1-Python - 装饰器
before
前面说了嵌套函数的闭包函数形式,你可能会问,闭包函数是用来做什么呢?这节就来讲解闭包函数的应用——装饰器。我们通过老男孩的故事来说说装饰器。
另外:
装饰器是Python中,非常难理解的一个点,因为了解它的前提要对函数的基础和闭包有深刻的理解。
装饰器的做用非常的大,用处也随处可见,尤其是一些源码中,常常是点睛之笔.......
但个人建议,初学Python的白白们,知道有这个东西就行,等把Python学个七七八八,再回来学装饰器就好理解了。
一个真实的故事
转眼,老男孩的开发(软件开发工程师,以下简称开发)陆陆续续为老男孩官网写了10万+个函数,随着老男孩的飞速发展,老男孩官网也越来越臃肿,也越来越慢。一天老男孩就对开发说:"现在官网这么慢,你着手优化一下,比如测试一下每个函数的运行时间,看哪些函数拖了后腿,一天后告诉我结果……"
开发一听测试函数的运行的时间,这好办,修改函数,测试一下到底运行了多少时间不就完了么。
import time # 导入time模块,执行计算时间的功能
def func():
start = time.time() # 获取函数函数开始运行的时间戳
print('function running......')
time.sleep(3) # 由于这个函数运行太快,我们手动让函数“睡”3秒
print('function run time:', time.time() - start) # 结束时间减去开始运行的时间,得出函数运行的时间
func() # function run time: 3.0002944469451904
关于time模块
time模块会在模块部分详细的说,这里暂时介绍用到的time模块和函数的__name__属性。
import time
def func():
pass
time.time() # 返回当前时间的时间戳
time.sleep(secs) # 通过secs参数指定函数“睡”多久
func.__name__ # 获取函数名
然而10万+个函数,这要每个函数都改一遍,那还如直接交辞职报告呢!就在开发苦思冥想的准备写个体面点的辞职报告的时候,忽然灵机一动,如果写个函数,专门用来测试其它函数的执行时间,那就能按时完成任务了啊。
import time
def timer(func):
''' prints function time '''
start = time.time()
func() # 调用函数的执行
print('function %s run time %s' % (func.__name__, time.time() - start)) # 打印函数执行的时间
def f1():
time.sleep(1) # 通过睡眠,模拟函数执行的时间
def f2():
time.sleep(2)
timer(f1) # function f1 run time 1.0005981922149658
timer(f2) # function f2 run time 2.00011944770813
然而,虽然有了改进,但十万+的工作量依然很大,就思考还能不能进一步优化。比如依然只是调用f1函数,但能自动触发timer函数的执行,这岂不美哉。而且列出了伪代码:
def timer():
pass
def f1():
pass
f1 = timer
f1()
开发想想应该能实现:
import time
def timer(func):
''' prints function time '''
def wrapper():
start = time.time()
func() # 这里是执行函数,参考的前面例子中的pirnt(x)来理解
print('function %s run time %s' % (func.__name__, time.time() - start))
return wrapper
def f1():
time.sleep(1) # 通过睡眠,模拟函数执行的时间
def f2():
time.sleep(2)
print('赋值前的f1', f1) # 赋值前的f1 <function f1 at 0x005D6738>
f1 = timer(f1)
print('重新赋值的f1', f1) # 重新赋值的f1 <function timer.<locals>.wrapper at 0x00E43270>
f2 = timer(f2)
f1() # function f1 run time 1.0000762939453125
