1-Redis5-数据类型篇
about
包含:字符串、列表、集合、有序集合、哈希
全局命令
对所有的数据类型都生效的命令。
# 高危命令,生产禁用!返回所有的redis中所有的key,尽量避免在生产中使用
KEYS *
# 查询以k2开头的所有KEYS
KEYS k2*
# 返回指定key的值
KEYS k1
# 返回当前数据库中key的总数,这个先相当于是个计数器,生产中可以用
DBSIZE
# 返回指定key的value值的类型
TYPE k1
# 删除一个key,key存在并且删除成功,返回1,否则返回0
# 删除n个key,并且都删除成功,返回删除成功的key的个数
DEL k1
DEL k1 k2 ...kn
# 判断 key 是否存在,如果返回0,表示key不存在,如果判断多个key,例如,EXISTS k1 k2 k3,如果都存在,返回3
# 如果返回0表示都不存在,返回1,2的话,就表示只有这一两个key存在
EXISTS k1
EXISTS k1 k2 ... kn
# 重命名
RENAME k1 k11
# 查看所有的配置项
CONFIG GET * # 以键值对的形式返回所有的配置项
CONFIG GET appendonly # 查看指定配置项
CONFIG SET requirepass 1234 # 临时动态的设置某个设置,重启redis失效,想要永久的,还是要手动的写入到配置文件中
CONFIG REWRITE # 将临时动态设置的某个设置,刷写到配置文件中
# 高危命令,生产禁用!清空redis中所有的key,找都找不回来的那种清空,如果用了,请尽早买好跑路的高铁票
FLUSHALL
# 查看服务端,此时此刻的客户端连接数
INFO CLIENTS
# 查看服务端支持的最大的客户端连接数
CONFIG GET maxclients
设置键值对的生存时间:
# 以秒/毫秒为单位设置生存时间
EXPIRE/PEXPIRE
# 以秒/毫秒为单位返回剩余的生存时间
TTL/PTTL
# 即在生存时间内,取消生存时间设置
PERSIST
# 为 k2 设置生存时间为20秒,关于返回值
# 0 表示key不存在
# 1 表示key存在,且设置过期时间成功
EXPIRE k2 20
# 返回 k2 剩余的生存时间,关于返回值
# -1 表示key存在且永不过期
# -2 表示key不存在
# n 表示key存在,还有n秒后过期
TTL k2
# 取消过期时间设置,或者你可以重新 set k2 v2 当然,set这种不够优雅
PERSIST k2
注意,不要将大量的键值对设置为同一时间失效,避免造成缓存雪崩!
redis存储数据的上限
由于Redis是一个基于内存的数据库,所以它的数据存储在内存中,那么Redis数据大小限制取决于内存的大小。
因此,当Redis中的数据超过可用内存时,它将开始使用交换空间(swap space)或溢出文件(overflow file),这将导致系统变慢或崩溃。因此,我们需要注意Redis中数据大小的限制,以便避免这些问题的发生。
单个键值对的大小限制:Redis最大可以存储512MB的数据,因此,单个键值对的大小不能超过512MB。超过这个大小将导致数据丢失或内存中断。
Redis数据库的大小限制:每个Redis数据库默认可以最多存储2^32个键值对,当达到这个限制后,将无法再向其添加更多数据。
禁用高危命令
刚才学了一些命令,你可以发现有些高危命令是生产中禁止使用的,那么相信人的自觉性肯定是不靠谱的,我们需要禁用掉这些命令。
打开你的redis.conf文件,想要禁用某个命令,可以这样写:
# 为某个命令赋值为空字符串,就先当于禁用掉这个命令了
# 你也可以为某个命令重命名,防止自己也没得用
rename-command KEYS ""
# rename-command KEYS "KEYSSS"
rename-command SHUTDOWN ""
rename-command CONFIG ""
rename-command FLUSHALL ""
你应该根据情况决定是禁用掉某个命令还是重命名某个命令。
比如你直接禁用掉到DEL命令,但此时aof文件中有DEL的操作日志,那么当你重启Redis或者调整aof文件时,就会报错,因为没有这个删除命令了.....
