1-MySQL - InnoDB
before
centos7.3 + mysql5.7.20
本篇主要介绍MySQL的InnoDB存储引擎的细节。
说在前面:由于版本不一致和大家对一些实现理解不同,本篇也是搜集了官网和网上的资料加自己的理解整理而来,如果有不对的地方,望指正。
存储引擎的主要功能
MySQL的存储引擎大致提供了以下几个大的方面的功能:
- 数据读写
- 保证数据安全和一致性
- 提高性能
- 热备份
- 自动故障恢复
- 高可用方面支持
MySQL存储引擎的种类
下列是Oracle的MySQL支持的存储引擎的种类,包括目前在用和停用的:
- InnoDB
- MyISAM
- MEMORY
- ARCHIVE
- FEDERATED
- EXAMPLE
- BLACKHOLE
- MERGE
- NDBCLUSTER
- CSV
第三方引擎:
- Xtradb
- RocksDB
- MyRocks
TokuDB
TokuDB、RocksDB、MyRocks的共同点:压缩比高,数据插入性能极高。
存储引擎的相关操作
-- 查看当前版本中支持的引擎
SHOW ENGINES;
-- 查看当前版本中使用指定引擎的表有哪些,比如查看都有哪些表使用了 CSV 引擎
SELECT table_name,engine FROM information_schema.tables WHERE engine='CSV';
-- 查看MySQL当前版本支持的默认引擎
SELECT @@default_storage_engine;
-- 修改系统默认引擎
SET default_storage_engine=MyISAM; -- Session级别,影响当前会话
SET GLOBAL default_storage_engine=MYISAM; -- 全局级别,仅影响新会话,重启之后,参数均失效
-- 想要永久生效,编辑配置文件 vim /etc/my.conf
[mysqld]
default_storage_engine=myisam
存储引擎是作用于表级别的,表创建时,可以指定不同的存储引擎,但我们一般建议统一存储引擎为InnoDB。
-- 查看指定库中表的引擎
SHOW TABLE STATUS FROM world;
-- 查看所有表的引擎
SELECT table_schema,table_name,ENGINE FROM information_schema.tables;
-- 过滤一下非系统表
SELECT table_schema,table_name,ENGINE
FROM information_schema.tables
WHERE table_schema
NOT IN ('sys', 'mysql', 'information_schema', 'performance_schema');
修改指定表的存储引擎:
-- 等价
ALTER TABLE tt.a1 ENGINE=MYISAM;
ALTER TABLE tt.a2 ENGINE INNODB;
-- 另外,需要注意的是,上面的命令也可以用来进行innodb表的碎片整理
-- 扩展,如果innoob的表有外键关系,那么修改时,需要删除外键后再修改
alter table city drop FOREIGN KEY city_ibfk_1;
alter table city engine myisam;
问题来了,如果有1000张表都需要修改存储引擎该怎么办?
来个示例:将world和 tt 数据库中所有myisam引擎的表修改为innodb
-- 先将符合条件的表过滤出来
SELECT table_schema,table_name,ENGINE
FROM information_schema.tables
WHERE table_schema IN ("world", "tt") AND ENGINE='myisam';
+--------------+------------+--------+
| table_schema | table_name | ENGINE |
+--------------+------------+--------+
| tt | a1 | MyISAM |
| tt | a2 | MyISAM |
| tt | a3 | MyISAM |
| world | t1 | MyISAM |
+--------------+------------+--------+
4 rows in set (0.00 sec)
-- 拼接命令并导出,如果报错参考:https://www.cnblogs.com/Neeo/articles/13047216.html
SELECT CONCAT('ALTER TABLE ',table_schema,'.',table_name,' engine=innodb;')
FROM information_schema.tables
WHERE table_schema IN ("world", "tt") AND ENGINE='myisam'
INTO OUTFILE '/tmp/check_engine.sql';
-- 导出成功
[root@cs ~]# cat /tmp/check_engine.sql
ALTER TABLE tt.a1 engine=innodb;
ALTER TABLE tt.a2 engine=innodb;
ALTER TABLE tt.a3 engine=innodb;
ALTER TABLE world.t1 engine=innodb;
-- 接下来,就可以执行这个脚本了
[root@cs ~]# mysql -uroot -p </tmp/check_engine.sql
Enter password:
-- 此时,就成功了
SELECT table_schema,table_name,ENGINE
FROM information_schema.tables
WHERE table_schema IN ("world", "tt");
接下来就是本篇的主角了,关于InnoDB那些事儿。
about innodb
从MySQL5.5版本开始,InnoDB替代MyISAM正式成为MySQL的默认存储引擎,提高了可靠性和性能。
InnoDB主要功能
| 功能 | 支持 | 功能 | 支持 |
|---|---|---|---|
| 存储限制 | 64TB | 索引高速缓存 | 是 |
| 多版本并发控制(MVCC) | 是 | 数据高速缓存 | 是 |
| B树索引 | 是 | 自适应散列索引 | 是 |
| 群集索引 | 是 | 复制 | 是 |
| 数据压缩 | 是 | 更新数据字典 | 是 |
| 数据加密 | 是 | 地理空间数据类型 | 是 |
| 查询高速缓存 | 是 | 地理空间索引 | 否 |
| 事务 | 是 | 全文搜索索引 | 是 |
| 锁粒度 | 行 | 群集数据库 | 否 |
| 外键 | 是 | 备份(热备)和恢复 | 是 |
| 文件格式管理 | 是 | 快速索引创建 | 是 |
| 多个缓冲池 | 是 | performance_schema | 是 |
| 更改缓冲 | 是 | 自动故障恢复(ACSR) | 是 |
InnoDB存储引擎逻辑存储结构
在InnoDB存储引擎中,所有数据都存放在表空间(tablespace)中,表空间由段(segment)、区(extent)、页(page)、行(Row)组成,它们的关系如下图:
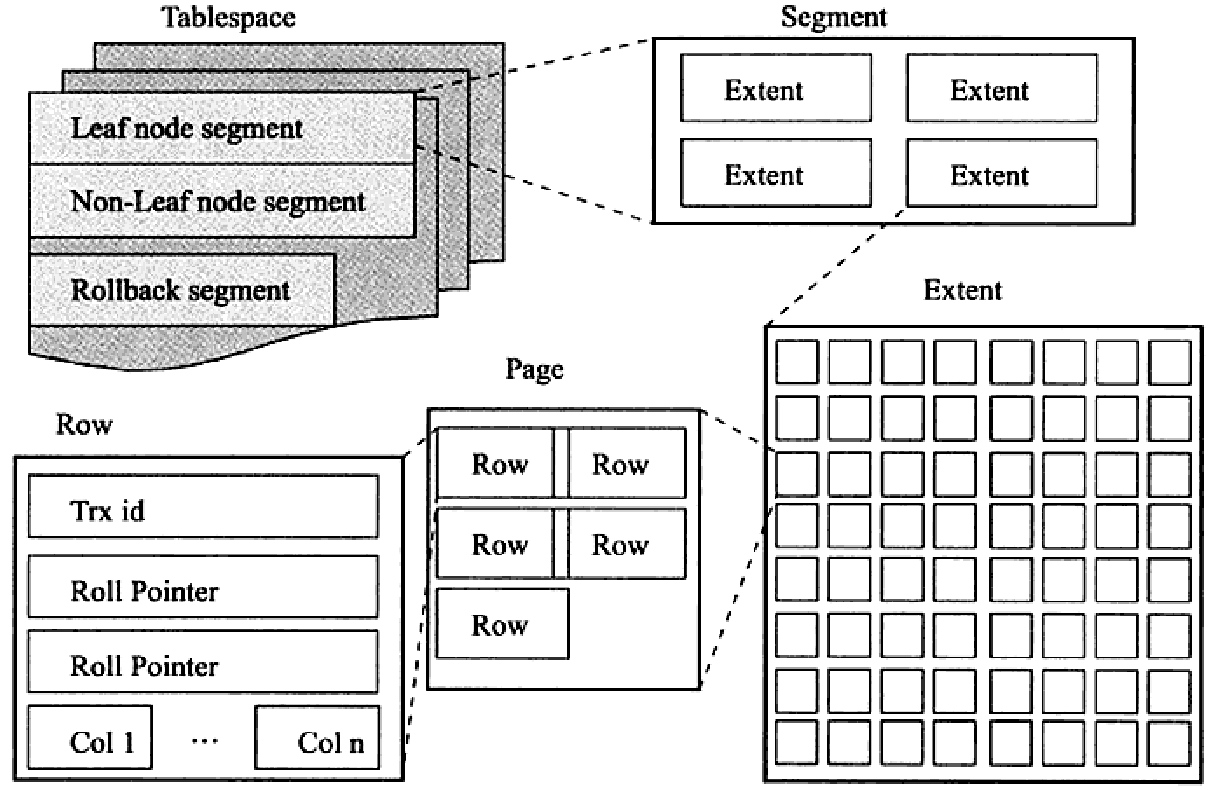
段(segment)
表空间由各个段组成,常见的段类型有:数据段、索引段、回滚段。
由于InnoDB表采用的是聚簇索引,所以数据段可以看成是B+树的叶子节点,索引段可以看成是B+树的非索引节点。
区(extend)
一个段由多个区组成,区由多个连续页组成,每个区的大小为1MB,默认情况下,每个页的大小为16KB:
mysql> select @@innodb_page_size;
+--------------------+
| @@innodb_page_size |
+--------------------+
| 16384 |
+--------------------+
1 row in set (0.00 sec)
即一个区中一共有64个连续页。用户可通过innodb_page_size参数设置每个页的大小。
默认情况下,用户在创建一张InnoDB表后,该表对应的独立表空间文件为96KB,在每个段开始时会先用32个碎片页来存放数据,使用完这32个页后才是64个连续页的申请。这么做是考虑到有些表的数据相对来说是比较少的,可以节省磁盘空间,因为申请64个页(即1个区)需要1MB空间。
页(page)
页是InnoDB磁盘管理的最小单位,默认大小为16KB。常见的页类型有:
- 数据页(B-tree Node)
- undo页(undo Log Page)
- 系统页(System Page)
- 事务数据页(Transaction system Page)
- 插入缓冲位图页(Insert Buffer Bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页(compressed BLOB Page)
行(Row)
InnoDB存储引擎将数据按行进行存放,每个页最多存放7992行记录(16KB除以2~200),InnoDB存储引擎提供了Compact、Redundant、Compressed、Dynamic四种格式来存放行记录数据,用户可通过命令show table status like 'table_name'来查看该属性。
其中Row_format就是行记录格式。
InnoDB存储引擎物理存储结构
最直观的物理存储结构,我们能看到的,就是MySQL的存储目录data:
[root@cs ~]# ll /data/mysql
总用量 188468
-rw-r----- 1 mysql mysql 56 6月 8 09:25 auto.cnf
-rw-r----- 1 mysql mysql 7386 8月 17 17:06 cs.err
-rw-r----- 1 mysql mysql 4 9月 21 11:24 cs.pid
drwxr-x--- 2 mysql mysql 20 8月 17 18:00 data_test
-rw-r----- 1 mysql mysql 596 9月 1 03:11 ib_buffer_pool
-rw-r----- 1 mysql mysql 79691776 9月 22 16:35 ibdata1
-rw-r----- 1 mysql mysql 50331648 9月 22 16:35 ib_logfile0
-rw-r----- 1 mysql mysql 50331648 9月 15 16:25 ib_logfile1
-rw-r----- 1 mysql mysql 12582912 9月 22 16:35 ibtmp1
drwxr-x--- 2 mysql mysql 4096 6月 8 09:25 mysql
drwxr-x--- 2 mysql mysql 8192 6月 8 09:25 performance_schema
drwxr-x--- 2 mysql mysql 60 9月 17 21:22 pp
drwxr-x--- 2 mysql mysql 160 8月 26 00:02 school
drwxr-x--- 2 mysql mysql 8192 6月 8 09:25 sys
drwxr-x--- 2 mysql mysql 4096 9月 22 16:35 tt
drwxr-x--- 2 mysql mysql 172 9月 22 16:20 world
其中:
ib_logfile0 ~ ib_logfile1:REDO日志文件,事务日志文件ibdata1:系统数据字典(统计信息),UNDO表空间等数据ibtmp1:临时表空间磁盘位置,存储临时表
基于InnoDB的表都会建立:
frm:存储表的字段信息ibd:表的数据行和索引
表空间
https://dev.mysql.com/doc/refman/5.7/en/innodb-tablespace.html
MySQL在5.5版本(能够上生产环境,稳定的版本)才有了表空间(Table space)的概念,恰好这个时间节点是在被Oracle收购后.....
