Python类基础筑基(1)——面对对象
Python类基础筑基(1)————面对对象

![[lab.magiconch.com][福音戰士標題生成器]-1701391443259](https://s2.loli.net/2023/12/01/WpEDI6ayQt5zbM9.jpg)
本文以Python3主要为主,穿插2.7的信息,如无特别说明默认为Python3
1.Python的命名空间与作用域
1.1命名空间(namespace)
namespace (命名空间)是从名称到对象的映射。现在,大多数命名空间都使用 Python 字典实现,但除非涉及到性能优化,我们一般不会关注这方面的事情,而且将来也可能会改变这种方式。命名空间的例子有:内置名称集合(包括 abs() 函数以及内置异常的名称等);一个模块的全局命名空间;一个函数调用中的局部命名空间。对象的属性集合也是命名空间的一种形式。
命名空间是在不同时刻创建的,且拥有不同的生命周期。下边列出来四种常见的命名空间的简单介绍:
- 内置名称的命名空间是在 Python 解释器启动时创建的,永远不会被删除。内置名称实际上也在模块里,即
builtins。 - 模块的全局命名空间在读取模块定义时创建;通常,模块的命名空间也会持续到解释器退出。
- 从脚本文件读取或交互式读取的,由解释器顶层调用执行的语句是
__main__模块调用的一部分,也拥有自己的全局命名空间。 - 函数的局部命名空间在函数被调用时被创建,并在函数返回或抛出未在函数内被处理的异常时,被删除。(实际上,用“遗忘”来描述实际发生的情况会更好一些。)当然,每次递归调用都有自己的局部命名空间。
上述内容代表了常见的四种命名空间:内置命名空间、全局命名空间、main模块命名空间、函数的命名空间。实际上main也应该算作一种全局命名空间,只是他相对特殊这里单列出来。
“从脚本文件读取或交互式读取的,由解释器顶层调用执行的语句是 __main__ 模块调用的一部分,也拥有自己的全局命名空间” 这句话该如何理解呢?什么是main模块自己的全局命名空间?
这里可以参考一下python官方文档的解释:
在 Python 中,特殊名称 __main__ 用于两个重要的构造:
- 程序的顶层环境的名称,可以使用
__name__ == '__main__'表达式进行检查; - Python 包中的
__main__.py文件。
这两种机制都与 Python 模块有关,涉及用户如何与模块互动以及模块之间如何互动。下面详细解释了它们的作用。如果你是 Python 模块的新手,请参阅教程部分 Modules 以进行介绍。
__main__ 是顶层代码运行的环境名称。所谓的 "顶层代码" 是指开始运行的第一个用户指定的 Python 模块。它之所以被称为 "顶层",是因为它导入了程序所需的所有其他模块。有时 "顶层代码" 也被称为应用程序的 入口点。
顶层代码环境可以是:
-
交互式提示符的作用域:
pythonCopy code>>> __name__ '__main__' -
作为文件参数传递给 Python 解释器的 Python 模块:
pythonCopy code$ python helloworld.py Hello, world! -
使用
-m参数传递给 Python 解释器的 Python 模块或包:pythonCopy code$ python -m tarfile usage: tarfile.py [-h] [-v] (...) -
从标准输入中读取的 Python 代码:
pythonCopy code$ echo "import this" | python The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. ... -
使用
-c参数传递给 Python 解释器的 Python 代码:pythonCopy code$ python -c "import this" The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. ...
在每一种情况下,顶层模块的 __name__ 被设置为 '__main__'。
因此,一个模块可以通过检查自己的 __name__ 来发现它是否在顶层环境中运行,这允许一种常见的习惯用法,用于在模块未从导入语句初始化时有条件地执行代码:
pythonCopy codeif __name__ == '__main__':
# 当模块未从导入语句初始化时执行。
...
if __name__ == '__main__':
# Execute when the module is not initialized from an import statement.
...
