1-Python - 函数基础
Before
在之前的学习中,只是用Python实现了一些简单的功能,这些功能也只是由简单的流程控制语句配合数据类型(如列表、字典)实现,但是这些程序有着无法避免的缺陷,比如说:
- 代码耦合性太高,各功能都糅合在一起,“干湿”不分离。
- 扩展性差,由于代码都揉在一起,如果要添加新的功能,可能就要费一番功夫了。
- 代码冗余,比如实现一个加法功能,那么当别处还需要这个功能的话,还要重新实现这个功能,这种情况多了,就是在重复的造轮子,这种情况是不可取的。
- 可读性差,经过如上的几种不可避免操作之后,代码可读性就变得非常差。
列举了如上的几种目前代码的弊端之后,该如何解决呢?解决方法就是使用函数。其实我们在之前的学习中已经体会到函数的好处了,比如要计算一个列表的长度,可能想到用for循环解决问题:
count = 0
l = [1, 2, 3, 4, 5]
for i in l:
count += 1
print(count) # 结果为:5
当要计算一串字符串、元组的长度呢?此时不可避免地陷入重复造轮子的过程。直到学习了len()函数之后。
print(len([1, 2, 3, 4, 5])) # 结果为:5
不管是字符、列表还是元组,都可以调用这个len()函数来计算。我们暂时无需了解len()函数内部具体是怎么实现的,只要知道len()函数怎么用就行了。就像我们感冒了要吃药,我们只要知道吃什么药和该怎么吃就好了,不用考虑药到底是怎么构成的 。
这章主要来学习函数的相关知识。而本篇主要讲解Python中关于函数的基础部分。
函数是通用程序的组件(部件),在别的语言中或称为过程或子例程。函数也是工具。
通俗的说,我们可以把函数想象为一个黑匣子,将数据(1+1)传递进去,经过内部一番如此这般之后,然后得到了想要的结果:

函数的定义与调用
说了这么多概念,那怎么来创建(定义)函数?
def <function_name>([arg1,agr2,…argn]):
''' functional annotation '''
pass
return
通过def关键字来定义函数,空格之后的function_name为函数名(必须有),函数的命名规则参考变量的命名。括号(必须有)内的参数是可选的,括号后面的冒号:也是必须的。注释部分为可选的(但强烈建议有注释,就像产品的说明书一样),pass部分为函数的具体功能实现代码。执行结果视情况可以选择用return返回,如果没有显式的return具体内容的话,默认返回None。
虽然def为关键字,但def也是可执行的语句,就是说当定义完函数之前,这个函数此时是不存在的:
print(dir()) # ['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
def foo():
pass
print(dir()) # ['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'foo']
由第一个打印结果显示,当程序执行到def语句之前,foo函数还不存在,而当def执行完毕,第二个打印结果告诉我们,在当前的名称空间内已经存在了foo函数。
注意:dir()函数返回绑定在当前名称空间内(如果参数为空)的变量。
当Python解释器执行到def语句时,def语句创建一个函数对象并将这个对象赋值给def后面function_name变量。然后这个变量指向这个函数,或者说这个函数名(变量名)成为了这个函数的引用。因为def为执行语句,函数可以嵌套在if等语句内:
def foo():
print("foo function")
def bar():
print("bar function")
if 1:
foo()
else:
bar()
for i in range(10):
if i == 2:
foo()
else:
bar()
通过上面的例子,也可以看到, foo()和bar()函数一处定义,多处调用。这也是函数的特点:
- 最大化的减少代码冗余和代码重用。
- 程序的结构分解,也就是解耦合。
- 打包打代码,使功能更加独立。
通过若干函数来将整个程序的功能拆分开,每个功能都是独立的存在。而上述示例也说明了函数要先定义,后调用。而例子中的函数加括号,是执行这个函数:
def foo():
return 1
print(foo) # <function foo at 0x011066A8>
print(foo()) # 1
由上例可以看到,打印这个函数时,打印的是函数在内存中的地址,而打印这个函数加括号,打印的是这个函数执行的结果。
当定义了一个函数对象之后,这个对象允许任何附属功能绑定到这个函数对象上:
def foo():
return 1
def bar():
pass
bar.a = foo()
bar.b = 3
print(bar.a) # 结果为:1
print(bar.b) # 结果为:3
可以看到,我们分别将foo函数的执行结果和整数3绑定到了bar函数对象上面了。
注意:养成良好的习惯,写注释。
虽然函数的注释是可选的,但我们强烈建议有注释(虽然后面的例子中为了节省空间且演示函数功能太小,有些可能不带),因为注释就相当于这个函数的说明书,一直以来我发现很多的程序员包括我自己,在一段时间之后,再翻看原来的代码,某些代码包括函数不加注释的话,自己都看不懂自己写的函数是干什么用的。
函数的返回值
上一小节中,在执行foo函数后,返回了执行结果1,那么就通过这个函数来说说返回值的几种形式。
函数没有return,也就是没有返回值
def foo():
pass
f = foo()
print(f) # 结果为:None
如上例所示,如果函数没有显式的写return,那么默认返回None。我们可以理解为当我们没有写return时,该函数默认return None。
返回一个值
def foo():
# return 1
# return 'abc'
# return [1, 2, 3]
# return {'a': 'b'}
return len('1234')
f = foo()
print(f) # 结果为:4
可以看到return返回的值可以是任意类型。
返回多个值
当返回多个值的时候,值之间需要用逗号隔开,最后多个值以元组的方式返回。
def foo():
return 1, 2, {'a': 'b'}, [3, 4]