这里简单说说表空间。虽然MySQL将数据存储到段、区、页中,但是这其中还经历了一个逻辑层 ,物理层面的逻辑层!这里称之为表空间。
PS:一般提到表空间的概念,基本上都是说的是Oracle表空间,这里MySQL可能借鉴了......你有兴趣也可以参考LVM的原理,都类似。
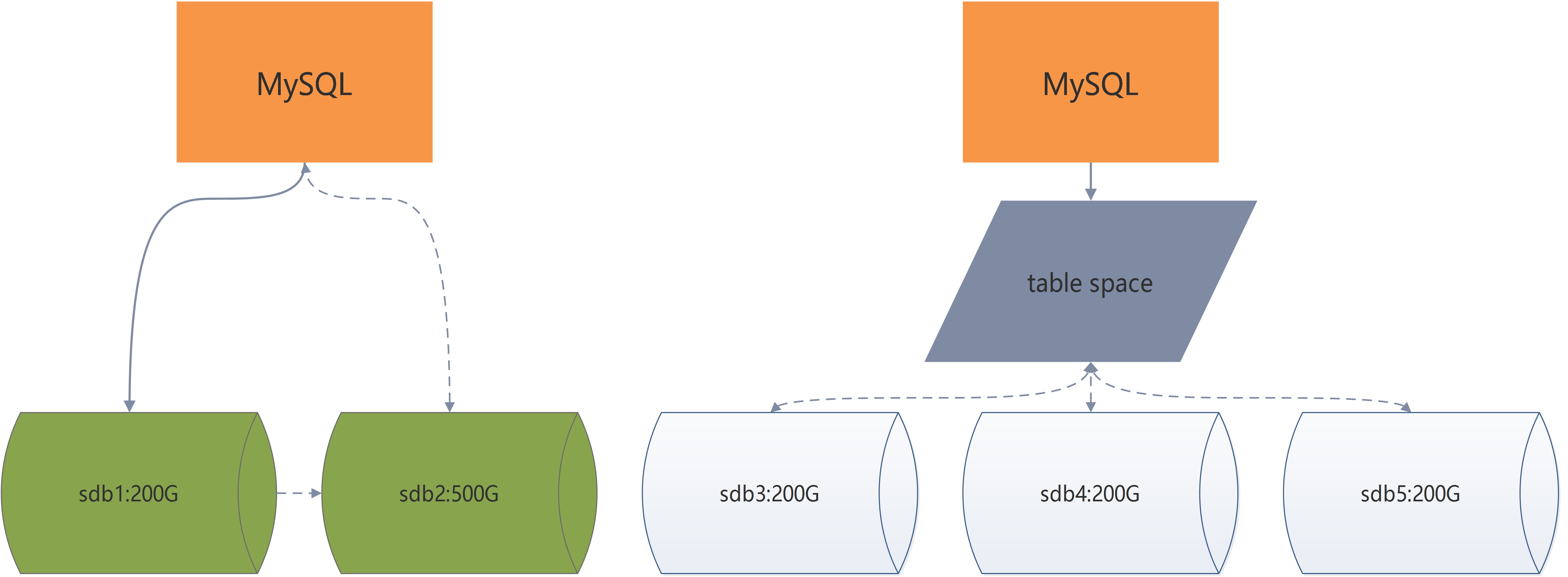
如上图左侧部分,如果MySQL将ibd文件直接从内存中写入到sdb1磁盘中,如果有一天该sdb1磁盘满了怎么办?一般来说可以将sdb1中的数据导入到磁盘空间更大的磁盘sdb2中,然后MySQL后续直接往sdb2中写入数据即可,直到有一天.........
MySQL为了解决这个问题,也可能是借鉴了Oracle.......在MySQL层和磁盘层中间再加上一层逻辑层,即表空间,MySQL将ibd文件都存储到table space层,后续的磁盘都可以动态的挂载到table space层..........
而在MySQL中的表空间,经过发展现在有共享表空间和独立表空间两个概念。
共享表空间
Innodb所有数据保存在一个单独的表空间里面,我们称这个表空间为共享表空间,毕竟所有表都在这个共享表空间里面嘛!
这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所以其大小限制不再是文件大小的限制,而是其自身的限制。从Innodb的官方文档中可以看到,其表空间的最大限制为64TB,也就是说,Innodb的单表限制基本上也在64TB左右了,当然这个大小是包括这个表的所有记录、索引和其他相关数据。
随着MySQL初始化时,默认的共享表空间也随之建立,即数据目录中的ibdata1文件(后续可以是多个),并且初始就一个ibdata1文件,且文件的初始大小为12MB,然后随着数据量的推移,以64MB为单位增加。
可以通过以下参数来查看该ibdata1文件:
SELECT @@innodb_data_file_path;
-- SHOW VARIABLES LIKE 'innodb_data_file%';
SELECT @@innodb_autoextend_increment;
也可以vim /etc/my.cnf配置文件:
# ---------- 在默认的datadir目录下设置多个 ibdata 文件 ----------
[mysqld]
innodb_data_file_path=ibdata1:1G;ibdata2:12M:autoextend:max:512M # 自增长到最大512MB
# innodb_data_file_path=ibdata1:1G;ibdata2:12M:autoextend # 初始12M,自增长直到64TB
# 另外,自增长只针对后面的ibdata文件,上面的ibdata1就是写死的1GB大小了
# ---------- 在指定目录设置多个 ibdata 文件 ----------
innodb_data_home_dir= /data/mysql/mysql3307/data
innodb_data_file_path=ibdata1:1G;ibdata2:12M:autoextend # 会在 innodb_data_home_dir 目录下设置多个 ibdata 文件
# ---------- 在指定目录设置多个 ibdata 文件 ----------
innodb_data_home_dir= # innodb_data_home_dir的值保留为空,但该参数不能不写
innodb_data_file_path=ibdata1:12M;/data/mysql/mysql3307/data/ibdata2:12M:autoextend
# 如上例子会在 datadir 下创建 ibdata1;会在 /data/mysql/mysql3307/data/ 目录创建 ibdata2
还有另一种情况就是:当没有配置innodb_data_file_path时,默认innodb_data_file_path = ibdata1:12M:autoextend;当需要改为1G时,不能直接在配置文件把 ibdata1 改为 1G ;而应该再添加一个 ibdata2:1G ,如innodb_data_file_path = ibdata1:12M;ibdata2:1G:autoextend。
另外,一般,对于共享表空间的设置,在MySQL初始化之前就设计好了,那么在MySQL初始化的时候,按照你的设置,就自动的建立好相应的文件了。
MySQL5.6版本,共享空间虽然得以保留,但也只用来存储:数据字典、UNDO、临时表
而在5.7版本,临时表被独立出去了....
8.0版本,UNDO也被独立出去了.....
点击以下链接查看架构演示:
独立表空间
从5.6开始,默认表空间不再使用共享表空间,替换为独立表空间,主要存储的是用户数据。
存储特点:每个表都有自己的表空间,表空间内存放着ibd文件,idb文件被称之为表空间的数据文件,主要用来存储数据行以及索引信息;而基本的表结构和元数据存储在frm文件中。
除了上述的frm和ibd文件之外,还搭配的有:
Redo Log,重做日志。Undo Log,存储在共享表空间中,回滚日志。ibtmp,临时表,存储在JOIN和UNION操作产生的临时数据,用完自动删除。
独立表空间/共享表空间切换
我们可以对表的元数据、数据、索引信息进行单独管理,那么也能单独对表空间进行管理,比如设置表使用共享表空间。
通过innodb_file_per_table参数来控制MySQL对表使用共享表空间还是独立表空间,而默认值1表示使用独立表空间(一个表就是一个独立的idb文件),而改成0就是使用共享表空间。
mysql> select @@innodb_file_per_table;
+-------------------------+
| @@innodb_file_per_table |
+-------------------------+
| 1 |
+-------------------------+
1 row in set (0.00 sec)
现在我们测试一下,将innodb_file_per_table的值改为0,然后新建一张表(修改操作对原来建立的表没有影响,只会影响修改值后新建的表):
mysql> set global innodb_file_per_table=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select @@innodb_file_per_table;
+-------------------------+
| @@innodb_file_per_table |
+-------------------------+
| 0 |
+-------------------------+
1 row in set (0.00 sec)
mysql> create table tt.t6(id int);
Query OK, 0 rows affected (0.03 sec)
现在,我们来看磁盘上的关于tt数据库下t6表的物理存储结构:
[root@cs ~]# ll /data/mysql/tt/t6*
-rw-r----- 1 mysql mysql 8556 10月 20 16:59 /data/mysql/tt/t6.frm
[root@cs ~]# ^C
[root@cs ~]# ll /data/mysql/tt/t5*
-rw-r----- 1 mysql mysql 8608 9月 29 10:14 /data/mysql/tt/t5.frm
-rw-r----- 1 mysql mysql 98304 9月 29 10:16 /data/mysql/tt/t5.ibd
上述结果中,t5表是之前建立的表,它有ibd和frm两个文件分别存储数据、索引和元数据信息;而innodb_file_per_table=0后创建的t6表,它的物理存储结构中,就只剩下了frm文件,用来存储元数据信息,而数据和索引信息不在存储自己的独立表空间中,即自己的idb文件中了,而是存储到了共享表空间中了(idbata)。
这里我们只是进行测试,生产中很少用到,所以,别忘了将innodb_file_per_table值改回来。
表空间迁移
alter table tt.t1 discard tablespace;
alter table tt.t2 import tablespace;
buffer pool
MySQL使用缓冲池(buffer pool)来进一步提高InnoDB的性能。
你也可以称缓冲池为缓冲区池、缓冲区、缓存区,都是一个意思。
先来了解一个概念:
- 数据页(data page),MySQL记录在磁盘上以页的形式存储
- 脏页,内存脏页,磁盘数据页在内存中发生了修改,在刷写到磁盘数据页之前,我们把内存中的数据页成之为脏页;脏页产生的过程称为之构建脏页
buffer pool缓冲池缓存了什么?
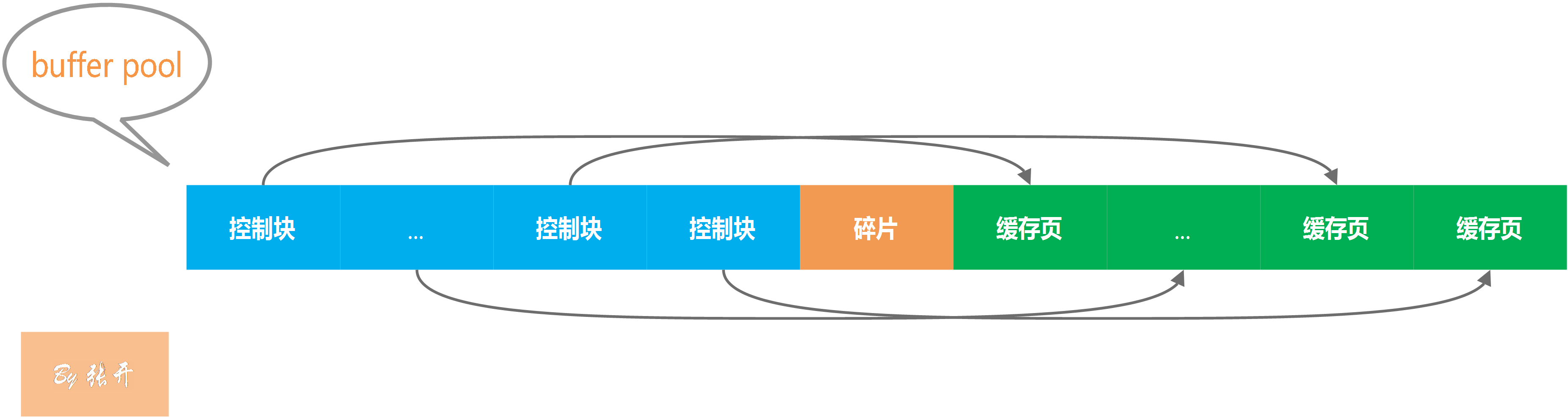
buffer pool中缓存了包括索引、一些表相关数据、锁信息。
buffer pool同样采用了页(默认每页16KB)的形式在内存中管理数据,并且每个页设置一个控制信息块对应一个控制块,这个控制块记录了该页所属的表空间号、页号、缓存页在bufferpool中的地址等信息,它的结构如下:
预读
那InnoDB是如何管理buffer pool呢?在具体介绍之前,先来了解下"预读"的概念。
什么是预读?