字符串
# 如果key存在,则覆盖原来的value值,若key不存在,就设置key和value
127.0.0.1:6379> SET k1 v1
OK
# set key的时候,同时指定过期时间
127.0.0.1:6379> SETEX k1 10 v1
# 查看单个key值
127.0.0.1:6379> GET k1
"v1"
# 同时set多个key的值
127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3
OK
# 同时查看多个key的值
127.0.0.1:6379> MGET k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
# 先GET再set, 先GET,如果k1不存在,返回空nil,然后在设置一个值v1
# 如果key存在,先将原有的value给你返回,再把新的value给你设置上
127.0.0.1:6379> GETSET k1 v1111
"v1"
# 在set的时候指定超时时间,在存活时间内,可以获取到该值
127.0.0.1:6379> SET k1 v1 ex 100
OK
127.0.0.1:6379> SETEX k2 100 v1
OK
127.0.0.1:6379> TTL k1
(integer) 92
127.0.0.1:6379> TTL k2
(integer) 94
# 如果key不存在,就设置一个key:value,如果key存在则什么都不做
# 返回 0 表示key存在,啥也不做
# 返回 1 表示key不存在,设置键值对成功
127.0.0.1:6379> SETNX k1 v1
(integer) 0
# 删除单个key,删除多个key
127.0.0.1:6379> DEL k1
(integer) 1
127.0.0.1:6379> DEL k1 k2 k3
(integer) 2
# 追加值,若key不存在,相当于set键值对,若key存在,将append的value拼接到原来key的value的后面
127.0.0.1:6379> APPEND k1 v1
(integer) 2
127.0.0.1:6379> GET k1
"v1"
127.0.0.1:6379> APPEND k1 111
(integer) 5
127.0.0.1:6379> GET k1
"v1111"
# 为指定字节位置的元素替换为指定值
127.0.0.1:6379> SET k7 0123456789
127.0.0.1:6379> SETRANGE k7 5 A # 将第5个字节位置的值替换为 A
(integer) 10
127.0.0.1:6379> GET k7 # 替换后的结果
"01234A6789"
127.0.0.1:6379> SETRANGE k7 12 BC # 如果指定的字节数超出字符串长度,就补零
(integer) 14
127.0.0.1:6379> GET k7
"01234A6789\x00\x00BC"
127.0.0.1:6379> SETRANGE k7 6 7 BC # 不允许这种将第6~7字节位置的元素替换为指定值
(error) ERR wrong number of arguments for 'setrange' command
# 判断key是否存在,存在返回1,否则返回0
127.0.0.1:6379> EXISTS k1
(integer) 1
# 如果key存在,返回值的长度,否则返回0
127.0.0.1:6379> STRLEN k1
(integer) 2
127.0.0.1:6379> STRLEN k222 # k222不存在
(integer) 0
# 返回字符串指定字节范围的值
127.0.0.1:6379> SET k7 0123456789
OK
127.0.0.1:6379> GETRANGE k7 1 5 # 第1~5个字节范围内的值,注意,索引从0开始
"12345"
127.0.0.1:6379> GETRANGE k7 5 15 # 第5~15个字节范围内的值,如果字符串长度不够,以起始位置开始,有多少返回多少
"56789"
127.0.0.1:6379> GETRANGE k7 15 20 # 起始和结束范围都不在字符串范围内,返回空
""
上例中有对范围设置值或者取值的操作,但谨记,不能对中文这么做,因为一个中文由多个字节组成。
计数器功能:
127.0.0.1:6379> INCR num # 每次调用INCR命令,num值自加一,num提前可以不存在
(integer) 1
127.0.0.1:6379> INCR num
(integer) 2
127.0.0.1:6379> INCRBY num 10 # 一次性加n
(integer) 12
127.0.0.1:6379> INCRBY num 100
(integer) 112
127.0.0.1:6379> DECR num # DECR 使num自减一
(integer) 111
127.0.0.1:6379> decrby num 10 # 一次性减n
(integer) 101
127.0.0.1:6379> DECR num1 # 如果num1这个key不存在,则先设置为0,再减一
(integer) -1
127.0.0.1:6379> GET num # 可以通过GET获取该计数器的值
"101"
127.0.0.1:6379> GET num1
"-1"
127.0.0.1:6379> TYPE num # 注意,值仍然是字符串
string
列表
应用场景:
- 消息队列系统
- 最新的微博消息,比如我们将最新发布的热点消息都存储到Redis中,只有翻看"历史久远"的个人信息,这类冷数据时,才去MySQL中查询
列表的特点:
- 后插入的在最前面,相当于每次都默认在索引0前面做插入操作。这个特性相当于微信朋友圈,最新发布的的动态在最上面。
- 列表内每一个元素都有自己的下标索引,从左到右,从0开始;从右到左,从
-1开始,这跟Python中的列表一样。 - 列表中的元素可重复。
# 增
LPUSH l1 a b # 如果 l1 不存在就创建,然后将 a b 插入到 l1 中,如果 l1 存在,直接将 a b 插入到 l1 中
