1-Python - 员工信息增删改查程序作业
需求
Python3.6.8 + win10
需求
现要求你写⼀个简单的员⼯信息增删改查程序,需求如下:
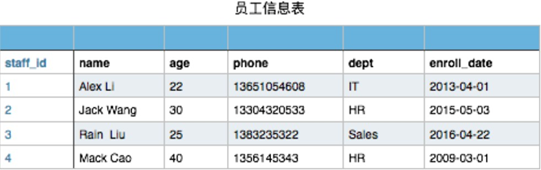
该表在文件中的存储方式:
文件名:staff_table(文件内容如下)
1,Alex Li,22,13651054608,IT,2013-04-01
2,Jack Wang,28,13451024608,HR,2015-01-07
3,Rain Wang,21,13451054608,IT,2017-04-01
4,Mack Qiao,44,15653354208,Sales,2016-02-01
5,Rachel Chen,23,13351024606,IT,2013-03-16
6,Eric Liu,19,18531054602,Marketing,2012-12-01
7,Chao Zhang,21,13235324334,Administration,2011-08-08 8,Kevin Chen,22,13151054603,Sales,2013-04-01
9,Shit Wen,20,13351024602,IT,2017-07-03
10,Shanshan Du,26,13698424612,Operation,2017-07-02
PS:每一句对应的内容:序号,姓名,年龄,手机号,部分,入职时间
功能实现为主
文件(staff_table)行数据的说明
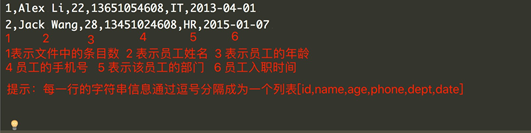
作业需求:
对用户输入的字符串进行解析,从文件中筛选出相应符合条件的结果集。
1 查文件(find)
find name,age from staff_table where age > 22 find * from staff_table where dept = "IT"
find * from staff_table where enroll_data like "2013"
demo 1
:find name,age from staff_table where age > 22(提示:name和age之间只有一个逗号没有空格)
要求:从staff_table文件中,找出员工年龄在22岁以上的员工,将这些员工的姓 名,员工的年龄打印出来
:find name,age from staff_table where age > 22
对用户输入字符串的解析流程:
1 读文件
2 将每一个员工的年龄与22进行比较
3 获取到员工年龄大于22的员工信息
4 从符合条件的员工信息中筛选出员工的姓名、年龄
######## 结果展示 #######

:find name from staff_table where age > 22

:find name,age,phone,dept from staff_table where age > 22

补充:find 与from之间可以是(表示员工的所有信息)也可以是员工信息的任意字段(多个字段可以用英文逗号隔开)
demo 2:
:find * from staff_table where dept = "IT"
需求:从staff_table 文件中找到IT部门的员工,并打印员工的所有信息
demo 3:
:find * from staff_table where enroll_data like "2013"
需求:从staff_table文件中找到员工的入职时间是2013年的员工,并打印员工所 有的信息
2 添加员工信息(用户的手机号不允许重复)
:add staff_table Mosson,18,13678789527,IT,2018-12-11
需求:
添加员工信息时,必须有员工名称(Mosson)、员工年龄(18)、员工手 机号(13678789527)、员工部门(IT)、员工入职时间(2018-12-11)
将这些信息追加到staff_table文件新的一行中,并插入这一行的id
注意:添加员工的时候不考虑异常情况即添加的时候按照姓名,年龄,手机号, 部分,入职时间 且每一条数据都包含员工的完整数据(姓名、年龄、手机号、部门、入职时间)
3 删除员工信息(根据序号删除相应员工的信息)
:del from staff_table where id = 10
需求:从staff_table中删除序号id为10的这一条员工的信息
4 修改员工信息(可以根据特殊条件修改员工信息)
demo 1
:update staff_table set dept="Market" where dept = "IT"
需求:将staff_table中dept为IT的修改成dept为Market
demo 2
:update staff_table set age=25 where name = "Alex Li"
需求:将staff_table中用户名为Alex Li的用户的年龄改成25
示例
staff_table.txt的文件内容如下:
1,zhangkai,22,13651054608,IT,2013-04-01
2,Jack Wang,28,13451024608,HR,2015-01-07
3,Rain Wang,21,18531000000,IT,2017-04-01
4,Mack Qiao,44,15653354208,Sales,2016-02-01
5,Rachel Chen,23,13351024606,IT,2013-03-16
6,Eric Liu,19,18531054602,Marketing,2012-12-01
7,Chao Zhang,21,13235324334,Administration,2011-08-08
8,Kevin Chen,22,13151054603,Sales,2013-04-01
9,Shit Wen,20,13351024602,IT,2017-07-03
10,Shanshan Du,26,13698424612,Operation,2017-07-02
只需要将该文件保存到作业的同级目录即可。
代码示例如下:
#!/bin/bash
# -*- coding: utf-8 -*-
import re
import time
import operator
import sqlparse
from copy import deepcopy
from prettytable import PrettyTable
STAFF_TABLE = r'./staff_table.txt'
class Public(object):
# file_path = r'./staff_table.txt'
data_dict = {}
rule = {
"=": operator.eq,
">": operator.gt,
">=": operator.ge,
"<": operator.lt,
"<=": operator.le,
"!=": operator.ne,
"like": operator.contains,
}
