【TensorFlow实战】TensorFlow实现经典卷积神经网络之AlexNet
AlexNet
卷积神经网络已经基本解决了ImageNet数据集的图片分类问题。ImageNet项目的灵感最早来自儿童认识世界时眼睛相当于每200ms就拍照一次。
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中,其主要应用到的新技术点在于:
1.成功使用ReLU作为CNN的激活函数,验证了其效果在较深的网络中超过Sigmoid,解决了Sigmoid在网络较深时梯度弥散的问题。
2.训练时使用Dropout随机忽略一部分神经元,防止过拟合。AlexNet中主要最后几个全连接层使用了Dropout。
3.在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
4.提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其它反馈小的神经元,增强了模型的泛化能力。
5.使用CUDA加速深度神经网络的训练。(两块GTX 580 GPU)
6.数据增强,随机从256*256的原始图片中截取224*224大小的区域(以及水平翻转的镜像),相当于增加了(256-224)^2=2048倍的数据量。大大减轻了过拟合,提升了泛化能力。进行预测时,则是却图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对它们进行预测并对10次结果取平均。同时,AlexNet论文中提到对图片的RGB数据进行PCA处理,并对主成分做一个标准为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。
整个AlexNet有8个需要训练参数的层(不包括池化层和LRN层),前5层为卷积层,后3层为全连接层。
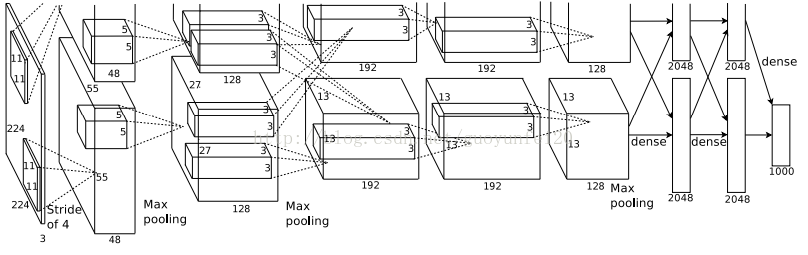
AlexNet最后一层是有1000类输出的Softmax层用作分类。LRN层出现在第1个及第2个卷积层后,而最大池化层出现在两个LRN层及最后一个卷积层后。ReLU激活函数应用在这8层每一层的后面。因为AlexNet原训练在两个GPU上,所以上图不少组件被拆为两个部分。
AlexNet每层的超参数如下图所示。其中图片的输入为224*224,第一层的卷积核为11*11,步长4,有96个卷积核;紧接一个LRN层;然后是一个3*3的最大池化层,步长为2。这几后的卷积核都比较小,都是5*5或3*3,并且步长为1,即会扫面全图所有像素;而最大池化层依然保持3*3,步长为2。

可以发现,在前几个卷积层,虽然计算量很大,但参数量很小,都在1M左右或更小。这就是卷积有用的地方,可以通过较小的参数量提取有效的特征。虽然每一个卷积层占整个网络的参数量的1%都不到,但是如果去掉任何一个卷积层,都会使网络的分类性能大幅下降。
AlexNet之TensorFlow实现:
from datetime import datetime
import math
import time
import tensorflow as tf
batch_size=32
num_batches=100
# 该函数接受一个tensor作为输入,并显示其名称和tensor尺寸
# 目的是展示每一个卷积层或池化层输出的tensor尺寸
def print_activations(t):
print(t.op.name, ' ', t.get_shape().as_list())
# 该函数接受image作为输入,返回第5个池化层及parameters(AlexNet中所有需要训练的模型参数)
def inference(images):
parameters = []
# conv1
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 64], dtype=tf.float32, # 截断的正态分布函数初始化卷积核kernel
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
print_activations(conv1)
parameters += [kernel, biases]
# pool1
lrn1 = tf.nn.lrn(conv1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='lrn1') # LRN层,depth_radius设为4。其它经典CNN不适用LRN
pool1 = tf.nn.max_pool(lrn1,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool1')
print_activations(pool1)
# conv2
with tf.name_scope('conv2') as scope:
kernel = tf.Variable(tf.truncated_normal([5, 5, 64, 192], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[192], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv2)
# pool2
lrn2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='lrn2')
pool2 = tf.nn.max_pool(lrn2,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool2')
print_activations(pool2)
# conv3
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv3)
# conv4
with tf.name_scope('conv4') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv4 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv4)
# conv5
with tf.name_scope('conv5') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv5 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv5)
# pool5
pool5 = tf.nn.max_pool(conv5,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool5')
print_activations(pool5)
return pool5, parameters
之后添加3个全连接层,隐含节点分别为4096,4096,1000。接下来是AlexNet运算时间评测。
# 该函数用于评估AlexNet每轮计算的时间
def time_tensorflow_run(session, target, info_string):
# """Run the computation to obtain the target tensor and print timing stats.
#
# Args:
# session: the TensorFlow session to run the computation under.
# target: the target Tensor that is passed to the session's run() function.
# info_string: a string summarizing this run, to be printed with the stats.
#
# Returns:
# None
# """
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print ('%s: step %d, duration = %.3f' %
(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print ('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %
(datetime.now(), info_string, num_batches, mn, sd))
# 主函数。输入是随机生成的图片
def run_benchmark():
# """Run the benchmark on AlexNet."""
with tf.Graph().as_default():
# Generate some dummy images.
image_size = 224
# Note that our padding definition is slightly different the cuda-convnet.
# In order to force the model to start with the same activations sizes,
# we add 3 to the image_size and employ VALID padding above.
images = tf.Variable(tf.random_normal([batch_size,
image_size,
image_size, 3],
dtype=tf.float32,
stddev=1e-1))
# Build a Graph that computes the logits predictions from the
# inference model.
pool5, parameters = inference(images)
# Build an initialization operation.
init = tf.global_variables_initializer()
# Start running operations on the Graph.
config = tf.ConfigProto()
config.gpu_options.allocator_type = 'BFC'
sess = tf.Session(config=config)
sess.run(init)
# Run the forward benchmark.前向的评估
time_tensorflow_run(sess, pool5, "Forward")
# Add a simple objective so we can calculate the backward pass.训练过程的评估
objective = tf.nn.l2_loss(pool5)
# Compute the gradient with respect to all the parameters.
grad = tf.gradients(objective, parameters)
# Run the backward benchmark.
time_tensorflow_run(sess, grad, "Forward-backward")
run_benchmark()
以上是AlexNet训练时间评测,CNN的预测问题不大,在iOS或Android可以轻松运行人脸识别。AlexNet在ILSVRC数据集错误率可达%。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号