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
预读为什么有效?
数据访问,通常都遵循"集中读写"的原则,使用一些数据,大概率会使用附近的数据,这就是所谓的"局部性原理",它表明提前加载是有效的,确实能够减少磁盘IO。
按页(4K)读取,和InnoDB的缓冲池设计有啥关系?
- 磁盘访问按页读取能够提高性能,所以缓冲池一般也是按页缓存数据。
- 预读机制启示了我们,能把一些"可能要访问"的页提前加入缓冲池,降低未来的磁盘IO操作。
InnoDB使用两种预读算法来提高I/O性能:线性预读(linear read-ahead)和随机预读(randomread-ahead):
- 线性预读(linear read-ahead):线性预读有一个很重要的参数
innodb_read_ahead_threshold,它控制是否将下一个区(extent)预读到buffer pool中。- 如果一个extent中被顺序读取的page大于等于
innodb_read_ahead_threshold参数的值时,Innodb会异步的将下一个extent读取到buffer pool中。innodb_read_ahead_threshold可以设置为0-64的任何值,默认值为56,值越高,访问模式检查越严格。 - 例如,如果将值设置为48,则InnoDB只有在顺序访问当前extent中的48个page时才触发线性预读请求,将下一个extent读到内存中。反之如果设置为2,即使当前extent中只有2个page被连续访问,Innodb也会异步的将下一个extent读取到buffer pool中。
- 如果禁用该变量,只有当顺序访问到extent的最后一个page的时候,Innodb才会将下一个extent放入到buffer pool中。
- 如果一个extent中被顺序读取的page大于等于
- 随机预读(randomread-ahead):随机预读方式则是表示当同一个extent中的一些(可以不连续)page被读取到buffer pool中时,Innodb会将该extent中的剩余page一并读到buffer pool中,由于随机预读方式给Innodb code带来了一些不必要的复杂性,同时在性能也存在不稳定性,在5.5中已经将这种预读方式废弃。要启用此功能,请将配置变量设置innodb_random_read_ahead为ON。
线性预读着眼于将下一个extent提前读取到buffer pool中,而随机预读着眼于将当前extent中的剩余的page提前读取到buffer pool中。
相关参数:
mysql> mysql> show variables like "%read_ahead%";
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| innodb_random_read_ahead | OFF |
| innodb_read_ahead_threshold | 56 |
+-----------------------------+-------+
2 rows in set (0.00 sec)
了解了预读相关 概念,再来看InnoDB用了什么算法来管理buffer pool。
传统的LRU算法对缓冲页进行管理
在缓存技术中,最常见的缓存管理算法就是LRU(Least Recently Used)算法了,例如memcache就是采用LRU算法来进行缓存页置换管理,但MySQL并没有原样采用LRU算法,而是在LRU算法基础上做了优化。
更多关于LRU算法,参见:https://www.cnblogs.com/Neeo/articles/13882916.html
那么传统的LRU算法如何进行缓冲页管理的呢?
最常见的用法就是把缓冲池的页放到LRU(链表)的头部,作为最近访问的元素,从而最晚被淘汰,这里又分为两种情况:
- 页已经在缓冲池里,那就只做"移至"LRU头部的动作,而没有页被淘汰。
- 页不在缓冲池里,除了做"放入"LRU头部的动作,还要做"淘汰"LRU尾部页的动作。
来个例子,如下图,缓冲池中LRU的长度为10,并且缓冲了页号如图所示的这些页。
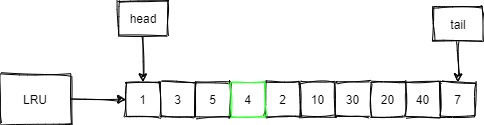
现在,我们要访问的数据在4号页中,那要做的动作:
- 首先,判断4号页在不在缓冲池中。
- 如上图很明显是在的,就把4号页移动到LRU的头部,此时并没有页被淘汰,其结果如下图所示。
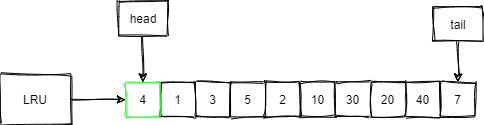
现在,我们访问数据在50号页内:
- 首先,页号为50的页并不在LRU内。
- 把50号页放到LRU链表的头部,同时淘汰尾部7号页,如下图所示:
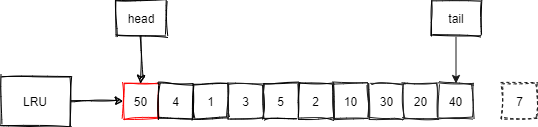
由上面两个例子可以看到,传统的LRU算法十分直观,也有很多软件在采用,那么MySQL为啥不直接使用呢?我们继续探讨。
MySQL优化LRU算法对脏页进行管理
接上小节,为啥MySQL不直接使用传统LRU算法管理脏页呢?因为这里存在两个问题:
- 预读失败
- 缓冲池污染
分别来说两个问题。
什么是预读失败?
经过预读(read-ahead),提前把页放入了缓冲池中,但最终MySQL并没有从这些预读的页中读取数据,我们称之为预读失效。
那如何对预读失败进行优化?
- 让预读失败的页,停留在缓冲池LRU里的时间尽可能短。也就是说,让这些数据放在LRU的尾部,尽快淘汰掉。
- 让真正被读取的页,才放入LRU的头部。
这样来保证真正被读取的热点数据留在缓冲池中的时间尽可能的长。
InnoDB的具体优化是,将传统的LRU算法中的一个链表,抽象为两个链表:
- 新生代(new sublist)链表。
- 老生代(old sublist)链表。
然后将新/老生代的两个链表首尾相连,即新生代的尾部tail连接老生代的头部head,并且新生代和老生代的分配比例一般是7:3。其实就是一个循环链表,只不过抽象为两部分。
此时如果有预读的页加入缓冲池中,它此时只能加入到老生代的头部,接下来的它面临着:
- 如果数据被读取,即预读成功,才会从老生代的头部移动到新生代的头部。
- 如果数据没有被读取,即预读失败,则不会从老生代移动到新生代,这样这些数据将更早的被淘汰。
举个例子,如下图,LRU的长度为10,前70%为新生代,后30%为老生代,且新老生代首尾相连。
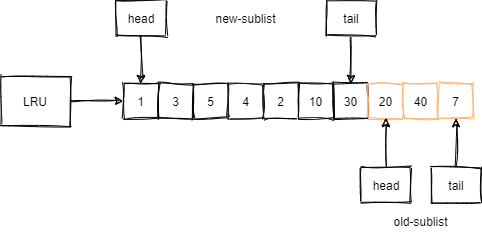
例如,有一个页号为50的新页被加载到缓冲池中:
- 50号页首先被插入到老生代的头部,老生代的尾部(也是整个链表的尾部)的页会被淘汰掉。
- 假如50号页最终预读失败,那么它将比新生代的数据更早的淘汰。
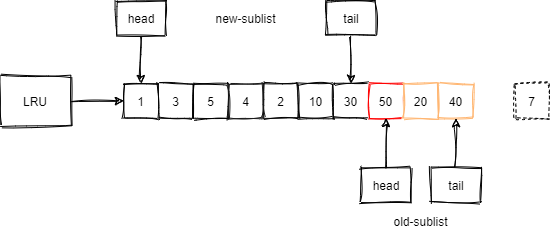
假如,50号页预读成功了,例如SQL最终访问了该页内的某行记录:
- 50号页将会从老生代头部移动到新生代的头部。
- 原新生代的尾部页会被挤到老生代的头部,此时没有页从整个LRU中被淘汰。
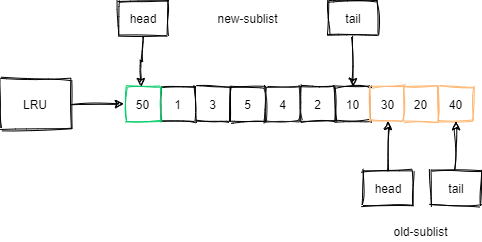
有上例可以看到,InnoDB优化后的LRU能够很好的解决预读失败的问题。
现在InnoDB需要解决传统LRU的第二个问题——缓冲池污染的问题。
那么什么是缓冲池污染?
当某个SQL语句,要批量扫描大量数据甚至是全表扫描时,如果把这些数据一股脑都缓冲到缓冲池中,可能导致把缓冲池的所有页都置换出去,即导致大量的热点数据被置换,此时MySQL的性能会急剧下降,这种情况叫做缓冲池污染。
例如,执行下面的SQL:
select * from userinfo where name like "%zhangkai%";
虽然,结果集可能只有少量的数据,但要知道在like语句中首位使用%是不会走索引的,必须全表扫描,此时就需要访问大量的页,那将会:
- 把页加载到缓冲池中,此时插入老生代头部。
- 从页中读取相关row,插入到新生代的头部。
- 匹配row的name字段,把符合条件的,加入到结果集中。
- 一直重复上述步骤,直到扫描完所有页中的row.......
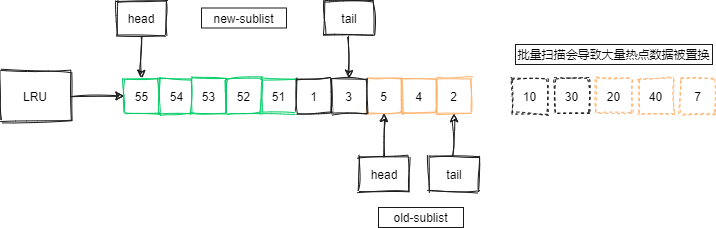
如此一来,虽然结果集拿到了,但这些数据很可能只会被访问一次,而真正的热点数据被大量置换出去了......