def __init__(self):
self.get_file()
def write_file(self):
with open(STAFF_TABLE, 'w', encoding='utf-8') as f:
# 避免出现可能的顺序混乱问题,这里先对字典进行排序,这里以对key进行
tmp_list = sorted(self.data_dict)
for k in tmp_list:
# 因为考虑到字典中的值有的是int类型,这里先都强转为str后再join
content = ",".join(map(lambda x: str(x), self.data_dict[k].values()))
f.write('{}{}'.format(content, '\n'))
def get_file(self):
with open(STAFF_TABLE, 'r', encoding='utf-8') as f:
title = ['id', 'name', 'age', 'phone', 'dep', 'dt']
for line in f:
line = line.strip().split(',')
self.data_dict[int(line[0])] = dict(zip(title, line))
def check_sql(self, sql):
""" 去除sql语句最后的分号 """
return sql.strip(';')
def c_error(self, s):
""" 自定义异常信息 """
print(s)
def h(slef):
""" 帮助信息函数 支持 help查看所有帮助,和 help(update) 查看指定函数的帮助"""
h = """
输入 help 查询帮助信息
支持的查询与语句有下面这些,只支持单条件查询 支持的运算符有 = != < <= > >= like
select * from staff where id!=1; -- 也允许运算符两边带空格的写法 id != 1
select id,name,age from staff where dep=IT; -- 可以查询指定字段
select * from staff where name like Wen; -- like 后的条件也允许字符串包裹 "Wen" 'Wen'
select id,name from staff where name like Wen;
更新语句必须带 where条件,仅支持运算符 =
UPDATE staff SET name='李四' where id=2
UPDATE staff SET age=18 where name=李四
UPDATE staff set phone=18531000000 where id=3;
UPDATE staff set dep=IT where name=Shit Wen; -- 同样支持带引号的 dep='IT' 和 name='Shit We'
插入,仅支持每次插入一条数据,且无需插入id字段,严格按照下列语法插入,将要插入的数据全部写在value后的括号内,每个字段以逗号分隔
只对部门做了校验,输入的部门必须是这些 ["IT", "HR", "Sales", "Marketing", "Administration", "Operation"]
INSERT INTO staff value(zhangkai,20,188888888,IT,2020-12-18);
删除支持模糊查询后删除
DELETE FROM staff WHERE id=1;
DELETE FROM staff WHERE id>=1;
DELETE FROM staff WHERE name>=Shit Wen;
DELETE FROM staff WHERE dep='IT'; -- 同样支持带引号的 dep='IT' 和 name='Shit We' 这种
"""
print(h)
class Handler(Public):
def show_query(self, data_list, fields, start_time=None):
"""
根据要展示的字段,展示结果
:param data_list:
:param fields:
:return:
"""
if data_list:
table = PrettyTable(fields)
for item in data_list:
table.add_row([item[j] for j in fields])
print(table)
print("匹配到 {} 条结果, 耗时 {:.4f} 秒".format(data_list.__len__(), time.time() - start_time))
def check_fields(self, sql):
""" 确定展示字段 select * select id,name """
# print(list(self.data_dict.values()))
token = sqlparse.parse(sql)
fields = str(token[0].tokens[2]).replace(' ', '')
# print(fields)
if '*' in fields:
return ['id', 'name', 'age', 'phone', 'dep', 'dt']
else:
return fields.split(',')
def check_sql(self, sql):
""" 去除sql语句最后的分号 """
return sql.strip(';')
def check_where(self, sql):
""" 检查sql语句是否有where """
if 'where' in sql.lower():
return sql.split('where')[-1].strip()
else:
return False
def fuzzy_query(self, con):
""" 根据条件进行条件查询 """
t_start = time.time()
data_list = []
k, o, v = con.split(' ') # ['id', '!=', '2']
if self.rule.get(o):
for i in self.data_dict.values():
# print(222222222222, i)
a, b = i[k], v.strip("'").strip('"')
if k == 'id':
a, b = int(a), int(b)
if self.rule.get(o)(a, b):
data_list.append(i)
self.show_query(data_list, self.check_fields(self.sql), t_start)
def select(self, sql):
""" 查询 """
# 去掉sql后面的分号
self.sql = self.check_sql(sql)