print(res) # 该打印语句没有执行
result = foo()
print(result) # 结果为:(1, 2, {'a': 'b'}, [3, 4])
print(result[2]) # 结果为:{'a': 'b'}
由上例还可以发现,return之后的print语句并没有执行。这也是return的另个一个特点,那就是终止函数的执行。
函数的参数
之前示例中的函数并没有传递参数,这样的函数称为无参函数。对应就是有参函数。有参函数的参数传参方式一般为按位置传参、按关键字传参、接收可变长度的参数、命名关键字参数。而在传递参数的时候,一般根据参数的实际意义来划分,函数接收的参数为形式参数,调用函数的参数为实际参数。
def foo(value): # value: 形参,形式参数
pass
foo(2) # 2: 实参,实际参数
函数的形参可以接受任意类型的参数,但又由于不确定接收的到底什么类型,所以称为形式参数。而调用时传递的参数就是一个具体的数据,所以称为实际参数。
通俗的说,形参就像萝卜坑,而实参就是萝卜,但萝卜也不能随便找个坑就好了,什么样的萝卜对应什么样的坑那是有规矩的。一起来看看吧。
常见的函数传参方式
常规参数,按位置匹配传参
def foo1(value):
print(value)
foo1(1)
foo1函数,参数的传递按照位置传参。位置传参需要按照从左到右的顺序依次定义参数。
按位置传参的形参,必须被传值,而对应的实参,必须与形参一一对应,多一个不行,少一个也不行。
按关键字传参,通过变量名匹配传参
def foo2(value=None):
print(value)
foo2(value=2) # 指名道姓的将 2 传递给 value 参数
foo2(3) # 虽然是按位置传参,但也会传递给 value 参数
foo2函数,按照关键字传参。关键字参数可以不用像位置实参一样与形参一一对应,而是指名道姓的传。多个关键字传参的话,因为指定将key传给指定的value,所以也就不必在乎前后顺序了,为了增强可读性,我们仍建议按照位置传参的形式为关键字传参。而当形参位置已经有值的话,则为默认参数,而默认参数在定义函数阶段,就已经为形参赋值,定义阶段有值,调用阶段如无必须无需传值。如果实参是经常变化的值,那么在定义对应形参位置时定义为位置形参,如果实参是不经常变化的时候,形参可以定义为默认参数。
位置传参和关键字传参搭配传参,或称value2为默认参数
def foo3(value1, value2=None):
print("value1: {} value2: {}".format(value1, value2))
foo3(1) # 如果不为 value2 传值,那么 value2 就使用默认值 None
foo3(3, value2=3)
foo3函数,位置传参搭配关键字传参。位置参数必须在关键字参数的前面,而实参的形式既可以是按位置参数来传,也可以按关键字来传。
接收任意长度的位置参数,并收集在一个元组内
def foo4(*args): # *args 接收任意长度的位置参数,并收集到元组中
print(args)
foo4(1, 2, 3, 4)
foo4函数,以*args传递所有的实参对象,并作为一个(都被收集到元组内)基于位置的参数。就是说*args接收所有的除key=value格式的位置参数。
位置传参和可变长度搭配传参
def foo5(value, *args):
print(value, args)
foo5(1, 2, 3, 4, 5) # 第一个参数按照位置传参,剩余的被 *args 收集
foo5函数,位置和可变长度的*args结合,从结果来看,从左到右的第一个参数按位置传递给了value,而剩余的位置参数都被*args接收。
*args接收任意长度的位置参数,并收集到元组中, 命名关键字参数value接收关键字参数
def foo6(*args, value):
print(args,value) # (1, 2, 3, 4) 5
foo6(1, 2, 3, 4, value=5) # 命名关键字传参,前面被*args接收,value以key=value的形式传递
foo6函数,可变长度参数配合命名关键字参数(value),*args接收所有位置参数,而当value在*args后面的时候,我们称其为命名关键字参数,而命名关键字参数定义在*后的形参,这类形参,必须被传值,而且要求实参必须是以关键字的形式来传值。
接收任意长度的key=value形式的参数,并收集到一个字典内,一般在所有的参数的后面
def foo7(**kwargs):
print(kwargs) # {'a': 1, 'b': 2, 'c': 3}
foo7(a=1, b=2, c=3)
foo7函数,**kwargs接收任意长度的key=value格式的参数,并收集到字典中。请牢记,**kwargs如果和别的形参搭配使用时,必须在所有参数的最右侧使用。
接收任意长度的位置参数和key=value形式的参数,且kwargs必须放在args后面
def foo8(*args, **kwargs):
print(args, kwargs) # (1, 2, 3, 4) {'a': 5, 'b': 6}
foo8(1, 2, 3, 4, a=5, b=6) # 普通位置参数被*args接收,关键字参数被**kwargs接收
foo8函数,*args和**kwargs一起使用的话,可以接收任意形式、任意长度的参数。但切记**kwargs还是要放到*args的后面。
各种传参混用,但是不推荐这种传参方式,提高了代码的复杂度,这里只是介绍可以这么用而已
def foo9(value1, value2=None, *args, value3, **kwargs):
print("value1:{}, value2:{}, args:{}, value3:{}, kwargs:{}".format(value1, value2, args, value3, kwargs))
"""
value1:1, value2:2, args:(3, 4), value3:5, kwargs:{'a': 6, 'b': 7}
"""
foo9(1, 2, 3, 4, value3=5, a=6, b=7)
foo9函数展示了从左到右的各种传参方式的先后位置。那么从左到右依次为:位置参数、关键字参数(默认参数)、*args、命名关键字参数、**kwargs。