f2() # function f2 run time 2.000044345855713
上面的例子,参考前面闭包函数的例子去理解。在第14、16行执行timer函数并传递func参数,而这个func参数,其实就是传递的f1、f2两个函数名。在wrapper函数内对func变量进行引用来自嵌套作用域传来的func变量。而第8行timer将wrapper函数名和带有对func变量引用的嵌套作用域一起返回。并且timer将返回值分别赋值给f1、f2变量。此时被重新赋值的f1、f2变量其实为wrapper函数(第15行的打印可以证明)。这时第17~18行f1、f2加括号就能运行。还记得嵌套函数有“记忆”功能吗?因为在第14行已经将f1函数传给timer函数并且被timer“记住”,在第17行执行wrapper函数的时候,就跳转执行到第6行,“看到”func(实为f1函数名)变量就去局部作用域查找,没有,就去上一级嵌套作用域内查找,找到了func(之前传过的f1函数名)。加括号f1函数就被执行。执行完毕,第7行打印了f1函数的执行时长。第18行f2的执行过程和f1函数一致。
这就很完美了,但美中不足的是,还有两次赋值操作(第14、16行),这看着多碍眼啊,要是能去掉该多好。于是开发又去找老大Alex去寻找解决办法。Alex一看,就冷冷的说:“这不就是装饰器么,Python已经用语法糖帮我们解决这个问题呀……”。
import time
def timer(func):
''' prints function time '''
def wrapper():
start = time.time()
func()
print('function %s run time %s' % (func.__name__, time.time() - start))
return wrapper
@timer
def f1():
time.sleep(1) # 通过“睡”一会儿,模拟函数执行的时间
@timer
def f2():
time.sleep(2)
f1() # function f1 run time 1.0000762939453125
f2() # function f2 run time 2.000044345855713
上例,我们只是在每个函数上面加上"@timer"之外,并没有修改f1和f2函数的代码。
通过这个真实的故事,我们完整的写出一个装饰器函数。那么接下来我们就来学习一下装饰器的具体用法。
注意:语法糖(Syntactic sugar),也称糖衣语法,在Python(其他语言也有类似语法)中为程序添加某种语法,这种语法对语言的原本功能没有影响,只是更方便开发者使用,语法糖使得程序更加简洁,提高了可读性。
其他的衍生词汇则有语法盐、语法精糖、语法糖浆。
开放封闭原则
在说装饰器之前,我们还要学习一个原则——开放封闭原则。那什么是开放封闭原则呢?
对扩展是开放的
为什么要对扩展开放呢?可以想象一下,任何一个程序在设计之初,都不可能做到面面俱到、实现所有的功能,并且后续不作任何更改。所以,我们要支持代码扩展,添加新的功能。
对修改是封闭的
既然说要允许代码扩展,那为什么又要对修改封闭么?举个例子,比如要给银行的交易功能添加或测试新的功能,如果直接修改源代码,那么造成有些交易发生异常,甚至无法交易。所以,对修改(源码)是封闭的。
装饰器的出现完美的遵循了这个开放封闭原则。
通过上面的统计函数运行时间的例子可以看到,只需在测试的函数上加上统计时间功能的装饰器。而对于原函数没有做任何修改。
无参装饰器
装饰器的本质:装饰器本身是任意可调用对象,被装饰的对象也可以是任何可调用的对象。
装饰器的功能:在不修改被装饰对象源代码,以及调用方式的前提下,为其添加新的功能。
上面说的有点绕,现在只需记住:
-
不修改被装饰对象的源代码。
-
不修改被调用对象的调用方式,就是说,我们在被装饰对象"不知不觉"中添加了一些功能。
装饰器需要达到的目标:添加新功能。
再来看装饰器的一般写法。
def timer(func): # 装饰器
def wrapper():
res = func() # 执行被装饰函数代码
print(res) # 其他的逻辑代码
# returen res # 将结果返回
return wrapper # 返回功能函数名
@timer # 采用 @ + 装饰器名,写在被装饰函数上面,完成装饰
def index(): # 被装饰器函数
print('index function') # 逻辑代码
index() # 执行index函数,自动触发装饰器函数的执行