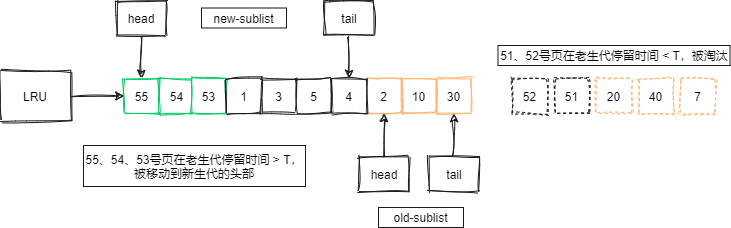
为了解决这类扫描大量数据导致缓冲池污染的问题,MySQL在缓冲池中加入一个老生代停留时时间窗口机制:
- 假设老生代停留时间为T。
- 插入老生代头部的页,即使立刻被访问,但也不会立刻被放入到新生代的头部。
- 只有满足被访问且在老生代停留时间大于T,才会被放入到新生代的头部。
如下图,在原LRU基础上,有页号为51、52、53、54、55的页将被一次被访问:
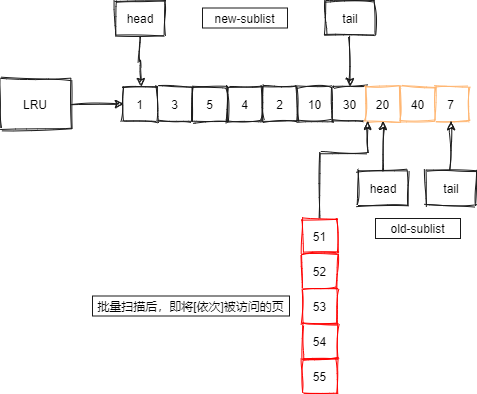
如下图,如果此时没有老生代停留时间策略,那么这些批量被访问的页将大量的替换原有的热点数据:
如下图,当加入老生代停留时间策略后,短时间内被大量加载的页,并不会被立刻插入新生代头部,而是优先淘汰那些不满足在老生代停留时间大于T的页,而那些在老生代里停留时间大于T的页,才会被插入到新生代的头部:
buffer pool相关参数
了解了buffer pool的原理和算法原理,接下来就大致说说相关的参数和设置:
mysql> show variables like "%innodb_buffer_pool%";
+-------------------------------------+----------------+
| Variable_name | Value |
+-------------------------------------+----------------+
| innodb_buffer_pool_chunk_size | 134217728 |
| innodb_buffer_pool_dump_at_shutdown | ON |
| innodb_buffer_pool_dump_now | OFF |
| innodb_buffer_pool_dump_pct | 25 |
| innodb_buffer_pool_filename | ib_buffer_pool |
| innodb_buffer_pool_instances | 1 |
| innodb_buffer_pool_load_abort | OFF |
| innodb_buffer_pool_load_at_startup | ON |
| innodb_buffer_pool_load_now | OFF |
| innodb_buffer_pool_size | 134217728 |
+-------------------------------------+----------------+
10 rows in set (0.00 sec)
其中:
innodb_buffer_pool_size,缓存区大小,默认是128MBinnodb_buffer_pool_chunk_size,当增加或者减少innodb_buffer_pool_size时,操作以块(chunk)形式执行。默认块大小是128MBinnodb_buffer_pool_instances,当buffer pool设置的较大时(超过1G或者更大),innodb会把buffer pool划分为几个instances,这样提高读写操作的并发,减少竞争。
我们知道当增加或者减少buffer pool大小的时候,实际上是操作的chunk。所以buffer pool的大小必须是innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances,如果配置的innodb_buffer_pool_size不是innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的倍数,buffer pool的大小会自动调整为innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的倍数,自动调整的值不少于指定的值。例如指定的buffer pool size是9G,instances的个数是16,chunk默认的大小是128M,那么buffer会自动调整为10G。
PS:一般建议 innodb_buffer_pool_size 大小设置为物理内存的 75-80%。
mysql> show engine innodb status\G -- 查询MySQL buffer pool 的使用状态
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992
Dictionary memory allocated 116177
Buffer pool size 8192 -- 单位:页 16字节 8192 * 16 / 1024 = 128 MB
Free buffers 7728
Database pages 464
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 429, created 35, written 37
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 464, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
see also : MySQL5.7 14.8.3.1 Configuring InnoDB Buffer Pool Size
buffer pool刷写策略
buffer pool中的脏页何时刷写到磁盘这个问题!
这里用到的一些参数:
mysql> show variables like "%innodb_io_cap%";
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_io_capacity | 200 |
| innodb_io_capacity_max | 2000 |
+------------------------+-------+
2 rows in set (0.00 sec)
mysql> show variables like "%innodb_max_dirty%";
+--------------------------------+-----------+
| Variable_name | Value |
+--------------------------------+-----------+
| innodb_max_dirty_pages_pct | 75.000000 |
| innodb_max_dirty_pages_pct_lwm | 0.000000 |
+--------------------------------+-----------+
2 rows in set (0.00 sec)
mysql> select @@innodb_lru_scan_depth;
+-------------------------+
| @@innodb_lru_scan_depth |
+-------------------------+
| 1024 |
+-------------------------+
1 row in set (0.00 sec)
mysql> select @@innodb_flush_neighbors;
+--------------------------+
| @@innodb_flush_neighbors |
+--------------------------+
| 1 |
+--------------------------+
innodb_io_capacity参数指定刷新脏页的数量,innodb_io_capacity_max是最大值,在I/O能力允许的情况下可以调高innodb_io_capacity值来提高每次刷新脏页的值,提高性能。另外,innodb_max_dirty_pages_pct参数控制脏页的比例,默认是75%,当脏页比例超过75%,就会触发checkpoint刷盘,刷盘到innodb_max_dirty_pages_pct_lwm参数时,改为自适应刷写策略,简单理解为当脏页占比越高,刷脏页的强度越大,否则慢慢变小。
innodb_lru_scan_depth指定每次刷新脏页的数量。
这里再来了解一个有趣的策略。一旦一个查询请求需要在执行过程中先 flush 掉一个脏页时,这个查询就可能要比平时慢了。而 MySQL 中的一个机制,可能让你的查询会更慢:在准备刷一个脏页的时候,如果这个数据页旁边的数据页刚好是脏页,就会把这个“邻居”也带着一起刷掉;而且这个把“邻居”拖下水的逻辑还可以继续蔓延,也就是如果邻居的邻居也是脏页的话,那它也会被放到一起刷。
在 InnoDB 中,innodb_flush_neighbors参数就是用来控制这个行为的,值为1的时候会有上述的"连坐"机制,值为0时表示不找邻居,自己刷自己的。找"邻居"这个优化在机械硬盘时代是很有意义的,可以减少很多随机 I/O。机械硬盘的随机 IOPS(每秒的读写次数) 一般只有几百,相同的逻辑操作减少随机 I/O 就意味着系统性能的大幅度提升。而如果使用的是 SSD 这类 IOPS 比较高的设备的话,建议把 innodb_flush_neighbors的值设置成 0。因为这时候 IOPS 往往不是瓶颈,而"只刷自己",就能更快地执行完必要的刷脏页操作,减少 SQL 语句响应时间。
在 MySQL 8.0 中,innodb_flush_neighbors参数的默认值已经是0了。
double write
buffer pool中的脏页刷盘时,还采用了double write机制,来保证数据的安全性,想要了解double write,我们先来了解一下partial page write。
partial page write
innodb page size 是16KB,如果在写入磁盘数据页时,遇到断电或者系统崩溃,很可能导致16KB的数据页只有部分写入到了磁盘上,另外的丢了,这就是partial page write的问题。
double write
innodb为了解决partial page write的问题,采用double write机制。
double write功能由innodb_doublewrite参数控制是否开启,MySQL5.7中,默认值为1是开启的,你也可以设置为0关闭它:
mysql> select @@innodb_doublewrite;
+----------------------+
| @@innodb_doublewrite |
+----------------------+
| 1 |
+----------------------+
1 row in set (0.00 sec)
double write也有自己的内存区域double write buffer和磁盘文件两部分组成:
[root@cs ~]# ll /data/mysql/ibdata*
-rw-r----- 1 mysql mysql 79691776 11月 17 20:58 /data/mysql/ibdata1
PS:double write和undo log一样都存放于共享表空间中。
double write的工作流程
当buffer pool的脏页需要刷写到磁盘数据页时,先使用memcopy将脏页拷贝到double write buffer,之后double write bffer再分为2次写入磁盘:
- 第一次,从double write buffer顺序写入(fsync)到共享表空间中,留作备份。
- 第二次,从double write buffer再离散写入各个表空间中,此时如果断电或者意外宕机,就可以从共享表空间中恢复数据了。
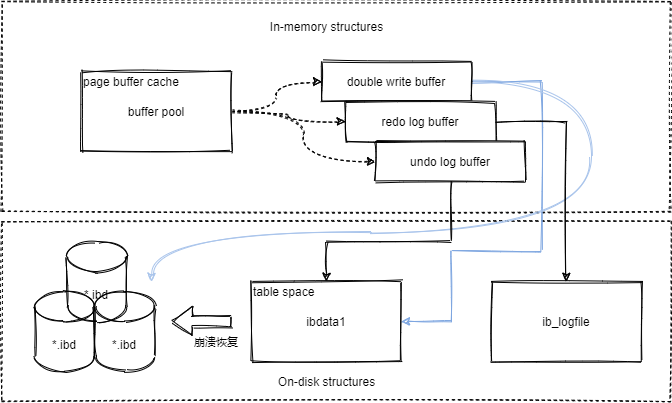
double write保证了数据的安全性,但也因此多了很多的fsync操作,对性能有一定的影响,这在实际工作中要根据应用场景决定是否开启。
事务
首先,只有存储引擎是innodb的表才支持事务........
事务就是一组原子性的SQL查询,或者说是一个独立的工作单元,如果数据库引擎能够成功地对数据库应用该组查询的全部语句,那么就执行该组语句。如果其中有任何一条语句因为崩溃或者其他原因无法执行,那么所有的语句都不会执行。即事务内的语句,要么全部执行成功,要么全部执行失败。
事务的ACID特性
ACID表示原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability),一个运行良好的事务处理系统,必须具备这些标准特性。
- 原子性(atomicity):一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
- 一致性(consistency):数据库总是从一个一致性状态转换到另一个一致性状态。
- 隔离性(isolation):通常来说,一个事务所做的修改在最终提交之前,对其他事务是不可见的。也可以说事务之间不相互影响。
- 持久性(durability):一旦事务提交,则其所做的修改就会永久的保存到数据库中,此时即使系统崩溃,修改的数据也不会丢失。
多说一点,持久性是一个有点模糊的概念,因为实际上持久性也分很多不同的级别,有些持久性策略能提供非常强的安全保证,而有些则未必,而且不可能有能够做到100%的持久性保证的策略,不然还要备份干啥?
事务的生命周期(事务控制语句)
事务的开始
begin
说明,在5.5以后的版本,不需要手动begin,只要你执行的是一个DML语句,会自动在前面加一个begin命令。
事务的结束
commit:提交事务,完成一个事务,一旦事务提交成功,就具备了ACID的特性了。
rollback:回滚事务,将内存中,已执行过的操作,回滚到事务开始之前。
自动提交策略(autocommit)
为了避免有些事务没有提交的情况,MySQL5.6开始有了自动提交策略,即自动帮我们commit,通过autocommit参数可以发现该策略是否打开,1是默认打开,0是关闭。
select @@autocommit;
set session autocommit=0; -- 等价于 set autocommit=0;
set global autocommit=0;
-- 配置文件修改 vim /etc/my.cnf
[mysqld]
autocommit=0
当在autocommit=0时,我们可以动手来练习一下事务,过程就是begin之后,执行一个操作,然后rollback和commit操作来观察事务的执行和回滚:
-- 确保 autocommit=0
mysql> select @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 0 |
+--------------+
1 row in set (0.00 sec)
-- 现在,t2表有一条记录
mysql> select * from t2;
+----+--------+----------------------------------+
| id | user | pwd |
+----+--------+----------------------------------+
| 1 | 张开 | 9B9FC7A9EA433FB08DA3AB8EB22BDAF1 |
+----+--------+----------------------------------+
1 row in set (0.00 sec)
来演示begin-->rollback操作:
mysql> begin; -- 开始事务
Query OK, 0 rows affected (0.00 sec)
mysql> delete from t2 where id=1; -- 执行删除操作
Query OK, 1 row affected (0.00 sec)
mysql> select * from t2; -- 删除成功
Empty set (0.00 sec)
mysql> rollback; -- 回滚
Query OK, 0 rows affected (0.01 sec)
mysql> select * from t2; -- 数据恢复
+----+--------+----------------------------------+
| id | user | pwd |
+----+--------+----------------------------------+
| 1 | 张开 | 9B9FC7A9EA433FB08DA3AB8EB22BDAF1 |
+----+--------+----------------------------------+
1 row in set (0.00 sec)
上面的事务执行到删除成功,其实事务并没有执行完毕,所以可以rollback。
再来看begin-->commit操作:
-- 还是之前的t2表,还是那一条数据
mysql> begin; -- 开始事务
Query OK, 0 rows affected (0.00 sec)
mysql> delete from t2 where id=1; -- 删除操作
Query OK, 1 row affected (0.00 sec)
mysql> commit; -- 事务提交成功。注意,已经提交的事务无法回滚
Query OK, 0 rows affected (0.01 sec)
mysql> select * from t2; -- 再查就没有数据了
Empty set (0.00 sec)
mysql> rollback; -- 此时,再rollback也不行了,因为上一个事务结束了
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t2; -- 仍然是空的
Empty set (0.00 sec)
最后,别忘了将autocommit的值改为1。
隐式提交语句
无论是begin还是autocommit都算是显式的事务提交,但有些情况也会自动的触发事务并提交,来看都有哪些情况或者语句:
-- 隐式提交的sql语句
begin
语句1
语句2
begin -- 当上一个事务没有提交完成,又开始了一个begin,那在本次begin之前,上一个begin会自动提交
-- 当在事务中执行了下面语句也会将之前的事务提交
set autocommit=1
-- 导致提交的非事务语句:
DDL语句:(alter,create,drop)
DCL语句:(grant,revoke,set password)
锁定语句:(lock tables,unlock tables)
-- 其他导致隐式提交的语句示例:
truncate table
load data infile
select for update
所以,在执行自己的事务期间,要尽量的避免上述的隐式提交语句出现,避免干扰自己的事务逻辑。
InnoDB事务如何保证ACID?