虽然没错,但不推荐的用法
def foo10(*x, **y): # 与*args和**kwargs一样
print(x, y) # (1, 2, 3, 4) {'a': 5, 'b': 6}
foo10(1, 2, 3, 4, a=5, b=6)
可变长度的参数指实参个数不固定,按位置定义的可变长度参数用*表示,而按照关键字定义的可变长度参数为**。所以,*x和**y是等价于*args和**kwargs的,但我们通俗的对*用*args(Postional Arguments)表示,**用**kwargs(Keyword Arguments)表示,但是请牢记,args和kwargs并不是Python的关键字。
*args的聚合和打散
def foo(*args, **kwargs):
print('args: ', args) # args: ([1, 2, 3, 4],)
print('*args: ', *args) # *args: [1, 2, 3, 4]
print('kwargs: ', kwargs) # kwargs: {'a': 5, 'b': 6}
foo([1, 2, 3, 4], a=5, b=6)
上例,通过第2行代码可以看到,当形参是*args的时候,表示聚合,就是把位置参数都收集到元组内(列表算一个位置参数);而在第3行时,则又为分散的了(元组的括号没了),什么原因呢?当print函数执行打印这个聚合(元组形式)的数据的时候,被加了*(相当于元组前面加*),表示数据被解包了,也就是说被打散了,变成了一个个的对象,而不再是元组形式的了。
def foo(*args, **kwargs):
print('args: ', args) # args: ([1, 2, 3, 4],)
print('*args: ', *args) # *args: [1, 2, 3, 4]
print('kwargs: ', kwargs) # kwargs: {'a': 5, 'b': 6}
print('*kwargs: ', *kwargs) # *kwargs: a b
print('**kwargs: ', **kwargs) # TypeError: 'a' is an invalid keyword argument for this function
foo([1, 2, 3, 4], a=5, b=6)
上例,通过第6行可以看到,我们在传参的时候为列表加个*,然后形参聚合成元组,而在第2行打印的时候,由于这个*还在,所以打散,然后第3行的时候,由于传进来一个*再加上这一行原有的一个*,执行两边打散操作。而需要注意的是,在第5行打印*kwargs的时候,我们只是收集了key,而打印**kwargs则报错了,这点需要我们注意。
注意,*args和**kwargs允许不传参。也就是这个位置有参数就接收,没有参数传进来,也不报错。
def test1(*args, **kwargs):
print(666) # 666
print('没有参数,不报错', *args, **kwargs) # 没有参数,不报错
test1()
def test2(*args, **kwargs):
print(666) # 666
print('有参数就接收', *args, **kwargs) # 传参就接收 oldboy {'age': 23}
test2('oldboy', {'age': 23})
通过上面的例子,可以看到,test1函数没有传递参数,但函数依然运行,没有报错,而test2函数则将传来的参数,接收并整理。
除了无参函数和有参函数,还有空函数,那就是我们已经见过的形式。
def foo():
pass
再通过一个例子了解一下函数的另一个特性:
def foo(x, y):
return x + y
print(foo(1, 2)) # 3
print(foo('a', 'b')) # ab
上面例子向我们传递了一个重要的信息。那就是多态!例子中的foo函数内的x + y的返回结果,完全取决于传递参数的数据类型。正如第3行的print执行的是加法运算,而第4行的print执行的是赋值运算。Python在这里将+号对传进来的数据根据类型做了随机应变的处理。这种依赖数据类型做随机应变的行为称为多态。虽然这个foo函数功能简陋,但是只要我们传递的参数类型是+这个运算符所能处理的,那么它就可以随处被调用,只要我们了解这个函数的规则,那么它对我们来说就像接口一样,有着很强大的兼容性,这无疑在增加了函数的灵活性。这也是像len()之类的函数这么好用的原因之一。但毕竟不能肆无忌惮的传参,因为它处理不了的话,就会报错。
函数默认参数的陷阱
函数对象
在Python中,函数可以被当作数据传递,也就是说,函数可以被引用,被传递,也可以当做返回值,也可以当做容器类型(元组,列表)的元素。
函数可以被引用
定义一个foo函数,这个函数可以被变量f1和f2引用,这是在之前的例子中常用到的。
def foo():
return 'ok'
f1 = foo()
print('f1: ',f1) # f1: ok
f2 = foo
print('f2: ',f2) # f2: <function foo at 0x00373A98>
print('f2(): ',f2()) # f2(): ok
而在第5行将foo函数被变量f2引用后,此时打印的(第6行)为foo的内存地址,而f2加括号(第7行)触发了foo函数的执行。返回"ok"。
函数可以当做函数的参数
def bar():
a = 1
print('a =',a)
def foo(b):
pass
foo(bar)
上例中,bar函数被当作foo函数的实参传递给形参b。
函数可以当做函数的返回值
def bar():
print('bar function')
def foo():
return bar
f = foo()
print(f) # <function bar at 0x00FA3A98>
f() # bar function
上例中,foo函数返回的是bar函数,foo函数将结果赋值给f。在第6行打印的时候可以看到打印的bar函数的内存地址,那么变量f加括号相当于bar函数加括号,执行bar函数的print。
函数可以当做容器类型的元素