关键点就是@符号,其实第7代码的意思是拿到位于下方函数的函数名当成timer函数的参数,并执行timer函数,得到timer函数的返回值赋值给变量index,而变量index则为timer函数的返回值(timer函数将内部的wrapper函数的函数名返回),代码理解就是index = timer(index)。那么伪代码用代码去实现:
import time
def timer(func):
''' prints function time '''
def wrapper():
start = time.time()
func()
print('function %s run time %s' % (func.__name__, time.time() - start))
return wrapper
@timer # foo = timer(foo)
def foo():
time.sleep(1)
foo() # function foo run time 1.0007328987121582
一个最简单的计算时间的装饰器函数完成了。上面的代码流程是:
- 第1步:首先在第1行导入time模块。然后程序往下走。
- 第2步:在第2行定义timer函数。
- 第3步:接着执行到第9行,发现装饰器的语法糖。这一步你可以想象语法糖默默的帮我们做了定义foo函数,并且执行foo = timer(foo)这一步赋值操作。
- 第4步:然后触发timer函数执行,执行timer内部代码,程序执行第4行,定义wrapper函数。只是定义,所以程序往下走。
- 第5步:接着在第8行将wrapper函数名返回。
- 第6步:timer函数暂时执行完毕,期间做了包括将执行timer函数并为func形参传递实参foo函数名,在嵌套作用域内"记住"foo变量(foo函数名),经过这一些列操作。程序从新回到语法糖的第9行并继续往下走。
- 第7步:因为在第3步骤时,语法糖帮我们定义了foo函数,此时就直接执行到12行,执行foo加括号。关键点:此时的foo变量已经不是最初的foo函数那个函数名了,而是在第3步骤中拿到的foo变量,而这个foo变量实为timer函数的返回值——wrapper函数名。加括号执行的是wrapper函数。所以,此时程序执行第4行的wrapper函数,接着执行内部代码。
- 第8步:程序执行到第5行,通过time模块获取到当前的时间戳,程序往下走。
- 第9步:执行到了第6行,在局部作用域去找变量func,没找到,往上去嵌套作用域里找,这次找到了,在第3步骤中,语法糖给func传递了foo函数名,此时func加括号等价于foo函数加括号执行。
- 第10步:程序再次通过第9行的语法糖开始执行到第11行的foo函数的内部代码,“睡”1秒,至此,被装饰函数的内部代码执行完毕。程序往下走。
- 第11步:第6行的func加括号执行完毕,继续执行到了第7行的打印,通过__name__拿到了func的函数名为foo,再一次获取当前的时间戳并减去第5行时获得的时间戳,算出程序运行了多少时间,通过占位符格式化完毕,打印出结果。wrapper函数执行完毕,回到第12行。foo加括号执行完毕,继续往下走,没有代码,程序结束。
有参装饰器
老男孩的开发正在为测试运行时间时碰到问题而头疼。问题是这样的,老男孩官网的公共主页不需要登录,而后台页面必须指定用户登录才能访问:
import time
def timer(func):
def wrapper():
start = time.time()
func()
print('function %s run time %s' % (func.__name__, time.time() - start))
return wrapper
@timer
def public():
time.sleep(0.1)
print('oldboy public index page')
@timer
def admin(name):
print('oldboy public admin page') # 老男孩后台页面
if name == 'root': # 只有用户名是root的用户才能访问
return 'welcome vip page'
return 'name error' # 否则提示请用户名错误
public()
admin('oldboy')
但上面的代码,admin函数执行时会报错,因为虽然在第19行给admin参数传参了,但是实际运行的是在装饰器内的第5行执行的,而很明显第5行我们并没有传递参数,这时就会报缺少参数的错误。你看到是这里可能会说,那我们在需要传参的地方,传上参数不就完了吗?
