1-MySQL - count那些事儿
before
win10 + mysql5.7.20
最近,老有学生问关于count(1)、count(*)是什么意思,就写篇博客,做个说明。
MySQL中,count有三种用法count(1)、count(*)、count(列),注意只有count(列)不计算null值。
来看个示例,首先先准备个表和一些数据,1表示男的,共6个男的;0表示女的,共4个女的。最后一个null就没啥好说了....最后,6男4女1个null,总共11条记录。
create table user(gender tinyint) charset=utf8;
insert into user values
(1),(1),(1),(1),(1),(1),
(0),(0),(0),(0),(null);
有了数据,我们根据具体的查询需求,来慢慢理解count的玩法。
查询user表中有多少行记录
[t1]>select count(*), count(1), count(gender) from user;
+----------+----------+---------------+
| count(*) | count(1) | count(gender) |
+----------+----------+---------------+
| 11 | 11 | 10 |
+----------+----------+---------------+
1 row in set (0.00 sec)
要统计记录的总行数,用count(1)、count(*)的结果是对的,但count(gender)就不对了,因为count(列)它不计算null值,而我们的记录中,正好有一个null值,它不计算,所以结果是10。
所以,如果你的表中要统计的字段如果有null值,要根据你的需求来选择用哪种count。
count(1)、count(*)、count(列)的区别
从执行结果来看:
- count(1)和count(*)没啥区别,都不会过滤null值。
- 而count(列)则会过滤掉null值。
从执行效率来说,它们之间根据不同情况有少许区别:
-
如果列为主键,
(1)如果列为主键,count(列名)效率优于count(1) (2)如果列不为主键,count(1)效率优于count(列名) (3)如果表中存在主键,count(主键列名)效率最优 (4)如果表中只有一列,则count(*)效率最优 (5)如果表有多列,且不存在主键,则count(1)效率优于count(*)
1、count(1):可以统计表中所有数据,不统计所有的列,用1代表代码行,在统计结果中包含列字段为null的数据;
2、count(字段):只包含列名的列,统计表中出现该字段的次数,并且不统计字段为null的情况;
3、count(*):统计所有的列,相当于行数,统计结果中会包含字段值为null的列;
二、count执行效率
列名为主键,count(列名)比count(1)快;列名不为主键,count(1)会比count(列名)快;
如果表中多个列并且没有主键,则count(1)的执行效率优于count(*);
如果有主键,则select count(主键)的执行效率是最优的;如果表中只有一个字段,则select count(*)最优。
参考:https://blog.csdn.net/xintingandzhouyang/article/details/105003015
https://blog.csdn.net/guorui_java/article/details/114951671
count(expression or null)的问题
win10 + mysql5.7.20
今天突然被一个学生问到这样一个问题,如下图,为啥要加or null才能得到正确的结果?
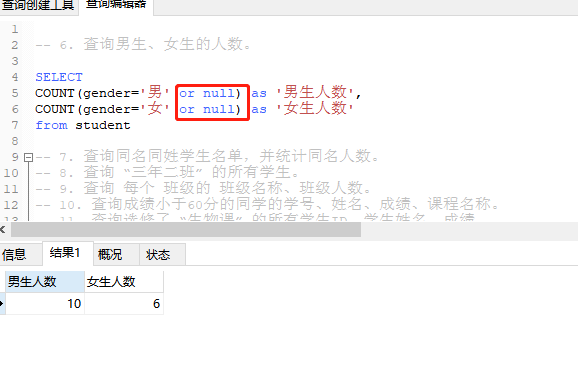
接下来我就把我的理解和大家说下。
首先count函数通常用来:
- 统计表的所有行,包括为null的行。
[t1]>select count(*) from user;
+----------+
| count(*) |
+----------+
| 11 |
+----------+
1 row in set (0.00 sec)
- 除了统计行数之外,还可以用来统计指定列的值的数量,比如上图中统计gender为男的数量,但这就有聊了。
情景1:统计不为null值的列数
如果count中指定列名,那么统计的是值不为null的数量。如下示例的查询结果可以看到,值为null的列没有统计到。
[t1]>select count(gender) from user;
+---------------+
| count(gender) |
+---------------+
| 10 |
+---------------+
1 row in set (0.00 sec)
情景2:count中指定的是一个表达式
如果count中指定的是一个表达式,除非表达式结果为null,否则也会被统计。
[t1]>select count(gender=1) from user;
+-----------------+
| count(gender=1) |
+-----------------+
| 10 |
+-----------------+
1 row in set (0.00 sec)
上面的查询,想统计男生的数量,但结果是男女的总数量,这是因为,在统计列数时,当gender=1或者gender=0的判断结果无论是真还是假,但只要不是null,那就会被count统计上了,类似于这样的判断:
-- 如果当前列值是1,就返回1,否则返回0,那么结果就是11了, 原因是女和null值都不符合条件if条件,返回的是0,但0也被统计了
[t1]>select count(if(gender=1, 1, 0)) from user;
+---------------------------+
| count(if(gender=1, 1, 0)) |
+---------------------------+
| 11 |
+---------------------------+
1 row in set (0.00 sec)
-- true/false和1/0一样
[t1]>select count(if(gender=1, true, false)) from user;
+----------------------------------+
| count(if(gender=1, true, false)) |
+----------------------------------+
| 11 |
+----------------------------------+
1 row in set (0.00 sec)
这就导致我们的查询结果不符合预期了......为了解决这个问题,我们可以在查询时引入count统计列值时不统计null的机制。
-- 下面两个count的表达式是一样的
[t1]>select count(if(gender=1, true, null)) as "男", count(gender=1 or null) as "男"
from user;
+----+----+
| 男 | 男 |
+----+----+
| 6 | 6 |
+----+----+
1 row in set (0.00 sec)
拆开了讲,就是:
gender=1 or null>1 or null>1,被count统计。gender=0 or null>0 or null>null,不被count统计。
[t1]>select 1 or null;
+-----------+
| 1 or null |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
[t1]>select 0 or null;
+-----------+
| 0 or null |
+-----------+
| NULL |
+-----------+
1 row in set (0.00 sec)
现在懂了吧。
参考:肥仔问题杂记–MySql中COUNT(XXX OR NULL) | MySQL」Count 函数的正确使用方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号