
数据预处理(Python&R)学习笔记
数据预处理(Python&R)学习笔记
首先,让我们先来看一下我们要处理的数据实例:
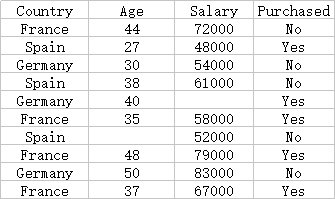
我们的目的是让这样的原始数据处理成机器学习算法可以直接计算的额数据形式。对于该数据实例,有以下几个操作关键:
1.进行缺失数据处理
对缺失值进行处理的一般思路是使用这一列数据的“平均数”,“中位数”或“众数”来填充,这里我们利用“中位数”来填充。
2.处理分类特征的数据(Country&Purchased)
像Country和Purchased这两列数据,其实质是分类,而不是数值大小,在这里使用虚拟编码对其进行处理。比如,对于Country这一列数据,使用OnehotEncoder进行处理。
3.将数据集分成训练集和测试集
将数据集分成训练集和测试集是十分必要的,我们一般会随机地将数据集的25%或20%(一般不超过40%)数据设置为测试集,剩下的为训练集。这里我们设置20%为测试集。
4.特征缩放
特征缩放在一些机器学习算法中必要的,比如在涉及到欧氏距离计算的算法、决策树算法中。是为了防止数值较大的自变量对数值较小的自变量的影响(比如例子中Salary这一列与Age这一列)或是为了在算法中使得收敛速度更快。关于特征缩放有以下两种方法(标准化和正常化):

很显然,对于Salary&Age这两列的数据进行特征缩放毋庸置疑,但对于像Country&Purchased这两列进行虚拟编码的数据是否需要特征缩放就需要视情况而定。在这里是对所有自变量的数据进行特征缩放。
好了,现在可以开始使用Python&R进行操作了。
一、数据预处理(Python)
①导入标准库
# Data Preprocessing Template
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
②导入数据集,并划分自变量矩阵和因变量向量
# Importing the dataset
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
③利用每列平均数填充缺失值
# Taking care of missing data
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = 'NaN', strategy = 'mean', axis = 0)
imputer = imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
④对分类特征的数据(Country&Purchased)进行处理
# Encoding categorical data
# Encoding the Independent Variable
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
# Encoding the Dependent Variable
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
⑤将数据分成训练集和测试集
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
⑥特征缩放
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
以上步骤并不是每一步都是必需的,要视具体情况而定。
二、数据预处理(R)
①导入数据集
# Data Preprocessing
# Importing the dataset
dataset = read.csv('Data.csv')
②对缺失数据进行处理
# Taking care of missing data
dataset$Age[is.na(dataset$Age)] = mean(dataset$Age, na.rm = T)
dataset$Age[is.na(dataset$Salary)] = mean(dataset$Salary, na.rm = T)
③对分类特征的数据(Country&Purchased)进行处理
# Encoding categorical data
dataset$Country = factor(dataset$Country,
levels = c('France', 'Spain', 'Germany'),
labels = c(1, 2, 3))
dataset$Purchased = factor(dataset$Purchased,
levels = c('No', 'Yes'),
labels = c(0, 1))
④将数据分成训练集和测试集
# Splitting the dataset into the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Purchased, SplitRatio = 0.8)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
⑤特征缩放
# Feature Scaling
training_set[, 2:3] = scale(training_set[, 2:3])
test_set[, 2:3] = scale(test_set[, 2:3])