通过与用户交互,模拟文件的增删改查操作,每个函数对应不同的操作,暂时用打印来代替具体的操作。通过这个练习来理解为什么说函数可以当做容器类型的元素。
def add():
print('add function')
def update():
print('update function')
def select():
print('select function')
def delete():
print('delete function')
dict = {'add': add, 'update': update, 'select': select, 'delete': delete}
while 1:
cmd = input('Enter command: ').strip()
if cmd in dict:
dict[cmd]()
elif cmd == 'q':
print('goodbye')
break
else:
print('Error command')
continue
代码第1~7行,定义增删改查四个函数,print就算代替具体的操作了。第9行定义一个字典。第10行开始,写了一个循环用来与用户进行交互。第11行获取用户输入的内容,第12行开始判断,用户输入的cmd是否在dict内,如果在说明cmd是dict的key,那么dict[cmd]取出对应的value,而value是对应的增删改查的函数,找到函数加括号(第13行)就能执行这个函数。完成增删改查的操作(执行print)。而第14行当用户输入"q"的时候,退出程序。第17行是当用户输入无效的命令的时候,提示并从新循环等待输入。运行结果如下例所示:
Enter command: asss # 输入错误命令,会提示命令无效,并等待用户重新输入
Error command
Enter command: add # 输入正确的命令,执行对应的函数,并等待用户重新输入
add function
Enter command: q # 用户输入"q",则退出程序
goodbye
Process finished with exit code 0
命名空间与作用域
在之前的学习中,我们随便的定义函数,随便的将数据赋值给变量。但Python真的放心我们这么无所顾忌?真相是不允许的,接下来通过一个示例来了解一下变量的知识。
x = 1
def foo():
x = 2
print(x)
def bar():
print(x)
foo() # 2
bar() # 1
上例中,我们执行了foo和bar函数(第7~8行),分别打印了2和1这两个变量对应的值。那么,为什么bar函数打印的是x=1的结果?而foo函数打印的是x=2的结果?为什么bar函数不能打印x=2的值?而foo函数却没有打印x=1的值?而且我们在上例中随手写了两个函数,但我们却使用了四个变量名,两个函数名加上2个变量x,那么Python是如何管理这些变量名的呢?要回答这些问题,我们就要学习关于变量作用域的知识了。
变量的作用域,顾名思义,就是变量起作用的范围。上例中,我们定义了两个同名的变量x,为什么Python在执行的时候,没有造成混乱,这就是归功于作用域了。
当定义一个变量之后,Python在创建、查找、使用、修改这个变量名都是在一个"地方"进行的,我们称这个"地方"为——命名空间,或称为名称空间。当程序执行变量所对应的代码时,作用域指的就是命名空间。所有变量命包括作用域在内,都是Python赋值时生成的,而且必须在赋值后,才能被调用,Python在给变量赋值时,就将变量赋值的地点绑定给一个特定的命名空间,这个命名空间则决定了变量的作用范围了。这就解释通了上面的那些疑惑。通过作用域可以总结:
- 变量在函数内部定义,只能作用于函数内部,而外部无法调用这个变量。
- 因为有了作用域,在函数内部外部定义两个相同的变量名,却不会引起冲突。
- 在任何情况下,变量的作用域只是与被赋值的地方有关,而与函数调用没有关系。
在Python中,关于作用域有着自己的原则,如下图所示:
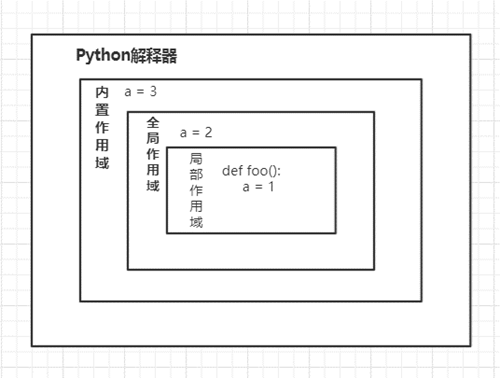
一般的,我们将函数内部定义的变量称为本地变量,作用域称为本地作用域,或称局部作用域。顾名思义,就在本地起作用,作用于当前函数内部。
而全局作用域的话,就是说在当前文件的顶层定义的变量。作用于当前文件。
内置作用域则是Python解释器内置模块定义好的。这才是实际意义上的全局作用域,因为在何处都可以被直接调用,如内置的那些关键字。作用于所有需要使用的地方。
上面的意思可能有点难懂。其实,每个文件都可以称为一个模块,而只有在Python解释器层面通过一些手段调用全部的模块(文件),这样的话,我们才可以操作这些模块内的"全局变量"了,但我们要区分开内置(解释器层的)作用域的和全局作用域(模块层的)的区别。如果我们在Python中听到全局的,那么你第一反应就是模块层级的全局作用域。
变量的查找顺序
结合上图中的伪代码写出了上面的代码示例,我们在foo函数内部(本地作用域)定义了变量a=1,在函数外部定义了a=2,在函数的外部(全局作用域)的外部(内置作用域)定义(按我们能定义展开讨论,事实上,我们不在解释器内置层面定义自己的变量,当然也不做其他的修改)了a=3,那么,这个三个变量a的作用域的范围是不同的,如果在foo函数内部打印这个a变量,Python首先找本地作用域下的a=1,找到后打印;但如果我们在示例代码内将a=1注释了,这时,Python在找的时候本地作用域下没有,就会去全局作用域下去找,找了a=2,然后打印,但如果全局作用域下的a=2也被注释,那么Python解释器就会去内置作用域下去找,找到a=3,执行打印。如果内置作用域下也没有变量a, Python解释器就会抛出一个NameError: name 'a' is not defined的NameError错误。
Python在查找变量时遵守作用域原则LEGB,顺序如下图所示:

关于嵌套函数层(Enclosing function local)是Python后来新增的,我们暂时先忽略,现在可以记住Python查找变量的顺序是Local(本地作用域)、 Global(全局作用域) 、 Built-in(内置作用域),如果本地查到就算成功,不再往下一级查找,都查找不到则报错。
现在让我们总结一下:
-
Python解释器层才是真正的全局作用域。
-
一般意义上的全局作用域是指当前模块中定义的顶级变量。
-
Python查找变量的顺序遵循
