1-MySQL - MHA
about
MHA Manager和 Node软件包,百度云盘链接:https://pan.baidu.com/s/1LZD7n7hrQZV8jYUCPDOorQ 提取码:duc1
github下载:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
MHA(Master High Availability)架构架构演变于主从复制架构,且不允许多个节点部署在单机多实例上,最低要求是一主两从。所以,我们本次部署MHA高可用的架构如下:
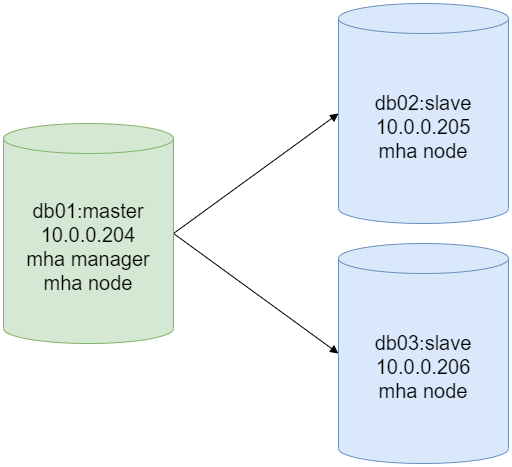
部署MHA高可用架构,需要两个软件来支持:
# MHA Manager
mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
# MHA Node
mha4mysql-node-0.58-0.el7.centos.noarch.rpm
这两个软件都是基于Perl语言开发,软件安装后,就会生成一堆的脚本,通过不同的脚本,完成高可用的特性。
MHA Manager software
MHA Manager软件只需要安装在主节点所在的服务器即可,也可以单独的部署在一个服务器上。
| 脚本 | 功能 |
|---|---|
| masterha_manager | 启动MHA |
| masterha_check_ssh | 检查MHA的SSH配置情况 |
| masterha_check_repl | 检查主从复制情况 |
| masterha_master_monitor | 检查master节点是否宕机 |
| masterha_check_status | 检查当前MHA运行状态 |
| masterha_master_switch | 控制故障转移(自动或者手动) |
| masterha_conf_host | 添加或者删除配置的server信息 |
| masterha_stop | 关闭manager |
MHA Node software
MHA Node软件需要安装到所有从节点。
MHA Node软件提供的脚本工具,通常由MHA Manager的脚本自动调用,无需人为操作。
| 脚本 | 功能 |
|---|---|
| save_binary_logs | 保存和复制master的二进制日志 |
| apply_diff_relay_logs | 识别差异的中继日志事件,并将其差异的事件回放 |
| purge_relay_logs | 清除中继日志(不会阻塞SQL线程) |
MHA配置文件介绍
# MHA Manager的配置文件
[server default]
# server default 默认配置,适用于所有的节点
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog # 主库的二进制日志的位置
# MHA专用用户
user=mha
password=mha
# 主从复制专用用户
repl_user=rs
repl_password=123
# 探测节点状态的时间间隔,每隔两秒探测一次,如果探测失败,将尝试探测3次,无果则判断节点故障,然后执行故障转移过程
ping_interval=2
# ssh连接时的用户
ssh_user=root
[server1]
hostname=10.0.0.204
port=3306
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
了解:VIP?VIP漂移?
参考:https://www.cnblogs.com/xinrong2019/p/13833975.html
IP地址和MAC地址:
- 在 TCP/IP 的架构下,所有想上网的电脑,不论是用何种方式连上网路,都必须要有一个唯一的 IP-address。事实上IP地址是主机硬件地址的一种抽象,简单的说,MAC地址是物理地址,IP地址是逻辑地址。
什么是虚拟IP:
- 虚拟IP地址(VIP) 是一个不与特定计算机或一个计算机中的网络接口卡(NIC)相连的IP地址。数据包被发送到这个VIP地址,但是所有的数据还是经过真实的网络接口。VIPs大部分用于连接冗余;一个VIP地址也可能在一台计算机或网卡发生故障时可用,交由另一个可选计算机或网卡响应连接。
- 虚拟IP就是一个未分配给真实主机的IP,也就是说对外提供服务器的主机除了有一个真实IP外还有一个虚IP,使用这两个IP中的任意一个都可以连接到这台主机。
虚拟IP可以用来做什么?解决了什么问题?
- 一般可以用来做HA(High Availability),比如数据库服务器的URL可以使用一个虚拟IP,当主服务器发生故障无法对外提供服务时,动态将这个虚IP切换到备用服务器。即实现服务器热备,故障自动切换,一般简称为VIP漂移。
- 虚拟IP的功能:
- 客户端访问数据库虚拟IP。
- 通过ARP缓存,找到对应的MAC地址。
- 访问真实服务器。
- VIP漂移流程:
- 如果真实服务A宕机。
- 真实服务器B没有收到真实服务器A的心跳包。
- 真实服务器B将虚拟IP绑定到自己的MAC地址,并发送这个ARP包给路由器。
- 路由器接收到后更新ARP缓存。
- 接着有请求虚拟IP的请求过来,都会被转发到真实服务器B。
而配置了 VIP漂移后的架构应该是由原来的一主两从,变成了互为主从这样的架构了。
初始由db01作为主节点,当主节点宕掉后,MHA Manager会自动选择合适的从库作为新的主节点。
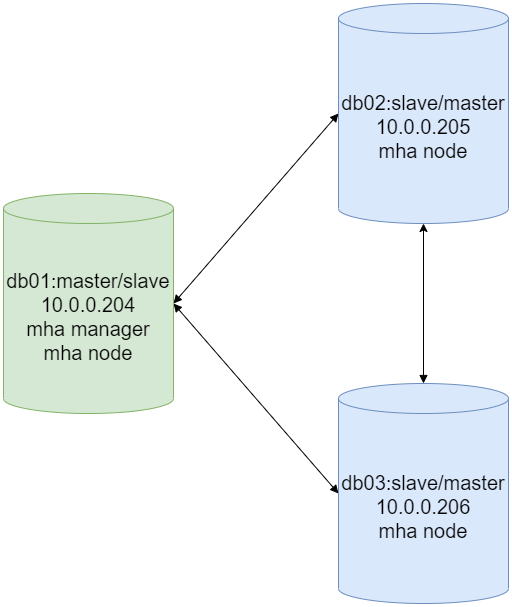
部署MHA高可用架构
部署基于GTID的主从复制架构
部署MySQL多实例参考: https://www.cnblogs.com/Neeo/articles/13527500.html
前提条件
关闭各节点所在服务器的的防火墙,并保证通信正常。
准备四台虚拟机
我这四台虚拟机都是新安装好的多实例,环境还是干净的。
下面关于四台虚拟机的基本配置。
db01:
[root@db01 ~]# hostnamectl set-hostname db01
[root@db01 ~]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
# 去掉UUID
#UUID=ed848b09-d61d-432d-811f-2ae62c7470a0
IPADDR=10.0.0.204
[root@db01 ~]# systemctl restart network
[root@db01 ~]# vim /etc/hosts
10.0.0.204 db01
[root@db01 ~]# ping www.baidu.com
[root@db01 ~]# bash
db02:
[root@db02 ~]# hostnamectl set-hostname db02
[root@db02 ~]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
# 去掉UUID
#UUID=ed848b09-d61d-432d-811f-2ae62c7470a0
IPADDR=10.0.0.205
[root@db02 ~]# systemctl restart network
[root@db02 ~]# vim /etc/hosts
10.0.0.205 db02
[root@db02 ~]# ping www.baidu.com
[root@db02 ~]# bash
db03:
[root@db03 ~]# hostnamectl set-hostname db03
[root@db03 ~]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
# 去掉UUID
#UUID=ed848b09-d61d-432d-811f-2ae62c7470a0
IPADDR=10.0.0.206
[root@db03 ~]# systemctl restart network
[root@db03 ~]# vim /etc/hosts
10.0.0.206 db03
[root@db03 ~]# ping www.baidu.com
[root@db03 ~]# bash
db04:
[root@db04 ~]# hostnamectl set-hostname db04
[root@db04 ~]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
# 去掉UUID
#UUID=ed848b09-d61d-432d-811f-2ae62c7470a0
IPADDR=10.0.0.207
[root@db04 ~]# systemctl restart network
[root@db04 ~]# vim /etc/hosts
10.0.0.207 db04
[root@db04 ~]# ping www.baidu.com
[root@db04 ~]# bash
配置四台MySQL的配置文件
db01:
cat > /etc/my.cnf <<EOF
[mysqld]
user=mysql
basedir=/opt/software/mysql
datadir=/data/mysql/3306/data
server_id=204
port=3306
socket=/tmp/mysql.sock
log_error=/data/mysql/3306/logs/mysql_error.log
secure-file-priv=/tmp
log_bin=/data/mysql/3306/logs/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
socket=/tmp/mysql.sock
prompt=db01 [\\d]>
user=root
password=123
EOF
# ------------------------ 创建binlog目录,然后启动MySQL服务 ----------
> /data/mysql/3306/data/auto.cnf
mkdir -p /data/mysql/3306/logs/binlog
chown -R mysql:mysql /data/mysql/3306/logs/binlog
systemctl start mysqld
mysql -uroot -p123 -e "select @@server_id"
db02:
cat > /etc/my.cnf <<EOF
[mysqld]
user=mysql
basedir=/opt/software/mysql
datadir=/data/mysql/3306/data
server_id=205
port=3306
socket=/tmp/mysql.sock
log_error=/data/mysql/3306/logs/mysql_error.log
secure-file-priv=/tmp
log_bin=/data/mysql/3306/logs/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
socket=/tmp/mysql.sock
prompt=db02 [\\d]>
user=root
password=123
EOF
# ------------------------ 创建binlog目录,然后启动MySQL服务 ----------
> /data/mysql/3306/data/auto.cnf
mkdir -p /data/mysql/3306/logs/binlog
chown -R mysql:mysql /data/mysql/3306/logs/binlog
systemctl start mysqld
mysql -uroot -p123 -e "select @@server_id"
db03:
cat > /etc/my.cnf <<EOF
[mysqld]
user=mysql
basedir=/opt/software/mysql
datadir=/data/mysql/3306/data
server_id=206
port=3306
socket=/tmp/mysql.sock
log_error=/data/mysql/3306/logs/mysql_error.log
secure-file-priv=/tmp
log_bin=/data/mysql/3306/logs/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
socket=/tmp/mysql.sock
prompt=db03 [\\d]>
user=root
password=123
EOF
# ------------------------ 创建binlog目录,然后启动MySQL服务 ----------
> /data/mysql/3306/data/auto.cnf
mkdir -p /data/mysql/3306/logs/binlog
chown -R mysql:mysql /data/mysql/3306/logs/binlog
systemctl start mysqld
mysql -uroot -p123 -e "select @@server_id"
db04:
cat > /etc/my.cnf <<EOF
[mysqld]
user=mysql
basedir=/opt/software/mysql
datadir=/data/mysql/3306/data
server_id=207
port=3306
socket=/tmp/mysql.sock
log_error=/data/mysql/3306/logs/mysql_error.log
secure-file-priv=/tmp
log_bin=/data/mysql/3306/logs/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
socket=/tmp/mysql.sock
prompt=db04 [\\d]>
user=root
password=123
EOF
# ------------------------ 创建binlog目录,然后启动MySQL服务 ----------
> /data/mysql/3306/data/auto.cnf
mkdir -p /data/mysql/3306/logs/binlog
chown -R mysql:mysql /data/mysql/3306/logs/binlog
systemctl start mysqld
mysql -uroot -p123 -e "select @@server_id"
注意,由于我的四台虚拟机是克隆出来的,而每个虚拟机中的MySQL都是配置好的,所以三台MySQL的uuid是一样的,但这样在后续的构建主从时,会报错:
Last_IO_Error: Fatal error:
The slave I/O thread stops because master and slave have equal MySQL server UUIDs;
these UUIDs must be different for replication to work.
