1-Python - 文件操作
before
本小节介绍一个特殊的函数——open函数,因为到目前为止,我们写的程序都非常的简陋,应用范围狭窄,而通过open函数,我们就可以将程序得以扩展到文件和流的领域。
打开文件
通过open函数打开文件,其语法如下:
open(
file,
[mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True]
)
open函数打开文件或文件描述符并返回文件对象,如果无法打开则抛出OSError错误。
file参数为字符串或者是字节对象的路径或者相对路径(当前工作目录)。
buffering参数控制着文件的缓冲,如果参数是0或者False,那么就是说无缓冲,所有的读写操作都是直接针对硬盘的操作。如果参数是1或者True,那么意为Python会使用内存代替硬盘,从而让程序变得更快,只有使用flush或者close时,缓冲区的文件才会更新到硬盘。
encoding参数指以什么方式操作文件,该参数只适用于文本模式。
errors参数指定如何处理编码和解码错误。仅适用于文本模式。
newline参数为换行符控制换行符模式的工作方式,仅适用于文本模式,如果该参数为None,那么它的工作方式是,从文件流中读取输入时,启用通用换行符模式,将所有的换行符(\r\n 或者\n)转换为\n,再返回给调用者。
closefd参数为True时,则为传入file参数为文件的文件名。为False时传入的file参数只能是文件描述符。什么是文件描述符?在UNIX平台的系统中,文件描述符就是一个非负数,比如说,打开一个文件,就会得到一个文件描述符。
mode为可选参数,用于指定打开文件的模式,默认为r,以读的方式打开文件,常用的mode模式如下所示:
| mode | 描述 |
|---|---|
| r | 打开文件,以读的方式,默认的方式 |
| w | 以写的方式打开文件,如果原文件存在则会被覆盖,如果没有此文件就会创建,前提是该模式下必须保证文件目录的存在 |
| a | 以追加的方式打开文件,如果文件存在则从原文件的末尾写入,否则会创建文件 |
| rb | 打开文件,以二进制的形式读文件 |
| ab | 以二进制追加模式打开文件 |
| wb | 以二进制写模式打开,打开前原文件会被清空 |
一般地,如果Python处理的是文本文件,使用r、w模式没有任何问题。但有时会处理一些其他类型文件(二进制文件),如音、视频文件,那么就应该在模式参数中增加b模式,如rb模式读取二进制文件。那么为什么使用rb模式?
如果使用rb模式,通常跟r模式不会有太大区别,仍然是读取一定的字节,并且能执行文本文件的相关操作。Python使用二进制模式关键点是给出原样的文件。而文本模式下则不一定。
因为在于Python对于文本文件的操作方式有些不同,其中就有标准化换行符。一般的,Python的标准换行符是\n,表示结束一行并另起一行,这也是UNIX系统的规范。而Windows系统中则是\r\n,但无需担心,Python会自动在各平台间(包括Mac平台)帮我们转换。但这并不足以解决问题,因为二进制文件中(音、视频)很可能包含这些换行符。如果Python以文本模式处理这些文件,那么很可能就破坏了文件。为了避免此类问题,就要以二进制的方式操作这些文件,这样在操作中就不会发生转换从而避免文件损坏。
如果在读的时候以通用的模式读取文件,则所有的文件都统一转换为\n,从而不用考虑平台问题。
open函数常用的参数为file、encoding、mode三个参数。
常用方法
既然打开了文件,就要对文件做些什么了!接下来介绍文件对象的一些方法。
对文件的操作最重要的就是读和写了,那么拿到一个文件对象f时,通过f.read和f.write两个方法完成读写操作。
w模式和write
f1 = open('t1.txt', mode='w')
f1.write('hello')
f1.write('world')
f1.close()
上例,open函数以写的方式打开t1.txt文件并将文件句柄f1返回,w模式的特点是如果文件不存在就创建文件,文件存在就覆盖写,并且这个文件句柄只能写入普通的文本字符串(写入bytes类型的文件会报错)。通过文件句柄调用写方法将两个字符串写入文件中,然后关闭文件句柄。此时如果你打开t1.txt文件的话,会发现这两个字符串紧挨着在一行上。这是因为两个字符串之间没有换行符\n。
来,我们加上换行符:
f1 = open('t1.txt', mode='w')
f1.write('hello\n')
f1.write('world\n')
f1.close()
现在,这两个字符串各占一行了。
r模式和read系列
那么如何读文件呢?