LPUSHX l1 c # 如果 key 存在则插入,不存在则什么也不做
LINSERT l1 before a a1 # 在元素 a 前面插入 a1
LINSERT l1 after a a2 # 在元素 a 后插入 a2
RPUSH l1 1 # 在列表尾部追加 元素 1
RPUSH l1 2 3 # 在列表尾部先追加 2 再追加 3
RPUSHX l1 4 # 如果列表 l1 存在就将元素4追加到列表尾部,如果列表不存在则什么也不做
# 查,根据索引下标取值
LRANGE l1 0 -1 # 从索引0开始取到-1,也就是从头取到尾,获取列表中的所有元素
LRANGE l1 0 2 # 取索引 0 1 2 三个索引对应的元素
LRANGE l1 0 0 # 取索引 0 对应的元素
LRANGE l1 10 15 # 如果索引不在合法范围内,则取空
LINDEX l1 1 # 根据索引下标返回元素
# 删除
DEL l1 # 删除整个列表
LPOP l1 # 抛出列表头部元素
RPOP l1 # 抛出列表尾部元素
RPOPLPUSH l1 l2 # 将列表 l1 尾部的元素抛出并且添加到列表 l2 中
LREM l1 2 a1 # 从左到右,删除指定个数的元素 a1 ,本示例中,若 a1 有 1 个,就删一个,若 a1 有 3 个或者更多,也就删除 2 个
LTRIM l1 2 4 # 保留索引2-4的元素,其余删除
# 改
LSET l1 0 a # 将列表索引为0的元素修改为指定值,如果索引位置不存在则报错
hash
应用场景:
- 作为MySQL的缓存。
对应关系:
mysql数据格式:
user表
id name job age
1 zhang it 18
2 wang it 24
3 zhao it 20
对应hash类型存储格式:
key field1 value field2 value field3 value
user:1 name zhang job it age 18
user:2 name wang job it age 18
user:3 name zhao job it age 18
user对应MySQL的表,n和MySQL中user表的id一一对应
user:n
操作:
# 增
127.0.0.1:6379> HMSET user:1 name zhangkai age 18 gender m
OK
127.0.0.1:6379> HMSET user:2 name wangkai age 18 gender m
OK
# 查
# 获取指定字段的值,相当于 select name from user where id=1;
127.0.0.1:6379> HGET user:1 name
"zhangkai"
# 获取多个指定字段的值,相当于 select name,age from user where id=1;
127.0.0.1:6379> HMGET user:1 name age
1) "zhangkai"
2) "18"
# 获取所有键值对,相当于 select * from user;
127.0.0.1:6379> HGETALL user:1
1) "name"
2) "zhangkai"
3) "age"
4) "18"
5) "gender"
6) "m"
# 判断指定字段是否存在,存在返回1,否则返回0
127.0.0.1:6379> HEXISTS user:1 name
(integer) 1
# 返回key中所有字段的数量
127.0.0.1:6379> HLEN user:1
(integer) 3
# 改
127.0.0.1:6379> HINCRBY user:1 age 8 # 为整型字段的值加固定数字
127.0.0.1:6379> HSET user:1 name zhangkai2 # 为指定字段重新赋值
集合
集合的应用场景:
- 适用于各种需要求交集、并集、差集的场景,比如共同好友,共同关注的场景。
- 另外这里的集合也有数学上的集合特性,去重,交、并、差集的运算。
基础操作:
# 增
127.0.0.1:6379> SADD s1 a b c # 声明key并添加 a b c 三个元素
(integer) 3
127.0.0.1:6379> SMEMBERS s1 # 返回 s1 中所有元素
1) "c"
2) "b"
3) "a"
127.0.0.1:6379> SCARD s1 # 返回 s1 中元素的个数
(integer) 3
127.0.0.1:6379> SRANDMEMBER s1 # 随机返回集合中的1个元素
"a"
127.0.0.1:6379> SRANDMEMBER s1
"a"
127.0.0.1:6379> SRANDMEMBER s1
"c"
127.0.0.1:6379> SRANDMEMBER s1
"b"
127.0.0.1:6379> SRANDMEMBER s1 2 # 随机返回指定个数的元素
1) "b"
2) "c"
127.0.0.1:6379> SISMEMBER s1 a # 判断元素 a 是否存在
(integer) 1
# 删除
127.0.0.1:6379> SPOP s1 # 随机删除一个元素,并将这个元素返回
"c"
127.0.0.1:6379> SPOP s1 2 # 随机删除指定个数的元素,并将多个元素返回
1) "d"
2) "a"
127.0.0.1:6379> DEL s1 # 删除集合
(integer) 1
# 移动
127.0.0.1:6379> SADD s1 a b c # 将元素 a 从s1移动到s2中,如果s2不存在,就先创建再移动
(integer) 3
127.0.0.1:6379> SMOVE s1 s2 a # 注意,一次只能移动一个,不支持多个,比如:SMOVE s1 s2 a b c
(integer) 1
127.0.0.1:6379> SMEMBERS s1
1) "c"
2) "b"
127.0.0.1:6379> SMEMBERS s2
1) "a"
再来看集合的运算。我们来个示例,有个需求,现有个培训学校开设了Python和Linux两门课程,来学习的同学都有如下情况:
- 有的同学学习Linux
- 有的学习Python
- 还有的既学了Linux又学了Python
那现在问题来了,我们要对这些同学的情况做统计,比如找出两门课都报了的同学?