所以,上面在每台MySQL服务启动之前,手动清空各自的uuid所在文件,当MySQL服务重启后,会自动在重新创建出来,达到uuid不重复的目的。
四个服务器上的MySQL安装完毕了,就可以进行主从复制了。
首先,由于我们是新环境,就免去全备主库这一步了。
1. 在主库db01创建专用复制用户
[root@db01 ~]# mysql -uroot -p123
grant replication slave on *.* to rs@'%' identified by '123';
2. 在三个从库db02、db03、db04构建主从关系
分别在db02、db03和db04节点,执行change master to语句,完事之后,查看主从状态是否正常:
CHANGE MASTER TO
MASTER_HOST='10.0.0.204',
MASTER_USER='rs',
MASTER_PASSWORD='123',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1;
start slave;
show slave status \G
[root@db02 ~]# mysql -uroot -p123
db02 [(none)]>show slave status \G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
[root@db03 ~]# mysql -uroot -p123
db03 [(none)]>show slave status \G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
[root@db04 ~]# mysql -uroot -p123
db04 [(none)]>show slave status \G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
OK,主从环境构建成功。
准备MHA高可用的环境
1. 创建软连接
MHA程序运行时,没有调用/etc/profile中的环境变量信息,而是调的/usr/bin中的相关软连接,所以,我们上来先把软件配置好。
在所有的节点上建立软连接:
ln -s /opt/software/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /opt/software/mysql/bin/mysql /usr/bin/mysql
2. 各节点进行互信配置
所谓互信就是通过配置密钥,让多个节点之间无密码访问。
首先在各节点都要执行删除原来的.ssh:
rm -rf /root/.ssh
然后,下面的操作在db01中进行操作:
ssh-keygen
cd /root/.ssh
mv id_rsa.pub authorized_keys
scp -r /root/.ssh 10.0.0.205:/root
scp -r /root/.ssh 10.0.0.206:/root
scp -r /root/.ssh 10.0.0.207:/root
配置完成后,四个节点都要进行验证,在每个节点输入下面命令,都能返回对应节点的hostname就行了:
ssh 10.0.0.204 hostname
ssh 10.0.0.205 hostname
ssh 10.0.0.206 hostname
ssh 10.0.0.207 hostname
上面执行验证时,根据提示输入yes或者回车。
install MHA Node
接下来,我们需要在各个节点上都安装上MHA Node软件。
- 下载依赖包,各节点都要下载:
yum install -y perl-DBD-MySQL
- 安装MHA Node软件,三个节点都要进行安装:
rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
到了这一步,四台从节点都配置好了。我们先把db04节点停掉,后续择机使用,先使用一主二从的架构
[root@db04 ~]# systemctl stop mysqld.service
install MHA Manager
我们只需要将MHA Manager软件包安装到主节点上,也就是db01节点。
- 下载依赖包:
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
- 安装MHA Manager软件包,我这里选择装在主库上,也就是db01上:
rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
- 在主库上创建mha专用监控管理用户,只在主库创建即可, 它会自动复制到从库:
-- 在主库上创建专用用户
grant all privileges on *.* to mha@'10.0.0.%' identified by 'mha';
-- 然后可以分别在从库中进行确认
select user,host from mysql.user;
- 在主库上创建mha manger的配置文件:
# 创建配置文件和日志目录
mkdir -p /etc/mha
mkdir -p /var/log/mha/node1
# 创建配置文件
cat > /etc/mha/node1.cnf <<EOF
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
repl_user=rs
repl_password=123
user=mha
password=mha
ping_interval=2
ssh_user=root
[server1]
hostname=10.0.0.204
port=3306
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
EOF
- 在主库中,使用MHA Manager提供的脚本验证各节点间的SSH互信:
[root@db01 tmp]# masterha_check_ssh --conf=/etc/mha/node1.cnf
Tue May 11 21:24:43 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue May 11 21:24:43 2021 - [info] Reading application default configuration from /etc/mha/node1.cnf..
Tue May 11 21:24:43 2021 - [info] Reading server configuration from /etc/mha/node1.cnf..
Tue May 11 21:24:43 2021 - [info] Starting SSH connection tests..
Tue May 11 21:24:45 2021 - [debug]
Tue May 11 21:24:43 2021 - [debug] Connecting via SSH from root@10.0.0.204(10.0.0.204:22) to root@10.0.0.205(10.0.0.205:22)..
Tue May 11 21:24:44 2021 - [debug] ok.
Tue May 11 21:24:44 2021 - [debug] Connecting via SSH from root@10.0.0.204(10.0.0.204:22) to root@10.0.0.206(10.0.0.206:22)..
Tue May 11 21:24:45 2021 - [debug] ok.
Tue May 11 21:24:47 2021 - [debug]
Tue May 11 21:24:44 2021 - [debug] Connecting via SSH from root@10.0.0.206(10.0.0.206:22) to root@10.0.0.204(10.0.0.204:22)..
Tue May 11 21:24:45 2021 - [debug] ok.
Tue May 11 21:24:45 2021 - [debug] Connecting via SSH from root@10.0.0.206(10.0.0.206:22) to root@10.0.0.205(10.0.0.205:22)..
Tue May 11 21:24:47 2021 - [debug] ok.
Tue May 11 21:24:47 2021 - [debug]
Tue May 11 21:24:43 2021 - [debug] Connecting via SSH from root@10.0.0.205(10.0.0.205:22) to root@10.0.0.204(10.0.0.204:22)..
Tue May 11 21:24:45 2021 - [debug] ok.
Tue May 11 21:24:45 2021 - [debug] Connecting via SSH from root@10.0.0.205(10.0.0.205:22) to root@10.0.0.206(10.0.0.206:22)..
Tue May 11 21:24:47 2021 - [debug] ok.
Tue May 11 21:24:47 2021 - [info] All SSH connection tests passed successfully.
看到successfully就表示成功了。
- 验证主从状态,主库执行:
[root@db01 tmp]# masterha_check_repl --conf=/etc/mha/node1.cnf
Tue May 11 21:39:15 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue May 11 21:39:15 2021 - [info] Reading application default configuration from /etc/mha/node1.cnf..
Tue May 11 21:39:15 2021 - [info] Reading server configuration from /etc/mha/node1.cnf..
Tue May 11 21:39:15 2021 - [info] MHA::MasterMonitor version 0.58.
Tue May 11 21:39:16 2021 - [info] GTID failover mode = 1
Tue May 11 21:39:16 2021 - [info] Dead Servers:
Tue May 11 21:39:16 2021 - [info] Alive Servers:
Tue May 11 21:39:16 2021 - [info] 10.0.0.204(10.0.0.204:3306)
Tue May 11 21:39:16 2021 - [info] 10.0.0.205(10.0.0.205:3306)
Tue May 11 21:39:16 2021 - [info] 10.0.0.206(10.0.0.206:3306)
Tue May 11 21:39:16 2021 - [info] Alive Slaves:
Tue May 11 21:39:16 2021 - [info] 10.0.0.205(10.0.0.205:3306) Version=5.7.20-log (oldest major version between slaves) log-bin:enabled
Tue May 11 21:39:16 2021 - [info] GTID ON
Tue May 11 21:39:16 2021 - [info] Replicating from 10.0.0.204(10.0.0.204:3306)
Tue May 11 21:39:16 2021 - [info] 10.0.0.206(10.0.0.206:3306) Version=5.7.20-log (oldest major version between slaves) log-bin:enabled
Tue May 11 21:39:16 2021 - [info] GTID ON
Tue May 11 21:39:16 2021 - [info] Replicating from 10.0.0.204(10.0.0.204:3306)
Tue May 11 21:39:16 2021 - [info] Current Alive Master: 10.0.0.204(10.0.0.204:3306)
Tue May 11 21:39:16 2021 - [info] Checking slave configurations..