LEGB原则。 -
每次函数的调用都创建一个新的本地作用域,也就是说每一个def表达式都会定义一个新的本地作用域,这是为了后续可能做的其他操作提供便利。
虽然已经知道了内置作用域,但内置作用域并没有你想象的那么复杂和神秘,内置作用域只是由一个名为__builtin__模块提供的。可以通过导入builtins模块就可以查看Python为我们提供了哪些内置的变量名:
Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import builtins # 由于版本差异,Python2需要这么导入:import __builtin__ 查看:dir(__builtin__)
>>> dir(builtins)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException',
'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning',
'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError',
'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning',
'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError',
'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit',
'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError',
'InterruptedError', 'IsADirectoryError','KeyError', 'KeyboardInterrupt',
'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None',
'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError',
'OverflowError', 'PendingDeprecationWarning', 'PermissionError',
'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning',
'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration',
'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError',
'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError',
'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning',
'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError',
'__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__',
'__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool',
'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex',
'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval',
'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals',
'hasattr', 'hash','help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass',
'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview',
'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property',
'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice',
'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars',
'zip']
现在讲述一件真实的故事。老男孩的官网要改后台管理员的用户名,由root改为oldboy,开发接到任务就开始更改相关代码:
ADMIN = 'root'
def login():
''' login function '''
# global ADMIN
ADMIN = 'oldboy'
print(ADMIN) # oldboy
login()
print(ADMIN) # root
在login函数内将admin改为oldboy,下一行的打印也成功了,但是,可以看到第8行的打印结果并没有改过来,怎么回事?其实在本地作用域只能调用全局的作用域,但无法修改全局作用域下的值。开发就向老大Alex请教,Alex一看代码,就冷冷的说一句,把第4行代码的注释打开。
ADMIN = 'root'
def login():
''' login function '''
global ADMIN
ADMIN = 'oldboy'
print(ADMIN) # oldboy
login()
def master():
''' master fuction '''
print(ADMIN) # oldboy
master()
def maintenance():
''' maintenance function '''
if ADMIN == 'root':
print(ADMIN)
else:
print(ADMIN) # oldboy
maintenance()
把注释打开就好了,老大(master函数)看后觉得可以的。竖日,运维(maintenance函数)要登录老男孩官网,但是怎么都无法登录进去,这又是怎么回事?