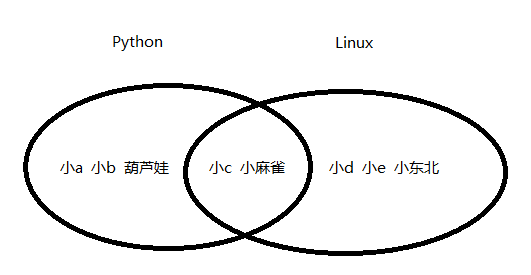
# 先把数据准备好
127.0.0.1:6379> SADD python xiaoA xiaoB Huluwa xiaoC xiaoMaque
(integer) 5
127.0.0.1:6379> SADD linux xiaoC xiaoMaque xiaoD xiaoE xiaoDongbei
(integer) 5
# 求交集,找出即学习了Python又学习了Linux的同学
127.0.0.1:6379> SINTER python linux # 这俩集合谁在前谁在后没区别
1) "xiaoC"
2) "xiaoMaque"
# 求交集,找出即学习了Python又学习了Linux的同学,并将结果保存到集合tmp中,tmp不存在则先创建
127.0.0.1:6379> SINTERSTORE tmp python linux
(integer) 2
127.0.0.1:6379> SMEMBERS tmp
1) "xiaoMaque"
2) "xiaoC"
# 求并集,找出学习两门课程的所有人
127.0.0.1:6379> SUNION python linux
1) "xiaoE"
2) "xiaoA"
3) "xiaoB"
4) "xiaoD"
5) "xiaoDongbei"
6) "xiaoMaque"
7) "xiaoC"
8) "Huluwa"
# 求并集,找出学习两门课程的所有人,并将结果保存到集合tmp中,tmp不存在则先创建
127.0.0.1:6379> SUNIONSTORE tmp python linux
(integer) 8
127.0.0.1:6379> SMEMBERS tmp
1) "xiaoE"
2) "xiaoA"
3) "xiaoB"
4) "xiaoD"
5) "xiaoDongbei"
6) "xiaoMaque"
7) "xiaoC"
8) "Huluwa"
# 求差集,找出只学习了Python(或者Linux)课程的人
127.0.0.1:6379> SDIFF python linux # 只学习Python课程的人
1) "xiaoA"
2) "xiaoB"
3) "Huluwa"
127.0.0.1:6379> SDIFFSTORE tmp python linux # 只学习Python课程的人,并将结果保存到集合tmp中,tmp不存在则先创建
(integer) 3
127.0.0.1:6379> SMEMBERS tmp
1) "xiaoA"
2) "xiaoB"
3) "Huluwa"
127.0.0.1:6379> SDIFF linux python # 只学习Linux课程的人
1) "xiaoDongbei"
2) "xiaoE"
3) "xiaoD"
# # 只学习Linux课程的人,并将结果保存到集合tmp中,tmp不存在则先创建
127.0.0.1:6379> SDIFFSTORE tmp linux python
(integer) 3
127.0.0.1:6379> SMEMBERS tmp
1) "xiaoDongbei"
2) "xiaoE"
3) "xiaoD"
有序集合zset
有序集合在集合的基础上增加了排序功能,比如以点击数为条件进行排序。
有序集合的典型应用场景:
- 各种排行榜,音乐排行榜、热点新闻榜.....