事务的工作流程
如上图,现在有这样一条事务要执行update t1 set name='A' where name='B';。
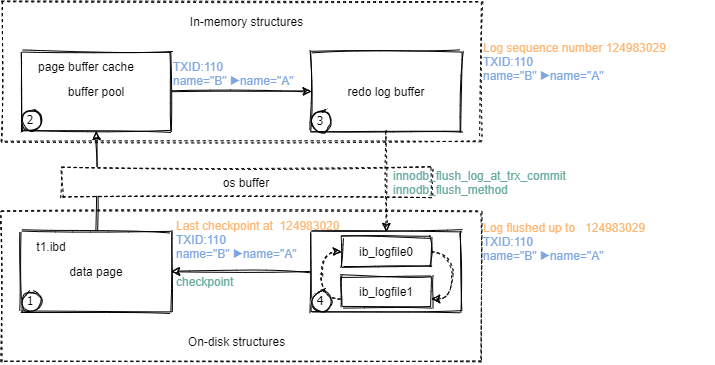
如上图,就是一条事务的执行过程,而我们本小节就是研究在其过程中的细节,进而理解Innodb是如何保证事务的ACID的。
完整的架构:https://dev.mysql.com/doc/refman/5.7/en/innodb-architecture.html
首先,你应该留意的概念:
- redo log,重做日志,主要在事务中实现持久性
- redo log file,磁盘上的redo log
- red log buffer,redo log的缓存
- undo log,提供事务的回滚和MVCC
- buffer pool,缓冲区池,缓冲数据和索引
- LSN,日志序列号,在事务的不同阶段,LSN号页在递增,在CSR时提供依据
- WAL(Write-Ahead LOG),日志优先写,先写日志,再写磁盘,实现持久化
- CKPT(checkpoint),检查点,根据不同的策略将脏页刷写到磁盘
- TXID,innodb为每个事务都会生成一个事务号,伴随整个事务的过程
现在我们来大致了解事务的执行过程:
现在有一个update t1 set name="B" where name="A";这样的一个事务被提交到MySQL内存:
begin开始后,将加载到内存的数据页内的name="B"的位置修改为name="A"。- 根据WAL策略,update操作不会第一时间刷写到磁盘数据页,而是将这一更改变化进行记录,记录的是对磁盘上的某个表空间的某个数据页的偏移量为xxx处的xx数据做了修改,修改后的值为多少,另外记录LSN和TXID等其他信息。将这个记录写入到redo log buffer。这个redo log的状态设置为
prepare,意味准备提交的事务。 - 当这个事务
commit后,再将这条记录的状态设置为commit,并且由redo log buffer刷写到了磁盘的ib_logfile中。- redo log buffer和磁盘上的redo log file之间还要经过system os buffer,所以
innodb_flush_log_at_trx_commit和innodb_flush_method这两个参数决定了redo log buffer中的日志何时刷写到磁盘的redo log file中,是否经过system os buffer。
- redo log buffer和磁盘上的redo log file之间还要经过system os buffer,所以
- 当redo log被刷写到磁盘上时,根据不同的条件触发了checkpoint机制,此时由相关线程将记录状态为
commit的记录真正的刷写到对应的磁盘数据页,也就完成了真正的一条事务。在这个过程中对于记录状态为prepare的事务,直接丢掉即可,因为事务没提交嘛。- 在数据没有被刷写到磁盘数据页之前的过程,我们称之为构建脏页,这些数据也称之为脏数据。
- checkpoint就是将脏页按照一定的规则刷写到磁盘数据页。
根据上图,当事务执行到第4步时,就无惧宕机或者其他的意外情况了, 因为我们将对数据页的更改已经保存到了磁盘上,当MySQL执行CSR时,直接将redo file中记录的更改操作重新执行一次就完了,所以这也是redo log被称为重做日志的原因,执行重做的过程称之为基于redo的"前滚操作"。
既然有前滚操作,就有回滚操作,这是undo log负责的部分,后续会展开讲解。
我们现在了解一下redo log过程中哪些不为人知的细节。
在这之前大致了解下MySQL中的三种日志类型:
redo log:是存储引擎层生成的日志,主要为了保证数据的可靠性和持久性。bin log:是数据库层面生成的日志,主要用于日志恢复和主从复制。undo log:主要用于日志回滚和MVCC中。
基于redo——前滚
什么是redo log
redo log(重做日志)是事务日志的一种。
其主要的做用是在事务中实现持久化,当然也保证了事务的原子性和一致性。之前说redo log是存储引擎的层面生成的日志,是因为redo log 记录的是对磁盘上的某个表空间的某个数据页的偏移量为xxx处的xx数据做了修改,修改后的值为多少,它记录的是对物理磁盘上数据的修改,它本质上是16进制的修改,因此称之为物理日志。每当执行一个事务就会产生这样的一条物理日志。
redo log文件是持久化在磁盘上的,由多个具体的日志文件共同组成逻辑上的redo log。MySQL默认有2个redo log文件(分别叫做ib_logfile0、ib_logfile1),每个文件的大小是48MB,这两个文件默认存储在MySQL的数据文件目录内:
[root@cs ~]# ll /data/mysql/ib_log*
-rw-r----- 1 mysql mysql 50331648 11月 2 10:11 /data/mysql/ib_logfile0
-rw-r----- 1 mysql mysql 50331648 9月 15 16:25 /data/mysql/ib_logfile1
该文件的相关参数:
mysql> show variables like "innodb_log%";
+-----------------------------+----------+
| Variable_name | Value |
+-----------------------------+----------+
| innodb_log_buffer_size | 16777216 |
| innodb_log_checksums | ON |
| innodb_log_compressed_pages | ON |
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
| innodb_log_group_home_dir | ./ |
| innodb_log_write_ahead_size | 8192 |
+-----------------------------+----------+
7 rows in set (0.02 sec)
其中:
innodb_log_files_in_group,定义日志组中的日志文件数。默认值和推荐值为2。innodb_log_file_size,定义日志组中每个日志文件的大小(以字节为单位)。日志文件的总大小innodb_log_file_size*innodb_log_files_in_group不能超过512GB的最大值。innodb_log_group_home_dir定义InnoDB日志文件的目录路径。默认的InnoDB在MySQL数据目录中创建日志文件。
redo log的工作方式
innodb每执行一条事务产生的redo log会以循环的方式写入到磁盘,如下图所示:
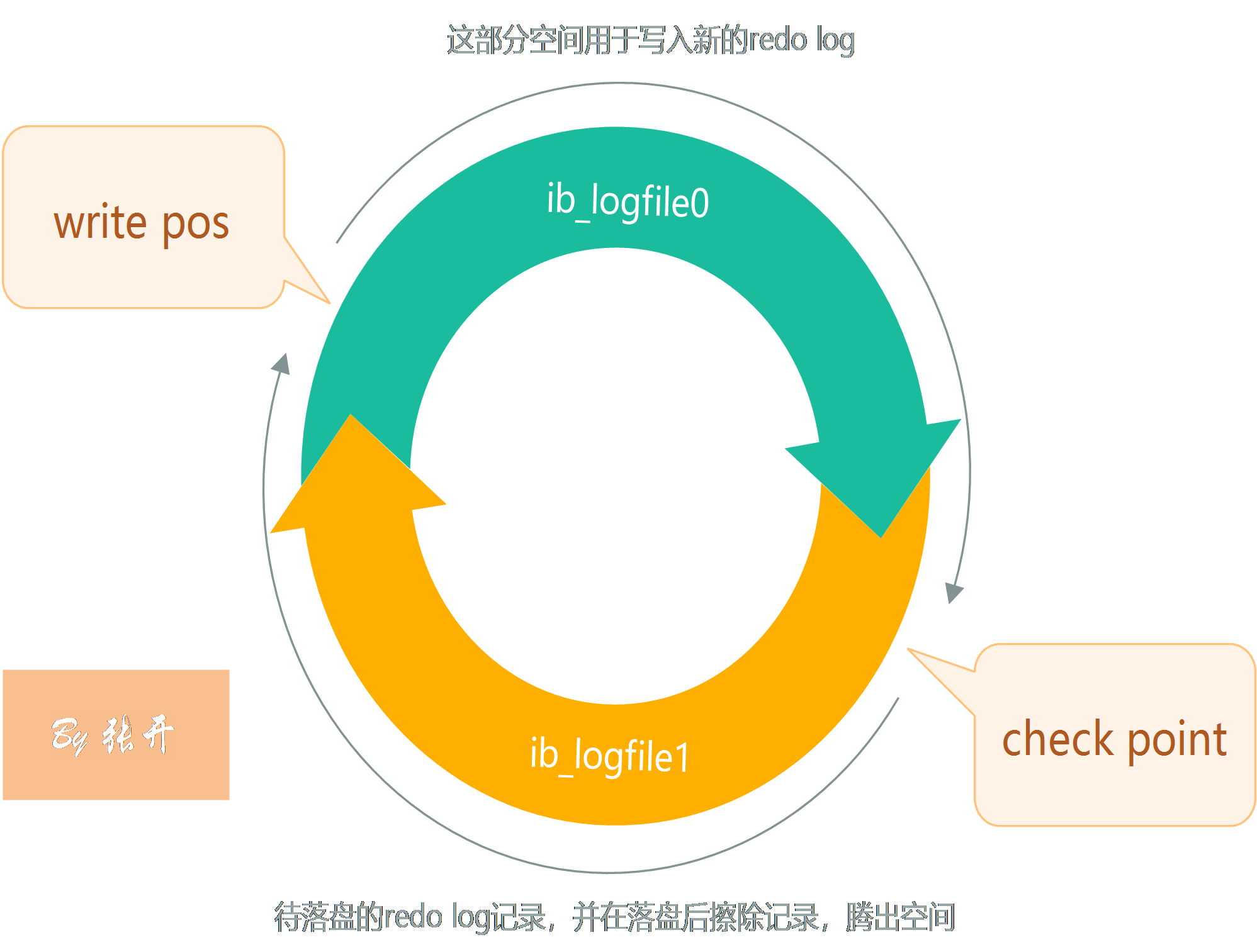
其中,write pos(position)表示redo log当前记录的位置,当ib_logfile0写满后,会从ib_logfile1文件头部继续覆盖写(前提是被覆盖的日志操作都已经刷写到磁盘的数据页上了);check point表示将日志记录的修改真正的刷写的对应的磁盘数据页中,完成数据落盘;数据落盘后check orint会将这部分日志记录擦除,所以write pos和check point之间部分是redo log的空着的部分,用于记录新的日志;而check point和write pos是redo log待落盘的数据修改记录。
当write pos追上check point时(表示没有空间写记录了),要停止新的记录,先推动check point往前走(数据落盘后,位置就空出来了),空出位置共新记录的写入。
redo log buffer
如果在内存中执行一个事务,那么产生的日志直接刷写到磁盘的redo log文件中也不太合适,这样也会产生大量的I/O操作,而且磁盘的运行速度远慢于内存,所以,redo log也有自己的缓存——redo log buffer,简称log buffer或者innodb log buffer。
MySQL在启动时,就会向系统申请一块空间作为redo log的buffer cache,默认大小是16MB,由redo_log_buffer_size控制:
mysql> select @@innodb_log_buffer_size 字节,(select @@innodb_log_buffer_size)/1024/1024 MB;
+----------+-------------+
| 字节 | MB |
+----------+-------------+
| 16777216 | 16.00000000 |
+----------+-------------+
1 row in set (0.00 sec)
redo log buffer内存的存储方式是以block为单位进行存储的,每个block块的大小是512字节,同磁盘的扇区大小一致,这样设计可以保证后续的写入都是原子性的。
另外,也正是以块的方式写入redo log file,且每个block大小为512字节(磁盘I/O的最小单位),所以不会出现数据损坏的问题,这也是为啥redo log中不采用double write机制的原因。
block的构成如下:
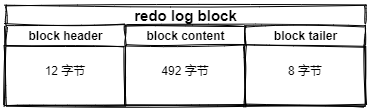
redo log持久化过程
每当产生一条redo log时,先被写入到redo log buffer,然后在某个"合适的时候"将整块的block刷写到redo log文件。那这个"合适的时候"是啥时候呢?