首先,我们如果有需求需要从本地作用域修改全局作用域的变量,那么就用global语句来声明(global语句只用来做命名空间的声明)。它告诉Python函数打算生成(全局作用域没有则生成,有则修改)一个或多个全局变量名。global语句的语法。
def foo():
global val1, val2, ... valn
global可以声明多个变量,变量之间用逗号隔开。
我们并不建议使用过多的global语句,因为这很难控制。尽管global语句在有些情况下很好用(站在login函数的角度来说),但也会造成一些别的问题(对maintenance函数就不是那么友好了),如运维在不知道情况的时候,就无法登录了,这种是不安全的。所以在使用global语句的时候,还需要多多注意。避免发生上面那个真实的故事。
嵌套函数与嵌套作用域
在上一小节中,我们“忽略”了一个知识点,那就是Python查找变量遵循的LEGB原则时,我们把E略过没说,这里我们就来研究一下这个E是到底有什么神奇之处。
x = 1
def foo():
x = 2
def bar1():
x = 3
def bar2():
x = 4
如上例所示,嵌套函数指的是一个函数foo,将另一个(也可有多个)函数bar1,嵌套其内,而bar1函数又将bar2函数嵌套其内,理论上可以嵌套多层,但这无疑降低了代码的可读性,并增加了编写难度,故不推荐这种写法。
而嵌套作用域,顾名思义,被嵌套起来的作用域,指的是嵌套在函数内部的作用域。相对于全局作用域来说,foo函数为局部作用域。对于其内的其他函数,则为嵌套作用域。而对于bar1函数来说,上一层至foo函数为嵌套作用域。而bar1函数又为局部作用域。对于bar2来说,bar1和foo函数都为其嵌套作用域。bar2函数内部又为局部作用域。Python在查找变量x时,比如查找bar2下的变量x,首先在自己的局部作用域查找,有的话就不往上再查找了。如果没有,则去上一层嵌套作用域bar1函数内查找,如果bar1函数内没有变量x,则再往上一层的foo函数查找,如果foo函数层也没有,那么嵌套作用域查找完毕,再往上去全局作用域查找,没有则再去内置作用域查找,最后都没有就抛出NameError的错误。
嵌套函数一般分为两种,函数的嵌套调用和函数的嵌套定义。
def foo(x, y):
if x > y: # 如果x大,则返回x
return x
return y # 否则将y返回
def bar(a, b, c, d):
ret = foo(a, b) # 调用foo函数拿到一个大的值,跟下一个参数进行比较
ret = foo(ret, c)
ret = foo(ret, d) # 通过几次比较,拿到最大的值
return ret # 将最大的值返回
print(bar(2, 3, 1, 4)) # 打印返回的结果:4
上面的例子中,演示了嵌套函数的嵌套调用。foo函数用来比较两个数的大小,并将大值返回,而bar函数则通过调用foo函数来计算4个值的最大值,最后将最大值返回。
def f1():
x = 2
print('from f1', x)
def f2():
print('from f2')
def f3():
print('from f3')
f3() # from f3
f2() # from f2
f1() # from f1 2
print(f1) # <function f1 at 0x00FD4B28>
# print(f2) # NameError: name 'f2' is not defined
# print(x) # NameError: name 'x' is not defined
上面的例子,演示了嵌套函数的定义。我们在f1函数中定义了f2函数,在f2函数内部定义了f3函数。通过执行函数,执行各自的print语句。而且,通过被注释的第12~13行可以看到,我们在函数外部无法访问其内部的变量名(函数名也是变量名)。
x = 1
def foo(x):
def bar(y):
return x < y
return bar
f = foo(10) # 基准值:10
print(f) # <function foo.<locals>.bar at 0x00C56738>
print(f(5)) # False
print(f(20)) # True
print(bar) # NameError: name 'bar' is not defined
上例中,第1行定义全局变量x,第2到5行定义了函数foo将bar函数嵌套其内,bar函数返回两个参数的比较结果,foo函数则将bar函数的内存地址返回。第6行执行foo函数并传参,通过第7行的打印可以看到变量f其实就是bar函数,那么函数f加括号就可以执行(第8,9行),并且得到比较的返回结果。而第10行打印则报bar没有定义。通过这个例子可以总结如下:
-
嵌套函数(bar)首先在本地作用域(bar函数自己的本地作用域)查找变量x,如果没有的话,则往上一层foo函数的作用域(嵌套作用域)查找,没有的话则再向全局和内置作用域查找。
-
被嵌套的函数(bar)无法被外部引用。
-
上例中,在第6行时为