f2 = open('t1.txt', mode='r')
content = f2.read()
print(content)
f2.close()
"""
hello
world
"""
上例,首先以读模式拿到文件句柄f2,然后使用read方法一次性读取t1.txt内的所有内容。注意,r模式读取普通的文本字符串(读取bytes类型的文本文件会报错)。最后关闭文件句柄。
这里思考一个问题,read是一次性的读取所有文件内容,但如果文件特别大的话,比如有两个G的日志文件,将这么大的文件一次性的读取到内存中,是不合理的,所以,可以在read的时候指定每次读的字节数大小:
f3 = open('t1.txt', mode='r')
content = f3.read(5)
print(content)
content = f3.read(5)
print(content)
f3.close()
"""
hello
worl
"""
上例,当第一次读的时候,读了5个字节的内容hello,第二次读的时候,从第一次读的位置后面继续往后读5个字节,首先读到了一个换行符\n,然后在读第二行的四个字节worl。
除了在read,还有其他的读方法:
f4 = open('t1.txt', mode='r')
content = f4.readline()
print(content)
f4.close()
f5 = open('t1.txt', mode='r')
content = f5.readlines()
print(content)
f5.close()
"""
hello
['hello\n', 'world\n']
"""
上例,readline每次读一行(两次打印结果之间的空行是第一行的\n),readlines读取所有行,并以列表的形式返回。
a模式
有些情况不能覆盖写,而是要追加写,比如日志文件,这就用到了a模式——追加写:
f6 = open('t1.txt', 'a')
for i in "hello":
f6.write('{}{}'.format(i, '\n'))
f6.close()
追加写模式中,如果文件存在,则以追加的方式继续写入,如果文件不存在就创建文件,然后以追加的方式写入。
wb/ab/rb
之前处理的都是文本字符串,要处理音视频、图片等二进制类型的文件时,就需要搭配使用b模式了,b模式标识处理的是二进制文件:
f7 = open('t1.png', 'rb')
content = f7.read()
f8 = open('t2.png', 'wb')
f8.write(content)
f7.close()
f8.close()
上例,要处理的是图片类型的文件,所以要使用b模式来读写。如果要传输的是视频之类的,就要考虑使用ab模式了。
seek/tell
除了上面read系列的顺序读取文件,Python还提供了随机读取文件方法:
f9 = open('t1.txt', 'r')
print(f9.tell())
f9.seek(2)
print(f9.tell())
content = f9.read()
print(content)
print(f9.tell())
f9.close()
"""
0
2
llo
world
12
"""
上例,seek(offset, [whence])方法意为把当前读(或写)的位置移动到由offset和whence定义的位置,offset表示偏移的字节量,而whence为可选参数,搭配offset使用,表示从哪个位置开始偏移,0表示从文件开头开始,1代表从当前位置开始开始,2表示从文件末尾开始偏移。 而tell方法则返回当前指针所在的位置。
关闭文件
我们为什么在对文件对象f操作完毕之后,都要去关闭它?
f14 = open('t1.txt', 'w')
f14.write('hello\n')
# f14.close()
f15 = open('t1.txt', 'r')
content = f15.read()
print(content)
上例,如果f14文件句柄不关闭,f15文件句柄则无法读取文件内容。这只是其中一种情况。
有时候,Python解释器因为某些原因如提高程序运行速度,会将文件缓存在内存中某个地方。但碰到意外如程序突然崩溃,就会造成这些缓存数据没有及时写入硬盘。也为了降低系统对打开文件的资源占用,如在Linux系统中,对打开文件数会有限制,超过限制则无法打开文件。为了避免这些可能出现的问题,在对文件处理完毕之后及时关闭文件。
而关闭文件则有两种方式,一起来看看吧!