Tue May 11 21:39:16 2021 - [info] read_only=1 is not set on slave 10.0.0.205(10.0.0.205:3306).
Tue May 11 21:39:16 2021 - [info] read_only=1 is not set on slave 10.0.0.206(10.0.0.206:3306).
Tue May 11 21:39:16 2021 - [info] Checking replication filtering settings..
Tue May 11 21:39:16 2021 - [info] binlog_do_db= , binlog_ignore_db=
Tue May 11 21:39:16 2021 - [info] Replication filtering check ok.
Tue May 11 21:39:16 2021 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.
Tue May 11 21:39:16 2021 - [info] Checking SSH publickey authentication settings on the current master..
Tue May 11 21:39:16 2021 - [info] HealthCheck: SSH to 10.0.0.204 is reachable.
Tue May 11 21:39:16 2021 - [info]
10.0.0.204(10.0.0.204:3306) (current master)
+--10.0.0.205(10.0.0.205:3306)
+--10.0.0.206(10.0.0.206:3306)
Tue May 11 21:39:16 2021 - [info] Checking replication health on 10.0.0.205..
Tue May 11 21:39:16 2021 - [info] ok.
Tue May 11 21:39:16 2021 - [info] Checking replication health on 10.0.0.206..
Tue May 11 21:39:16 2021 - [info] ok.
Tue May 11 21:39:16 2021 - [warning] master_ip_failover_script is not defined.
Tue May 11 21:39:16 2021 - [warning] shutdown_script is not defined.
Tue May 11 21:39:16 2021 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
- 启动MHA Manager:
nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/node1/manager.log 2>&1 &
程序在后台运行,我们可以通过下一步进行确认,是否运行成功。
- 检查MHA的工作状态,主库执行:
[root@db01 tmp]# masterha_check_status --conf=/etc/mha/node1.cnf
node1 (pid:3205) is running(0:PING_OK), master:10.0.0.204
OK,到这一步,MHA的基础环境搭建完毕。
其他命令:
# 关闭Manager进程
masterha_stop --conf=/etc/mha/node1.cnf
MHA高可用架构的工作原理
一次故障转移过程
这一小节,我们来探讨MHA高可用架构,在遇到主库宕机后,自动故障切换的过程。
1. 选取备选主节点
当正在运行的主库突然宕机了,MAH会从两个从库中选取出一个主节点,那么选举主节点的算法是什么呢?
- 根据两个从库的position或者GITD号,选择一个最接近原主库的那个从库当作备选主节点,这个算法比较简单,但是问题也是有的,就是这个策略适用于两个从库的数据存在差异时才有用。
- 如果两个从库的数据是一致的时候,就会根据我们在配置文件中的配置顺序的上下关系,选择上面的从库当作备选主节点,如下面的配置文件中,server2在server3上面,那么server2就会成为备选主节点。
[root@db01 ~]# cat /etc/mha/node1.cnf
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
user=mha
password=mha
ping_interval=2
repl_password=123
repl_user=rs
ssh_user=root
[server1]
hostname=10.0.0.204
port=3306
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
- 如果设定有权重(
candidate_master=1),就按照权重强制指定备选主节点。注意,当设置了权重之后,也会有权重失效的情况:- 默认情况下,如果设有权重的从库落后主库100M的relay logs的话,权重失效!因为数据太"老"了。
- 如果设置了
check_repl_delay=0的话,即使当前从库落后日志,也强制会被当作为备选主节点。 - 这里提到的两个参数,都可以在配置文件中设置,我们后续再说。
无论上面选举过程中经过了什么样的"py"交易,总算选取出一个备选主节点了,那它就直接走马上任了?就能对外提供服务了?不是的,还要经过一个数据补偿的阶段,也就是希望追平数据。
2. 数据补偿
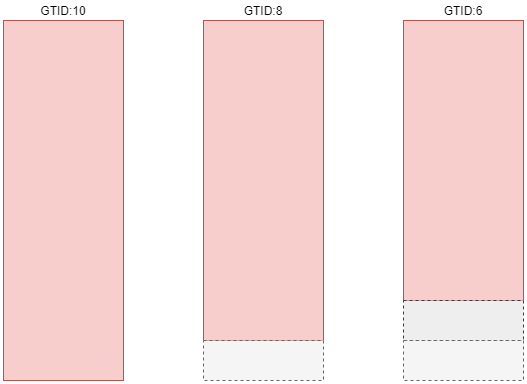
在数据补偿这个阶段中,也有两种情况:
- 当前选举出的备选主节点,能通过ssh连接到原主库上:
- 那就直接进行通过对比GTID或者position号,将二进制日志回放到当前的各个节点上(save_binary_logs脚本来完成),完成数据补偿的过程。
- 然后执行整体流程的第3、4、5步骤,完成故障迁移的整体流程。
- 另一种就是无法通过ssh连接到原主库上,那该怎么办?
- 对比从库之间的relaylog的差异(apply_diff_relay_logs脚本来完成),追平现有的数据,至于丢失的哪部分,没招了.....
- 真没招了么?答案还是有的那就是第6步骤中的操作,二次数据补偿。
3. 故障转移Failover
备选主节点升级为主节点。
和其余从库确认新的主从关系后,对外提供服务。
将故障节点踢出集群。
4. 应用透明(VIP)
MAH自带应用透明技术,就是利用vip技术,当主库宕机后,就将原来主库上的vip切换到新主上。
此时,算是基本上完成了一次故障转移的流程,但没完!
5. 故障转移通知(send_report)
目前的MHA是一个一次性高可用,即部署成功后,它只能完成一次故障转移的工作,这就意味着,当故障转移工作完成后,要及时通知数据库的管理员,对MHA架构进行维护,不然下次再故障,就没法自动的故障转移了。
6. 二次数据补偿(binlog_server)
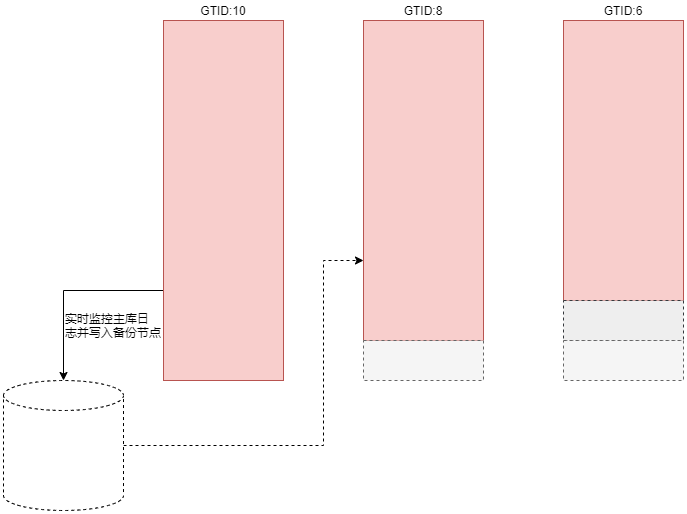
为了防止主库宕了,新的备选主节点也连不上原主节点,导致可能有一部分数据(没来得同步,主库就宕了)"丢失"。
所以,在构建MHA高可用架构时,就准备一个节点,这里称之为备份节点,专门用来实时的保存主库的二进制日志,当主库宕了,从库无法连接主库,就从备份节点中回放二进制日志,这样,"丢失"的数据就找回来了,这就很6了啊。
当然,你非要说万一备份节点也宕了呢.........
关于candidate_master=1参数的补充
该参数应用场景:
-
两地三中心,比如北京中关村机房、北京亦庄机房、天津机房,当北京的中观村的主节点宕了,那么我们最希望主节点切换到北京的亦庄机房去,所以通过该参数来增加权重,避免"一不小心"切换到了天津机房了。
-
在应用透明中,如果是keep alive架构实现的vip,就需要加权重切换vip所在的服务器上了,否则切换到一个普通的从库服务器,会影响到业务正常使用。
另外,我们刚刚搭建的MHA高可用架构,目前仅能支持到数据补偿和故障切换功能,后续功能暂未提供,所以,不能直接上生产环境。
MHA故障模拟及恢复
依据现在MHA高可用架构,如果主库宕掉,预期的结果:
- db02节点会成为新的主节点,这是因为当前三个节点中的数据都是一致的,那么选举时,又没有设置权重,就根据配置文件节点设置先后顺序来决定谁成为新的主节点,我们的配置文件中,db02在db03上面。
- db03会成为db02的从库。
- db01会被踢出集群。
- MHA在自动完成故障恢复后,宕掉了,谁让这个家伙只能搞一次故障转移过程呢.....
故障模拟
此时的主库是db01节点:
[root@db02 ~]# mysql -uroot -p123
db01 [(none)]>show slave status \G
Master_Host: 10.0.0.204
此时的MHA Manager的配置文件:
[root@db01 ~]# cat /etc/mha/node1.cnf
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
user=mha
password=mha
ping_interval=2
repl_password=123
repl_user=rs
ssh_user=root
[server1]
hostname=10.0.0.204
port=3306
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
1. 模拟主库(db01)节点宕机
在当前的主库中,即db01节点宕掉MySQL:
# 这里你可以新开一个db01的窗口,监控MHA Manager的日志信息,观察整个故障转移过程中都做了哪些事儿
[root@db01 ~]# tail -f /var/log/mha/node1/manager
# 正常模拟主库宕机场景
[root@db01 ~]# netstat -lnp|grep 330
tcp6 0 0 :::3306 :::* LISTEN 1246/mysqld
[root@db01 ~]# pkill mysqld
[root@db01 ~]# netstat -lnp|grep 330
[root@db01 ~]#
2. 确认各个状态
db02成为新的主节点:
# 在db02中访问slave状态为空
[root@db02 ~]# mysql -uroot -p
db02 [(none)]>show slave status \G
Empty set (0.00 sec)
# 在db03中访问主从环境状态
[root@db03 ~]# mysql -uroot -p123
db03 [(none)]>show slave status \G
Master_Host: 10.0.0.205
MHA宕掉了:
# 在db01执行
[root@db01 ~]# masterha_check_status --conf=/etc/mha/node1.cnf
node1 is stopped(2:NOT_RUNNING).