这意味着如果脚本文件被直接运行(而不是被导入为模块),那么其中的代码将作为主程序执行,即被解释器顶层调用执行。这是Python中的一种约定,用于标识脚本的主要入口点。
1.2作用域(scope)
一个命名空间的 作用域 是 Python 代码中的一段文本区域(textual region),从这个区域可直接访问该命名空间。“可直接访问”的意思是,该文本区域内的名称在被非限定引用时,查找名称的范围,是包括该命名空间在内的。
作用域是按字面文本(textual region)确定的解释:模块内定义的函数的全局作用域就是该模块的命名空间,无论该函数从什么地方或以什么别名被调用。另一方面,实际的名称搜索是在运行时动态完成的。但是,Python 正在朝着“编译时静态名称解析”的方向发展,因此不要过于依赖动态名称解析!(局部变量已经是被静态确定了。)
作用域虽然是被静态确定的,但会被动态使用。执行期间的任何时刻,都会有 3 或 4 个“命名空间可直接访问”的嵌套作用域:
- 最内层作用域,包含局部名称,并首先在其中进行搜索
- 那些外层闭包函数的作用域,包含“非局部、非全局”的名称,从最靠内层的那个作用域开始,逐层向外搜索。
- 倒数第二层作用域,包含当前模块的全局名称
- 最外层(最后搜索)的作用域,是内置名称的命名空间
如果一个名称被声明为全局,则所有引用和赋值都将直接指向“倒数第二层作用域”,即包含模块的全局名称的作用域。
1.3关于作用域和命名空间的混淆点
命名空间:名称(name)及其所引用对象(object)的集合。python使用dictionary来表示命名空间,key对应名称(name),value为名称所对应的对象(object)。
实际上命名空间是一种映射关系的具体实现,在python中以dictionary来实现,其存储了具体的映射关系。
而作用域是在命名空间的基础上所遵循的规则信息。其规定了我们的程序将查看哪些命名空间(中的名称)及以顺序。
1.1.4作用域的具体例子(global & nonlocal)
如果程序执行时去使用一个变量 hello ,那么 Python, 查找变量顺序为:
局部的命名空间 -> 全局命名空间 -> 内置命名空间
如果按照这个顺序找不到相应的变量,它将放弃查找并抛出一个 NameError 异常:
NameError: name 'hello' is not defined。
Python 有一个特殊规定。如果不存在生效的 global 或 nonlocal 语句,则对名称的赋值总是会进入最内层作用域。赋值不会复制数据,只是将名称绑定到对象。删除也是如此:语句 del x 从局部作用域引用的命名空间中移除对 x 的绑定。所有引入新名称的操作都是使用局部作用域:尤其是 import 语句和函数定义会在局部作用域中绑定模块或函数名称。
global 语句用于表明特定变量在全局作用域里,并应在全局作用域中重新绑定;nonlocal 语句表明特定变量在外层作用域中,并应在外层作用域中重新绑定。
摘两段关于global和nonlocal的定义:
global 语句是作用于整个当前代码块的声明。 它意味着所列出的标识符将被解读为全局变量。 要给全局变量赋值不可能不用到 global 关键字,不过自由变量也可以指向全局变量而不必声明为全局变量。
nonlocal 语句会使得所列出的名称指向之前在最近的包含作用域中绑定的除全局变量以外的变量。与 global 语句中列出的名称不同,nonlocal 语句中列出的名称必须指向之前存在于包含作用域之中的绑定(在这个应当用来创建新绑定的作用域不能被无歧义地确定)。
要重新绑定在最内层作用域以外的变量,可以使用 nonlocal 语句;如果未使用 nonlocal 声明,这些变量将为只读(尝试写入这样的变量将在最内层作用域中创建一个 新的 局部变量,而使得同名的外部变量保持不变)。
nonlocal 语句中列出的名称不得与之前存在于局部作用域中的绑定相冲突。
这句话看起来很难理解,不过没关系,下面的例子很好的解释了这个问题:
def scope_test():
def do_nonlocal():
spam = "do_nonlocal spam"
nonlocal spam
spam = "nonlocal spam"
spam = "test spam"
do_nonlocal()
print("After nonlocal assignment:", spam)
scope_test()
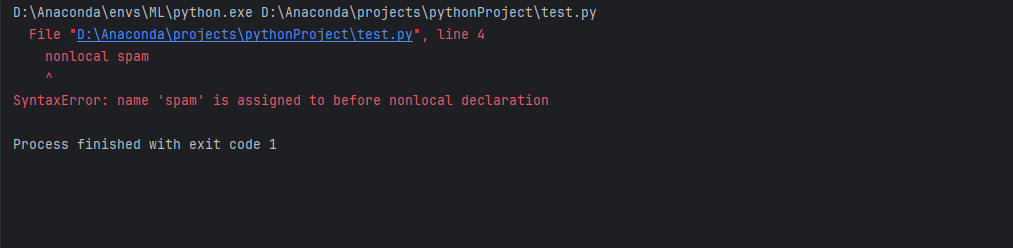
可以看到nonlocal不能绑定已经绑定过的局部变量,这里使用‘绑定’这个词是有原因的,可以看一下下边的内容。
扩展:名称和对象
对于Python来说所有内容都是对象,对象之间相互独立,多个名称(甚至是多个作用域内的多个名称)可以绑定到同一对象。这在其他语言中通常被称为别名。Python 初学者通常不容易理解这个概念,处理数字、字符串、元组等不可变基本类型时,可以不必理会。
但是,对于涉及可变对象(如列表、字典,以及大多数其他类型)的 Python 代码的语义,别名可能会产生意料之外的效果。这样做,通常是为了让程序受益,因为别名在某些方面就像指针。例如,传递对象的代价很小,因为实现只传递一个指针。
我们通过以下的例子来综合解释一下如何使用global & nonlocal:
def scope_test():
def do_local():
spam = "local spam"
def do_nonlocal():
nonlocal spam
spam = "nonlocal spam"
def do_global():
global spam
spam = "global spam"
spam = "test spam"
do_local()
print("After local assignment:", spam)
do_nonlocal()
print("After nonlocal assignment:", spam)
do_global()
print("After global assignment:", spam)
scope_test()
print("In global scope:", spam)
示例代码的输出是:
After local assignment: test spam
After nonlocal assignment: nonlocal spam
After global assignment: nonlocal spam
In global scope: global spam
在调用scope_test之后,会先创建一个在scope_test函数作用域之内的spam变量其作用域是在scope_test函数的局部变量里面,这时候调用do_local()函数其将do_local()函数小局部作用域中的spam通过nonlocal关键字绑定到了上一个局部作用域中,并进行了赋值,这时上一个局部作用域中的spam被赋值修改了绑定关系。所以输出结果从test spam变化成为了nonlocal spam。
需要注意的是do_global()函数将在全局一个不存在的spam进行了绑定,相当于在局部变量中创建了全局变量,这是比较特殊的。
2.面对对象与类
2.1Python的面对对象
最简单的类定义形式如下:
class ClassName:
"""class help doc"""
<statement-1>
.
