《Text Mining and Analysis》第三周学习笔记
《Text Mining and Analysis》第三周学习笔记
课程导读:
Goals and Objectives
- Explain what a mixture of unigram language model is and why using a background language in a mixture can help “absorb” common words in English.
- Explain what PLSA is and how it can be used to mine and analyze topics in text.
- Explain the general idea of using a generative model for text mining.
- Explain how to compute the probability of observing a word from a mixture model like PLSA.
- Explain the basic idea of the EM algorithm and how it works.
- Explain the main difference between LDA and PLSA.
Guiding Questions
- What is a mixture model? In general, how do you compute the probability of observing a particular word from a mixture model? What is the general form of the expression for this probability?
- What does the maximum likelihood estimate of the component word distributions of a mixture model behave like? In what sense do they “collaborate” and/or “compete”? Why can we use a fixed background word distribution to force a discovered topic word distribution to reduce its probability on the common (often non-content) words?
- What is the basic idea of the EM algorithm? What does the E-step typically do? What does the M-step typically do? In which of the two steps do we typically apply the Bayes rule? Does EM converge to a global maximum?
- What is PLSA? How many parameters does a PLSA model have? How is this number affected by the size of our data set to be mined? How can we adjust the standard PLSA to incorporate a prior on a topic word distribution?
- How is LDA different from PLSA? What is shared by the two models?
Key Phrases and Concepts
- Mixture model
- Component model
- Constraints on probabilities
- Probabilistic Latent Semantic Analysis (PLSA)
- Expectation-Maximization (EM) algorithm
- E-step and M-step
- Hidden variables
- Hill climbing
- Local maximum
- Latent Dirichlet Allocation (LDA)
一、Probabilistic Topic Models: Mixture of Unigram LMs
首先,对出现的符号做以下说明:
d 文档
w 单词
θ 主题
p(w|θ) 主题θ下单词w出现的概率
Λ 参数的集合
c(w,d) 文档d中单词w出现的次数
-
我们怎样来去除那些common words呢?
很显然,因为这些common words在文档中总是出现,并且我们是用最大似然概率来计算(上一周),这导致这些common words获得高频概率,但这非我们想看到的结果。
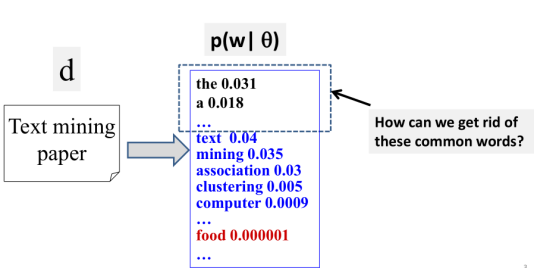
如何来解决这个问题?这是提到一种方法。
2.使用有个词分布来generate文档d
这个词分布分别是Topic θd 和Background topic θB。它比只有一个词分部的unigram model多了一点不确定性,这就是Mixture of unigram language model。在这里设p(θd)和p(θB)为0.5。
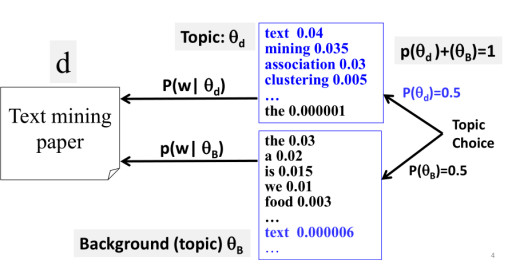
3.怎么计算一个特定的单词的概率,如p(“the”)=?
假设如上图所示的数据结果,p(“the”)的计算方式为:

4.归纳出Mixture model的一般计算形式
其主要思想就是利用两个词分布(Topic θd 和Background topic θB)来计算单词生成(出现)的概率,计算公式如下:
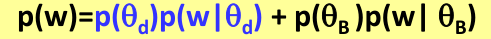
5.课程小结
这一节的主要内容如下图所示:

下一节讲解如何计算求解这个模型的参数。
二、Probabilistic Topic Models:Mixture Model Estimation
我们建立这个模型的目的就是把那些高概率的common words给筛出。为了达到这个目的,在这一节中讲述这个模型:
①除了θd外其余参数都是已知的,如何调整θd使得p(d|Λ)最大?
②通过一个简单的实例来讨论mixture model的规律(协作与竞争关系,模型对高频词的反应),得出其两条规律如下:
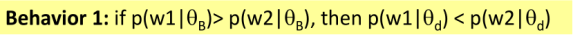

基于此,以下回答三个问题:
-
Mixture model中词分布的最大似然估计是如何计算的?
回答如图所示:

依然是利用上一节讲述的计算方法。
2.他们在什么意义上“协作”和/或“竞争”?
3.为什么我们可以使用固定的背景词分布来强制发现的主题词分布,以减少它在常见的(通常是非内容的)词上的概率?
这两个问题的回答是相辅相成的,解答如下图:

因为text在背景模型中较弱,它值很小,为了补偿这一点,我们必须让θd中text的概率更大。这样等式两边才能平衡,所以这是这个混合模型很常见的表现。
就是说,如果其中一个分布分给某个词的概率更高,另一个分布中这个词的概率就更低,它会阻止其他分布分给这个词高概率。这就是为了让子模型相抵 保证每一个词在主模型中享有公平的概率。
三、Probabilistic Topic Models:Expectation-Maximization (EM) Algorithm
在此之前,先来回答以下几个问题:
-
EM算法的基本思想是什么?
回答如下:
①用随机值初始化p(w|θd);
②然后使用E-step & M-step迭代改进该值;
③直到其值趋于稳定。
2.E步骤通常会做什么? M-step通常会做什么?在两个步骤中,我们通常应用贝叶斯规则?
回答如下:

3.这个算法是否能收敛到全局最优?
回答如下:
EM算法是一种爬坡算法,收敛于局部最优解。当然这也与它的起始点有关。如图所示:
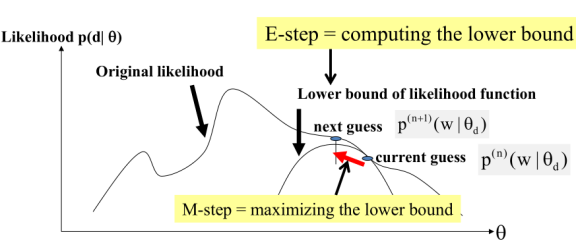
在这一节中,目的是解决上一节“除了θd外其余参数都是已知的,如何调整θd使得p(d|Λ)最大?”这里使用EM算法解决这个问题。
首先,先定义隐藏变量(Hidden Variable):

然后,利用上述讲述的EM算法的步骤进行计算,使得θd中词概率发生了变化。具体结果如下所示:

如此,问题便得到了一种有效的求解。
四、Probabilistic Latent Semantic Analysis (PLSA)
以下回答几个问题:
-
什么是PLSA ?PLSA模型有多少个参数?我们的数据集的大小会如何影响这个数字?
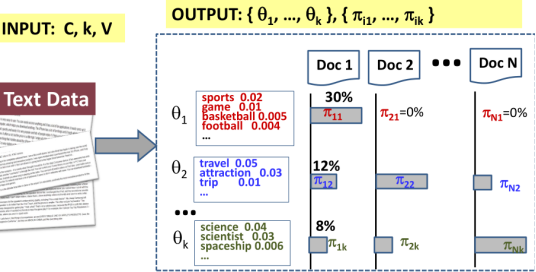
PLSA = mixture model with k unigram LMs (k topics),如图所示:
PLSA的未知参数有(K指K个主题):
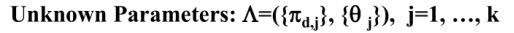
PLSA的推导过程如下:

数据集的大小会使未知参数的个数乘法式增长。
2.PLSA模型要求解的目标是?
回答如下:
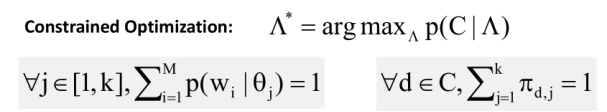
3.如何使用EM算法来求解这个优化问题?

其中E步和M步分别为:


五、Latent Dirichlet Allocation (LDA)
以下回答几个问题:
-
LDA与PLSA有什么不同?
回答:
PLSA中,主题分布和词分布是唯一确定的,但在LDA中,主题分布和词分布不再唯一确定不变,即无法确切给出。PLSA跟LDA的本质区别就在于它们去估计未知参数所采用的思想不同,前者用的是频率派思想,后者用的是贝叶斯派思想。
(来自课外阅读:http://blog.csdn.net/v_july_v/article/details/41209515#t15)
2.两种模型共享什么?
这个模型共享的部分可以从下图看出:

3.PLSA的缺陷
(1)不是一个生成模型,无法计算新文档的概率,但启发式的解决方法是可能的;
(2)有许多参数,导致模型的复杂性很高;
扩展阅读:
七月在线July博主关于LDA的详细介绍(我还没看懂)链接:http://blog.csdn.net/v_july_v/article/details/41209515#t15
以下为课程对整个概率主题模型的小结:

六、单词笔记
factor out 提取出
subject to 受制于....
demote 降级
optimal 最优的
assign 分配
collaboratively 协作地
scenario 方案
component 成分;组件
adequate 充足
parameter 参数
cluster 聚类
precisely 精确地
normalize 标准化
tentative 试验性的
inference 推理
process 处理;过程
typical 典型
prior 先验
perhaps 也许
generate 生成
flip a coin 抛硬币
end up with 以......而结束
formula 公式
solid 可靠的
variable 变量
probabilistically 有概率性地
occurrence 出现
initialize 初始化
invoke 调用
revise 修正
illustrate 阐明
split 分离开
iteratively 迭代第;反复地
latent 隐藏的
semantic 语义的
multiple 多个
accumulate 积累
versus 与.....相对

 浙公网安备 33010602011771号
浙公网安备 33010602011771号