[1]+ Done nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/node1/manager.log 2>&1
db01节点被提出集群,从哪体现呢?可以从配置文件中体现:
# 在db01中查看MHA Manager的配置文件,发现关于server1的相关信息没了
[root@db01 ~]# cat /etc/mha/node1.cnf
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
password=mha
ping_interval=2
repl_password=123
repl_user=rs
ssh_user=root
user=mha
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
也可以去看MHA Manager的日志信息:
# 这里截取部分日志信息 /var/log/mha/node1/manager
Wed May 12 00:45:38 2021 - [info] Executed CHANGE MASTER.
Wed May 12 00:45:39 2021 - [info] Slave started.
Wed May 12 00:45:39 2021 - [info] gtid_wait(bbcbb587-b0aa-11eb-a2ce-000c295ead38:1,
ce532bca-b1ad-11eb-a297-000c298ffc47:1-2) completed on 10.0.0.206(10.0.0.206:3306). Executed 0 events.
Wed May 12 00:45:40 2021 - [info] End of log messages from 10.0.0.206.
Wed May 12 00:45:40 2021 - [info] -- Slave on host 10.0.0.206(10.0.0.206:3306) started.
Wed May 12 00:45:40 2021 - [info] All new slave servers recovered successfully.
Wed May 12 00:45:40 2021 - [info]
Wed May 12 00:45:40 2021 - [info] * Phase 5: New master cleanup phase..
Wed May 12 00:45:40 2021 - [info]
Wed May 12 00:45:40 2021 - [info] Resetting slave info on the new master..
Wed May 12 00:45:40 2021 - [info] 10.0.0.205: Resetting slave info succeeded.
Wed May 12 00:45:40 2021 - [info] Master failover to 10.0.0.205(10.0.0.205:3306) completed successfully.
Wed May 12 00:45:40 2021 - [info] Deleted server1 entry from /etc/mha/node1.cnf .
Wed May 12 00:45:40 2021 - [info]
----- Failover Report -----
node1: MySQL Master failover 10.0.0.204(10.0.0.204:3306) to 10.0.0.205(10.0.0.205:3306) succeeded
Master 10.0.0.204(10.0.0.204:3306) is down!
Check MHA Manager logs at db01:/var/log/mha/node1/manager for details.
Started automated(non-interactive) failover.
Selected 10.0.0.205(10.0.0.205:3306) as a new master.
10.0.0.205(10.0.0.205:3306): OK: Applying all logs succeeded.
10.0.0.206(10.0.0.206:3306): OK: Slave started, replicating from 10.0.0.205(10.0.0.205:3306)
10.0.0.205(10.0.0.205:3306): Resetting slave info succeeded.
Master failover to 10.0.0.205(10.0.0.205:3306) completed successfully.
故障修复
1. 修复db01节点
我们这里只需要重启MySQL即可:
[root@db01 ~]# netstat -lnp|grep 330
[root@db01 ~]# systemctl start mysqld
[root@db01 ~]# netstat -lnp|grep 330
tcp6 0 0 :::3306 :::* LISTEN 7189/mysqld
当然,如果开发中要根据情况进行修复,比如重新初始化构建主从之类的。
2. 重新构建db01的主从关系
change master to语句,我们可以去MHA Manager的日志中找回来:
Wed May 12 00:45:38 2021 - [info] * Phase 3.3: New Master Recovery Phase..
Wed May 12 00:45:38 2021 - [info]
Wed May 12 00:45:38 2021 - [info] Waiting all logs to be applied..
Wed May 12 00:45:38 2021 - [info] done.
Wed May 12 00:45:38 2021 - [info] Getting new master's binlog name and position..
Wed May 12 00:45:38 2021 - [info] mysql-bin.000003:234
Wed May 12 00:45:38 2021 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.0.0.205', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rs', MASTER_PASSWORD='xxx';
Wed May 12 00:45:38 2021 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: mysql-bin.000003, 234, bbcbb587-b0aa-11eb-a2ce-000c295ead38:1,
ce532bca-b1ad-11eb-a297-000c298ffc47:1-2
Wed May 12 00:45:38 2021 - [warning] master_ip_failover_script is not set. Skipping taking over new master IP address.
从上面的日志中找到下面示例的哪一行,然后修改密码,因为记录中替换了。
CHANGE MASTER TO MASTER_HOST='10.0.0.205', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rs', MASTER_PASSWORD='123';
现在,在db01的MySQL中构建主从关系吧:
CHANGE MASTER TO
MASTER_HOST='10.0.0.205',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1,
MASTER_USER='rs',
MASTER_PASSWORD='123';
start slave;
show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.205
Master_User: rs
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 234
Relay_Log_File: db01-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
3. 修改MHA Manager的配置文件
因为在故障模拟时,MHA Manager将db01节点踢出了,现在我们要给它手动加回来,因为我们后面再启动mha会用到:
[root@db01 ~]# vim /etc/mha/node1.cnf
[root@db01 ~]# cat /etc/mha/node1.cnf
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
user=mha
password=mha
ping_interval=2
repl_password=123
repl_user=rs
ssh_user=root
[server1]
hostname=10.0.0.204
port=3306
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
4. 启动MHA Manager
db01中执行:
nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/node1/manager.log 2>&1 &
masterha_check_status --conf=/etc/mha/node1.cnf
# 示例
[root@db01 ~]# nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/node1/manager.log 2>&1 &
[1] 7227
[root@db01 ~]# masterha_check_status --conf=/etc/mha/node1.cnf
node1 (pid:7227) is running(0:PING_OK), master:10.0.0.205
OK了,现在MHA高可用环境恢复如初......就是主节点从db01转移到了db02了。
VIP应用透明
VIP应用透明配置
1. 编辑vip的配置文件
在manager所在节点,也就是db01中进行操作:
[root@db01 ~]# yum install -y dos2unix net-tools
[root@db01 ~]# vim /usr/local/bin/master_ip_failover # 脚本位置可以自定义
[root@db01 ~]# dos2unix /usr/local/bin/master_ip_failover # 把文件中可能的中文字符替换为Linux字符
[root@db01 ~]# chmod +x /usr/local/bin/master_ip_failover
[root@db01 ~]# cat /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
# Copyright (C) 2011 DeNA Co.,Ltd.
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
my (
$command, $ssh_user, $orig_master_host,
$orig_master_ip, $orig_master_port, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password
);
my $vip = '10.0.0.100/24';
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
);
exit &main();
sub main {
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
# updating global catalog, etc
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
`ssh $ssh_user\@$orig_master_host \" $ssh_start_vip \"`;
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
这个文件内容,我们需要对下面的几个参数根据自己的环境进行相应修改:
my $vip = '10.0.0.100/24';
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
各参数:
$vip:和对外提供服务的网卡的IP处于同一网段;但IP又必须是空闲的。$key:将来会生成临时的虚拟网卡,网卡名叫做eth0:1、eth0:1,它对应的是冒号后的序号。$ssh_start_vip和$ssh_stop_vip:启动/停止vip的脚本,对应的是虚拟网卡。
其实说白了,就是这个脚本会启动一个临时的虚拟网卡(重启系统或者重启网卡,这个虚拟网卡就没了),然后绑定到这个网卡上面:
[root@db01 ~]# ifconfig eth0:1 10.0.0.100/24
[root@db01 ~]# ifconfig
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.100 netmask 255.255.255.0 broadcast 10.0.0.255
ether 00:0c:29:8f:fc:47 txqueuelen 1000 (Ethernet)
[root@db01 ~]# ifconfig eth0:1 down # down掉这个虚拟网卡
2. 修改manager的配置文件,让其能够读到vip的配置文件
db01:
[root@db01 ~]# vim /etc/mha/node1.cnf
[root@db01 ~]# cat /etc/mha/node1.cnf
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
password=mha
ping_interval=2
repl_password=123
repl_user=rs
ssh_user=root
user=mha
# 就下面这一行
master_ip_failover_script=/usr/local/bin/master_ip_failover
[server1]
hostname=10.0.0.204
port=3306
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
3. 应用vip
这里面有个细节需要注意:这个脚本只有在故障(MAH故障切换)的时候才会被调用,所以首次(后续就不用管了)配置vip的时候,需要在主库中手动生成vip。如何生成呢?
注意啊,此时一定要确保是在主库中进行操作,我这里原主库是db01,但经过上面的模拟故障修复后,新的主库是db02,所以我需要在db02中进行操作:
[root@db02 ~]# ifconfig eth0:1 10.0.0.100/24
[root@db02 ~]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.205 netmask 255.255.255.0 broadcast 10.0.0.255
inet6 fe80::20c:29ff:fe4b:b55c prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:4b:b5:5c txqueuelen 1000 (Ethernet)
RX packets 38403 bytes 2606072 (2.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 10412 bytes 1180149 (1.1 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.100 netmask 255.255.255.0 broadcast 10.0.0.255
ether 00:0c:29:4b:b5:5c txqueuelen 1000 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
4. 重启manager
在db01中进行操作:
[root@db01 ~]# nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/node1/manager.log 2>&1 &
[1] 12125
[root@db01 ~]# masterha_check_status --conf=/etc/mha/node1.cnf
node1 (pid:12125) is running(0:PING_OK), master:10.0.0.205
现在,vip功能就配置成功了。
既然配置好了VIP功能,我们就要测下好不好使,怎么测试呢?也简单,就是手动宕掉主库,然后观察VIP的漂移结果。
VIP故障模拟
预期结果
- 主从环境是好的。
- MHA高可用架构也是可用的。
- 三台节点的数据是一致的,这意味着如果主库宕掉(此时主库是db02),那么db01的从库会被升级为主库,谁让它在manager配置文件中的位置比db03高呢!