手动关闭文件
手动关闭就是使用f.close来完成。这无需多说了:
f14 = open('t1.txt', 'w')
f14.write('hello\n')
f14.close()
f15 = open('t1.txt', 'r')
content = f15.read()
print(content)
f6.close()
自动关闭文件
但每次都手动关闭文件,比较麻烦,Python又提供了with语句来解决这个麻烦。
with语句:
with open(...) as f:
f.read()
open函数的参数不变,关键字as后面的文件对象f可以自定义。
with语句允许使用上下文管理器,上下文管理器则是支持__enter__与__exit__方法的对象。__enter__方法没有参数,当程序执行到with语句的时候被触发,返回值绑定在文件对象f上。而__exit__方法则有三个参数,包括异常类型、异常对象、异常回溯。现在无需深入了解这个三个参数,只需知道当with语句执行完毕,也就是对文件的操作执行完毕,with会自动执行__exit__方法来关闭文件。
来个示例:
with open('t1.txt', 'w') as f:
f.write('with 语句真省事')
with open('t1.txt', 'r') as f:
f.read() # with 语句真省事
with语句无疑帮我们做了很大的工作,让我们专心于文件操作本身。
当然了,with语句的功能不仅限于此,它还有其他的用法,详情参考:点我
"f"是什么?
我们对一个文件操作,总是要拿到这个文件句柄来做操作,那么这个文件句柄是什么呢?
from collections import Iterable
f = open('t1.txt', 'r')
print(isinstance(f, Iterable)) # True
由上例可以看到,文件句柄f它也是一个可迭代对象,那么我们就可以通过循环来取值。
f = open('t1.txt', 'r')
for i in f:
print(i)
"""
hello
world
"""
每次循环读取一行数据。
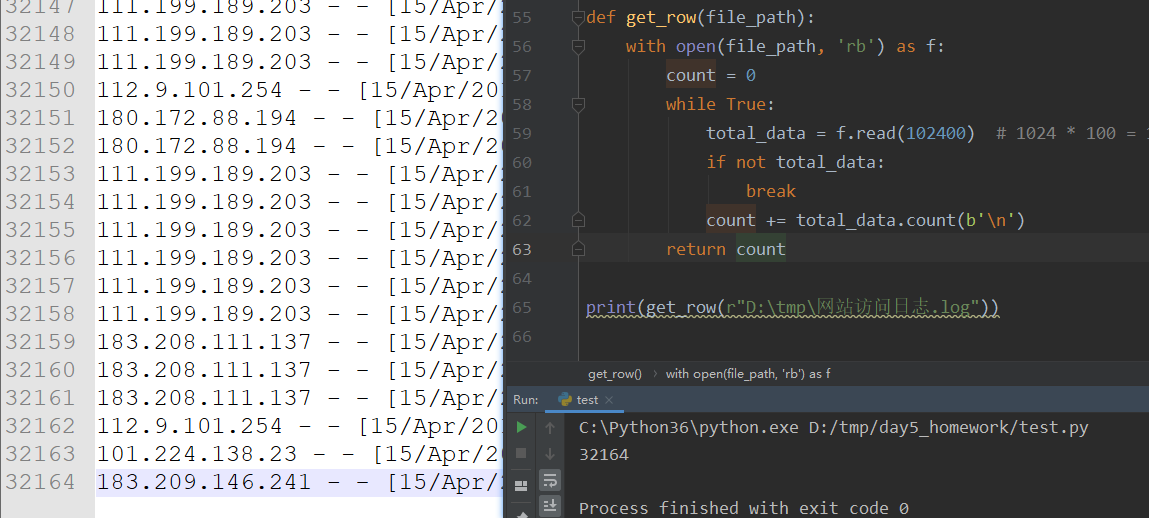
案例:获取文件的行数
需求:获取某文件的总行数:
def get_row(file_path):
with open(file_path, 'rb') as f:
count = 0
while True:
total_data = f.read(102400) # 1024 * 100 = 102400
if not total_data:
break
count += total_data.count(b'\n')
return count
print(get_row(r"D:\tmp\网站访问日志.log"))
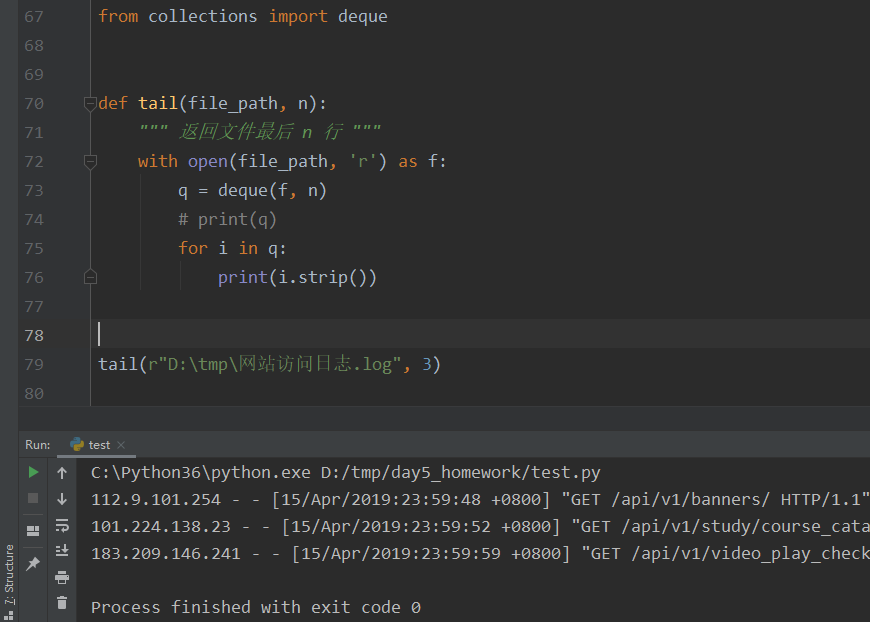
案例:获取文件的后几行
需求:获取指定文件,最后n行:
from collections import deque
def tail(file_path, n):
""" 返回文件最后 n 行 """
with open(file_path, 'r') as f:
q = deque(f, n)
# print(q)
for i in q:
print(i.strip())
tail(r"D:\tmp\网站访问日志.log", 3)
操作excel文件
操作ini文件
操作xml文件
我翻了翻w3c关于xml的教程,你想要大致弄懂xml这门标记语言,需要顺着这个思路看下去:
- xml教程:https://www.w3school.com.cn/xml/index.asp
- DTD教程:https://www.w3school.com.cn/dtd/index.asp
- Schema 教程:https://www.w3school.com.cn/schema/index.asp
而接下来要说的重点则是使用Python操作xml。
读文件
读取xml文件有两种方式:文件和网络。
具体操作如下示例:
import requests # pip install requests
from xml.etree import ElementTree as ET
xml_file = './schema.xml'
# 文件内容长这样:
"""
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria"/>
<neighbor direction="W" name="Switzerland"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica"/>
<neighbor direction="E" name="Colombia"/>
</country>
</data>
"""