.
.
<statement-N>
当进入类定义时,将创建一个新的命名空间,并将其用作局部作用域,因此,所有对局部变量的赋值都是在这个新命名空间之内。
类的帮助信息可以通过ClassName.__ doc __查看。
特别的,函数定义会绑定到这里的新函数名称。也就是会将里面的函数定义绑定到对应的函数名称,完成函数的创建。
当 (从结尾处) 正常离开类定义时,将创建一个 类对象。 这基本上是一个围绕类定义所创建的命名空间的包装器;至于什么是包装器,包装器的作用是什么,这个以后再讨论。
原始 (在进入类定义之前有效的) 作用域将重新生效,类对象将在这里与类定义头所给出的类名称进行绑定 (在这个示例中为 ClassName)。
这里需要关注的是类其实也是一个对象,类对象也是对象的一种。在创建的结束将类名和类对象进行绑定。
2.2类对象
类对象支持两种操作:属性引用和实例化。
2.2.1属性引用
使用 Python 中所有属性引用所使用的标准语法: obj.name。 有效的属性名称是类对象被创建时存在于类命名空间中的所有名称。 因此,如果类定义是这样的:
class MyClass:
"""A simple example class"""
i = 12345
def f(self):
return 'hello world'
那么 MyClass.i 和 MyClass.f 就是有效的属性引用,将分别返回一个整数和一个函数对象。 类属性也可以被赋值,因此可以通过赋值来更改 MyClass.i 的值。 有趣的是这样的内容在java系语言中被定为静态属性,其生命周期不会随着类的实例化所变化。
__doc__ 也是一个有效的属性,将返回所属类的文档字符串: "A simple example class"。
2.2.2实例化
类对象的实例化功能实际上就是其他语言的创建类的实例对象,需要注意的是实例对象和类对象是两个不同的概念,后面会详细介绍二者的区别。
类的 实例化 使用函数表示法。 可以把类对象视为是返回该类的一个新实例的不带参数的函数。常见的形式如下:
对象变量 = 类名()
x = MyClass()
创建类的新 实例 并将此对象分配给局部变量 x。
上述实例化操作 (“调用”类对象) 会创建一个空对象。 许多类都希望创建的对象实例是根据特定初始状态定制的。
因此一个类可能会定义名为 __init__() 的特殊方法,就像这样:
def __init__(self):
self.data = []
当一个类定义了 __init__()方法时,类的实例化会自动为新创建的类实例发起调用 __init__()。 因此在这个例子中,可以通过以下语句获得一个已初始化的新实例:
x = MyClass()
Example:
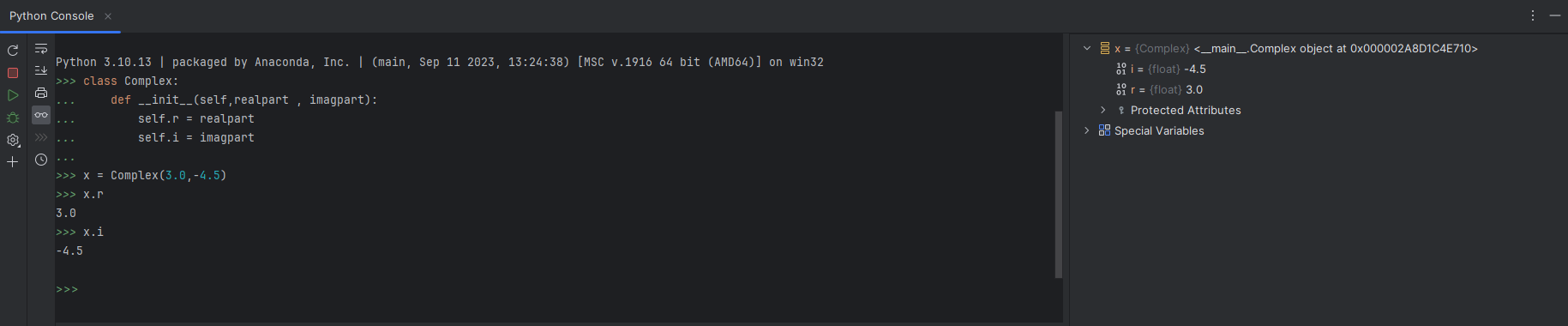
2.3实例对象
实例对象所能理解的唯一操作是属性引用。 有两种有效的属性名称:数据属性和方法。
