


CS224d lecture 13札记
欢迎转载,转载注明出处:
http://www.cnblogs.com/NeighborhoodGuo/p/4716827.html
不知不觉到了第三部分了,整个课程也快结束了,虽然不是第一次整个推完公开课,但是还是有些兴奋呢!
废话不多说,开始总结啦!
这节课就介绍了一个模型,就是在Computer Vision里十分popular的CNN(Convolutional Neural Networks)。不过这里介绍它在NLP的应用,可见model其实是可以有不同的应用的哦,没准我们的大脑就是这么运转的,哈哈扯远了。
从RNN引入CNN
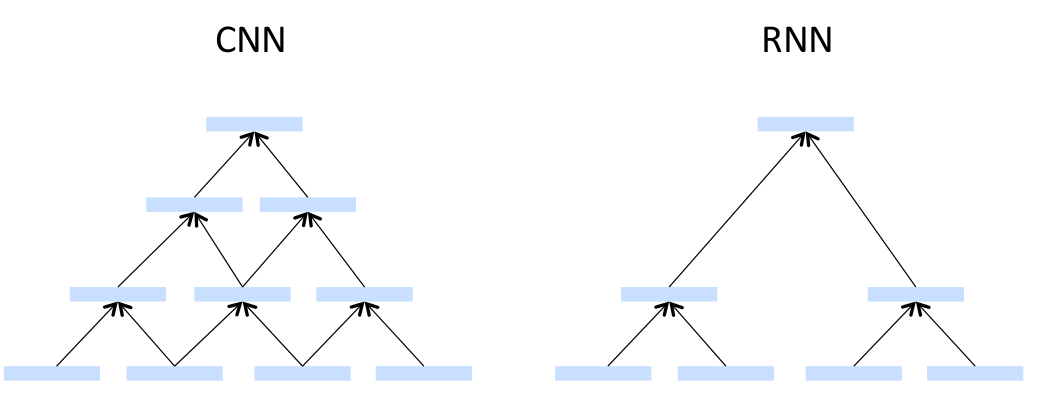
RNN是先整出来一个parsing tree然后一步一步的向上爬(蜗牛吗?- -),CNN不用整出来一个parsing tree,用论文里的话说就是Induced Feature Graph,可以自己生成拓扑结构。看似挺不错的。RNN是使用过的vector在同一layer里不会再使用第二次,CNN是用过的vector在同一layer里还可以用,从不计较。
CNN很像卷积的,选一个window,然后从左向右的一步一步的移动,然后生成上一层的layer。
第一部分介绍了一个最最简单的CNN,就是一个金字塔的结构:

然后使用和RNN里一样的计算步骤,一步一步的recursive
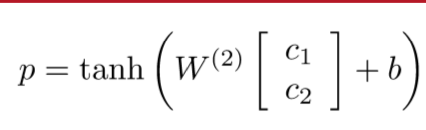
这种模型简单是简单,但是效果不好
CNN and pooling
于是就想出来一个好办法,第一步和之前的金字塔结构一样,就是生成金字塔的最下面两层:

然后生成了一个c的vector,接下来就pooling的过程,c_hat = max{C}
但是这样提取出来的只有一个啊,怎么办呢?多建几个金字塔不久好了,不对多建几个金字塔的底座,专业点说就是用不同宽度的window提取出feature map,然后再pooling,这样提取出来的features就多了。
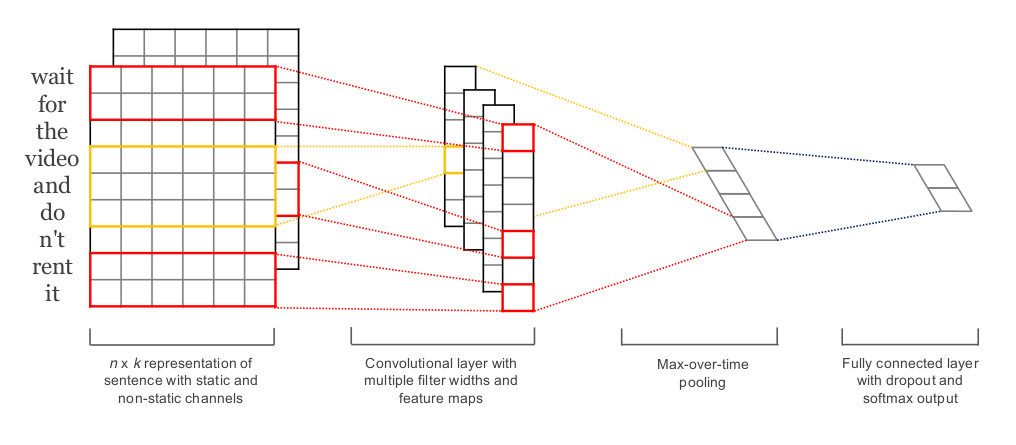
tricks
有一个trick据说可以提高精度
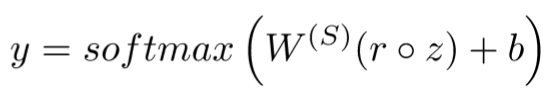
在training阶段的最后一步,在z之前element-wise乘一个r,r是Bernoulli random variables。
这样可以有意的提高overfitting的可能性,继而可以训练尽可能多的features
在使用的时候当然不用再乘r了,但是weight会很大,所以:

使其缩小,再计算最后结果
还有一个trick是为了避免overfitting的:

还有一个trick - -
由于我们的模型很复杂,dataset也很大,训练时间很长,但是最终的训练结果可能不是最优的,所以就每隔一段时间,记录下来相应的weight和accuracy,在最后训练完成的时候使用accuracy最高的weight。
Complex pooling schemes

在课程的最后讲了一个最复杂也是最牛掰的CNN,在看完paper之后算是弄明白了
第一层
第一层使用的是Wide Convolution
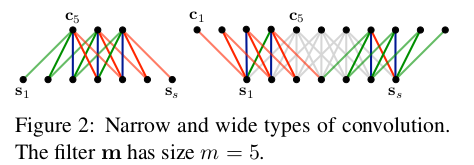
左边的是narrow右边的是wide
具体要怎么convolution呢?首先选一个m作为weight matrix
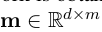
然后生成M
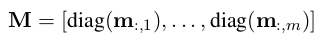
最后往上 计算一层:
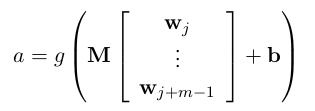
第二层
这个model里使用的k-max pooling和之前的不一样,这里一次提取出来前k个最大的,不像之前模型只提取出最大的
首先是k的计算方法:
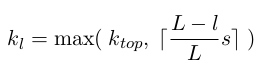
其中L是总层数,l是相应的层,s是句子里的单词数。k_top这个就自己优化了。
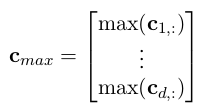
计算方法和这个类似,差别就是取出前k个最大的
Folding
这个最简单,就是把每两行相加起来,加之前是d行,加之后是d / 2行
最后一层
得到了想要的features最后就用Fully connected layer做预测了!
CNN application machine translation
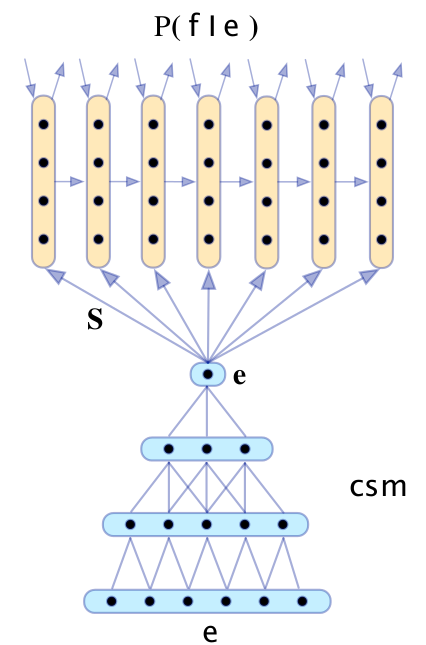
先不管用之前讲得哪种CNN生成最顶上的那个feature,然后用RNN生成对应的target language
各种model的优劣
Bag of vectors对于简单的分类问题很好
Window Model对于单词的分类很好,长段的分类不行
CNNs直接被吹得万金油了
Recursive NN语义学上貌似可信,但是得生成一个parsing tree(我怎么感觉这个不靠谱)
Recurrent NN认知学上貌似可信,但是现在性能不是最优的