- db01升级为主库,db02宕机,db03和db01组成新的主从关系。
- MHA Manager的配置文件中清除db02的节点信息。
- MHA Manager也会退出。
- VIP应该漂移到了db01上。
1. 查看db01的网卡信息
既然我们预期当db02的主库宕掉后,VIP会漂移到db01上,所以,我们先来看下db01此时网卡信息:
[root@db01 ~]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.204 netmask 255.255.255.0 broadcast 10.0.0.255
inet6 fe80::20c:29ff:fe8f:fc47 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:8f:fc:47 txqueuelen 1000 (Ethernet)
RX packets 48216 bytes 12171593 (11.6 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 24052 bytes 2344078 (2.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 15910 bytes 1279833 (1.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 15910 bytes 1279833 (1.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
现在还没有虚拟网卡,所以,接下来,我们宕掉主库。
2. 宕掉db02主库
db02:
[root@db02 ~]# systemctl stop mysqld.service
[root@db02 ~]# netstat -lnp|grep 330
[root@db02 ~]#
3. 确认结果是否符合预期
确认VIP是否按照预期漂移到了db01节点上:
[root@db01 ~]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.204 netmask 255.255.255.0 broadcast 10.0.0.255
inet6 fe80::20c:29ff:fe8f:fc47 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:8f:fc:47 txqueuelen 1000 (Ethernet)
RX packets 48503 bytes 12231171 (11.6 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 24305 bytes 2374330 (2.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.100 netmask 255.255.255.0 broadcast 10.0.0.255
ether 00:0c:29:8f:fc:47 txqueuelen 1000 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 16102 bytes 1335408 (1.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 16102 bytes 1335408 (1.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[1]+ Done nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/node1/manager.log 2>&1
可以看到,VIP按照预期漂移到当前节点上了,而且通过最后一行打印信息,说明MHA Manager也宕掉了,因为它已经完成了故障转移任务。
db02的节点信息也应该从MHA Manager的配置文件中删除了。
db01:
[root@db01 ~]# cat /etc/mha/node1.cnf
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
master_ip_failover_script=/usr/local/bin/master_ip_failover
password=mha
ping_interval=2
repl_password=123
repl_user=rs
ssh_user=root
user=mha
[server1]
hostname=10.0.0.204
port=3306
[server3]
hostname=10.0.0.206
port=3306
符合预期。
再来看db03的主从状态:
[root@db03 ~]# mysql -uroot -p123
db03 [(none)]>show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.204
Master_User: rs
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 234
Relay_Log_File: db03-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Master_Host是db01的IP地址,同样符合预期。
OK了, 各种状态都符合预期,是时候恢复db02了。
VIP故障恢复
恢复也容易,之前做过了,套路就是重启db02节点的MySQL实例,然后重新构建主从关系,修改MHA Manager的配置文件,重启mha manger就完了。
1. 重启db02节点的MySQL实例
db02:
[root@db02 ~]# netstat -lnp|grep 330
[root@db02 ~]# systemctl start mysqld
[root@db02 ~]# netstat -lnp|grep 330
tcp6 0 0 :::3306 :::* LISTEN 2314/mysqld
2. 重新构建与db01的主从关系
还是老套路,change master to信息去manger日志中找,你也可以自己手扣!
db01:
[root@db01 ~]# cat /var/log/mha/node1/manager
CHANGE MASTER TO
MASTER_HOST='10.0.0.204',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1,
MASTER_USER='rs',
MASTER_PASSWORD='123';
将密码一改,就可以在db02中进行主从关系构建了。
db02:
[root@db02 ~]# mysql -uroot -p123
db02 [(none)]>show slave status \G
Empty set (0.00 sec)
db02 [(none)]>CHANGE MASTER TO
-> MASTER_HOST='10.0.0.204',
-> MASTER_PORT=3306,
-> MASTER_AUTO_POSITION=1,
-> MASTER_USER='rs',
-> MASTER_PASSWORD='123';
Query OK, 0 rows affected, 2 warnings (0.01 sec)
db02 [(none)]>start slave;
Query OK, 0 rows affected (0.00 sec)
db02 [(none)]>show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.204
Master_User: rs
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 234
Relay_Log_File: db02-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
ok,执行没有问题。
3. 恢复mha manger
之前的故障恢复中,MHA Manager将db02的节点信息删掉了,所以,我们先要从新将db02接待信息添加到配置文件中去。
db01:
[root@db01 ~]# vim /etc/mha/node1.cnf
[root@db01 ~]# cat /etc/mha/node1.cnf
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
master_ip_failover_script=/usr/local/bin/master_ip_failover
password=mha
ping_interval=2
repl_password=123
repl_user=rs
ssh_user=root
user=mha
[server1]
hostname=10.0.0.204
port=3306
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
然后,重启MHA Manager服务。
db01:
nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/node1/manager.log 2>&1 &
masterha_check_status --conf=/etc/mha/node1.cnf
[root@db01 ~]# nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/node1/manager.log 2>&1 &
[1] 14021
[root@db01 ~]# masterha_check_status --conf=/etc/mha/node1.cnf
node1 (pid:14021) is running(0:PING_OK), master:10.0.0.204
ok了,一切恢复如初了。
故障提醒
所谓的故障提醒也就是,当检测到主库宕机后,在MHA自动故障转移后,给指定邮件发送故障提醒的功能。
而故障提醒的功能实现,也就是写个Perl脚本,然后在MHA Manager配置文件中进行配置下就完了。而Perl脚本网上也随处可见,这里不在多表。
邮件配置
来看配置吧。
1. 环境确认
此时,我的MHA Manager是好的,主库在db01服务器上,db01:
[root@db01 ~]# mysql -uroot -p123
db01 [(none)]>show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 206 | | 3306 | 204 | 16d77e8b-b257-11eb-95b5-000c29b09d3c |
| 205 | | 3306 | 204 | ef2baccd-b1ad-11eb-a0fb-000c294bb55c |
+-----------+------+------+-----------+--------------------------------------+
2 rows in set (0.00 sec)
2. 配置脚本和安装依赖
将下面的cat内容,按照示例创建在/usr/local/bin中,文件名可以自定义,我这里叫做master_send_report,注意,文件中不允许有中文。
都在db01中执行:
[root@db01 ~]# vim /usr/local/bin/master_send_report
[root@db01 ~]# sed -i 's/\r$//' /usr/local/bin/master_send_report
[root@db01 ~]# dos2unix /usr/local/bin/master_send_report
dos2unix: converting file /usr/local/bin/master_send_report to Unix format ...
[root@db01 ~]# chmod +x /usr/local/bin/master_send_report
[root@db01 ~]# cat /usr/local/bin/master_send_report
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Email::Simple;
use Email::Sender::Simple qw(sendmail);
use Email::Sender::Transport::SMTP::TLS;
use Getopt::Long;
#new_master_host and new_slave_hosts are set only when recovering master succeeded
my ( $dead_master_host, $new_master_host, $new_slave_hosts, $subject, $body );
my $smtp='smtp.qq.com'; # QQ的第三方服务器
my $mail_from='1206180814@qq.com'; # 发件人
my $mail_user='1206180814@qq.com'; # 登录邮箱
my $mail_pass='nvhtgzztdsqmhbdf'; # 授权令牌
my $mail_to='1206180814@qq.com'; # 收件人
GetOptions(
'orig_master_host=s' => \$dead_master_host,
'new_master_host=s' => \$new_master_host,
'new_slave_hosts=s' => \$new_slave_hosts,
'subject=s' => \$subject,
'body=s' => \$body,
);
mailToContacts($smtp,$mail_from,$mail_user,$mail_pass,$mail_to,$subject,$body);
mailToContacts();
sub mailToContacts {
my ( $smtp, $mail_from, $user, $passwd, $mail_to, $subject, $msg ) = @_;
open my $DEBUG, "> /var/log/mha/node1/mail.log"
or die "Can't open the debug file:$!\n";
my $transport = Email::Sender::Transport::SMTP::TLS->new(
host => 'smtp.qq.com',
port => 25,
username => '1206180814@qq.com', # 登录邮箱
password => 'nvhtgzztdsqmhbdf', # 授权令牌
);
my $message = Email::Simple->create(
header => [
From => '1206180814@qq.com', # 发件人
To => '1206180814@qq.com', # 收件人
Subject => 'MHA-manager(10.0.0.100) ERROR' # 邮件的主题
],
body =>$body, # 这里邮件正文,将来会自动读取MHA的日志信息,如果是发送测试邮件的话,正文为空
);
sendmail( $message, {transport => $transport} );
return 1;
}
# Do whatever you want here
exit 0;
为了避免出现报错,下载Perl的相关功能模块:
[root@db01 ~]# yum -y install cpan
[root@db01 ~]# cpan install Email::Simple
CPAN.pm requires configuration, but most of it can be done automatically.
If you answer 'no' below, you will enter an interactive dialog for each
configuration option instead.
# 启用自动配置
Would you like to configure as much as possible automatically? [yes] # 输入 yes
<install_help>
Warning: You do not have write permission for Perl library directories.