import time
def timer(func):
def wrapper(name):
start = time.time()
func(name)
print('function %s run time %s' % (func.__name__, time.time() - start))
return wrapper
@timer
def public():
time.sleep(0.1)
print('oldboy public index page')
@timer
def admin(name):
print('oldboy public admin page') # 老男孩后台页面
if name == 'root': # 只有用户名是root的用户才能访问
return 'welcome vip page'
return 'name error' # 否则提示请用户名错误
public()
admin('oldboy')
问题虽然解决了。但是因为传递参数带来了另一个问题,那就是主页的public函数会报错,因为人家不需要参数,你却传参了,一样会报参数的错误。这可难为死了开发,只好再去问Alex,Alex看了代码就冷冷的说:"忘了*args和**kwargs了么?",并且随手写了示例代码:
def test1(*args, **kwargs):
print(666) # 666
print('不传参也不报错', *args, **kwargs) # 不传参也不报错
test1()
def test2(*args, **kwargs):
print(666) # 666
print('传参就接收', *args, **kwargs) # 传参就接收 oldboy {'age': 22}
test2('oldboy', {'age': 22})
开发忽然回想起了学过的*args和**kwargs。恍然大悟,并且立马更改了代码:
import time
def timer(func):
def wrapper(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
print('function %s run time %s' % (func.__name__, time.time() - start))
return wrapper
@timer
def public():
time.sleep(0.1)
print('oldboy public index page')
@timer
def admin(name):
time.sleep(0.1)
print('oldboy public admin page') # 老男孩后台页面
if name == 'root': # 只有用户名是root的用户才能访问
return 'welcome vip page'
return 'name error' # 否则提示请用户名错误
public()
admin('oldboy')
"""
# 上面两个函数执行结果
oldboy public index page # public函数执行的结果
function public run time 0.10057306289672852
oldboy public admin page # 成功进入了admin页面
function admin run time 0.10007095336914062
"""
虽然上面的代码顺利执行,但是细心的开发却发现,打印结果中,并没有看到admin函数的返回值。也就是说第16行到第18行,到底有没有执行,不知道!经过仔细查看代码,发现第16行代码到第18行的代码执行了,只是我们没有接收。那怎么接收呢?
import time
def timer(func):
def wrapper(*args, **kwargs):
start = time.time()
ret = func(*args, **kwargs)
print('function %s run time %s' % (func.__name__, time.time() - start))
return ret
return wrapper
@timer
def public():
time.sleep(0.1)
print('oldboy public index page')
@timer
def admin(name):
time.sleep(0.1)
print('oldboy public admin page') # 老男孩后台页面
if name == 'root': # 只有用户名是root的用户才能访问
return 'welcome vip page'
return 'name error' # 否则提示请用户名错误
public_ret = public()
admin_ret = admin('root')
print('public return:', public_ret) # public return: None
print('admin return:', admin_ret) # admin return: welcome vip page
上例代码的执行流程(以admin函数为例)为:
-
步骤1:程序执行第1行,导入time模块。
-
步骤2:在第2行定义timer函数。
-
步骤3:程序运行到第13行,碰见语法糖,语法糖做了admin = timer(admin)这个步骤,触发timer函数的执行,并接收admin变量(admin函数的内存地址),执行timer内的代码,定义wrapper函数,并在第8行时被timer返回函数名wrapper。此时的admin变量就是wrapper函数。
-
步骤4:程序再次通过第13行的语法糖往下继续执行到第21行,admin变量加括号执行,此时我们知道admin就是wrapper函数。程序回到第3行执行wrapper函数,接收并“记住”root变量。继续往下执行内部的代码,第4行获取时间戳。
-
步骤5:此时程序执行到了第5行,func加括号,我们知道这个func其实就是语法糖帮我们做那一步操作——admin = timer(admin),所以此时是admin函数执行,程序来到了第15行,“睡”0.5秒后往下执行了一行打印任务。在第17行去找name变量,因为name值在执行第4步时已经被“记住”了,此时我们从“记忆”中拿出来,name成了root,之后进行if判断,root==root。判断成功,执行if内部的代码,也就是第18行将字符串return出去。我们知道,函数碰到return就结束执行。故admin函数结束了。程序回到第5行,继续执行。
-
步骤6:通过前面的学习,我们知道将函数赋值给一个变量,而这个变量就能接收到该函数的返回值。所以,我们在第5行通过变量ret接收到了admin函数的返回值。程序往下执行,打印admin函数的执行时间。程序继续往下走。在第7行时,通过return语句,我们拿到admin函数的返回值ret。
-
步骤7:这是,你可能会问为什么在第7行时要返回admin函数的返回值ret?admin函数不是已经return了吗!为什么又要返回一次?其实,我们要明白,admin函数的生命周期(从开始执行到执行结束)都是在wrapper函数内完成的,我们最后拿到的只是wrapper的返回值。所以,我们要把admin函数的返回结果,通过wrapper函数返回出去。此时,装饰器也执行完毕。程序继续往下走。
-
步骤8:程序执行到了第21行,admin(实为wrapper函数)执行完毕(并在第7行返回了结果),被重新赋值给变量admin_ret。程序往下走。
-
步骤9:最终,在第23行打印出来了admin函数的返回值。程序执行完毕。那可能又有疑惑,最后执行的是admin_ret。这是改了源代码了啊!需要说明的是,这么用是为了更清晰的展示admin_ret变量是admin函数的返回值。
public函数的执行流程参考admin函数的执行流程。不同之处只是public函数没有返回值罢了,正如第22行打印的public函数的返回值是None。
至此,开发成功的解决装饰器传参的问题。但他并不知道,还有下一个坑在等着他......
