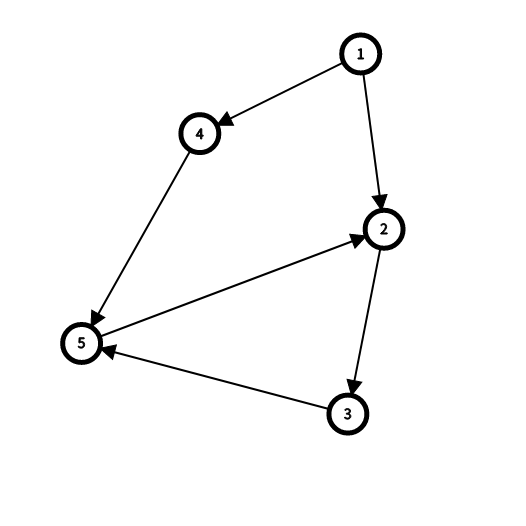
那么反着求解:
3号点的半支配点是 2 号点 , 2 号点的半支配点是 1 号点。
到了 5 号点 , 能够达到该点的有 3 号和 4 号。
此时 4 号点未被搜索过 , 这条路径端点即为 4 号点。
然后是 3 号点 , 它的反祖路径端点显然应该是 1 号节点 , 而 1 号节点当前仅为 2 号点的半支配点。而 5 号点的半支配点也是 1 号点。
必须记录过程中所有点半支配点中最小 \(dfs\) 的节点才能正确得到半支配点。
其实就是考虑了之前所有可能传递的半支配点信息 。 由于每次只是从往返回的边走一步的点上获取信息 , 保证了合法 , 再通过带权并查集来保证高效性与最优性。
然后就没有了。
另外很多题其实没有必要真的把支配树建出来 , 记个父亲然后拓扑排序就能解决问题 , 这样写会方便很多。
贴一个洛谷模板题的代码 (xzy orz)
#include<bits/stdc++.h>
using namespace std;
#define Set(a,b) memset(a,b,sizeof(a))
template<class T>inline void init(T&x){
x=0;char ch=getchar();bool t=0;
for(;ch>'9'||ch<'0';ch=getchar()) if(ch=='-') t=1;
for(;ch>='0'&&ch<='9';ch=getchar()) x=(x<<1)+(x<<3)+(ch-48);
if(t) x=-x;
}
const int N=2e5+10;
const int M=4e5+10;
typedef long long ll;
struct edge{int to,next;};
int fa[20][N],dep[N],deg[N],son[N],n,m,que[N],tail=0,dfn[N],I=0,id[N],anc[N];
vector<int> Go[N];
queue<int> Q;
inline int LCA(int u,int v){
if(dep[u]<dep[v]) swap(u,v);
for(int k=18;~k&&dep[u]>dep[v];--k) if(fa[k][u]&&dep[fa[k][u]]>=dep[v]) u=fa[k][u];
if(u==v) return u;
for(int k=18;~k;--k) if(fa[k][u]&&fa[k][v]&&fa[k][u]!=fa[k][v]) u=fa[k][u],v=fa[k][v];
return fa[0][u];
}
int size[N];
struct Graph{
edge a[M];int head[N];int cnt;
inline void clear(){cnt=0,Set(head,0);}
inline void add(int x,int y){a[++cnt]=(edge){y,head[x]};head[x]=cnt;}
inline void Topsort(){
Q.push(1);
while(!Q.empty()) {
int u=Q.front();Q.pop();
int sz=Go[u].size();
if(sz) {
int v=Go[u][0];
for(int i=1;i<sz;++i) v=LCA(v,Go[u][i]);
++son[v];dep[u]=dep[v]+1;
fa[0][u]=v;
for(int k=1;k<=18;++k) fa[k][u]=fa[k-1][fa[k-1][u]];
}
for(int v,i=head[u];i;i=a[i].next){
v=a[i].to;--deg[v];
if(!deg[v]) Q.push(v);
Go[v].push_back(u);
}
}
for(int i=1;i<=n;size[i++]=1) if(!son[i]) Q.push(i);
while(!Q.empty()) {
int u=Q.front();Q.pop();
int f=fa[0][u];if(!f) continue;
size[f]+=size[u];
--son[f];if(!son[f]) Q.push(f);
}
for(int i=1;i<=n;++i) printf("%d ",size[i]);puts("");
}
void dfs(int u){
++I;id[u]=I,dfn[I]=u;
for(int v,i=head[u];i;i=a[i].next){v=a[i].to;if(id[v]) continue;anc[v]=u;dfs(v);}
return;
}
}G,IG,DAG;
int fs[N],semi[N],Mn[N];
int find(int x){
if(fs[x]==x) return x;
int t=fs[x];fs[x]=find(fs[x]);