To install modules, you need to configure a local Perl library directory or
escalate your privileges. CPAN can help you by bootstrapping the local::lib
module or by configuring itself to use 'sudo' (if available). You may also
resolve this problem manually if you need to customize your setup.
# 选择 local::lib 在本地下载
What approach do you want? (Choose 'local::lib', 'sudo' or 'manual')
[local::lib] local::lib # 输入 local::lib
Autoconfigured everything but 'urllist'.
Now you need to choose your CPAN mirror sites. You can let me
pick mirrors for you, you can select them from a list or you
can enter them by hand.
# 连接互联网下载所需依赖关系
Would you like me to automatically choose some CPAN mirror
sites for you? (This means connecting to the Internet) [yes] # 输入 yes
Trying to fetch a mirror list from the Internet
Fetching with HTTP::Tiny:
http://www.perl.org/CPAN/MIRRORED.BY
Looking for CPAN mirrors near you (please be patient)
. done!
# 将其加入到 root/bashrc
Would you like me to append that to /root/.bashrc now? [yes] # 输入 yes
commit: wrote '/root/.cpan/CPAN/MyConfig.pm'
You can re-run configuration any time with 'o conf init' in the CPAN shell
Running install for module 'Test::More'
Running make for E/EX/EXODIST/Test-Simple-1.302183.tar.gz
Fetching with HTTP::Tiny:
http://www.cpan.org/authors/id/E/EX/EXODIST/Test-Simple-1.302183.tar.gz
# 继续安装其他依赖包
[root@db01 ~]# cpan install Email::Sender::Simple
[root@db01 ~]# cpan install Email::Sender::Transport::SMTP::TLS
3. 测试是否配置成功
在终端手动调用发送邮件的脚本,确认能否发送邮件:
[root@db01 ~]# /usr/local/bin/master_send_report # 没有结果返回表示发送成功了
[root@db01 ~]#
邮件接收到了:

[root@db01 ~]# masterha_check_repl --conf=/etc/mha/node1.cnf
.....省略
MySQL Replication Health is OK.
然后,我们手动停下
但是有个问题,测试时,每次都会发送两次.....问题,正在排查,但不妨碍我们完成后续的告警配置。
4. MHA Manager配置文件中配置发邮件相关参数
db01:
[root@db01 ~]# vim /etc/mha/node1.cnf
[root@db01 ~]# cat /etc/mha/node1.cnf
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
master_ip_failover_script=/usr/local/bin/master_ip_failover
report_script=/usr/local/bin/master_send_report # 就是这一行
password=mha
ping_interval=2
repl_password=123
repl_user=rs
ssh_user=root
user=mha
[server1]
hostname=10.0.0.204
port=3306
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
现在,邮件配置完事了,但真的好使么,还需要我们模拟一下真实的故障,看在故障中能否正常的发邮件。
模拟故障
1. 确认环境
还是老套路,确认MHA的各种状态,此时我的主库在db01中:
[root@db01 ~]# ifconfig
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.100 netmask 255.255.255.0 broadcast 10.0.0.255
ether 00:0c:29:8f:fc:47 txqueuelen 1000 (Ethernet)
[root@db01 ~]# masterha_check_status --conf=/etc/mha/node1.cnf
node1 (pid:37437) is running(0:PING_OK), master:10.0.0.204
[root@db01 ~]# masterha_check_repl --conf=/etc/mha/node1.cnf
....省略
MySQL Replication Health is OK.
[root@db01 ~]# mysql -uroot -p123
db01 [(none)]>show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 206 | | 3306 | 204 | 16d77e8b-b257-11eb-95b5-000c29b09d3c |
| 205 | | 3306 | 204 | ef2baccd-b1ad-11eb-a0fb-000c294bb55c |
+-----------+------+------+-----------+--------------------------------------+
2 rows in set (0.00 sec)
2. 手动模拟故障
即在db01中,手动关闭MySQL服务:
[root@db01 ~]# netstat -lnp|grep 330
tcp6 0 0 :::3306 :::* LISTEN 36927/mysqld
[root@db01 ~]# systemctl stop mysqld.service
[root@db01 ~]# netstat -lnp|grep 330
3. 确认各种状态
邮件发送成功:
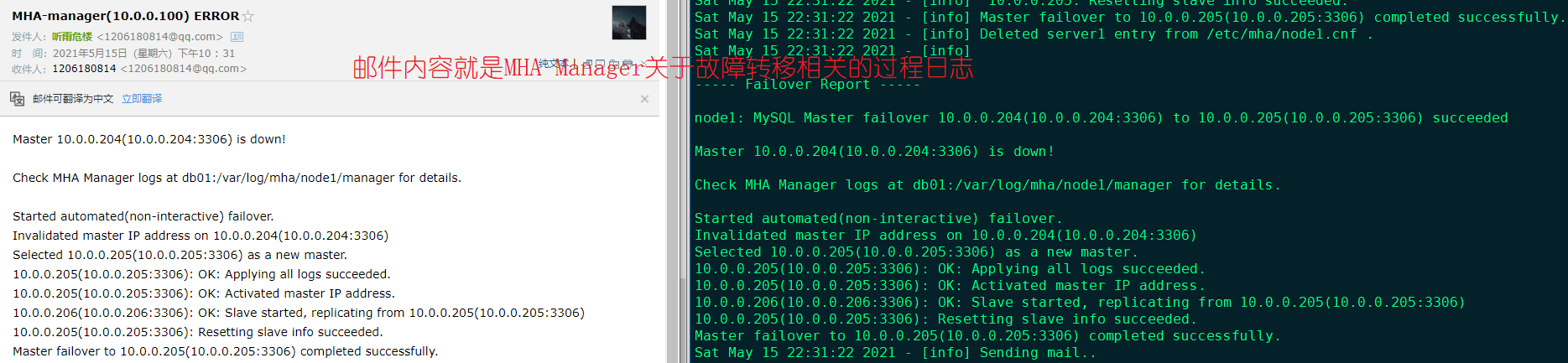
根据邮件内容,确认此时的主库转移到了db02中:
[root@db02 ~]# mysql -uroot -p123
db02 [(none)]>show slave hosts; # 由于db01的原主库宕了,这里只显示了db03的从库hosts信息
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 206 | | 3306 | 205 | 16d77e8b-b257-11eb-95b5-000c29b09d3c |
+-----------+------+------+-----------+--------------------------------------+
1 row in set (0.00 sec)
[root@db02 bin]# ifconfig # vip也漂移到db02中了
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.205 netmask 255.255.255.0 broadcast 10.0.0.255
inet6 fe80::20c:29ff:fe4b:b55c prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:4b:b5:5c txqueuelen 1000 (Ethernet)
RX packets 112101 bytes 7577531 (7.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 25143 bytes 2916256 (2.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
db03中的从库也正常连接到了db02主库:
[root@db03 ~]# mysql -uroot -p123
db03 [(none)]>show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.205
Master_User: rs
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000008
Read_Master_Log_Pos: 234
Relay_Log_File: db03-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000008
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
OK了,配置邮箱告警完毕。
故障恢复
啥也别说了,恢复吧!
1. db01从库配置
由于db01是原主库,所以,我们主要的配置工作就db01中,首先,由于MHA Manager在自动故障恢复中会把原主库移除集群,这里我们先把它db01的配置加回来:
[root@db01 ~]# vim /etc/mha/node1.cnf
[root@db01 ~]# cat /etc/mha/node1.cnf
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
master_ip_failover_script=/usr/local/bin/master_ip_failover
password=mha
ping_interval=2
repl_password=123
repl_user=rs
report_script=/usr/local/bin/master_send_report
ssh_user=root
user=mha
# 就是下面的sever1
[server1]
hostname=10.0.0.204
port=3306
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
然后重启db01的MySQL服务,然后构建主从关系:
[root@db01 ~]# netstat -lnp|grep 330
[root@db01 ~]# systemctl start mysqld.service
[root@db01 ~]# netstat -lnp|grep 330
tcp6 0 0 :::3306 :::* LISTEN 38335/mysqld
[root@db01 ~]# mysql -uroot -p123
CHANGE MASTER TO
MASTER_HOST='10.0.0.205',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1,
MASTER_USER='rs',
MASTER_PASSWORD='123';
start slave;
show slave status \G
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.205
Master_User: rs
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000008
Read_Master_Log_Pos: 234
Relay_Log_File: db01-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000008
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
这个时候,我们去db02中再确认下:
[root@db02 ~]# mysql -uroot -p123
db02 [(none)]>show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 206 | | 3306 | 205 | 16d77e8b-b257-11eb-95b5-000c29b09d3c |
| 204 | | 3306 | 205 | ce532bca-b1ad-11eb-a297-000c298ffc47 |
+-----------+------+------+-----------+--------------------------------------+
2 rows in set (0.00 sec)
2. 开启MHA Manger
既然主从关系都没问题了,我们开启MHA Manger就完了,db01:
nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/node1/manager.log 2>&1 &
masterha_check_status --conf=/etc/mha/node1.cnf
masterha_check_repl --conf=/etc/mha/node1.cnf
[root@db01 ~]# nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/node1/manager.log 2>&1 &
[1] 38372
[root@db01 ~]# masterha_check_status --conf=/etc/mha/node1.cnf
node1 (pid:38372) is running(0:PING_OK), master:10.0.0.205
[root@db01 ~]# masterha_check_repr --conf=/etc/mha/node1.cnf
-bash: masterha_check_repr: command not found
[root@db01 ~]# masterha_check_repl --conf=/etc/mha/node1.cnf
......省略
MySQL Replication Health is OK.