多装饰器
果然,开发又碰到问题了,因为他在给一个函数要加计时装饰器的时候发现,那个函数本身就已经有了一个装饰器。他又给这个函数加了自己的装饰器。但不知道会发生什么,就又去求助老大Alex,Alex看了代码,就给他讲解起来。
import time
def timer(func):
def wrapper():
start = time.time()
func()
print('function %s run time %s' % (func.__name__, time.time() - start))
return wrapper
def auth(func):
def inner():
''' 登录验证 '''
count = 1
while count <= 3:
name = input('enter name:')
pwd = input('enter pwd:')
if name == 'oldboy' and pwd == '666':
print('login successful')
func()
return
elif count == 3:
print('登录次数过多,明天再来吧')
return
else:
print('login error,剩余登录次数%s' % (3 - count))
count += 1
return inner
@auth # foo = inner = auth(wrapper) = auth(time(foo))
@timer # foo = wrapper = timer(foo)
def foo():
time.sleep(1)
print('function foo')
foo() # function foo run time 1.000114917755127
# foo函数执行结果
# enter name:oldboy
# enter pwd:666
# login successful
# function foo
# function foo run time 1.0003564357757568
@timer # bar = wrapper = timer(auth(bar))
@auth # bar = inner = auth(bar)
def bar():
time.sleep(1)
print('function bar')
bar()
# bar函数执行结果
# enter name:oldboy
# enter pwd:666
# login successful
# function bar
# function inner run time 5.279560804367065
我们先看foo函数的执行流程:
-
步骤1:第1行,导入time模块,定义timer和auth两个函数。
-
步骤2:程序就来到了第26行,@auth做了什么?拿到下面函数(装饰器也是函数)名,执行auth函数并将函数名传进去。而下面的函数是timer装饰器,所以,timer装饰器又做了同样的事情,拿到下面foo函数的函数名执行timer函数并将foo传进去,再重新赋值给foo。此时的foo为wrapper函数。而第27行的timer函数整体就做了注释代码的内容(从右到左看)。
-
步骤3:第27行timer函数返回了内部的wrapper,被第26行的auth函数当参数传递自己的函数中。此时foo为inner函数。因为auth函数的返回值就是inner。而timer(foo)则返回的是wrapper。但wrapper被auth函数当成参数传进去了。
-
步骤4:此时,程序通过第26行的@auth往下执行第30行的foo加括号。而foo就是inner函数,也就是执行auth内部的inner函数。
-
步骤5:程序进行登录判断,此时输入oldoby(第37行所示)和666(第38行所示)之后,进入判断验证,第16行打印登录成功(第39行代码所示)。接下来,第17行执行func函数。关键点:此时的func指的是哪个函数?还记得在26行我们执行auth函数时,传的参数是什么吗?是第27行timer函数的返回值——wrapper函数的函数名wrapper。所以,foo加括号触发wrapper函数运行。
-
步骤6:程序就执行到了timer函数内部的wrapper函数(第3行)。程序继续执行wrapper内部代码,获取时间戳。
-
步骤7:关键点又来了,此时第5行的func指的哪个函数?还记得第2步骤里面的timer是怎么执行的吗?timer加括号,拿到下面(第28行)的foo函数的函数名,传递进去,并将返回值(wrppaer)赋值给foo。此时timer函数的func形参接收了foo这个变量并“记住”在作用域内。所以,此时找func就回到了最初的步骤,局部作用域找func,没有,就去上一层的嵌套作用域内找,找打了,加括号执行。执行的才是第28的真正的源代码foo函数。执行内部代码,“睡”1秒,然后执行下一行的打印(第37行出现打印结果)。foo函数执行完毕。程序回到第5行,继续往下走,算出foo函数执行的时间,并打印。此时,整个foo函数和两个装饰器程序都执行完毕。我们再来看bar函数的执行流程。