foo函数形参x传递了参数10,并且只在最开始传递了一次,而在后面bar函数两次(第8,9行)调用都使用了10这个参数,可以理解为在第6行传递了参数,嵌套作用域就"记住"了这变量值,后面的打印都去调用这个变量值,并没有去全局作用找x=1。这种行为我们称为为闭合(closure)或者工厂函数,指能够记住嵌套函数作用域的值的函数。由此可以发现:命名空间是Python在运行时动态维护的。但一般的,嵌套函数内部的作用域是静态的,称为静态嵌套作用域。这样做是为了保护嵌套函数内部的变量不受外部命名空间的影响,从而保持一致的结果。如上例中。这种有"记忆"的功能在某些情况下特别有效。比如说嵌套作用域通常用来被lambda函数使用(lambda我们稍后讲)。 -
同样有"记忆"功能的是类,而且类更加高明,因为类让这些"记忆状态"更清晰、更明确。除了类和嵌套函数之外,全局变量和默认参数(函数的参数)也能起到"记忆"的效果。
def ta():
num = 1
print(num) # 1
def ba():
global num
num = 3
return num
return ba()
print(ta()) # 3
在默认情况下,一个变量名num在第一次赋值时已经创建。如果嵌套作用域(ta函数)下的局部作用域(ba函数)的变量名由global声明(第5行),此变量会创建或修改变量名num为整个模块的作用域(全局作用域)。通过第9行的打印可以看到,在全局作用域下找到了变量num。而不会影响当前嵌套作用域的num。通过第3行的打印可以看到,num的值并没有改变。
嵌套作用域下的变量在global后,会将当前局部的变量直接声明为全局变量,而嵌套作用域的同名变量不受影响。那么,当有些情况下,我们要只修改嵌套作用域下的变量,而不会影响全局作用域下的变量怎么办?比如只修改上例中第2行的num值为3。这时候就用到了nonlocal了。nonlocal的语法是:
def foo():
nonlocal val1, val2, ... valn
nonlocal可以声明多个变量,变量之间用逗号隔开。需要注意的是,nonlocal是在Python 3.x版本时引入的,下面的示例代码在Python 2.x解释器中运行,会引起报错:
x = 5
def ta():
x = 1
def ba():
x = 100
def ca():
nonlocal x
x = 3
ca()
print('Local ba x, after nonlocal:', x) # Local x, after nonlocal: 3
ba()
print('Enclosing ta x:', x) # Enclosing x: 1
ta()
print('Global x:', x) # Global x: 5
上例中,第1行,定义全局变量x=5,第2行,定义嵌套函数ta,ta内部定义x=1,第4行,定义嵌套函数ba,在第5行定义x=100,在第6行又定义ca函数,ca函数内部nonlocal声明变量x,在第8行定义x=3。第9行执行ca函数,第10行打印ba函数内的x变量的值,第11执行ba函数,第12行打印嵌套作用域下(ta函数)的变量x的值。第13执行ta函数。第14行打印全局变量下的变量x的值。
通过打印结果,我们可以得出结论,nonlocal声明修改嵌套作用域下的变量,而不会影响全局作用域,只从当前作用域往上一层嵌套作用域查找,而不会影响更上一层的变量,比如我们打印了ta函数下的x,就没有受影响。
再通过一个例子来总结一下global和nonlocal的区别。
x = 1
def foo():
x = 2
def bar1():
global x, y
x = 100
y = 150
bar1()
def bar2():
# nonlocal y # SyntaxError: no binding for nonlocal 'y' found
nonlocal x
x = 3
y = 30
bar2()
print('Enclosing x', x) # 3
foo()
print(x, y) # x = 100, y = 150
上例中,第1行定义全局变量x=1,第2行定义函数foo,并在第3行定义x=2,第4行定义函数bar1,global声明变量x、y,第6~7行分别赋值变量x、y,第8行执行函数bar1。第9行定义函数bar2,并在第10行用nonlocal声明x、y,但最后注释了,稍后我们再解释为什么注释。第11行nonlocal声明变量x。第12~13行分别赋值变量x、y。第14~15行分别执行bar2函数、foo函数。第16行打印全局变量x,y。通过上例,我们可以看到global与nonlocal的区别:
-
global声明变量为全局变量时,如果全局变量存在则修改,不存在则创建。
-
nonlocal在声明变量y时,变量y必须存在。如第10行的报错,我们在嵌套作用域内并没有提前定义变量y,故报错。而第11行声明变量x时,当前的嵌套作用域内存在变量x,从而在第12行修改成功并且在第15行打印修改后的x的变量值。
-
nonlocal只能作用于嵌套作用域,无法影响到全局作用域。
-
global则是将嵌套作用域下(foo函数)的局部作用域(bar1函数)的变量直接声明为全局作用域。而不会影响到其嵌套作用域内的变量。
无论是global还是nonlocal,我们都要小心使用,以免造成其给作用域带来的某些异常。
闭包函数