OK了,都完事了。
MHA Binlog Server
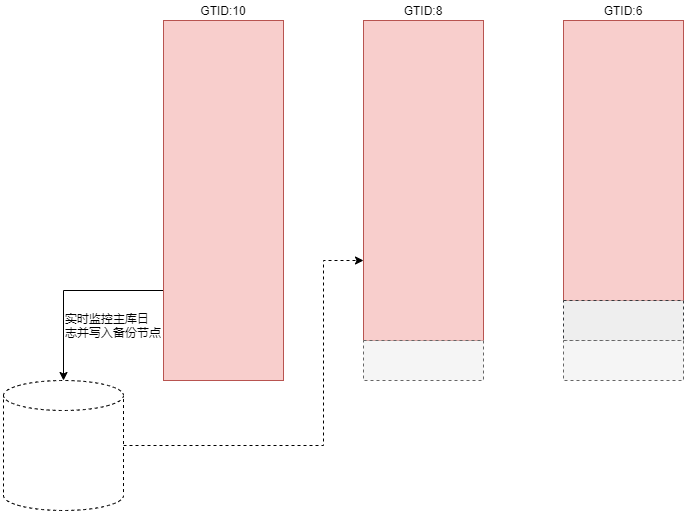
还记得在MHA高可用架构的工作原理部分,讲的二次数据补偿么?也就是当新的主库彻底连接不上原主库,可能导致一部分数据无法恢复,我们的解决办法是单独配置一个备份节点,专门用来备份主库的binlog日志。让新的主库在和原主库彻底失联后,能根据该备份节点的binlog进行数据恢复。
对于备份节点的要求
需要单独的服务器,且MySQL版本也要保持一致,另外,也要开启binlog和GTID功能。
备份节点会实时的拉取主节点的二进制日志,当主节点宕掉后,备份节点也会退出实时拉取的状态。
再次强调:备份节点不参与选主和对外提供服务,仅用来做备份库。
Binlog Server Configuration
按照我们现在的环境来说,是一主两从架构,现在要再搞个节点作为备份节点,从两个从库中选一个也行,再搞个新节点也行;而我这里选择使用db04这个预留的节点,作为备份节点。
那么此时的架构就是这样的了:
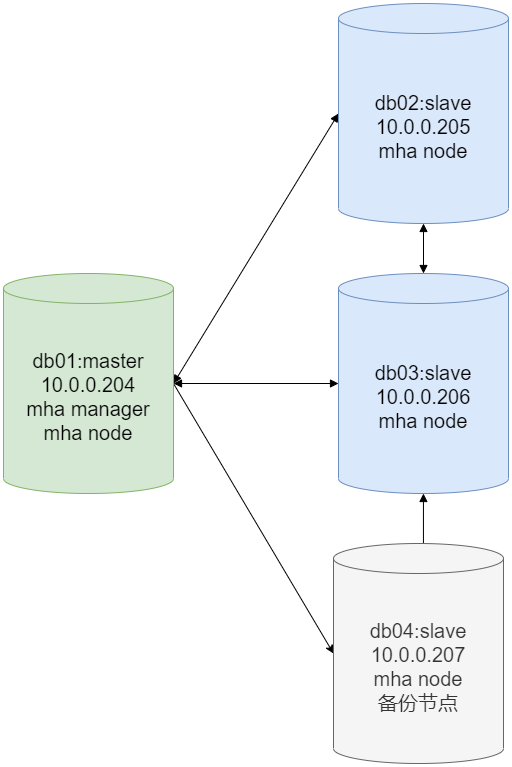
初始db01作为主节点,如果宕掉,则由db02和db03进行选举主节点,如果新的主节点联系不上原主节点,就去db04这个备份节点中回复数据。
让我们开始配置吧!
1. 首先,停止MHA Manager
db01中执行:
[root@db01 ~]# masterha_stop --conf=/etc/mha/node1.cnf
此时的主从环境是好的,db02:
[root@db02 ~]# mysql -uroot -p123
db02 [(none)]>show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 206 | | 3306 | 205 | 16d77e8b-b257-11eb-95b5-000c29b09d3c |
| 204 | | 3306 | 205 | ce532bca-b1ad-11eb-a297-000c298ffc47 |
+-----------+------+------+-----------+--------------------------------------+
2 rows in set (0.00 sec)
2. 配置文件配置
在MHA Manager的配置文件中声明备份节点。
db01中执行:
[root@db01 ~]# vim /etc/mha/node1.cnf
[root@db01 ~]# cat /etc/mha/node1.cnf
[binlog1]
# 声明10.0.0.207即db04作为备份节点
hostname=10.0.0.207
# 日志存储到一个新的目录中,注意,这个目录不要和原来的binlog目录重合。
master_binlog_dir=/data/mysql/3306/logs/repl_binlog
# 取消db04的选举权,只作为备份来用
no_master=1
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
master_ip_failover_script=/usr/local/bin/master_ip_failover
password=mha
ping_interval=2
repl_password=123
repl_user=rs
report_script=/usr/local/bin/master_send_report
ssh_user=root
user=mha
[server1]
hostname=10.0.0.204
port=3306
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
[server4]
hostname=10.0.0.207
port=3306
3. 配置备份节点
在db04中执行。
首先创建一个目录专门用来存放主节点的二进制日志:
[root@db04 ~]# mkdir -p /data/mysql/3306/logs/repl_binlog
[root@db04 ~]# chown -R mysql:mysql /data/mysql/3306/logs/repl_binlog
然后启动db04的MySQL服务,并与当前主库建立主从关系。
[root@db04 ~]# systemctl start mysqld
[root@db04 ~]# mysql -uroot -p123
# 跟之前的主库断开主从关系,
# 如果报错This operation cannot be performed with running replication threads;说明没有启动复制线程
# 这就可以stop lave; 直接启动复制线程后,再CHANGE MASTER TO
stop slave;
reset slave all;
CHANGE MASTER TO
MASTER_HOST='10.0.0.205',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1,
MASTER_USER='rs',
MASTER_PASSWORD='123';
start slave;
show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.205
Master_User: rs
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000015
Read_Master_Log_Pos: 234
Relay_Log_File: db04-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000015
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
当前主库中确认从库已经连上来了,db02执行:
[root@db02 ~]# mysql -uroot -p123
db02 [(none)]>show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 207 | | 3306 | 205 | 6dbfdccb-b609-11eb-9158-000c291b696b |
| 204 | | 3306 | 205 | ce532bca-b1ad-11eb-a297-000c298ffc47 |
| 206 | | 3306 | 205 | 16d77e8b-b257-11eb-95b5-000c29b09d3c |
+-----------+------+------+-----------+--------------------------------------+
3 rows in set (0.00 sec)
4. 备份节点手动拉取主库的二进制日志
这里有个问题,需要明确,如果主库此时有一万个二进制日志文件,那么备份节点在拉取日志的时候需要从主库的1号二进制日文件开始拉取么?答案是否定的,应该从全备后的二进制日志开始拉取,之前从全备中恢复就完了。
那这个起点文件的位置从哪判断呢?也简单,我们找个从库,看下从库当前拉取得主库二进制文件是哪个?那备份节点拉取主库得二进制日文件起点就是哪个,这里我们随便找个从库看下,db03:
[root@db03 ~]# mysql -uroot -p123
db03 [(none)]>show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.205
Master_User: rs
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000015
Read_Master_Log_Pos: 234
Relay_Log_File: db03-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000015
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
从结果中可以看到当前从库拉取得是主库得15号二进制文件,那这个文件就是我们要拉取得起点文件。
db04:
# 必须手动cd到创建得二进制目录中去,再执行拉取命令
[root@db04 ~]# cd /data/mysql/3306/logs/repl_binlog/
[root@db04 repl_binlog]# mysqlbinlog -R --host=10.0.0.205 --user=mha --password=mha --raw --stop-never mysql-bin.000015 &
[1] 2611
[root@db04 repl_binlog]# ll
total 4
-rw-r-----. 1 root root 234 May 16 17:48 mysql-bin.000015
[root@db04 repl_binlog]#
注意,拉取日志,必须在MHA Manager关闭后拉取。
5. 启动MHA Manager
db01:
nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/node1/manager.log 2>&1 &
masterha_check_status --conf=/etc/mha/node1.cnf
masterha_check_repl --conf=/etc/mha/node1.cnf
[root@db01 ~]# nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/node1/manager.log 2>&1 &
[1] 41247
[root@db01 ~]# masterha_check_status --conf=/etc/mha/node1.cnf
node1 (pid:41247) is running(0:PING_OK), master:10.0.0.205
[root@db01 ~]# masterha_check_repl --conf=/etc/mha/node1.cnf
...省略
MySQL Replication Health is OK.
OK,备份节点到此配置完毕。
但真的配置好了么?我们还要再次确认下!怎么确认呢?刚才不是说备份节点会实时的拉取主库的二进制日志么!那我就手动flush一些binlog日志,看看备份节点能否实时拉取到。
当前主库db02中执行:
[root@db02 ~]# mysql -uroot -p123
db02 [(none)]>show master status;
+------------------+----------+--------------+------------------+----------------------------------------------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+----------------------------------------------------------------------------------+
| mysql-bin.000015 | 234 | | | bbcbb587-b0aa-11eb-a2ce-000c295ead38:1,
ce532bca-b1ad-11eb-a297-000c298ffc47:1-2 |
+------------------+----------+--------------+------------------+----------------------------------------------------------------------------------+
1 row in set (0.00 sec)
db02 [(none)]>flush logs;
Query OK, 0 rows affected (0.01 sec)
db02 [(none)]>flush logs;
Query OK, 0 rows affected (0.00 sec)
db02 [(none)]>show master status;
+------------------+----------+--------------+------------------+----------------------------------------------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+----------------------------------------------------------------------------------+
| mysql-bin.000017 | 234 | | | bbcbb587-b0aa-11eb-a2ce-000c295ead38:1,
ce532bca-b1ad-11eb-a297-000c298ffc47:1-2 |
+------------------+----------+--------------+------------------+----------------------------------------------------------------------------------+
1 row in set (0.00 sec)
OK,主库的二进制日志已经刷新了,来看备份节点有没有拉取到,db04中执行:
[root@db04 repl_binlog]# pwd
/data/mysql/3306/logs/repl_binlog
[root@db04 repl_binlog]# ll
total 12
-rw-r-----. 1 root root 281 May 16 17:50 mysql-bin.000015
-rw-r-----. 1 root root 281 May 16 17:50 mysql-bin.000016
-rw-r-----. 1 root root 234 May 16 17:50 mysql-bin.000017
可以看到,新刷新出来的16号和17号日志文件,已经拉取到了。
完美!