# 如果xml来自于文件,则使用下面方式获取根节点
# tree = ET.parse(xml_file)
# print(tree) # <xml.etree.ElementTree.ElementTree object at 0x000002530A3E8D30>
# print(tree.getroot()) # <Element 'data' at 0x000002118D372C70>
# 如果xml来自于网络,如下面示例
# url = "http://ws.webxml.com.cn//WebServices/WeatherWebService.asmx/getWeatherbyCityName?theCityName=北京"
# response = requests.get(url=url)
# # print(response.text)
# root = ET.XML(response.text)
# print(root) # <Element '{http://WebXml.com.cn/}ArrayOfString' at 0x0000016A90A5A3B0>
# 上面的链接如果失效了的话,其返回结果就长这样
"""
<?xml version="1.0" encoding="utf-8"?>
<ArrayOfString xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns="http://WebXml.com.cn/">
<string>直辖市</string>
<string>北京</string>
<string>54511</string>
<string>54511.jpg</string>
<string>2021/8/30 11:27:47</string>
<string>20℃/29℃</string>
<string>8月30日 多云</string>
<string>北风小于3级</string>
<string>1.gif</string>
<string>1.gif</string>
<string>今日天气实况:气温:26℃;风向/风力:南风 1级;湿度:65%;紫外线强度:弱。</string>
<string>感冒指数:易发,大幅度降温,适当增加衣服。
运动指数:较适宜,请适当降低运动强度,并及时补充水分。
过敏指数:易发,应减少外出,外出需采取防护措施。
穿衣指数:热,适合穿T恤、短薄外套等夏季服装。
洗车指数:适宜,天气较好,适合擦洗汽车。
紫外线指数:弱,辐射较弱,涂擦SPF12-15、PA+护肤品。
</string>
<string>20℃/29℃</string>
<string>8月31日 多云</string>
<string>东南风转南风小于3级</string>
<string>1.gif</string>
<string>1.gif</string>
<string>19℃/29℃</string>
<string>9月1日 阴转多云</string>
<string>南风转西南风小于3级</string>
<string>2.gif</string>
<string>1.gif</string>
<string>北京位于华北平原西北边缘,市中心位于北纬39度,东经116度,四周被河北省围着,东南和天津市相接。
全市面积一万六千多平方公里,辖12区6县,人口1100余万。北京为暖温带半湿润大陆性季风气候,
夏季炎热多雨,冬季寒冷干燥,春、秋短促,年平均气温10-12摄氏度。北京是世界历史文化名城和古都之一。
早在七十万年前,北京周口店地区就出现了原始人群部落“北京人”。而北京建城也已有两千多年的历史,最初见于记载的名字为“蓟”。
公元前1045年北京成为蓟、燕等诸侯国的都城;公元前221年秦始皇统一中国以来,北京一直是中国北方重镇和地方中心;自公元938年以来,北京又先后成为辽陪都、金上都、元大都、明清国都。
1949年10月1日正式定为中华人民共和国首都。北京具有丰富的旅游资源,对外开放的旅游景点达200多处,有世界上最大的皇宫紫禁城、祭天神庙天坛、皇家花园北海、皇家园林颐和园,还有八达岭、慕田峪、
司马台长城以及世界上最大的四合院恭王府等各胜古迹。全市共有文物古迹7309项,其中国家文物保护单位42个,市级文物保护单位222个。北京的市树为国槐和侧柏,市花为月季和菊花。
另外,北京出产的象牙雕刻、玉器雕刻、景泰蓝、地毯等传统手工艺品驰誉世界。
</string>
</ArrayOfString>
"""
上例我们顺利的拿到了xml的根节点,有了根节点,我们就能访问任意的节点、节点属性、节点内容了。
from xml.etree import ElementTree as ET
xml_content = """
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria"/>
<neighbor direction="W" name="Switzerland"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica"/>
<neighbor direction="E" name="Colombia"/>
</country>
</data>
"""
root = ET.XML(xml_content)