在前文中说过嵌套函数还有一种特殊的表现形式——闭合(closure),我们称这种特殊的嵌套函数为闭包函数。
def foo():
x = 1
y = 2
def bar():
print(x, y)
return bar
f = foo() # 变量f就是bar函数,加括号就能执行
print(f) # <function foo.<locals>.bar at 0x01136738>
print(f.__closure__) # (<cell at 0x011BD070: int object at 0x604999C0>, <cell at 0x011BDED0: int object at 0x604999D0>)
print(f.__closure__[0].cell_contents) # 1
print(f.__closure__[1].cell_contents) # 2
参考上例来讨论一下闭包函数的特点。
闭包函数是指在函数(foo函数)内部定义的函数(bar函数),称为内部函数,该内部函数包含对嵌套作用域的引用,而不是全局作用域的引用。那么,该内部函数称为闭包函数。
闭包函数包含对嵌套作用域的引用,而不是全局作用域的引用。这句话通过第8行的打印,我们分析,虽然打印的结果只是bar函数的内存地址,但是其不仅仅是明面上的内存地址那么简单,这个bar函数还自带其外部的嵌套作用域。闭包函数相关的__closure__属性,__closure__ 属性定义的是一个包含 cell 对象的元组,其中元组中的每一个 cell 对象用来保存局部作用域中引用了哪些嵌套作用域变量。第9行打印的结果印证了这一点。我们在嵌套作用域内定义了2个变量x、y。而第9行的打印结果为一个元组,其内存在两个元素地址。我们通过第10~11行的打印取元组的第1个、第2个元素进一步验证,我们顺利的拿到了存在与嵌套函数x、y的变量值。
x = 1
def foo():
def bar():
print(x)
return bar
f = foo()
print(f.__closure__) # None
上例也证明内部函数bar只包含对嵌套作用域的引用,而不是全局作用域的引用,因为第4行引用的变量是全局的变量x。而通过第7行打印也证明这一点,bar函数的__closure__属性返回为None,也就是空值。如果嵌套作用域内有变量x,那么__closure__属性内就会存在嵌套作用域的变量地址。
def f1():
x = 1
y = 2
def b1():
print(x)
return b1
f = f1()
print(f.__closure__) # (<cell at 0x00B6D070: int object at 0x604999C0>,)
def f2():
x = 1
y = 2
def b2():
print(x, y)
return b2
f = f2()
print(f.__closure__) # (<cell at 0x0123DED0: int object at 0x604999C0>, <cell at 0x01248430: int object at 0x604999D0>)
但有一点需要说明的是,不管嵌套作用域内定义了多少变量。而内部函数包含对嵌套作用域的引用这句话。指的是内部函数的__closure__属性内的元组内元素个数,取决于在局部作用域中对嵌套作用域中哪些变量的引用。如上例,在f1函数内定义了两个变量,但在b1函数只引用了x这一个变量。所以b1函数的__closure__属性内只存在一个嵌套作用域的变量地址。而第13行在局部作用域引用了两个嵌套作用域的变量。故b2的__closure__内就有两个值。
上面的例子都为闭包函数的一层嵌套形式,下面的例子为闭包函数的两层嵌套形式。跟一层闭包函数一样,最内层的函数,包含对嵌套作用域的引用。
def foo():
name = 'oldboy'
def bar():
money = 1000
def oldboy_info():
print('%s have money: %s' % (name, money))
return oldboy_info
return bar
bar = foo()
oldboy_info = bar()
oldboy_info() # oldboy have money: 1000
print(oldboy_info.__closure__) # (<cell at 0x0090D050: int object at 0x009B9570>, <cell at 0x00900FF0: str object at 0x0090D060>)
print(oldboy_info.__closure__[0].cell_contents) # 1000
print(oldboy_info.__closure__[1].cell_contents) # oldboy
上例中,第6行的打印的name和money变量,是对上级作用域(bar函数)和顶级嵌套作用域(foo函数)的引用。通过第13~14行的打印可以看出,oldboy_info函数的__closure__内包含了2个变量。
欢迎斧正,that's all

 浙公网安备 33010602011771号
浙公网安备 33010602011771号