让我们最后一次模拟故障,确认各个环节都是可用的,以及确认刚才配置的备份节点在故障恢复时,有什么需要的注意的操作。
模拟故障
当现在的主库(db02)宕掉后,MHA会做哪些事儿:
- VIP会漂移到db01上。
- 收到故障转移邮件。
- 期间会做数据补偿,我们这不不用操心。
- db03会切换到新的主节点db01上。
- 而备份节点呢?试试拉取最新的主节点日志,当主节点宕掉之后,它也会宕下来。
- MHA Manager将原主节点提出集群,然后退出。
那么我们就通过模拟故障,看看是否符合预期。
1. 宕掉主库
宕机也好说,直接停止到当前主节点,db02:
[root@db02 ~]# netstat -nlp|grep 330
tcp6 0 0 :::3306 :::* LISTEN 4073/mysqld
[root@db02 ~]# systemctl stop mysqld.service
[root@db02 ~]# netstat -nlp|grep 330
2. 确认各种状态,是否符合预期
确认邮件发送成功:
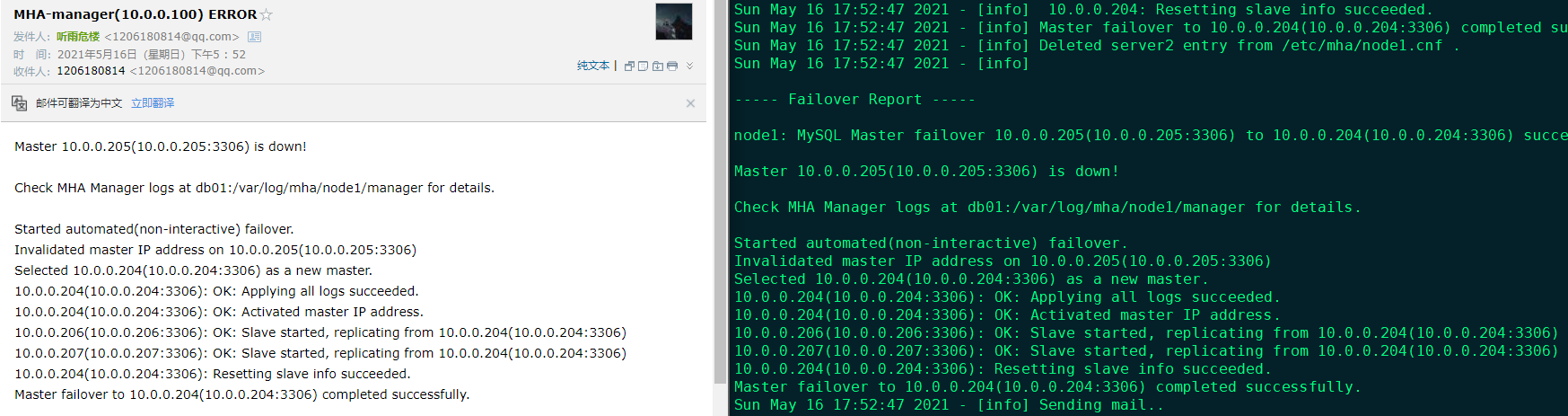
确认VIP漂移到db01上:
[root@db01 ~]# ifconfig
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.100 netmask 255.255.255.0 broadcast 10.0.0.255
ether 00:0c:29:8f:fc:47 txqueuelen 1000 (Ethernet)
确认新的主从关系:
db01 [(none)]>show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 207 | | 3306 | 204 | 6dbfdccb-b609-11eb-9158-000c291b696b |
| 206 | | 3306 | 204 | 16d77e8b-b257-11eb-95b5-000c29b09d3c |
+-----------+------+------+-----------+--------------------------------------+
2 rows in set (0.00 sec)
上面的结果中,之所以没有db04的从库信息,这是因为它跟着原主库一起宕掉了。
现在可以确认各个状态符合预期了。
好了,恢复吧.......
故障恢复
有了备份节点的恢复,就比原来的回复多了一个步骤,那就是手动拉取主节点日志的步骤,其他不变。
1. MHA Manager配置文件中重新添加节点信息,重启MySQL服务,重新构建与新节点的主从关系
db02:
[root@db02 ~]# systemctl start mysqld.service
[root@db02 ~]# mysql -uroot -p123
stop slave;
reset slave all;
CHANGE MASTER TO
MASTER_HOST='10.0.0.204',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1,
MASTER_USER='rs',
MASTER_PASSWORD='123';
start slave;
show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.204
Master_User: rs
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000014
Read_Master_Log_Pos: 234
Relay_Log_File: db02-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
db01:
[root@db01 ~]# vim /etc/mha/node1.cnf
[root@db01 ~]# cat /etc/mha/node1.cnf
[binlog1]
hostname=10.0.0.207
master_binlog_dir=/data/mysql/3306/logs/repl_binlog
no_master=1
[server default]
manager_log=/var/log/mha/node1/manager
manager_workdir=/var/log/mha/node1
master_binlog_dir=/data/mysql/3306/logs/binlog
master_ip_failover_script=/usr/local/bin/master_ip_failover
password=mha
ping_interval=2
repl_password=123
repl_user=rs
report_script=/usr/local/bin/master_send_report
ssh_user=root
user=mha
[server1]
hostname=10.0.0.204
port=3306
[server2]
hostname=10.0.0.205
port=3306
[server3]
hostname=10.0.0.206
port=3306
[server4]
hostname=10.0.0.207
port=3306
[root@db01 ~]# mysql -uroot -p123
db01 [(none)]>show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 207 | | 3306 | 204 | 6dbfdccb-b609-11eb-9158-000c291b696b |
| 205 | | 3306 | 204 | ef2baccd-b1ad-11eb-a0fb-000c294bb55c |
| 206 | | 3306 | 204 | 16d77e8b-b257-11eb-95b5-000c29b09d3c |
+-----------+------+------+-----------+--------------------------------------+
3 rows in set (0.00 sec)
2. 备份节点重新拉取新主库的日志
这里就三个点需要注意:
- 拉取日志的起点文件位置,可以从从库中查看。
- 在MHA Manager启动之前做这一步。
- 清空之前的日志。
- 在日志所在的目录执行拉取命令。
确认起始文件,这里以db03从库为例:
[root@db03 ~]# mysql -uroot -p123
db03 [(none)]>db03 [(none)]>show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.204
Master_User: rs
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000014
清空日志目录并拉取,db04中执行:
[root@db04 repl_binlog]# rm -rf *
[root@db04 repl_binlog]# mysqlbinlog -R --host=10.0.0.204 --user=mha --password=mha --raw --stop-never mysql-bin.000014 &
[1] 3694
[root@db04 repl_binlog]# ll
total 4
-rw-r-----. 1 root root 234 May 16 20:03 mysql-bin.000014
3. 重启MHA Manager
db01:
[root@db01 ~]# masterha_check_repl --conf=/etc/mha/node1.cnf
...省略
MySQL Replication Health is OK.
[root@db01 ~]# nohup masterha_manager --conf=/etc/mha/node1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/node1/manager.log 2>&1 &
[1] 43647
[root@db01 ~]# masterha_check_status --conf=/etc/mha/node1.cnf
node1 (pid:43647) is running(0:PING_OK), master:10.0.0.204
[root@db01 ~]# ifconfig
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.100 netmask 255.255.255.0 broadcast 10.0.0.255
ether 00:0c:29:8f:fc:47 txqueuelen 1000 (Ethernet)
[root@db01 ~]# mysql -uroot -p123
db01 [(none)]>show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 207 | | 3306 | 204 | 6dbfdccb-b609-11eb-9158-000c291b696b |
| 205 | | 3306 | 204 | ef2baccd-b1ad-11eb-a0fb-000c294bb55c |
| 206 | | 3306 | 204 | 16d77e8b-b257-11eb-95b5-000c29b09d3c |
+-----------+------+------+-----------+--------------------------------------+
3 rows in set (0.00 sec)
OK了。
MHA架构的日常管理
由上面的一通操作,我们也可以看到,身为DBA,对于MHA的日常管理来说:
- 搭建整个MHA高可用环境。
- 监控及故障处理。
- 高可用架构的优化:
- 核心就是降低主从的延时,让MHA Manager在数据补偿上的时间尽量减少,从而减少故障切换的时间。
- 对于MySQL5.7版本来说,开启GTID模式,开启从库SQL线程的并发复制。
that's all,see also: 老男孩-标杆班级-MySQL-lesson10-MHA高可用技术 | MHA master_ip_failover脚本文件,自用亲测,无坑 | MHA 邮件告警、故障提醒 | mha邮件提醒的send_report脚本 | MHA0.58版本,send_report脚本,绝对无坑自用亲测。Email::Simple告警

 浙公网安备 33010602011771号
浙公网安备 33010602011771号