2.3.1数据属性
数据属性就是java中的成员属性,需要注意的是pyhton是一门动态的语言, 数据属性不需要声明;就像局部变量一样,它们将在首次被赋值时产生。且在操作过程中可进行删除操作,删除一个实例对象的数据属性。这是其他静态语言所难以企及的。
下面举个例子,在上文的基础上进行修改:
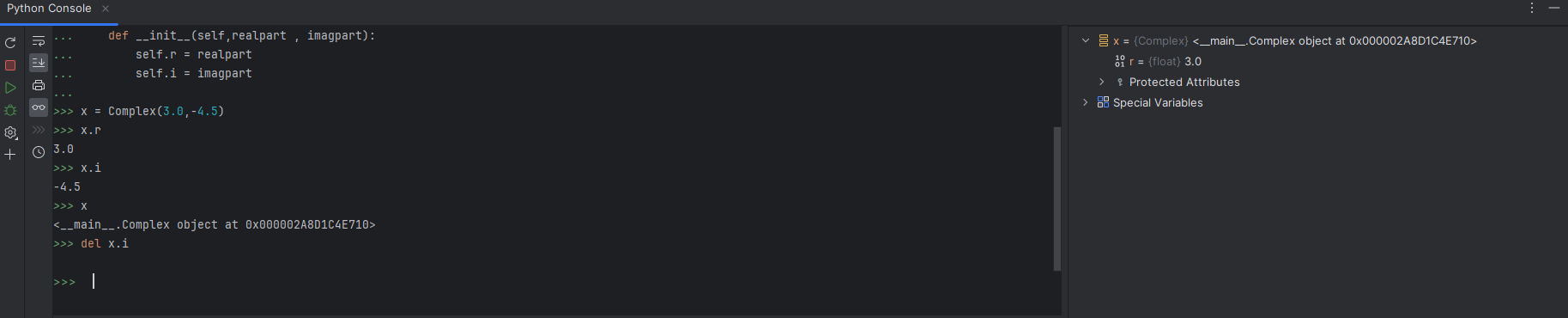
只能说python过于自由了。哈哈哈。
2.3.2方法
另一类实例属性引用称为 方法。 方法是从属于对象的函数。 (在 Python 中,方法这个术语并不是类实例所特有的:其他对象也可以有方法。 例如,列表对象具有 append, insert, remove, sort 等方法。 然而,在以下讨论中,我们使用方法一词将专指类实例对象的方法,除非另外显式地说明)
实例对象的有效方法名称依赖于其所属的类。 根据定义,一个类中所有是函数对象的属性都是其实例的相应方法。
因此在我们的示例中,x.f 是有效的方法引用,因为 MyClass.f 是一个函数,而 x.i 不是方法,因为 MyClass.i 不是函数。 但是 x.f 与 MyClass.f 并不是一回事 --- 它是一个 方法对象,不是函数对象。
这里让人难以理解的就是什么。为什么方法也是对象,对于函数对象还是比较好理解的,就像变量对象一样,是基础的对象类型,那么什么是方法对象呢?
2.4方法对象
这里在上文的对象中添加一个f()方法,代码如下:
class Complex:
def __init__(self,realpart , imagpart):
self.r = realpart
self.i = imagpart
def f(self):
return 'hello world'
添加完成以后,Complex对象就有了方法对象,可以通过实例对象来进行引用,如下图所示,它不仅可以在实例对象中进行引用同时也可以将其存储起来,存储对象在xf中,xf就相当于方法的别名,可以看到二者指向的对象是相同。
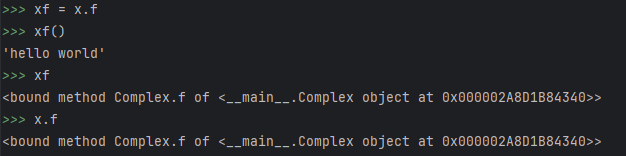
2.5方法对象&函数对象的区别、类对象&实例对象的区别
2.5.1方法对象&函数对象的区别
在官方的文档中有这样一句话:
Each value is an object, and therefore has a class (also called its type). It is stored as object.__class__.
对于方法对象和函数对象来说而这最大的区别就在于使用方法上,我们可以注意到:
f() 的函数定义指定了一个参数,但上面调用 x.f() 时却没有带参数。 这个参数发生了什么事? 当一个需要参数的函数在不附带任何参数的情况下被调用时 Python 肯定会引发异常 --- 即使参数实际上没有被使用...