-
MySQL正常关闭时。
-
MySQL的后台master thread每隔一段时间(1s)将redo log buffer的block刷写到redo log file。
-
当redo log buffer中记录的写入量大于redo log buffer内存的一半时。
-
根据
innodb_flush_log_at_trx_commit参数设置的规则。
about master thread
master thread是InnoDB一个在后台运行的主线程,从名字就能看出这个线程相当的重要。它做的主要工作包括但不限于:刷新日志缓冲,合并插入缓冲,刷新脏页等。master thread大致分为每秒运行一次的操作和每10秒运行一次的操作。master thread中刷新数据,属于checkpoint的一种。所以如果在master thread在刷新日志的间隙,DB出现故障那么将丢失掉这部分数据接下来,聊一聊innodb_flush_log_at_trx_commit这个参数是如何控制redo log刷写磁盘的。
innodb_flush_log_at_trx_commit
innodb_flush_log_at_trx_commit是双一标准之一!
那该参数是干嘛的呢?innodb_flush_log_at_trx_commit主要控制innodb将log buffer中的数据写入日志文件并flush磁盘的时间点,取值分别为0、1、2,默认值是1:
mysql> select @@innodb_flush_log_at_trx_commit;
+----------------------------------+
| @@innodb_flush_log_at_trx_commit |
+----------------------------------+
| 1 |
+----------------------------------+
1 row in set (0.01 sec)
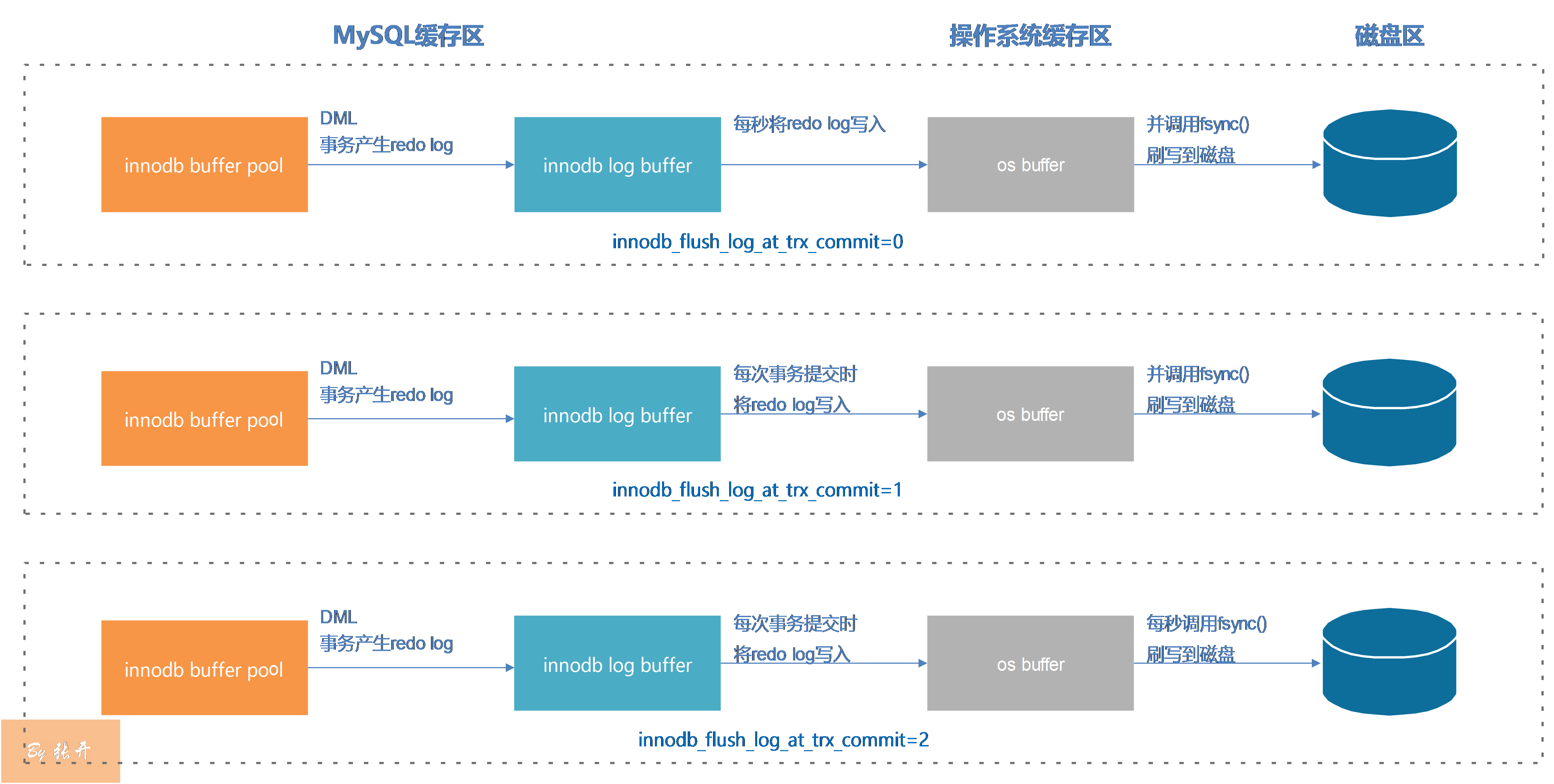
根据上图:
- 当
innodb_flush_log_at_trx_commit=0时,master thread每秒将redo log buffer中的日志往os buffer写入,os buffer再刷写(fsync)到磁盘的redo文件中。该模式速度最快,但安全性较差,因为MySQL宕机的话, 会丢失上一秒所有的事务。 - 当
innodb_flush_log_at_trx_commit=1时,每次事物的提交都会执行redo log buffer▶os buffer▶disk的过程。该模式最安全,但速度最慢,当MySQL宕机时最多可能丢失一个事务的redo log。 - 当
innodb_flush_log_at_trx_commit=2时,每次事务的提交都会从redo log buffer往os buffer写入,但os buffer会每秒完成一次fsync操作。该模式速度适中,只有在操作系统崩溃或者断电时,上一秒的redo log在os buffer中没来得及写入磁盘,导致丢失。
上面三种模式的日志刷写,都有os buffer的参与,那么有没有直接从redo log buffer写入到磁盘,从而绕过os buffer这样的策略或者设置,答案是有的,往下看。
Innodb_flush_method
innodb_flush_method参数控制log buffer和buffer pool在刷写磁盘时是否经过os buffer。
通过select查看当前系统中使用的模式:
mysql> select @@innodb_flush_method;
+-----------------------+
| @@innodb_flush_method |
+-----------------------+
| NULL |
+-----------------------+
1 row in set (0.00 sec)
If
innodb_flush_methodis set toNULLon a Unix-like system, thefsyncoption is used by default
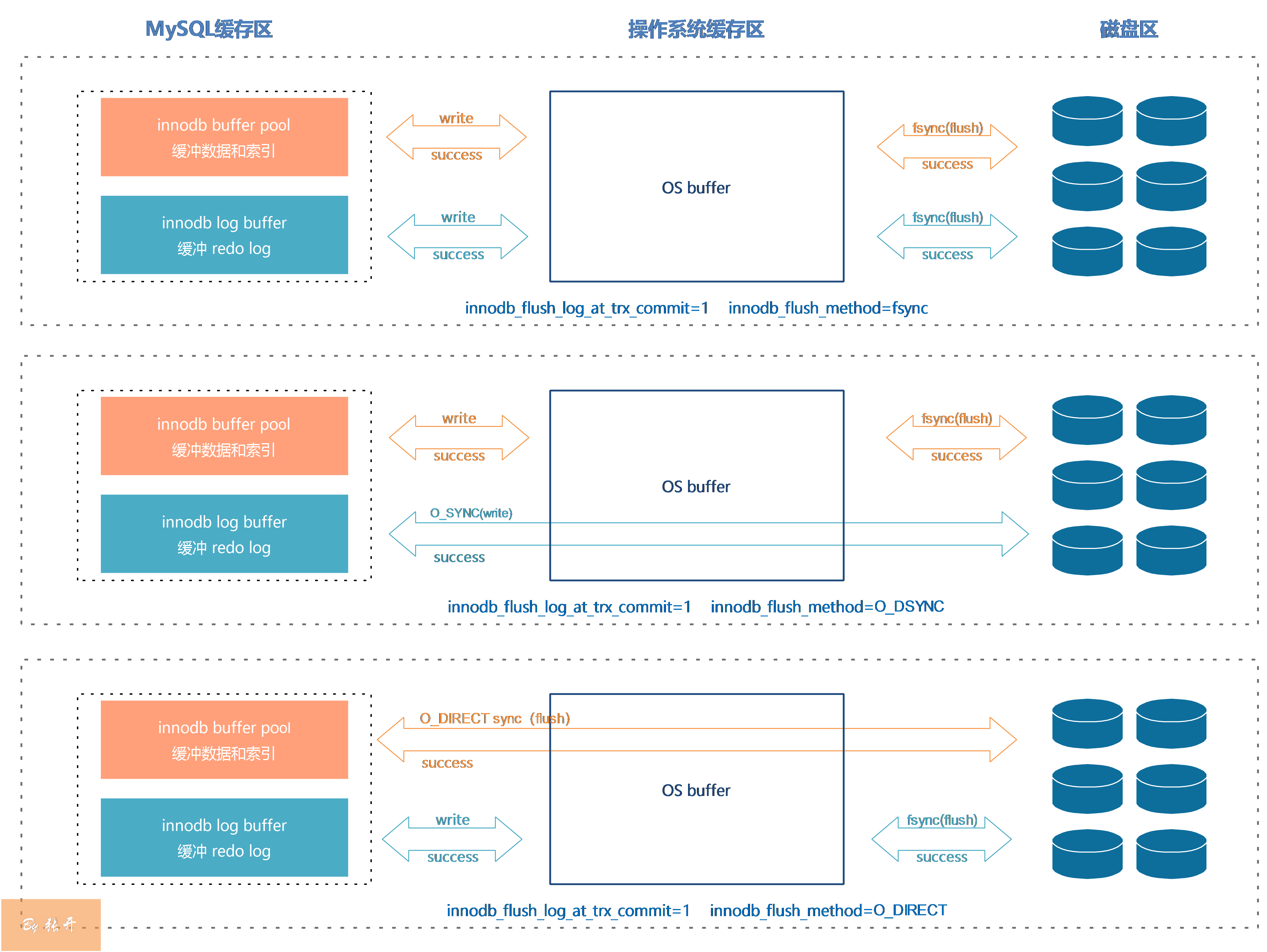
在Linux系统中,常用三种刷写模式:
fsync:调用fsync函数刷写数据文件和redo log,两者都走os buffer.O_DSYNC:数据文件走os buffer,redo log不走os buffer.O_DIRECT:数据文件直接刷写到磁盘,不走os buffer;redo log走os buffer.