if(id[semi[Mn[t]]]<id[semi[Mn[x]]]) Mn[x]=Mn[t];
return fs[x];
}
inline void Solve(){
G.dfs(1);
for(int i=1;i<=n;++i) {fs[i]=Mn[i]=semi[i]=i;size[i]=0;if(anc[i]) DAG.add(anc[i],i),++deg[i];}
for(int i=I;i>1;--i) {
int u=dfn[i],res=I;
if(!u) continue;
for(int v,j=IG.head[u];j;j=IG.a[j].next){
v=IG.a[j].to;if(!id[v]) continue;
if(id[v]<id[u]) res=min(res,id[v]);
else {find(v),res=min(res,id[semi[Mn[v]]]);}
}
int v=dfn[res];
semi[u]=v,fs[u]=anc[u];DAG.add(v,u);++deg[u];
}
DAG.Topsort();
return;
}
int main(){
init(n),init(m);
int u,v;I=0;
for(int i=1;i<=m;++i) {init(u),init(v);G.add(u,v);IG.add(v,u);}
Solve();return 0;
}
5. 边分治
和点分治类似,但是我们的策略变成了每次找到一条满足其左右两侧子树大小最为接近的边,然后把树分成左右两部分递归。这样由于一条边左右只有两棵子树,那么路径信息就非常好合并与维护了。
看上去没有什么问题 , 但是注意到我们当前子树可能并不能分成两部分很平衡的结构,一个菊花图就变成了 \(O(n^2)\)
怎么办呢 , 我们采用多叉树转二叉树的方式 , 如果一个点有多余两个儿子 , 我们就像建线段树那样建一棵树来管理这些儿子 , 叶子节点就是真正的儿子。
这样由线段树的性质来看 , 点数最多也就翻个倍 , 复杂度不受影响 , 总体复杂度也就是 \(O(nlogn)\) 了。
但是这样子我们的路径信息似乎就有点和原树不一样了,发现我们两个点之间的路径可能并不会经过原来树上的 lca , 而他们现在的LCA可能是一个虚点。
只要把虚点的点权设为它原来父亲的点权 , 连向虚点的所有边的边权设为 0 就可以了。
如果要维护路径上的点的个数,那么可以发现就是经过的实边条数 + 1 , 因为 \(LCA\) 是没有被计算过的。
6.圆方树
用于处理一些与 点双&仙人掌 有关的东西。
以仙人掌上的最短路问题为例。
普通的圆方树的建法就是:
首先构出 DFS树 并找出所有的点双(在仙人掌上就是环) , 然后为每一个点双新建一个节点(方点)并重新构一棵树(旧点称为 圆点)。
把环上dfs序最大的点(环首)作为新点的父亲边权为 0 , 然后新点其他环上的点连边权值为他们各自到环首的最短路长度。
原图中的桥边保持不变。
这样我们得到了一棵新的树,有一些显然的性质
1.方点之间不相邻,因为根本就没有把两个方点之间连边的操作。
2.每一个点最多成为一次非环首的点,换言之一个点可以通过其所在的非环首的环来识别(它的父亲方点)。
那么这样怎么处理最短路问题呢。
我们最短路肯定就是经过了很多的桥边和环边,考虑我们构圆方树时的策略,显然桥边是不受影响的,然后当我们走到环时,要继续往上走过这个环的话,显然会走最短路到环首,这样和我们在圆方树上的距离是一样的,所以我们用倍增什么的求个 \(LCA\) 就可以用树上的方法求距离了。
当然仙人掌还是有一点区别的,因为我们的 \(LCA\) 可能是一个方点 , 这意味着什么呢? 说明我们假设是 u ,v 两个点往上走的话会走到同一个环里,在环中的某个点相遇 , 而我们的距离是到环首的,所以就不能这么算。这个时候需要需要在 LCA 之前停下来 , 然后把两点在父亲方点所代表的环上的最短路找出来加到答案里面就好了。
仙人掌图最短路代码:
#include<bits/stdc++.h>
using namespace std;
#define Set(a,b) memset(a,b,sizeof(a))
template<class T>inline void init(T&x){
x=0;char ch=getchar();bool t=0;
for(;ch>'9'||ch<'0';ch=getchar()) if(ch=='-') t=1;
for(;ch>='0'&&ch<='9';ch=getchar()) x=(x<<1)+(x<<3)+(ch-48);
if(t) x=-x;return;
}
int n,m;
typedef long long ll;
const int N=1e4+10;
const int M=2e6+10;
struct edge{int to,next,w;}a[M<<1];
int head[N],cnt=0;
inline void add(int x,int y,int z){a[cnt]=(edge){y,head[x],z};head[x]=cnt++;}