实际上,你可能已经猜到了答案:方法的特殊之处就在于实例对象会作为函数的第一个参数被传入。 在我们的示例中,调用 x.f() 其实就相当于 MyClass.f(x)。
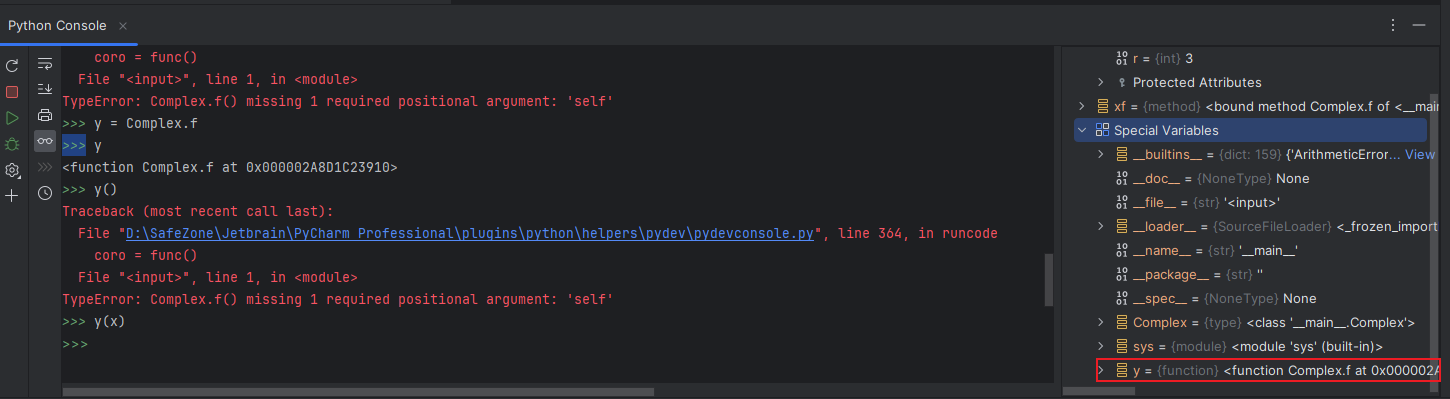
我们可以构建一个例子关于f的直接引用和实例对象的方法引用,如下代码所展示的
>>>y = Complex.f
>>>y
<function Complex.f at 0x000002A8D1C23910>
可以看到直接使用类对象的f引用结果变成了一个函数对象。图像右侧可以看到
那如果我们打印一个上文中x.f呢?

这就是二者的核心区别,如果我们直接调用y,他就会因为缺少参数而无法运行:

当然到这里你会更迷惑了,那么一个实例的方法的调用过程是什么呢?
当对实例对象进行属性引用时,如果该属性在实例中无法找到,将搜索实例所属的类。如果被引用的属性名称表示一个有效的类属性中的函数对象,会打包两者(实例对象和查找到的函数对象)的指针到一个抽象对象,这个抽象对象就是方法对象。当用参数列表调用方法对象时,将基于实例对象和参数列表构建一个新的参数列表,并用这个新参数列表调用相应的函数对象。
也就是说你本质上调用的是新参数列表的函数对象,当直接调用的时候新参数列表中没有实例对象(self实际上代之的是实例对象自己)而无法运行。
这也是类对象&实例对象的区别,实际上二者底层实现不一样,功能不同。
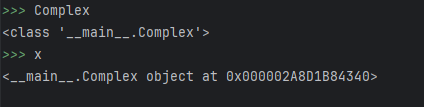
可以看到Complex自己代表了一个命名空间,和x并不相同。
任何一个作为类属性的函数都为该类的实例定义了一个相应方法。 注意的是这里是任何,也就是说任何符合带有self参数的引用的都只能作为方法来使用,这句话下面会解释。函数定义的文本并非必须包含于类定义之内:将一个函数对象赋值给一个局部变量也是可以的。 例如,下面的代码实现了一个函数并将其添加到了类中:
# Function defined outside the class
def f1(self, x, y):
return min(x, x+y)
class C:
f = f1
def g(self):
return 'hello world'
h = g
现在 f、g 和 h 都 C 类的指向函数对象的属性,因此它们都是 C 实例的方法 --- 其中 h 与 g 完全等价。 但请注意这种做法通常只会使程序的阅读者感到迷惑,这里只是展示其完全相同的结果。
也就是说在类空间中定义的函数对象,被转化成为了方法。实例化后以方法对象的形式调用。
那么这些函数对象能被调用吗?如何获取呢?