# 首先判断是否存在where,如果存在,就把where后的条件分割出来
con = self.check_where(self.sql)
if con:
# print(con)
self.fuzzy_query(con)
else:
self.show_query(self.data_dict.values(), self.check_fields(self.sql), time.time())
def update(self, sql):
""" update 更新 UPDATE staff SET name='李四' where id=2 """
# 去除sql后的逗号
t_start = time.time()
self.sql = self.check_sql(sql)
# print(self.sql)
res = re.search(
'\s(?P<set>[a-z]{3})\s(?P<con>[a-z]+)\s(?P<o1>[=><!]{1,2})\s(?P<v1>.*)\s(?P<where>[a-z]{5})\s(?P<k>[a-z]+)\s(?P<o2>[=><!]{1,2})\s(?P<v>.*)',
self.sql)
# print(res)
if res:
keyword_set, condition, o1, condition_value, keyword_where, fields_key, o2, fields_value = res.group(
"set"), res.group("con"), res.group("o1"), res.group("v1"), res.group("where"), res.group(
"k"), res.group("o2"), res.group("v").strip('"').strip("'")
if keyword_set != 'set':
print('sql keyword error: [{}]'.format(keyword_set))
return
if keyword_where != 'where':
print('sql keyword error: [{}]'.format(keyword_where))
return
if o1 != '=' or o2 != '=':
print('不支持的运算符:[{}],所在的sql:[{}]'.format(o1, sql))
return
if o2 != '=':
print('不支持的运算符:[{}],所在的sql:[{}]'.format(o2, sql))
return
count = 0
tmp_data = deepcopy(self.data_dict)
for k, v in self.data_dict.items():
if v.get(fields_key) == fields_value:
tmp_data[k][condition] = condition_value
count += 1
print('受影响的行数 {}, 耗时 {:.4f} 秒'.format(count, time.time() - t_start))
self.data_dict = tmp_data
self.write_file()
else:
print('sql error: [{}]'.format(sql))
def insert(self, sql):
"""" 插入数据 """
t_start = time.time()
# 插入数据,无需处理sql后的分号
self.sql = sql
res = re.search('\s(?P<keyword_value>[a-z]{5})\((?P<value>.*)\)', self.sql)
if res:
keyword_value, value = res.group('keyword_value'), res.group('value')
# print(keyword_value, value)
if keyword_value != 'value':
print('sql keyword error: [{}]'.format(keyword_value))
return
try:
# 处理括号中的值 zhangkai,20,188888888,IT,2020-12-18
name, age, phone, dep, dt = value.strip().replace(' ', '').split(',')
# 部门应该是存在的
dep_list = ["IT", "HR", "Sales", "Marketing", "Administration", "Operation"]
if dep not in dep_list:
raise self.c_error("输入的部门是[{}], 但应该是这些 [{}]".format(dep, ' '.join(dep_list)))
# 单独处理id,id应该是现有的最大id值加一
id = int(max(self.data_dict.keys())) + 1
# print(id, name, age, phone, dep, date)
self.data_dict[id] = {"id": id, "name": name, "age": int(age), "phone": phone, "dep": dep, "dt": dt}
print('受影响的行数 {}, 耗时 {:.4f} 秒'.format(1, time.time() - t_start))
self.write_file()
except Exception as e:
self.c_error(e)
pass
else:
print('sql error: [{}]'.format(sql))
def delete(self, sql):
""" 根据条件删除记录 """
# 去除sql后的逗号
t_start = time.time()
self.sql = self.check_sql(sql)
# print(self.sql)
res = re.search('\s(?P<where>[a-z]{5})\s(?P<k>[a-z]+)\s(?P<o>[=><!]{1,2})\s(?P<v>.*)', self.sql)
if res:
where, fields, o, fields_value = res.group("where"), res.group("k"), res.group("o"), res.group("v")
# print(where, fields, o, fields_value)
if where != 'where':
print('sql keyword error: [{}]'.format(where))
return
count = 0
# 因为要循环的同时,要删除匹配的元素,所以,要复制一份副本,否则循环和删除同时作用于一个字典时,会报错
tmp_dict = deepcopy(self.data_dict)
for key, value in self.data_dict.items():