-
步骤8:bar函数装饰器的执行流程正好和foo函数的装饰器执行流程相反。因为,上面foo函数(第31行)执行完毕,程序继续往下走,因为上面已经定义好了两个装饰器函数。在执行到第40行碰到装饰器的语法糖语法,做了跟foo函数执行流程的第2步骤一样的事情,不过是反过来的。@timer会拿到下面函数的函数名当参数传给自己的func形参,将自己(tiemr函数)的返回值赋值给bar。此时的变量bar实为wrapper函数。而当timer装饰器在那下面函数名的时候,下面的@auth装饰器也做了同样的事情,去拿下面(第42行)的函数名当参数传递给自己的func参数,并将返回值inner返回(此时的inner函数内部包含着真正的bar函数的函数名)。所以在第40行timer函数传给自己func参数的实参为inner函数。此时第40行的timer在给自己传参并得到返回值再赋值给bar变量后。程序再次通过第40行的语法糖往下执行到第45行。
-
步骤9:第45行的bar加括号就执行。关键点,这个bar加括号触发了哪个函数的执行?想想第40行@timer做了什么。传参、返回值、赋值。bar函数其实是触发了wrapper函数的执行。
-
步骤10:程序回到了第3行并往下继续执行,获取当前的时间戳,执行下一行代码func()。关键点,这个func触发了哪个函数的执行?还记得timer函数在传参的时候,传的是哪个参数吗?传递的是auth函数的返回值——inner函数的函数名。所以第5行的func加括号触发了inner函数的执行。程序继续往下执行。
-
步骤11:程序走到第11行,开始接下来的用户登录认证,在第48行、第49行所示的输入结束,第50打印提示登录成功。程序走到了第17行。
-
步骤12:关键点,这个func又是哪个函数。还记得我们在第41行的@auth做了什么吗?拿到了bar函数的函数名传递给func形参。所以,此时第17行的func实为bar函数。加括号bar函数执行。
-
步骤13:程序走到了第42行开始执行bar函数的内部函数的代码,“睡”1秒后执行下一行的打印(打印结果在第51行)。bar函数执行完毕。程序继续往下走。
步骤14. 程序回到了第18行,碰到return,auth函数结束执行。关键点来了,此时你需要思考一下程序接下来往哪走?让我们回想是谁出发了inner函数的执行。是第3步骤中的第5行func()触发的。那么此时程序就回到了这里。然后程序继续往下走。
步骤15. 关键点。第6行的print中,func.__name__拿的是谁的函数名?这就又要往前看了。我们在执行第40行@timer时,为timer函数传的参数是哪个?答案在更前面,timer函数的参数是第41行的auth函数的返回值——inner函数的函数名。所以,此时func.__name__拿到的inner就对了。而在第52行的打印中,也印证了这一点,打印的是inner。此时,程序有往下执行,time.time()获取当前的时间戳再减去在第4行时获取的时间戳,得出结果后,经过整理,打印出结果。程序自此执行完毕。
通过上面的例子,两个函数的装饰器的上下顺序不同,得到的函数的运行时间是有很大的差异的。很明显,bar函数的装饰器用法,并不是老男孩开发期望的结果,因为开发只想测试一个函数的运行时间,而bar函数的装饰器,则统计了bar函数和auth装饰器共同运行的时间。
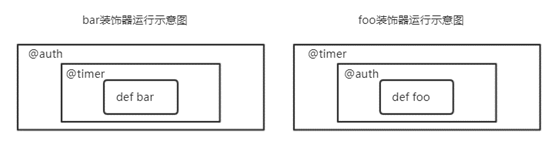
参考上图得出:
-
一个函数可以被多个装饰器装饰。
-
从代码执行角度来说,如果有多个装饰器,最上面的装饰器会把下面的函数名当成参数传给自己的形参,再重新赋值。而下面的装饰器会做同样的事情,直到最下面一层装饰器,拿到真正的被装饰的函数。也如图4.4所示。被装饰函数此时在最里面一层。真正的执行的时候,最外层如上图4.4的左侧示意图,auth装饰器执行到内部的func()时,程序执行内部的timer函数,而程序执行到timer内部的func()时,则开始执行真正的源代码,待源代码执行完毕,程序回到timer函数。timer函数的剩余逻辑代码执行完毕后,程序再次回到auth函数,执行auth函数剩余的代码逻辑,整个程序才算执行完毕。所以,真正执行的是从里面往外部执行的。
-
为了便于理解多装饰器,可以想象,最上面的装饰器开始执行,然后碰到下面的函数就将嵌套其内,下面的装饰器函数再将自己下面的装饰器嵌套自己的内部,一层一层嵌套,直到将被装饰函数嵌套到最内层。再通过在外层的装饰器的返回值,由最外层向内层一层一层的执行,而结束则是从最内层往外层一层一层结束。一句话,执行——由外到内,结束——有内到外。
上面的总结,我们再通过另一种写法来理解。
import time
def timer(func):