实例方法对象也具有属性: m.__self__ 就是带有 m() 方法的实例对象,而 m.__func__ 则是该方法所对应的函数对象。
举个例子可能会更好理解,在上文代码的基础上做一些简单的修改:
class SonClass(FatherClass):
def __init__(self):
super(SonClass, self).__init__()
print('This is son init')
def method(self, son_value):
# super(SonClass, self).method()
print('son_value is ' + son_value)
print("This is a son method")
print(self)
# print(self.y)
son = SonClass()
m = son.method
print(m.__self__)
func = m.__func__
print(func('self', son_value='func_test'))
注意的是,这里修改了method方法,取消了内部所有对self的引用,至于为什么接下来会说,我们在下边调用了m = son.method来获取实例对象的方法对象,简称实例方法对象,输出两个属性,并通过__func__来获取其函数对象,最后通过func('self', son_value='func_test')来实现调用函数对象。
输出结果如下:
This is son init
<__main__.SonClass object at 0x000001526B98FA00>
son_value is func_test
This is a son method
self
这里再解释一下为什么要取消self的调用,很简单函数对象并没有继承关系,也不会获取self对象到底是什么,是否是实例对象,所以这里使用字符串来作为参数,输出结果就是self字符。
若果包含self参数调用,会是什么样呢?报错如下:
Traceback (most recent call last):
File "D:\SafeZone\PythonProjects\ICS_4\main.py", line 52, in <module>
print(func('self', son_value='func_test'))
File "D:\SafeZone\PythonProjects\ICS_4\main.py", line 33, in method
super(SonClass, self).method()
TypeError: super(type, obj): obj must be an instance or subtype of type
2.5.2类对象&实例对象的区别
一般来说,实例变量用于每个实例的唯一数据,而类变量用于类的所有实例共享的属性和方法:
class Dog:
kind = 'canine' # class variable shared by all instances
def __init__(self, name):
self.name = name # instance variable unique to each instance
>>> d = Dog('Fido')
>>> e = Dog('Buddy')
>>> d.kind # shared by all dogs
'canine'
>>> e.kind # shared by all dogs
'canine'
>>> d.name # unique to d
'Fido'
>>> e.name # unique to e
'Buddy'
正如 名称和对象 中已讨论过的,共享数据可能在涉及 mutable 对象例如列表和字典的时候导致令人惊讶的结果。 例如以下代码中的 tricks 列表不应该被用作类变量,因为所有的 Dog 实例将只共享一个单独的列表,也就是说所有可变变量不应该放到类中。正如下下面的例子中:
class Dog:
tricks = [] # mistaken use of a class variable
def __init__(self, name):
self.name = name
def add_trick(self, trick):
self.tricks.append(trick)
>>> d = Dog('Fido')
>>> e = Dog('Buddy')
>>> d.add_trick('roll over')
>>> e.add_trick('play dead')
>>> d.tricks # unexpectedly shared by all dogs
['roll over', 'play dead']
这里回到本小节开头的那句话:
每个值都是一个对象,因此具有 类 (也称为 类型),并存储为 object.__class__ 。
我们上文代码中的打印所有的对象的Class:
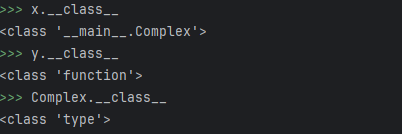
有趣的是Class的类型是type,这就非常有趣了,至于为什么可以参考:
在 Python 中,为什么 type 类对象自身的类型是 type? - 知乎 (zhihu.com)
3.继承
终于讨论到最有趣的地方的了,Python是我接触的第一个动态语言和多继承语言,当然,如果不支持继承,语言特性就不值得称为“类”。单继承的语言类似Java系,继承很好理解,Python的多继承将会是我们讨论的重点,我们不妨先从单继承的视角来看它的继承。
子(派生)类的语法定义如下:
class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-N>
当构造类对象时,基类会被记住。 此信息将被用来解析属性引用:如果请求的属性在类中找不到,搜索将转往基类中进行查找。 如果基类本身也派生自其他某个类,则此规则将被递归地应用。这只是针对单继承的基本查找规则,多继承相对更加复杂一点,后面会着重讨论。
3.1派生类的实例化
派生类的实例化没有任何特殊之处: DerivedClassName() 会创建该类的一个新实例。 方法引用将按以下方式解析:搜索相应的类属性,如有必要将按基类继承链逐步向下查找,如果产生了一个函数对象则方法引用就生效。
上边的是官方的文档,实际上什么也没说,和狗屁一样,我们不如实际一点,通过几个例子来详细说明,派生类实例化会涉及到什么,应用的时候应该注意什么。
3.1.1__init__会怎么调用?