在有序集合中,我们一般称其元素为成员,其成员对应的值为得分。
# 增加
127.0.0.1:6379> ZADD top 0 xuwei 0 zhoujielun
(integer) 2
# 查, withscores是可选参数,表示同时返回其成员和其得分
127.0.0.1:6379> ZSCORE top xuwei # 返回top中,指定成员的分数,如果指定成员不存在则返回nil
"0"
127.0.0.1:6379> ZSCORE top zhangkai
(nil)
# 返回top中所有成员,默认以分数大小升序排序,分值相同按ASCII编码排序
127.0.0.1:6379> ZRANGE top 0 -1
1) "xuwei"
2) "zhoujielun"
127.0.0.1:6379> ZRANGE top 0 -1 WITHSCORES
1) "xuwei"
2) "0"
3) "zhoujielun"
4) "0"
# 返回成员在有序集合中的索引下标,如果成员不存在返回nil
127.0.0.1:6379> ZRANK top xuwei
(integer) 0
127.0.0.1:6379> ZRANK top zhangkai
(nil)
# 返回top中成员的数量
127.0.0.1:6379> ZCARD top
(integer) 2
# 返回top中所有成员,-inf表示第一个成员,+inf表示最后一个成员,结果默认以其分数的大小排序
127.0.0.1:6379> ZRANGEBYSCORE top -inf +inf
1) "xuwei"
2) "zhoujielun"
127.0.0.1:6379> ZRANGEBYSCORE top -inf +inf WITHSCORES
1) "xuwei"
2) "0"
3) "zhoujielun"
4) "0"
# 返回top中所有成员,并且以索引从大到小排序
127.0.0.1:6379> ZREVRANGE top 0 -1
1) "zhoujielun"
2) "xuwei"
127.0.0.1:6379> ZREVRANGE top 0 -1 WITHSCORES
1) "zhoujielun"
2) "0"
3) "xuwei"
4) "0"
# 返回top中 0 <= index <= 2 索引范围内的成员,不在范围内返回空
127.0.0.1:6379> ZREVRANGE top 0 2
1) "zhoujielun"
2) "xuwei"
127.0.0.1:6379> ZREVRANGE top 0 2 WITHSCORES
1) "zhoujielun"
2) "0"
3) "xuwei"
4) "0"
127.0.0.1:6379> ZREVRANGE top 3 5 WITHSCORES
(empty list or set)
# 返回top中分数在 20 <= 分数 <= 200 这个范围内的成员的数量
127.0.0.1:6379> ZADD top 20 xuwei 80 zhoujielun 100 daolang 120 zhaolei # 先搞个数据
127.0.0.1:6379> ZCOUNT top 20 200
(integer) 4
# 返回top中分数在 20 <= 分数 <= 200 这个范围内的成员
127.0.0.1:6379> ZRANGEBYSCORE top 20 200
1) "xuwei"
2) "zhoujielun"
3) "daolang"
4) "zhaolei"
127.0.0.1:6379> ZRANGEBYSCORE top 20 200 WITHSCORES
1) "xuwei"
2) "20"
3) "zhoujielun"
4) "80"
5) "daolang"
6) "100"
7) "zhaolei"
8) "120"
# 返回top中分数范围在 100 <= 的 <= 20 范围内的成员,并以的的大小降序排序
127.0.0.1:6379> ZREVRANGEBYSCORE top 100 20
1) "daolang"
2) "zhoujielun"
3) "xuwei"
127.0.0.1:6379> ZREVRANGEBYSCORE top 100 20 WITHSCORES
1) "daolang"
2) "100"
3) "zhoujielun"
4) "80"
5) "xuwei"
6) "20"
# 改
# 为指定成员重新赋值
127.0.0.1:6379> ZADD top 30 xuwei
(integer) 0
# 为指定成员增加指定分数,并返回增加后的分数
127.0.0.1:6379> ZINCRBY top 10 xuwei
"40"
# 删除
# 删除分数在指定范围内的成员,并返回删除成员的数量
127.0.0.1:6379> ZREMRANGEBYSCORE top 80 100
(integer) 2
# 删除top中指定索引范围内 0 <= index <= 1 的成员
127.0.0.1:6379> ZREMRANGEBYRANK top 0 1
(integer) 2
# 删除top中一个或者多个成员,返回实际删除的个数,没有找到key返回0
127.0.0.1:6379> ZREMRANGEBYRANK top 0 1
(integer) 2
127.0.0.1:6379> DEL top
(integer) 1
来个音乐排行榜的示例:
# 创建初始的音乐排行榜,初始每首歌播放量都是0
ZADD top 0 aiqing 0 guxiang 0 lanlianhua 0 shiguang
# 模拟每首歌的播放量
ZINCRBY top 123 aiqing
ZINCRBY top 223 guxiang
ZINCRBY top 203 lanlianhua
ZINCRBY top 103 shiguang
# 返回播放量前三名的歌名
127.0.0.1:6379> ZREVRANGE top 0 2 WITHSCORES
1) "guxiang"
2) "223"
3) "lanlianhua"
4) "203"
5) "aiqing"
6) "123"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号