最高安全模式
innodb_flush_log_at_trx_commit=1
innodb_flush_method=O_DIRECT
最高性能
innodb_flush_log_at_trx_commit=0
innodb_flush_method=fsync
checkpoint
检查点(checkpoint)指得是脏页何时刷写到磁盘数据页的节点。在innodb中,无论是buffer pool中的数据页刷盘还是redo log刷盘都是通过checkpoint来完成的,只不过触发checkpoint执行的规则有所不同罢了。
innodb的checkpoint分为两类:
- sharp checkpoint,完全检查点,它用来在MySQL正常关闭时,触发checkpoint将所有的脏页都刷写到磁盘对应的数据页,包括redo log中的。
- sharp checkpoint只发生在MySQL正常关闭时。
- 运行时的刷写磁盘不用sharp checkpoint,而是使用fuzzy checkpoint。
- fuzzy checkpoint,模糊检查点,一次只刷一部分redo log到磁盘,而非将所有的redo log刷写到磁盘。由以下几种情况触发fuzzy checkpoint:
- master thread checkpoint,由master thread线程控制,每秒或者每10秒刷入一定比例的脏页到磁盘。
- flush_lru_list_checkpoint,MySQL需要保证LRU链表中大约有100页的空闲页可用,如果没有这么多空闲页,就会将LRU的尾部淘汰一部分页,如果这些页中有脏数据需要落盘,就会触发checkpoint进行刷盘操作。PS:在MySQL5.6版本之后,可以通过
innodb_page_cleaners参数来指定负责刷盘的线程数。 - async/sync flush checkpoint,当redo log file快满了的时候,会触发checkpoint刷盘,这个过程又有两种情况:
- 当不可覆盖(数据没有落盘)的redo log站redo log file比值的75%时,采用异步刷盘。此时不会阻塞用户查询。
- 当不可覆盖(数据没有落盘)的redo log站redo log file比值的90%时,采用同步刷盘。此时会阻塞用户查询。
- 当上述两种情况有任何一种情况发生时,都会写入到errlog中,一旦errorlog有这种提示时,意味着你要考虑是否要加大redo log file了,还是做其他的优化。
- 当然了,从MySQL5.6版本开始,这部分刷新的操作同样有单独的page clear thread来完成,所以,不会阻塞用户查询了。
- dirty page too much checkpoint,buffer pool中脏页太多,强制触发checkpoint刷盘,目的是保证buffer pool中有足够的空闲页。
LSN
PS:你应该拿着"事务的工作流程"部分的图来对比学习这部分内容。
LSN(Log Sequence Number)日志序列号,在innodb中,LSN是单调递增的整型数,占用8个字节,LSN值随着日志不断写入而增大,LSN号出现在每一个数据页、redo log中、checkpoint中,在事务执行的不同阶段LSN号也不同,我们可以通过下面命令查看:
mysql> show engine innodb status\G
---
LOG
---
Log sequence number 124983029
Log flushed up to 124983029
Pages flushed up to 124983029
Last checkpoint at 124983020
其中:
Log sequence number是当前的redo log buffer中的LSN号Log flushed up to是刷写到redo log file中的LSN号Pages flushed up to是刷写到磁盘数据页上的LSN号Last checkpoint at是上一次检查点所在位置的LSN号
以上四个LSN号是递减的,Log sequence number≥Log flushed up to≥Pages flushed up to≥Last checkpoint at,而我们在工作中重点关注的是Last checkpoint at和Log flushed up to这两个LSN号。
在MySQL的CSR过程中,必须保证redo log和磁盘数据页中的LSN号是一致的,否则无法正常启动,所以innodb会扫描redo log file到buffer pool,然后检查对比Last checkpoint at和Log flushed up to这两个LSN号,Last checkpoint at到Log flushed up to这两个LSN号之间的数据就是需要做数据恢复的,即MySQL将这部分redo日志在buffer pool中重做一边,直到Last checkpoint at追平Log flushed up to,数据恢复完毕,MySQL正常启动。
基于undo——回滚
当有多个事务在buffer pool中,其中有的立马commit了,有的最终没有commit,对于这些未提交的事务该如何处理?rollback怎么实现的?在CSR时,怎么处理这些prepare的事务?这个时候就需要引入undo log了。
关于undo log
与redo log记录物理日志不一样的是,undo log主要记录的是数据页的逻辑变化,简单理解为当delete一条记录时,undo log中会记录一个对应的insert记录,反之亦然;当update时,undo log会记录一个相反update记录.....故,我们称undo log是逻辑日志。
undo log也有自己的log buffer,另外,undo log也会被记录在redo log中,保证undo log的持久化。
undo log的主要作用是:
- 应用MVCC中
- 事务的回滚
undo log的存储
默认的,innodb对于undo采用段(segment)的方式,rollback segment称为回滚段。
相关参数如下,需要说明的是,由于MySQL版本不同,参数也不尽相同,这里以MySQL5.7为例:
[root@cs ~]# ll /data/mysql/ibdata*
-rw-r----- 1 mysql mysql 79691776 11月 2 10:11 /data/mysql/ibdata1
mysql> show variables like "%rollback_segment%";
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_rollback_segments | 128 |
+--------------------------+-------+
1 row in set (0.00 sec)
mysql> show variables like "%undo%";
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| innodb_max_undo_log_size | 1073741824 |
| innodb_undo_directory | ./ |
| innodb_undo_log_truncate | OFF |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 0 |
+--------------------------+------------+
5 rows in set (0.00 sec)
其中:
- 在MySQL5.7以后,
innodb_rollback_segments已更名为innodb_undo_logs,都是表示回滚段的个数。至于innodb_rollback_segments参数仍然保留是为了版本兼容 innodb_max_undo_log_size默认的undo log文件大小是1024MBinnodb_undo_tablespaces默认为0时,表示undo log都在一个文件中,存放在共享表空间中,并且该参数是静态参数,即如果要修改该参数,需要停止MySQL实例innodb_undo_directory表示undo log的默认存位置,它默认存储在共享表空间中,也就是ibdata1中。./`表示MySQL的数据目录。innodb_undo_log_truncate表示是否开启在线收缩undo log文件大小,默认是关闭的,如果设置为1表示开启,当undo log超过innodb_max_undo_log_size定义的大小时,undo log会被标记为可truncate,意味着可在线收缩undo log的大小。注意,设置开启只对开启了undo log分离的有效,不会对共享表空间的undo log有效。因为在线收缩undo log时,会截断undo log的写入,这意味着要有另一个或者多个undo log文件在工作,即需要设置参数innodb_undo_tablespaces>=2和innodb_undo_logs>=35,详见官方文档
undo log和redo log的事务的完整流程
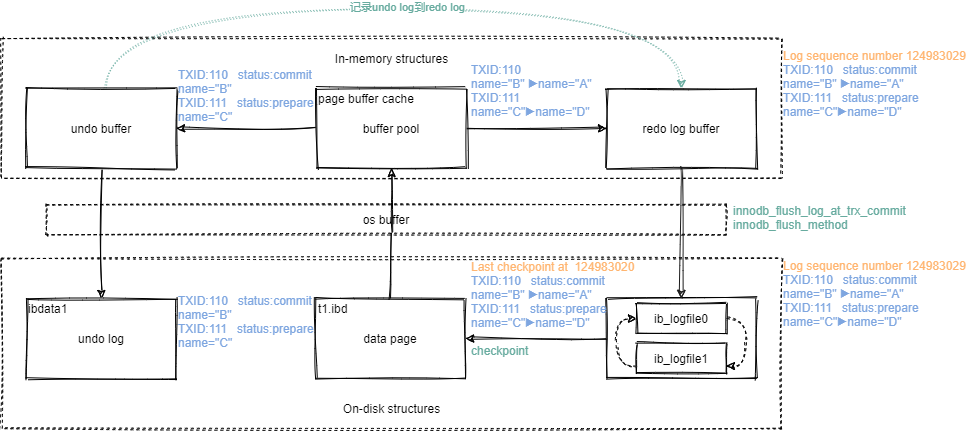
现在有两个事务要执行:
-- TXID:110
update t1 set name="A" where name"B";
-- TXID:111
update t1 set name="D" where name"C";
其记录redo log和undo log过程:
begin开始- 记录
name="B"到undo log - 修改
name="A" - 记录
name="A" where name"B"到redo log - 记录
name="C"到undo log - 修改
name="D" - 记录
name="D" where name"C"到redo log - 将redo log刷写到redo log file
- TXID110,commit了,故该条redo log的状态是commit