class FatherClass(object):
def __init__(self):
print('This is father init')
def method(self):
print("This is a father method")
class SonClass(FatherClass):
# def __init__(self):
# #super(SonClass,self).__init__()
# print('This is son init')
def method(self):
print("This is a son method")
son = SonClass()
print(son.__class__)
son.method()
代码的输出:
This is father init
<class '__main__.SonClass'>
This is a son method
可以看到子类初始化的时候没有显式指定__init__,就会默认调用父类的__init__。
如果我们显式的指定__init__会有什么后果?我们将注释去掉,结果如下:
注意的是这里的super行仍有注释存在。
This is son init
<class '__main__.SonClass'>
This is a son method
这里就要引出super()方法了,这里先不说名为什么要用super(),以及super()是如何实现的,我们就先姑且把它当作父类实例的代指函数,通过他就可以调用父类的对象。
我们把对应的super注释去掉,看看结果会如何:
This is father init
This is son init
<class '__main__.SonClass'>
This is a son method
可以看到父类的__init__方法也被调用了。
上述的内容可以一句话总结一下:
子类没有显式指定的时候,会自动调用父类的init,子类显示指定的时候也要显式调用父类的init。
需要补充的是,在没有显式指定的时候,父类的实例变量并无法访问,之恩那个访问到对应的父类的类变量。修改上文的代码后,来验证这个内容:
class FatherClass(object):
y = 'father class variable'
def __init__(self):
self.x = 'father variable'
print('This is father init')
def method(self):
print("This is a father method")
class SonClass(FatherClass):
def __init__(self):
#super(SonClass, self).__init__()
print('This is son init')
def method(self):
print("This is a son method")
son = SonClass()
print(son.__class__)
print(son.y)
print(son.x)
son.method()
结果如下:
This is son init
<class '__main__.SonClass'>
father class variable
Traceback (most recent call last):
File "D:\SafeZone\PythonProjects\ICS_4\main.py", line 25, in <module>
print(son.x)
AttributeError: 'SonClass' object has no attribute 'x'
3.2派生类方法的扩展与重载
重载派生类的方法很简单,只需要直接修改参数内容即可:
如下代码所示,重载了对应的method方法:
class FatherClass(object):
y = 'father class variable'
def __init__(self):
self.x = 'father variable'
print('This is father init')
def method(self):
print("This is a father method")
class SonClass(FatherClass):
def __init__(self):
super(SonClass, self).__init__()
print('This is son init')
def method(self, son_value):
print('son_value is ' + son_value)
print("This is a son method")
son = SonClass()
print(son.__class__)
print(son.y)
print(son.x)
son.method('mother fucker')
输出结果如下:
This is father init
This is son init
<class '__main__.SonClass'>
father class variable
father variable
son_value is mother fucker
This is a son method
扩展就更加简单,只需要通过super来调用父类,即可接着父类方法来实现续写:
def method(self, son_value):
super(SonClass, self).method()
print('son_value is ' + son_value)
print("This is a son method")
输出结果如下:
father class variable
father variable
This is a father method
son_value is mother fucker
This is a son method
3.3 super()函数详解
上文中所有super的写法我都依照python2的写法来实现的,实际上python3对于super有了更简便的写法,如下所示:
super(SonClass, self).method()#python 2
super().method()#python 3
这两个关键的参数被省略了,这对新手来说是一个很方便的事情,但是参数的省略带来信息的丢失,总是让人很迷茫,super到底的作用是什么?同时有很多python3的代码也采用了python2的写法(python3 对这个是兼容的)
那么不禁让人提问 :super是如何工作的?两个参数的作用是什么呢?
super的定义如下:
class super(type, object_or_type=None)
返回一个代理对象,它会将方法调用委托给 type 的父类或兄弟类。 这对于访问已在类中被重载的继承方法很有用。
type这是个只是一个参数名称,如果你要问和type有什么关系,不要忘记了所有class的类型是type,也就是说这里要填一个类对象进去。
对于后一个参数的理解就更加简单了,填入一个实例对象或者类对象即可。
那对这两个参数填入的内容已经有大概的了解,那么这两个参数到底有什么用?
这两参数被用来实例化super类,对没错。super是一个类对象:
>>>super.__class__
<class 'type'>
>>>class A:pass
>>>super(A).__class__
<class 'super'>
返回一个代理对象,它会将方法调用委托给 type 的父类或兄弟类。实例化之后将会返回代理对象,代理的就是他的祖先类的对象(可按照顺序调用各种祖先类对象,具体按照什么顺序稍后会解释)。
object_or_type 确定要用于搜索的 method resolution order。 搜索会从 type 之后的类开始。
MRO 指的是 type(object_or_type)的 MRO, MRO 中的那个类就是 type。注意这里使用粗体的指的是参数,前边的type为python内置函数。
也就是说,object_or_type用于确定在哪一颗祖先树上进行搜索,因为Python是多继承的(这里还没有讲多继承是如何实现的,不过没关系,可以从真实世界的族谱上理解一下),所以其继承关系会构建出来一颗祖先树。
在早期python的经典类结构,也就是python2中MRO遵循的是从左到右,深度优先,但是在2.2版本后多继承遵循了C3算法,详细可参考:The Python 2.3 Method Resolution Order | Python.org里面详细论述了python是如何实现MRO,考虑到文章的长度,在以后会单独写一篇关于继承顺序的文章,这里可以先看一下参考文献。
举一个简单的例子:
For example, if __mro__ of object_or_type is D -> B -> C -> A -> object and the value of type is B, then super() searches C -> A -> object。
想要了解某一个类的MRO情况可以通过__mro__属性来获取:
print(SonClass.__mro__)
输出:
(<class '__main__.SonClass'>, <class '__main__.FatherClass'>, <class '__main__.UncleClass'>, <class 'object'>)
这里再介绍一下两个内置函数,这两个内置函数用来测试是否满足的super的参数条件。
- 使用
isinstance()来检查一个实例的类型:isinstance(obj, int)仅会在obj.__class__为int或某个派生自int的类时为True。简单来说作用是检测实例是否是某一个类子类的实例对象。 - 使用
issubclass()来检查类的继承关系:issubclass(bool, int)为True,因为bool是int的子类。 但是,issubclass(float, int)为False,因为float不是int的子类。 检测class对象是否为某一个类对象的子类。
实际上super的参数还有另一种情况,当object_or_type 输入类型也是type的时候,就需要满足issubclass为true的条件,这时候super的调用就成了这样:
super(type1, type2)
MRO 指的是 type2 的 MRO, MRO 中的那个类就是 type1 ,同时 issubclass(type2, type1) == True 。
那么, super() 实际上做了啥呢?简单来说就是:提供一个 MRO 以及一个 MRO 中的类 C , super() 将返回一个从 MRO 中 C 之后的类中查找方法的对象。
那是不是意味着我们也可以这样写,写了之后会有什么效果呢?