print(root) # 获取根节点data <Element 'data' at 0x000001C356BEF770>
country_node = root.find('country')
country_nodes = root.findall('country')
print(country_nodes) # 获取跟节点下所有的country子节点,范围就是直属子节点 [<Element 'country' at 0x000001A19CB53C70>, <Element 'country' at 0x000001A19CB53E50>]
print(country_node) # 获取第一个country节点对象 <Element 'country' at 0x00000174AFE62C70>
print(country_node.tag) # 获取节点名称 country
print(country_node.attrib) # 获取节点的所有属性 {'name': 'Liechtenstein'}
year_node = country_node.find('year') # 获取country节点下的year子节点
print(year_node.tag, year_node.attrib) # 获取节点名称和节点属性,如果没有属性的话,就返回空字典 year {}
print(year_node.text) # 获取节点内容 2023
for node in root: # 循环获取根节点下所有的子节点,也就是两个country节点
print(node.tag, node.attrib)
for node in country_node: # 循环获取country节点下所有的子节点
print(node.tag, node.attrib)
# 寻找根节点中,去所有子孙节点中找year的节点,返回一个迭代器对象
year_nodes = root.iter('year')
print(year_nodes) # <_elementtree._element_iterator object at 0x0000023128DE2360>
for item in year_nodes:
print(item.tag, item.text)
其它示例:
import requests
from xml.etree import ElementTree as ET
content = '''<?xml version="1.0" encoding="UTF-8"?>
<soapenv:Envelope xmlns:soapenv="http://www.xx">
<soapenv:Body>
<tem:ConsumeXmlMsgResponse xmlns:tem="http://xxx.org/">
<!--Optional:-->
<tem:ConsumeXmlMsgResult>
<Root>
<Rows>
<Row>
<UUID>186011</UUID>
<DATE_START>2022/6/8 8:53:00</DATE_START>
<KH>186011</KH>
<BGRQ>2022/6/8 15:10:06</BGRQ>
<CJRQ></CJRQ>
<BGDLB>超声科</BGDLB>
<BGDH></BGDH>
<JYRQ></JYRQ>
<JCZBMC></JCZBMC>
<JCZBDM></JCZBDM>
<JCFF></JCFF>
<JCZBJG></JCZBJG>
<JLDW></JLDW>
<CKZ></CKZ>
<BBDM></BBDM>
<BBMC></BBMC>
</Row>
<Row><UUID>186011</UUID><DATE_START>2022/6/8 8:51:00</DATE_START><KH>186011</KH><BGRQ></BGRQ><CJRQ></CJRQ><BGDLB>输血科</BGDLB><BGDH></BGDH><JYRQ></JYRQ><JCZBMC></JCZBMC><JCZBDM></JCZBDM><JCFF></JCFF><JCZBJG></JCZBJG><JLDW></JLDW><CKZ></CKZ><BBDM>1</BBDM><BBMC>血</BBMC></Row>
<Row><UUID>186011</UUID><DATE_START>2022/6/8 8:52:00</DATE_START><KH>186011</KH><BGRQ></BGRQ><CJRQ></CJRQ><BGDLB>输血科</BGDLB><BGDH></BGDH><JYRQ></JYRQ><JCZBMC></JCZBMC><JCZBDM></JCZBDM><JCFF></JCFF><JCZBJG></JCZBJG><JLDW></JLDW><CKZ></CKZ><BBDM>1</BBDM><BBMC>血</BBMC></Row>
</Rows>
</Root>
</tem:ConsumeXmlMsgResult>
</tem:ConsumeXmlMsgResponse>
</soapenv:Body>