def wrapper():
start = time.time()
func()
print('function %s run time %s' % (func.__name__, time.time() - start))
return wrapper
def foo():
time.sleep(1)
print('function foo')
timer(foo)() # foo()= timer(foo) = timer(foo)()
'''
function foo
function foo run time 1.000493049621582
'''
上面的代码重点是第11行的写法。这种写法等于timer装饰器将foo函数的函数名传给func变量,然后拿到返回值wrapper,然后这个返回值wrapper加括号就执行。其它跟@timer语法糖一样。这种写法也证明了装饰器函数其实把被装饰器函数“包”在自己的内部执行。
通过一番讲解,开发瞬间明了。Alex老大说了那么一堆,其实不就是:想让哪个装饰器最先作用到被装饰的函数上,就把这个装饰器放到这个函数的正上方,其他的依次往上排。最上面的装饰器最先开始执行,但也是最后才结束执行的装饰器。虽然有点绕,但最上方的装饰器确实最后执行完毕。而离被装饰函数最近的装饰器,则随着被装饰函数的执行完毕,最先执行完毕。
装饰器与递归
一个很好的问题,如果用装饰器装饰递归函数,会发生什么?答案是随着递归的每次调用自身,装饰器也会不断的被执行。
如下面的递归示例:
import os
import time
def cal_time(func):
def wrapper(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
print('{} running: {}'.format(func.__name__, time.time() - start))
return res
return wrapper
@cal_time
def foo(path):
if os.path.isdir(path):
total = 0
for line in os.listdir(path):
tmp_path = os.path.join(path, line)
if os.path.isdir(tmp_path):
total += foo(tmp_path)
else:
total += 1
return total
else:
exit('给定的路径不是目录')
if __name__ == '__main__':
print(foo(r"D:\tmp"))
"""展示部分打印结果
foo running: 0.0
foo running: 0.0009958744049072266
foo running: 0.0
foo running: 0.0
foo running: 0.0009980201721191406
foo running: 0.0
foo running: 0.0
foo running: 0.0009963512420654297
foo running: 0.0
foo running: 0.0
foo running: 0.0009963512420654297
"""
上面的打印结果很明显,随着递归的每次调用,装饰器也统计了每次调用的函数执行时间。
那么,我就想计算个总耗时该怎么做?答案是可以套个马甲:
import os
import time
def cal_time(func):
def wrapper(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
print('{} running: {}'.format(func.__name__, time.time() - start))
return res
return wrapper
def _foo(path):
if os.path.isdir(path):
total = 0
for line in os.listdir(path):
tmp_path = os.path.join(path, line)
if os.path.isdir(tmp_path):
total += _foo(tmp_path)
else:
total += 1
return total
else:
exit('给定的路径不是目录')
@cal_time
def foo(path):
""" 马甲 """
return _foo(path=path)
if __name__ == '__main__':
print(foo(r"D:\tmp"))
"""
foo running: 1.0238351821899414
42077
"""
欢迎斧正,that's all

 浙公网安备 33010602011771号
浙公网安备 33010602011771号