这样调用会有什么结果呢?我们再举一个例子,在上文的代码中扩充添加一个TestClass类,他是最底层的类,是所有类的子类:
class FatherClass(object):
y = 'father class variable'
def __init__(self):
self.x = 'father variable'
print('This is father init')
def method(self):
print("This is a father method")
def function():
print('This is a father function')
class SonClass(FatherClass):
def __init__(self):
super(SonClass, self).__init__()
print('This is son init')
def method(self, son_value):
super(SonClass, self).method()
print('son_value is ' + son_value)
print("This is a son method")
class TestClass(SonClass):
def __init__(self):
super().__init__()
def metod(self):
pass
然后进行调用:
son = SonClass()
print(super(SonClass, TestClass).y)
输出结果:
This is father init
This is son init
father class variable
可以看到他直接找到了父类作为调用对象,并输出了对应的y属性,需要注意的是这里无法针对方法对象来实现,原因很简单,并没有self参数作为载体,来进行方法的调用。记住上文说的:任何一个作为类属性的函数都为该类的实例定义了一个相应方法。不能把它作为函数对象来调用。
3.4私有变量
那种仅限从一个对象内部访问的“私有”实例变量在 Python 中并不存在。这也算是设计特点, 但是,大多数 Python 代码都遵循这样一个约定:带有一个下划线的名称 (例如 _spam) 应该被当作是 API 的非公有部分 (无论它是函数、方法或是数据成员)。 这应当被视为一个实现细节,可能不经通知即加以改变。
但是这样并不是很有效的操作,例如避免名称与子类所定义的名称相冲突,即使去使用 _spam的形式也是不合理的,子类仍能继承到,因此Python存在一个机制,叫做名称改写。
3.4.1名称改写
形式为 __spam 的标识符,至少带有两个前缀下划线,至多一个后缀下划线)的文本将被替换为 _classname__spam,其中 classname 为去除了前缀下划线的当前类名称。
这种改写不考虑标识符的句法位置,只要它出现在类定义内部就会进行。
举个例子:如何使用私有变量进行解耦合
class FatherClass(object):
__y = 'father class variable'
def __init__(self):
self.x = 'father variable'
print('This is father init')
self.method()
def method(self):
print("This is a father method")
可以看到 父类这里的init和method进行了耦合,init依赖于 method。产生了耦合
子类继承的时候无法重写method方法,如果重写了就会报错:
子类定义如下:
class SonClass(FatherClass):
def __init__(self):
super(SonClass, self).__init__()
print('This is son init')
def method(self, son_value):
super(SonClass, self).method()
print('son_value is ' + son_value)
print("This is a son method")
报错信息如下:
Traceback (most recent call last):
File "D:\SafeZone\PythonProjects\ICS_4\main.py", line 33, in <module>
son = SonClass()
File "D:\SafeZone\PythonProjects\ICS_4\main.py", line 16, in __init__
super(SonClass, self).__init__()
File "D:\SafeZone\PythonProjects\ICS_4\main.py", line 7, in __init__
self.method()
TypeError: SonClass.method() missing 1 required positional argument: 'son_value'
This is father init
如何进行解耦合呢?
class FatherClass(object):
__y = 'father class variable'
def __init__(self):
self.x = 'father variable'
print('This is father init')
self.__method()
def method(self):
print("This is a father method")
__method = method
修改父类如上,使用名称改写来实现其解耦,子类无法直接调用到方法__y,实际上被替换为_FatherClass__method() ,不要没事调用他。
上面的示例即使在 SonClass 引入了一个 __update 标识符的情况下也不会出错,因为它会在 FatherClass 类中被替换为 _FatherClass__update 而在 MappingSubclass 类中被替换为 _MappingSubclass__update。
4.dataclass
有时候需要一些数据类型类似C的struct结构的,需要糅合一部分数据在一起,Python提供了预实现模块dataclasses,
我们引用就可以了,举个例子:
from dataclasses import dataclass
@dataclass
class Chinese:
name: str
money: str
appearance: str
theone:bool
如何使用呢?
neonexus = Chinese('neonexus',money=0,appearance='normal',theone=False)
print(neonexus.theone)
输出结果:
<super: <class 'SonClass'>, <TestClass object>>
False
参考文章:
Python’s super() considered super! | Deep Thoughts by Raymond Hettinger (wordpress.com)
Good With Computers (sixty-north.com)