int dfn[N],I=0,Ret[N],low[N];
typedef pair<int,ll> PA;
typedef vector<PA> BCC;
BCC Cir[N];int bcc=0;int pos[N];int Tn;
namespace Tree{
const int N=3e4+10;
ll dis[16][N];int fa[16][N],dep[N],son[N];
inline void add(int x,int y,int z){fa[0][y]=x;++son[x];dis[0][y]=z;}
queue<int> Q;
int que[N],tail=0;
inline void Prework(){
for(int k=1;k<=15;++k) for(int i=1;i<=n;++i) fa[k][i]=fa[k-1][fa[k-1][i]],dis[k][i]=dis[k-1][i]+dis[k-1][fa[k-1][i]];
for(int i=1;i<=n;++i) if(!son[i]) Q.push(i);
while(!Q.empty()) {
int u=Q.front();Q.pop();
que[++tail]=u;int f=fa[0][u];
if(f) {--son[f];if(!son[f]) Q.push(f);}
}
for(int i=tail;i;--i) {int u=que[i];dep[u]=dep[fa[0][u]]+1;}
}
inline ll Query(int u,int v){
if(dep[u]<dep[v]) swap(u,v);ll ans=0;
for(int k=15;~k&&dep[u]!=dep[v];--k) if(fa[k][u]&&dep[fa[k][u]]>=dep[v]) ans+=dis[k][u],u=fa[k][u];
if(u==v) return ans;
for(int k=15;~k;--k) if(fa[k][u]&&fa[k][v]&&fa[k][u]!=fa[k][v]) ans+=dis[k][u]+dis[k][v],u=fa[k][u],v=fa[k][v];
int lca=fa[0][v];
if(lca>Tn) {
int pu=pos[u],pv=pos[v],id=lca-Tn;ll LEN=Cir[id][Cir[id].size()-1].second;
if(pu>pv) swap(pu,pv);
ll D=Cir[id][pv].second-Cir[id][pu].second;
ans+=min(D,LEN-D);
}
else ans+=dis[0][u]+dis[0][v];
return ans;
}
}
inline void Build(int v,int u,int w){
++bcc;++n;ll Sum=w;int cur=-1;
while(v!=u) {
pos[v]=++cur;Cir[bcc].push_back(PA(v,Sum));
Sum+=a[Ret[v]].w;v=a[Ret[v]^1].to;
}
Cir[bcc].push_back(PA(u,Sum));Tree::add(u,n,0);
for(int i=0;i<=cur;++i){
int v=Cir[bcc][i].first;ll dis=Cir[bcc][i].second;
Tree::add(n,v,min(dis,Sum-dis));
}return;
}
void Dfs(int u){
low[u]=dfn[u]=++I;
for(int v,i=head[u];~i;i=a[i].next){
v=a[i].to;if(Ret[u]==(i^1)) continue;
if(!dfn[v]) {
Ret[v]=i,Dfs(v),low[u]=min(low[u],low[v]);
if(low[v]>dfn[u]) Tree::add(u,v,a[i].w);
}
else if(dfn[v]>dfn[u]) Build(v,u,a[i].w);else low[u]=min(low[u],dfn[v]);
}
return;
}
int Q;
int main()
{
Set(head,-1);init(n),init(m);init(Q);
int u,v,w;Tn=n;
for(int i=1;i<=m;++i) {init(u),init(v),init(w);add(u,v,w),add(v,u,w);}
Ret[1]=-1;Dfs(1);Tree::Prework();
for(int i=1;i<=Q;++i){init(u),init(v);printf("%lld\n",Tree::Query(u,v));}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号