</soapenv:Envelope>'''
root = ET.XML(content)
for i in root.iter("Row"): # 找到所有的Row标签,然后找里面,你需要的各个标签的值
print(i.find('UUID').text, i.find('DATE_START').text, i.find('KH').text,)
"""
186011 2022/6/8 8:53:00 186011
186011 2022/6/8 8:51:00 186011
186011 2022/6/8 8:52:00 186011
"""
修改和删除节点
修改节点
从文件中读文件,修改完写回到文件中:
from xml.etree import ElementTree as ET
xml_file = './schema_1.xml'
root = ET.parse(xml_file)
first_year_node = root.find("country").find("year")
print(first_year_node.tag, first_year_node.text, first_year_node.attrib) # year 2023 {}
first_year_node.text = "2500" # 为节点重新赋值
first_year_node.set('m1', 'v1') # 属性存在则更新,否则添加,只能一个一个的搞
first_year_node.set('m2', 'v2')
print(first_year_node.tag, first_year_node.text, first_year_node.attrib) # year 2500 {'m1': 'v1', 'm2': 'v2'}
# 以上的操作目前都在内存中修改的,如果要保存到文件,还需要手动保存
# 我这里重新生成一个新文件了,你也可以写回源文件
# 注意,写回去的文件内容,会自动的加上xml的版本,也就是这一行 <?xml version='1.0' encoding='utf8'?>
# 请忽略,读取文件的时候也会自动忽略这一行的
# root.write(xml_file, encoding='utf8')
root.write('./schema_1.xml', encoding='utf8')
从网络请求的内容,修改完写到文件:
import requests
from xml.etree import ElementTree as ET
xml_file = './schema_2.xml'
url = "http://ws.webxml.com.cn//WebServices/WeatherWebService.asmx/getWeatherbyCityName?theCityName=北京"
response = requests.get(url=url)
# print(response.text)
# 这个返回结果中,根节点中的所有数据都被封装到了string节点中,也就是说有很多个叫string的同名标签
# 所以结果这些string节点是以数组(列表)形式返回的,我们可以根据索引取值和修改其属性和内容
ArrayOfString = ET.XML(response.text)
print(ArrayOfString[0].tag, ArrayOfString[0].text) # {http://WebXml.com.cn/}string 直辖市
# 你也可以通过for循环获取每个节点的相关信息
# for node in ArrayOfString:
# print(node.text)
ArrayOfString[0].text = '我是首都'
# 当你修改后,要保存到文件,需要这样:
ET.ElementTree(ArrayOfString).write(xml_file, encoding='utf8')
删除节点
from xml.etree import ElementTree as ET
xml_file = './schema_1.xml'
root = ET.parse(xml_file)
first_year_node = root.find('country').find('year')
# 删除这里要注意,要通过被删除节点的父节点来删除其子节点,也就是如下这种形式
# 想删除第一个country中的year节点,那就必须找到year节点,然后通过country节点来删除
# 也就是不能通过root节点跨节点删除其孙节点
# 另外,要删除的节点不存在也报错
# root.find('country').remove(first_year_node)
# root.remove(first_year_node) # 报错
# 完事别忘了保存文件
root.write(xml_file, encoding='utf8')
构建xml文档
上面演示的操作,都是基于一个已存在的文档进行的操作。
现在我们来从无到有构建一个xml文档。
我们分别说几种不同的构建方式。
注意我是如何为节点添加属性和内容的!
