
CS224d 之学习总结-第三部分
转载请注明出处:
http://www.cnblogs.com/NeighborhoodGuo/p/4753136.html
第三部分
这一部分只介绍了一个model,就是在CV领域大名鼎鼎的CNN其他课程大多请的外宾过来讲课,讲得都是DL如何在实际情况下的应用。
CNN
Basic CNN
CNN顾名思义倦积神经网络这个model叫倦积神经网络是因为它提取features的方式和倦积有些类似都是一格一格(或者几格几格)的左右移动。
CNN和Recursive NN是很类似的
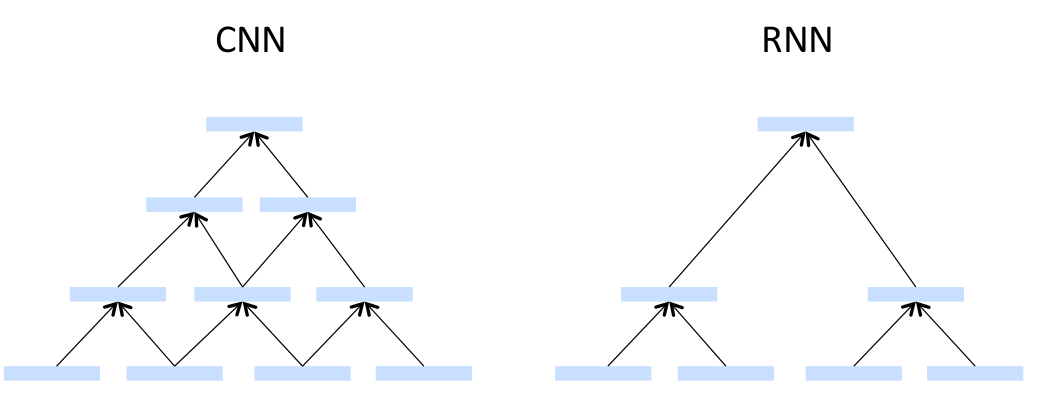
所不同的是CNN省略了Recursive NN的第一步也就是Parsing tree的那一步。
Induced Feature Graph,可以自己生成拓扑结构。看似挺不错的。RNN是使用过的vector在同一layer里不会再使用第二次,CNN是用过的vector在同一layer里还可以用,从不计较。
CNN很像卷积的,选一个window,然后从左向右的一步一步的移动,然后生成上一层的layer。

然后使用和RNN里一样的计算步骤,一步一步的recursive
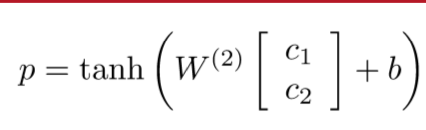
这种模型简单是简单,但是效果不好
CNN and pooling
带Pooling的CNN和Basic CNN在对于最下面两层的处理方面都是一样的,先生成金字塔的最下面两层:

然后生成了一个c的vector,接下来就pooling的过程,c_hat = max{C}
但是这样提取出来的只有一个,提取出来的features太少,于是我们用不同宽度的window提取出feature map,然后再pooling,这样提取出来的features就多了。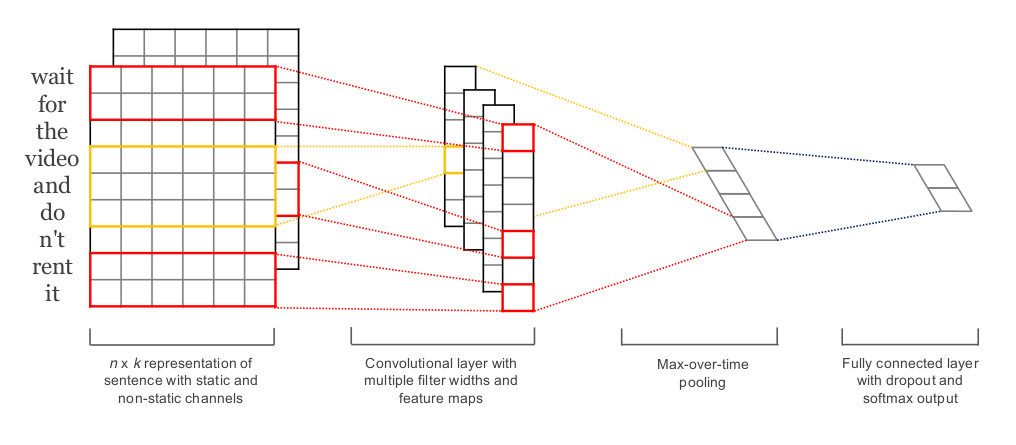
有一个trick据说可以提高精度这种方法是主动让models overfitting
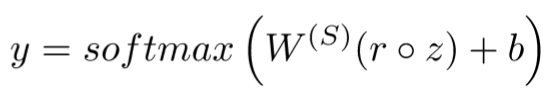
在training阶段的最后一步,在z之前element-wise乘一个r,r是Bernoulli random variables。
这样可以有意的提高overfitting的可能性,继而可以训练尽可能多的features
在使用的时候当然不用再乘r了,但是weight会很大,所以:

使其缩小,再计算最后结果
还有一个trick是为了避免overfitting的:

还有一个trick,由于我们的模型很复杂,dataset也很大,训练时间很长,但是最终的训练结果可能不是最优的,所以就每隔一段时间,记录下来相应的weight和accuracy,在最后训练完成的时候使用accuracy最高的weight。
Complex pooling schemes

这是目前为止效果最好的CNN模型
第一层
第一层使用的是Wide Convolution
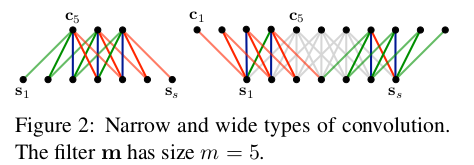
左边的是narrow右边的是wide
具体要怎么convolution呢?首先选一个m作为weight matrix
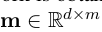
然后生成M
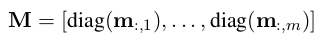
最后往上 计算一层:
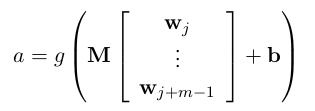
第二层
这个model里使用的k-max pooling和之前的不一样,这里一次提取出来前k个最大的,不像之前模型只提取出最大的
首先是k的计算方法:
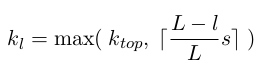
其中L是总层数,l是相应的层,s是句子里的单词数。k_top这个就自己优化了。
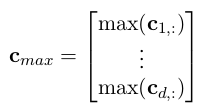
计算方法和这个类似,差别就是取出前k个最大的
Folding
这个最简单,就是把每两行相加起来,加之前是d行,加之后是d / 2行
最后一层
得到了想要的features最后就用Fully connected layer做预测了!
CNN application machine translation
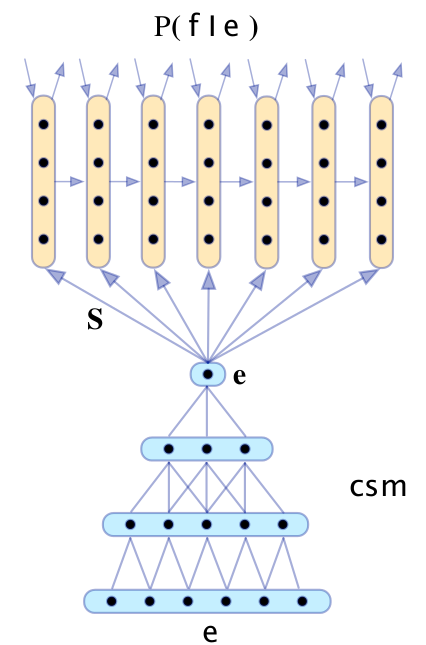
先不管用之前讲得哪种CNN生成最顶上的那个feature,然后用RNN生成对应的target language
Application Q&A
基于memory network的Q&A。Memory Networks不是和之前我们讲得模型里所定义的那种Memory。之前课上介绍的Model里的memory是使用各种data然后训练model,可以认为memory存储在这个model的weight里,可以用来进行object detection等的工作。而这堂课讲得memory和之前定义的不是一个概念,之前的memory类似计算机的软件,这堂课讲得memory类似计算机的硬盘,需要用到memory的时候从硬盘里提取数据,不需要的时候就放那里。
Q&A类似我们中学英语考试的阅读理解,或者语文高考的最后几道阅读题。我们实际想要达到的目标是能够让计算机完成语文高考的阅读题的水平,这种目标想法很好,但是实现很难衡量现有模型的好与坏,而且也不可能一下就实现这么复杂的架构。所以基于以上考虑聪明的科学家把Q&A分成了好几块类似我们中学英语的阅读理解,不用回答完整的句子,只要像英语阅读那样司选一或者只要回答单个或者几个关键词即可。论文中有具体的介绍分出来的Tasks的讲解和例子,从前到后的排序是由容易及难。我们大致的认为先把以上的几个分块的任务完成之后,再使用一个优化的model使得输出的句子比较nature就能完成AI的Q&A的任务了。
这个Memory Network的目标是可以理解(comprehension)一篇文章或者一部电影,然后根据文章或者电影的内容回答问题。但是动词的种类那么多,如果一个单词一个处理方法的话不现实,效率也挺低,而很多动词的意思其实是类似的,所以就可以使用下图中的基本Command来替代这些各种各样的单词。

替代完成后,再进行处理就相对来说简单了。
有了处理过的数据,也有了多个简单的Q&A目标,接下来就可以进行model的建立了。
我们建立的model主要分为四个部分I,G,O,R

I这一模块,其实之前的课程大部分都是针对I模块所包含的任务的,比如说Parsing,RNN。

不论在论文里还是在课上讲到的O模块的搜寻的向量只搜索两个,具体搜索方法如下:


简单的说就是每次取出最高score的向量,然后再根据取出来的这两个向量和原始的问题生成貌似nature的回答。
那么如果在Memory里一个单词没有见过或者一个单词遗失了怎么办呢?简单的办法就是使用临近的单词,然后Bag-of-words

当然以上的内容还远远没有达到AI的要求,课上和论文里都给出了approach AI的两个方法:



parallel计算
Efficient formulations
Structured VS unstructured computation
structured graph就是指各个units之间的连接都很规矩比如说CNN
这种规矩的表示方法的好处是:cache的使用都是连续的,很容易load,对内存的使用也很少。缺点就是灵活性不好
还有一种就是unstructured graph
好处是表达能力更强,但是cache的使用不连续,不容易load,对内存使用偏高(和之前的对立)
我们的目标就是在不影响性能的前提下,使表达更加structured
Block operations and BLAS
Block operations一个最简单的例子就是矩阵乘法和加法,也就类似把相似的运算打包成一整块,然后输入进去批量计算。
BLAS: Basic Linear Algebra Subroutines是一款很先进的并行计算工具,课上还推荐了其他很棒的并行计算工具。

CPUs and GPUs
课上讲师说CPU和GPU已经达到了peak performance。
内存的大小很受限,CPU和GPU的通讯很慢是一个瓶颈。
CPU更少的cores 每个core运算速度更快
GPU更多的cores 每个core运算速度慢
但是GPU有数量优势,整体来说GPU运算速度比CPU快
乍一看貌似完全使用GPU更好,其实不然。
由于有通讯瓶颈,在计算量较小的时候使用CPU其实更有计算优势,在计算数量较多的时候使用GPU才有明显的优势。

Data parallelism
这个就是用来优化之前的Batching gradient descent
1.先指定一个master core然后多个worker core,首先master给每个worker分配计算的任务
2.然后每个worker core各自分别计算
3.计算完成后汇总到master那里,由master汇总计算出最终结果
这里的parallelism是同步的。
Model parallelism
这个就是把model进行分块然后各个模块分别分配给各个core计算然后汇总结果。

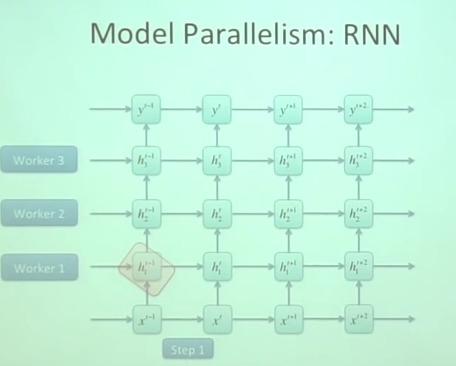
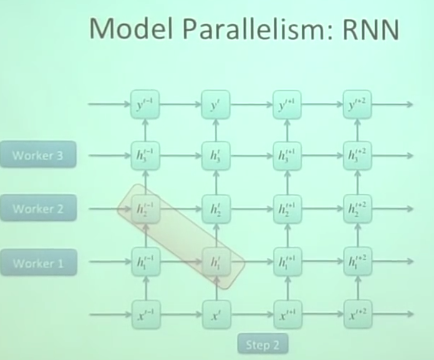

一台计算机的计算能力怎么说都是有限的,能不能使用多台计算机同时帮助计算呢?
但是计算机之间的以太网通信速度太慢了,开发更快速的计算机间通信才行。
Asynchronous SGD
前面说得同步的计算方法需要等待每个work core都计算完成才能汇总计算出结果,这样就会使一部分时间消耗在等待上面。
鉴于此就提出了异步的SGD

分配任务还是照常分配,但是谁计算完成谁就上传计算结果给master,然后master汇总完成之后立即给每个work core更新数据

HW3及有用的链接
homework
if __name__=='__main__'
http://www.cnblogs.com/xuxm2007/archive/2010/08/04/1792463.html
with … as …
http://zhoutall.com/archives/325
matlib.plot.subplot
http://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.subplot
set_aspect
http://matplotlib.org/api/axes_api.html?highlight=set_aspect#matplotlib.axes.Axes.set_aspect
|
‘equal’ |
same scaling from data to plot units for x and y |
|
num |
a circle will be stretched such that the height is num times the width. aspect=1 is the same as aspect=’equal’. |
优化方法
http://weibo.com/p/230418eb3aea990102v41r
有用的资源
Speech recognition model的开源project
两个dataset语音识别方面的:
TIMIT
http://blog.163.com/gz_aaa/blog/static/37834532201471881923177/
http://www.fon.hum.uva.nl/david/ma_ssp/2007/TIMIT/
Switchboard
http://www.isip.piconepress.com/projects/switchboard/
几个开源的Parallelism Packages
1.BLAS
2.CPUs: Intel MKL, Atlas, GOTO
GPUs: Cuda, OpenAcc, clBLAS
3.Theano, Torch

 浙公网安备 33010602011771号
浙公网安备 33010602011771号