
CS224d lecture 16札记
欢迎转载,转载注明出处:
http://www.cnblogs.com/NeighborhoodGuo/p/4728185.html
终于把最后一讲也看完了,stanford的NLP课程也接近了尾声,真的是非常的开心,这门课真的让我收获了很多。
这一课讲得就是DL在NLP方面的应用,其实大部分内容在之前的课上和之前的推荐阅读里都有提及,这一课也算是一门复习课吧。
同样的先overview一下:1.Model overview 2.Character RNNs on text and code 3.Morphology 4.Logic 5.Q&A 6.Image - Sentence mapping
Model overview
老师在课上极力推荐Glove
word vector的维度经常决定了模型的参数数量
Phrase Vector Composition的表示方式主要有Averaging, Recursive Neural networks, Convolutional neural networks, Recurrent neural network
其中很多Recursive functions都是MV-RNN的变种

其中Parsing tree主要分为三种:第一种是Constituency Tree对于syntactic structure的捕捉很有优势 第二种是Depenency Tree对于semantic structure的捕捉很有优势
第三种是Balanced Tree非常类似CNN
Objective function主要有三种:第一种是Max-margin 第二种是cross-entropy 第三种是Auto-encoder(这一种对于NLP的用处还不明确,所以课上都没有讲)
Optimization分为两大类:第一大类是Optimization Algorithm,有SGD, SGD + momentum, L-BFGS, AdaGrad, Adelta
第二大类是Optimization tricks, 有Regularization, Dropout
Morphology
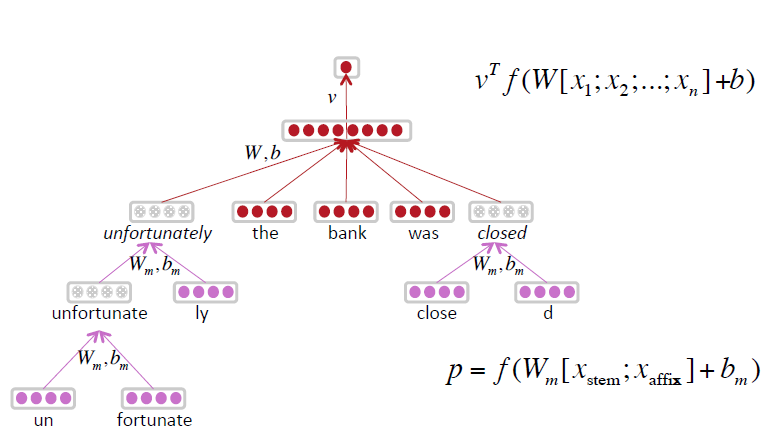
在英语中有些词汇有一个标准的词根,这个词根还可以衍生出许多派生词。有些时候词根的词汇出现的频率特别高,派生词出现的频率比较低。
这样就导致了model对词根的表示比较精确,但是对派生词的表示就比较模糊了。
于是基于这种问题就有了一种对于模型的改进措施。
对于派生词将它先parsing生成一个基于词根的tree然后使用词根以及前缀后缀,这样就把派生词和词根联系起来了。
Logic
主要是为了识别出来以下的内容:

使用的模型还是RNN,模型都比较类似就不赘述了。
Q&A
课上的这部分内容来自于之前的一篇推荐paper,以后计算机能和人对话,就是apple手机上的siri再更加完善的版本。
还有就是计算机能够参加类似幸运52,开心辞典类的节目,而且还能比人做的好。这个就厉害了。
Image - Sentence mapping
最新的研究成果是李飞飞教授做的。就是说一张图片放过来,计算机能描述出这张图上面的内容。
简单的方法是把图片和句子投影到同一个向量空间中,当出现一个图片时,应用欧式距离求最近的几个句子就能找到合适的描述了。反之可以做图片检索。
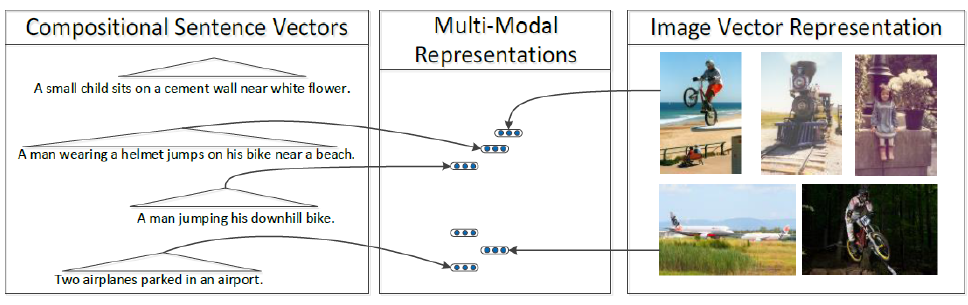
但是这样生成的句子都是有限的句子,计算机不能自己“描述”,于是就有了改进版本。
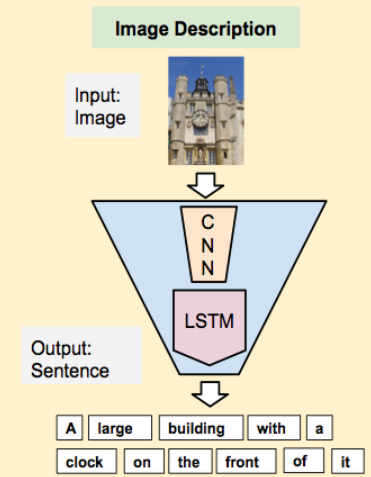
先用CNN模型把图片投射成一个向量,再用LSTM生成句子。这个有点类似机器翻译,只不过把source language换成了image
最后说一下这种模型的评价方法(evaluation)名称叫做Mean rank
在生成一个图片对于的句子的时候,可能会生成很多句子,有些正确有些不正确。
把生成的所有的句子按照相关性从大到小排序,然后记录下正确的句子的rank求mean就是mean rank
当然是越小越好啦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号