- TXID111,没有commit,所以该条redo log的状态是prepare
现在,当你进行rollback时,就可以根据事务ID去undo log中做回滚操作。CSR时也可以根据undo log做回滚操作。
undo log的类型
在innodb中,undo log分为:
- insert undo log,指在insert操作中产生的undo log,因为insert操作的记录,只对事务本身可见(当然要设置对应的隔离级别),对其他事务不可见,故该undo log可以在事务提交后直接删除,不需要进行purge线程进行清除操作。
- update undo log,记录的是对delete和update操作产生的undo log,因为该undo log可能需要提供MVCC机制或者rollback操作,所以不能在事务提交后直接删除,而是提交时放入undo log链表中,未来通过purge线程来删除。
- 而update操作又可以分为两种:
- 如果更新的列不是主键列,在undo log中直接记录一个相反update记录,然后直接update。
- 如是主键列,首先执行的操作是删除该行(原记录);完事再插入一条更新后的记录。
- delete操作实际上也不会直接删除,而是将delete的记录打个tag,标记为删除,然后这个事务对应的undo log被放到了删除列表中。
- 而update操作又可以分为两种:
PS:purge线程主要作用就是清理undo页和清除page中带有删除标记的数据行。
隔离级别
事务的隔离性其实比想象的要复杂。
在SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改,哪些在事务内和事务间是可见的,哪些是不可见的。
通常,较低级别的隔离可以执行更高的并发,系统的开销也更低。
下面简单介绍以一下四种隔离级别。
未提交读(RU,read uncommitted)
在RU级别,事务中的修改,即使没有提交,对其他事务也都是可见的,事务可以读取未提交的数据,这被称为脏读(dirty read)。这个级别会导致很多问题,从性能上来说,RU不会比其他级别好太多,但却缺乏其他级别的很多好处,除非真的有非常必要的理由,在实际应用中一般很少使用。
提交读(RC,read committed)
大多数数据库系统的默认隔离级别都是RC(但MySQL不是!),RC满足前面提到的隔离性的简单定义:一个事务开始时,只能"看见"已经提交的事务所做的修改。换句话说,一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的。这个级别有时候也叫做不可重复读(nonrepeatable read),因为两次执行同样的查询,可能会得到不一样的结果。
可重复读(RR,repeatable read)
RR级别解决了脏读问题并和MVCC一起解决"幻读"问题,该级别保证了在同一个事物中多次读取同样记录的结果是一致的。
该级别是MySQL的默认事务隔离级别。
可串行化(Serializable)
serializable是最高的隔离级别,它通过强制事务串行执行,避免了前面说的"幻读"问题。简单来说,serializable会在读取每一行数据上都加锁,所以可能导致大量的超时和锁争用问题。实际应用也很少用到这个隔离级别。只有在非常需要确保数据的一致性而且可以接受没有并发的情况下,才考虑采用该级别。
| 隔离级别 | 脏读可能性 | 不可重复读可能性 | 幻读可能性 | 加锁读 |
|---|---|---|---|---|
| RU | Yes | Yes | Yes | No |
| RC | No | Yes | Yes | No |
| RR | No | No | Yes | No |
| Serializable | No | No | No | Yes |
在MySQL中,可以通过tx_islation参数来查看:
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set, 1 warning (0.00 sec)
这四种级别通过transction_isolation参数来修改:
-- 支持 session 和 global 级别设置
set transaction_isolation='READ-UNCOMMITTED';
set transaction_isolation='READ-COMMITTED';
set transaction_isolation='REPEATABLE-READ';
set transaction_isolation='SERIALIZABLE';
-- 也支持配置文件设置 vim /etc/my.cnf
[mysqld]
transaction_isolation=READ-COMMITTED
上述四种隔离级别最常用的就是RU和RC,所以,我们接下来就单独来研究一下这两种隔离级别。
RR
RR保证了在同一个事物中多次读取同样记录的结果是一致的。我们来个示例演示一下。
首先保证自动提交关闭和隔离级别设置为RR。

然后,我们在左侧终端执行一个事务,右侧终端也同样执行一个事务,两个事务操作同一行记录,观察:
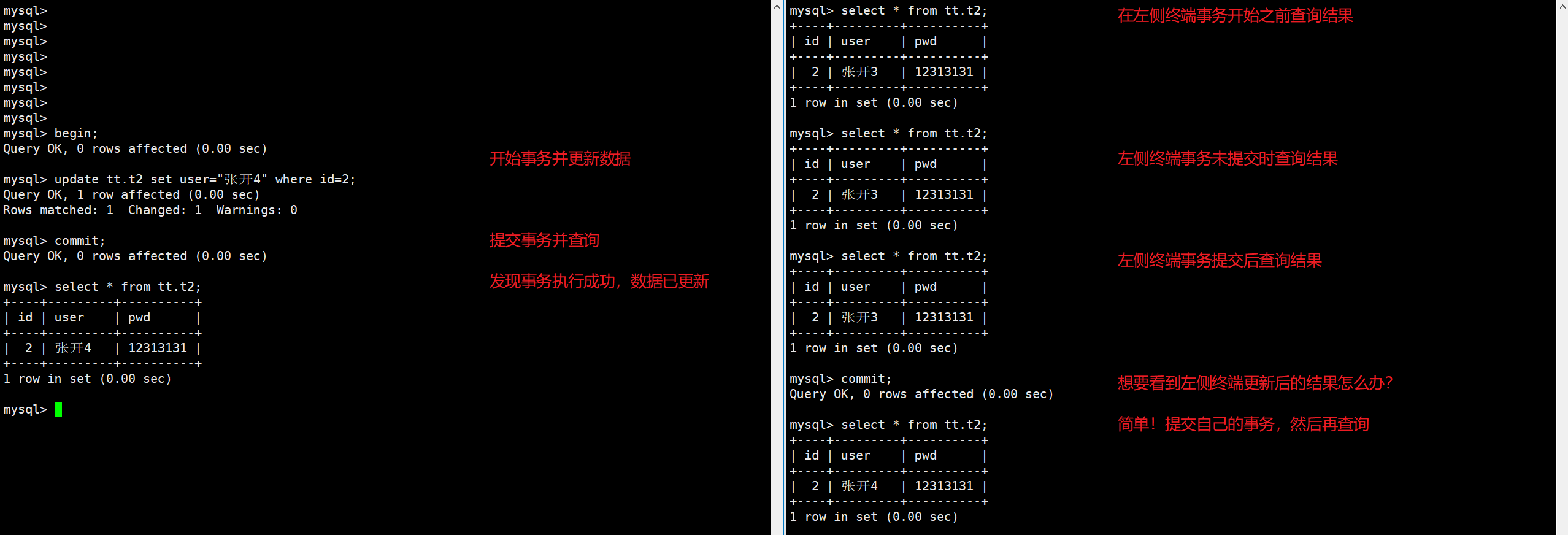
通过上述示例的结果对比,发现现象符合定义:RR保证了在同一个事物中多次读取同样记录的结果是一致的,这样避免了同一行数据出现"幻读"现象。
RC
首先保证自动提交关闭和隔离级别设置为RC。

然后,我们在左侧终端执行一个事务,右侧终端也同样执行一个事务,两个事务操作同一行记录,观察:
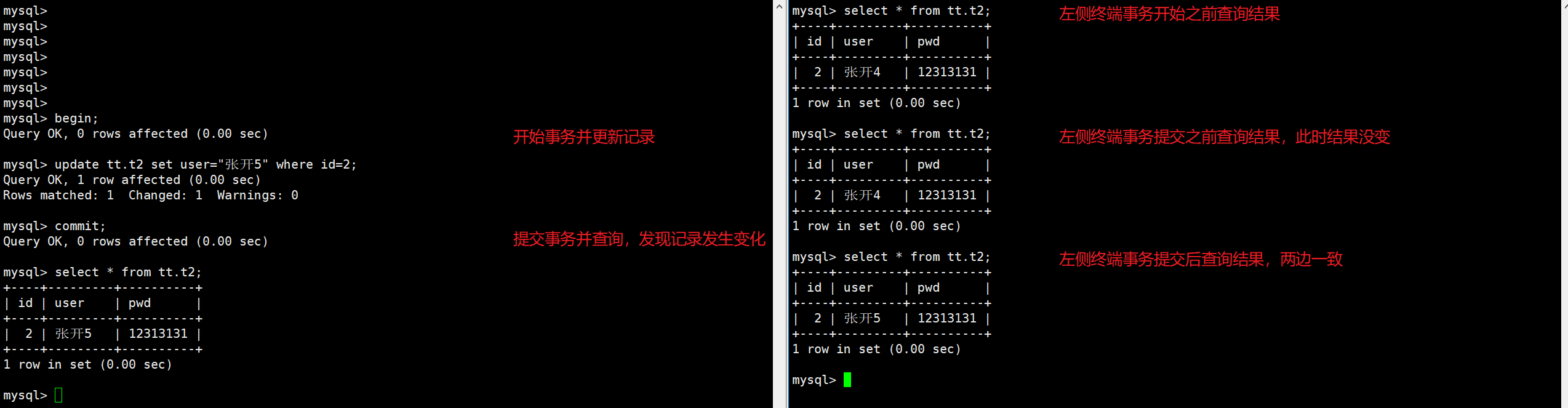
由右侧终端的结果可以证明之前的定义没错,右侧终端能立即读到左侧终端事务已提交的结果,但这因此产生了"幻读"现象,因为右侧查询结果随着左侧终端的更改而无法确定拿到的值到底是什么!
那在RC级别如何保证读一致性的问题?通常在查询时添加for update语句来保证读一致性,也就是我读该行数据的时候,加个锁,那别人也就无法修改这行数据,直到我读完后,别人才能修改这行数据。
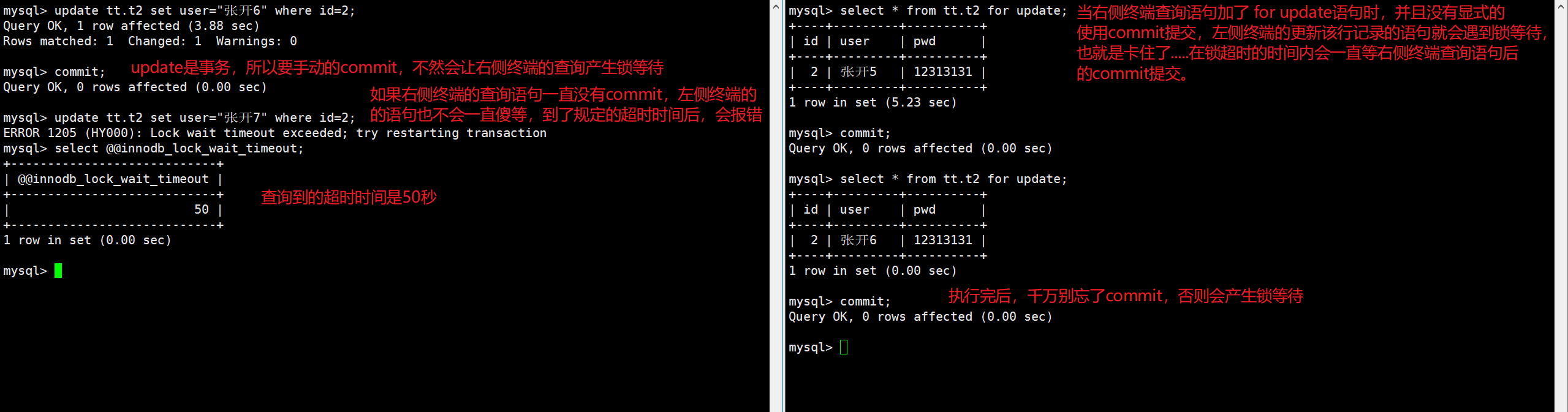
上述的超时时间通过innodb_lock_wait_timeout参数可以查询到:
mysql> select @@innodb_lock_wait_timeout;
+----------------------------+
| @@innodb_lock_wait_timeout |
+----------------------------+
| 50 |
+----------------------------+
1 row in set (0.00 sec)
最后,在使用完for update后,一定要commit,否则容易产生大量的锁等待。
锁
上面的RC级别的演示中,我们也引出了锁的概念。
在InnoDB的事务中,"锁"和"隔离级别"一起保证了事务的一致性和隔离性,当然也有其他技术参数,比如redo也有参与。
在MySQL中,有很多种锁,包括悲观锁、乐观锁、排它锁、GAP、Next-Lock等等。
RC中用的悲观锁,何为悲观?就是总有刁民想害朕的那种感觉。RC中,读数据的时候,总觉得别人可能也来操作这行数据,那不行,没安全感,怎么办?加把锁,我搞完你再来.........
另外,这里还需要补充一把死锁。
死锁是指两个或者多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环的现象。当多个事务试图以不同的顺序锁定资源时,就可能产生死锁;多个事务同时锁定同一资源时,也会产生死锁。死锁发生后,只有部分或者完全回滚其中一个事务,才能打破死锁。
为了解决死锁问题,InnoDB引擎实现了各种死锁检测和死锁超时机制,当检测到由死锁的循环依赖产生时,会立即返回一个错误;另一种处理方式就是当查询的时间达到锁等待的超时时间的设定后放弃锁请求,但这种方式不太好。InnoDB目前处理死锁的方法时,将持有最少行级排它锁的事务进行回滚。
InnoDB和MyISAM的区别
- innodb支持行级锁,而myisam仅支持表级锁
- innodb支持事务,而myisam不支持事务
- innodb支持热备份
that's all,see also:
MySQL InnoDB 共享表空间和独立表空间 | MySQL修改innodb_data_file_path参数的一些注意事项 | mysql innodb_data_file_path、innodb_data_home_dir、innodb_buffer_pool_size、innodb_buffer_pool_instances 四个参数 | 老男孩-标杆班级-MySQL-lesson05-存储引擎 | redo log —— MySQL宕机时数据不丢失的原理 | mysql日志系统之redo log和bin log | MySQL InnoDB 的redo log与 checkpoint | MySQL checkpoint深入分析 | 关于InnoDB存储引擎中的LSN(Log Sequence Number) | Mysql之LSN和checkpoint和double write | MySQL-LSN | mysql 5.7 undo truncate 功能 | InnoDB事务日志(redo log 和 undo log)详解 | 详细分析MySQL事务日志(redo log和undo log) | 浅析MySQL事务中的redo与undo | MySQL 5.7 学习:新增配置参数 | Mysql Buffer Pool | innodb引擎的4大特性 | mysql 特性之一 double write (双写) | MySQL采用buffer机制 double write buffer | MySQL 特性:Double Write | MySQL之Double Write Buffer分析 | mysql之 double write 浅析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号