法1,使用ET.Element来构建:
from xml.etree import ElementTree as ET
xml_file = './schema_3.xml' # 最开始这个文件不存在,我们要将构建的xml文档保存到这个文件中去
# 需求,构建一个如下结构的xml文件
"""
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2023</year>
<gdppc></gdppc>
</country>
</data>
"""
# 首先要构建其根节点
data_node = ET.Element("data")
# 构建其country节点
# 如果有属性的话,直接以字典的形式传参即可
country_node = ET.Element('country', {"name": "Liechtenstein"})
# 构建rank、year、gdppc节点
rank_node = ET.Element('rank', {"updated": "yes"})
rank_node.text = "2" # 值都要以字符串的形式赋值
year_node = ET.Element("year")
year_node.text = "2023"
gdppc_node = ET.Element("gdppc")
# 现在各个节点之间都没啥关系,接下来要做的就是按照需求将它们进行关系绑定
# 将rank、year、gdppc节点添加到country节点中
country_node.append(rank_node)
country_node.append(year_node)
country_node.append(gdppc_node)
# 将country节点绑定到根节点data中
data_node.append(country_node)
# 现在各个节点整理好了,可以写到文件了
ET.ElementTree(data_node).write(xml_file, encoding='utf8')
法2,使用ET.SubElement方法构建:
from xml.etree import ElementTree as ET
xml_file = './schema_4.xml' # 最开始这个文件不存在,我们要将构建的xml文档保存到这个文件中去
# 需求,构建一个如下结构的xml文件
"""
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2023</year>
<gdppc></gdppc>
</country>
</data>
"""
# 首先要构建其根节点
data_node = ET.Element("data")
# 构建其country节点
# 如果有属性的话,直接以字典的形式传参即可
country_node = ET.SubElement(data_node, 'country', {"name": "Liechtenstein"})
# 构建rank、year、gdppc节点
rank_node = ET.SubElement(country_node, 'rank', {"updated": "yes"}) # makeelement返回节点对象
# 可以通过该节点对象为其赋值
rank_node.text = "2"
# year节点没有属性,要传个空字典,否则报错
year_node = ET.SubElement(country_node, "year", {})
year_node.text = "2023"
# gdppc没有属性没有值,直接构建节点对象就完了
ET.SubElement(country_node, "gdppc", {})
# 现在各个节点整理好了,可以写到文件了
ET.ElementTree(data_node).write(xml_file, encoding='utf8')
另外,在保存文件的时候,还有个参数要注意:
ET.ElementTree(data_node).write(xml_file, encoding='utf8', short_empty_elements=False)
# 当short_empty_elements=False的时候,对于没有值的节点,将会构建成这样
# <gdppc></gdppc>
# 当short_empty_elements=True的时候,对于没有值的节点,将会构建成这样
<gdppc/>
最后,你可能也从别的地方学到构建文档用makeelement来构建节点,但源码不推荐这么做:
class Element:
def makeelement(self, tag, attrib):
"""Create a new element with the same type.