a, b = value[fields], fields_value.strip("'").strip('"')
if fields in ['id', 'age']:
a, b = int(a), int(b)
if self.rule.get(o)(a, b):
tmp_dict.pop(key)
count += 1
print('受影响的行数 {}, 耗时 {:.4f} 秒'.format(count, time.time() - t_start))
self.data_dict = tmp_dict
self.write_file()
else:
print('sql error: [{}]'.format(sql))
def main():
""" 入口函数 """
obj = Handler()
while True:
cmd = input('mysql> ').strip()
# 取出命令进行反射执行对应的操作
cmd0 = cmd.split(' ', 1)[0].lower()
if cmd0 == 'help':
obj.h()
continue
if hasattr(obj, cmd0):
# 将sql语句全部小写,操作符两边以空格分割,如果sql带注释则去掉注释
fm_sql = sqlparse.format(cmd, keyword_case='lower', use_space_around_operators=True, strip_comments=True)
getattr(obj, cmd0)(fm_sql)
else:
print('不支持的命令')
obj.h()
if __name__ == '__main__':
main()
演示示例:
mysql> select * from staff where id!=1;
+----+-------------+-----+-------------+----------------+------------+
| id | name | age | phone | dep | dt |
+----+-------------+-----+-------------+----------------+------------+
| 2 | Jack Wang | 28 | 13451024608 | HR | 2015-01-07 |
| 3 | Rain Wang | 21 | 18531000000 | IT | 2017-04-01 |
| 4 | Mack Qiao | 44 | 15653354208 | Sales | 2016-02-01 |
| 5 | Rachel Chen | 23 | 13351024606 | IT | 2013-03-16 |
| 6 | Eric Liu | 19 | 18531054602 | Marketing | 2012-12-01 |
| 7 | Chao Zhang | 21 | 13235324334 | Administration | 2011-08-08 |
| 8 | Kevin Chen | 22 | 13151054603 | Sales | 2013-04-01 |
| 9 | Shit Wen | 20 | 13351024602 | IT | 2017-07-03 |
| 10 | Shanshan Du | 26 | 13698424612 | Operation | 2017-07-02 |
+----+-------------+-----+-------------+----------------+------------+
匹配到 9 条结果, 耗时 0.0030 秒
mysql> select id,name,age from staff where dep=IT;
+----+-------------+-----+
| id | name | age |
+----+-------------+-----+
| 1 | Alex Li | 22 |
| 3 | Rain Wang | 21 |
| 5 | Rachel Chen | 23 |
| 9 | Shit Wen | 20 |
+----+-------------+-----+
匹配到 4 条结果, 耗时 0.0020 秒
mysql> select * from staff where name like Wen;
+----+----------+-----+-------------+-----+------------+
| id | name | age | phone | dep | dt |
+----+----------+-----+-------------+-----+------------+
| 9 | Shit Wen | 20 | 13351024602 | IT | 2017-07-03 |
+----+----------+-----+-------------+-----+------------+
匹配到 1 条结果, 耗时 0.0009 秒
mysql> select id,name from staff where name like Wen;
+----+----------+
| id | name |
+----+----------+
| 9 | Shit Wen |
+----+----------+
匹配到 1 条结果, 耗时 0.0010 秒
mysql> UPDATE staff SET name='李四' where id=2;
受影响的行数 1, 耗时 0.0000 秒
mysql> UPDATE staff SET age=18 where name=李四 -- 没有匹配到叫李四的人,所以,一条记录也没有修改
受影响的行数 0, 耗时 0.0000 秒
mysql> UPDATE staff set phone=18531000000 where id=3;
受影响的行数 1, 耗时 0.0010 秒
mysql> UPDATE staff set dep=IT where name=Shit Wen;
受影响的行数 1, 耗时 0.0000 秒
mysql> UPDATE staff set dep=Operation where name=Shit Wen;
受影响的行数 1, 耗时 0.0000 秒
mysql> INSERT INTO staff value(zhangkai,20,188888888,IT,2020-12-18);
受影响的行数 1, 耗时 0.0000 秒
mysql> DELETE FROM staff WHERE id=1;
受影响的行数 1, 耗时 0.0000 秒
mysql> DELETE FROM staff WHERE dep='IT';
受影响的行数 3, 耗时 0.0009 秒
mysql>
that's all, see also:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号