*tag* is a string containing the element name.
*attrib* is a dictionary containing the element attributes.
# 重点就是下面这一行,说不要调用这个方法,请使用SubElement这个工厂函数
Do not call this method, use the SubElement factory function instead.
"""
return self.__class__(tag, attrib)
CDATA
XML文档中的所有文本均会被解析器解析。
即如果在你的xml某个节点中,其内容包含诸如<、&这样的字符,但在xml中这些字符都是非法的,那么怎么处理呢?答案是这些包含非法字符的文本使用CDATA包含起来。
CDATA中的字符不会被解析,CDATA用法如下:
CDATA 部分中的所有内容都会被解析器忽略。
CDATA 部分由 "<![CDATA[" 开始,由 "]]>" 结束:
<solt><![CDATA[文本]]></solt>
而CDATA中的文本我们也无需特殊处理,xml内部解析器会自动帮我们处理的,如下示例:
from xml.etree import ElementTree as ET
xml_context = """
<message>
<user>xx</user>
<pwd>oo</pwd>
<solt><![CDATA[xof23^&@<(34>]]></solt>
</message>
"""
root = ET.XML(xml_context)
for node in root:
print(node.text)
"""
xx
oo
xof23^&@<(34>
"""
来个写入的示例:
import sys
import time
import string
# 如果报错没有lxml模块,就在终端中执行 pip install lxml 进行下载安装,关于lxml库,参考:https://blog.csdn.net/m0_63794226/article/details/126360128
from lxml import etree
file_path = './tx.xml'
def create_xml():
data = etree.Element("data")
title_txt = '%s' % '真心话大冒险'
title_txt = etree.CDATA(title_txt)
title = etree.SubElement(data, 'title')
title.text = title_txt
dataxml = etree.tostring(
data, pretty_print=True, encoding="UTF-8",
method="xml", xml_declaration=True, standalone=None
)
with open(file_path, 'wb') as f:
f.write(dataxml)
if __name__ == '__main__':
create_xml()

参考:https://blog.51cto.com/u_15815563/5740622
压缩与解压
可以使用Python内置的shutil模块实现对文件/文件夹的压缩与解压操作。
压缩
import shutil
shutil.make_archive(base_name='root', format='zip', root_dir=r'D:\tmp\web\root')
# base_name:压缩文件名
# format:压缩格式,支持"zip", "tar", "gztar", "bztar", or "xztar"
# root_dir:要压缩的的目录或者具体的文件路径
# 生成的压缩文件会保存在跟你Python脚本同级目录
解压
import shutil
shutil.unpack_archive(filename=r'D:\tmp\web\root.zip', extract_dir=r'D:\tmp\web\new_root', format='zip')
# filename:要解压的压缩包文件
# extract_dir:解压的路径
# format:压缩文件格式
压缩指定目录内的指定文件:
import os
from zipfile import ZipFile
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
dir_path = os.path.join(BASE_DIR, '联通')
with ZipFile('to.zip', 'w') as myzip:
for item in os.listdir(dir_path):
abs_path = os.path.join(dir_path, item)
print(abs_path)
if abs_path.endswith('.py'):
myzip.write(abs_path)
文件夹拷贝
将某ooo目录及内部的子文件,完整的拷贝一份,并命名为xxx,注意这么写,不能拷贝内部的子目录,也就是只能拷贝一层。
import os
import shutil
source_path = r"D:\tmp\test\ooo"
target_path = r"D:\tmp\test\xxx"
if not os.path.exists(target_path):
# 如果目标路径不存在原文件夹的话就创建
os.makedirs(target_path)
if os.path.exists(source_path):
# root 所指的是当前正在遍历的这个文件夹的本身的地址
# dirs 是一个 list,内容是该文件夹中所有的目录的名字(不包括子目录)
# files 同样是 list, 内容是该文件夹中所有的文件(不包括子目录)
for root, dirs, files in os.walk(source_path):
for file in files:
src_file = os.path.join(root, file)
shutil.copy(src_file, target_path)
print('copy dir finished!')
欢迎斧正,that's all

 浙公网安备 33010602011771号
浙公网安备 33010602011771号