1-Python - 深、浅拷贝那些事儿
前言
我们初学者总会对深浅拷贝产生疑惑。
现在,是时候解决这个问题了。
首先......
赋值带来的问题
在Python中,我们或多或少的都会遇到一些赋值带来的问题:
>>> l1 = [1, 2, 3]
>>> l2 = l1
>>> id(l1), id(l2)
(57456640, 57456640)
>>> l1.append('a')
>>> l1, l2, id(l1), id(l2)
([1, 2, 3, 'a'], [1, 2, 3, 'a'], 57456640, 57456640)
如上例所示,我们定义了列表l1,并且将该列表赋值给l2。在后面我们为l1添加一个元素,却发现l2也跟着改变了?这到底是怎么回事?
Python中变量的存储关系
要弄懂这是怎么回事,首先,我们要明白关于变量和值在内存中的存储形式。
在高级的语言中,变量是对内存及地址的一种抽象,这种说法同样适用于Python。
在Python中,变量或者对象的存储,都采用了引用语义的形式,也就是说存储的只是变量值所在的内存地址,而不是值本身。变量和值的关系有两种:
- 引用语义:在Python中,变量保存的是对象(值)的引用,称为引用语义(或称对象语义或指针语义),变量所需的存储空间大小一致,而不随着值得大小而变化。
- 值语义:如C语言采用值语义,就是说把变量和值同时保存在一个存储空间内,每个变量在内存中所占的空间就要根据值的大小而定。

引用语义也就是说,如果a = 1,那么Python在初始化a的时候,会在内存中为变量a开辟一个内存空间,为值1也开辟一块内存空间。在a的内存空间中存着1的内存地址。这样,就在a与1之间建立了一种指向关系。
所以,这带来了开始的问题,当多个变量都指向同一个内存地址时。当该内存地址中的值发生变化,那么所有指向它的变量都会受到影响。
不同数据类型的地址存储及改变
了解了Python中变量和值的关系。我们再来聊聊关于“值”的一些事情。
要知道,变量指向的值,都是一个具体的数据类型,而不同的类型又有不同的特性。所以,我们要继续研究不同数据类型在内存中的表现。
首先,我们知道,在Python中,数据类型包括:bool、int、float、str、set、list、tuple、dict等等。在通过一定的组织后,这些数据类型又可以组成不同的数据结构。那么数据结构是如何划分的呢?一般的, 如果一个数据类型,可以将其他的数据类型当做自己的元素,那么就称为一种数据结构。而这些元素我们又称为基础数据类型。Python中,常用的数据结构有三种:
- 集合:set。
- 序列类型:list、tuple、str。
- 映射类型:dict。
数据结构还包括:层次结构、树形结构、图结构等等。
基础数据类型包括:
- int
- float
- bool
- str
这个str挺特殊的,因为在C语言的角度来说,str只是char的集合。
由于Python的变量是采用引用语义,所以,每个变量中存储的只是值得内存地址而不是值本身。
数据类型重新初始化对Python语义的影响
变量的每一次初始化,都会开辟一块内存空间,然后与新的值建立指向关系。
s1 = 'old str'
print(id(s1)) # 25482560
s1 = 'new str'
print(id(s1)) # 25482592
上述s1的变化如下图所示。
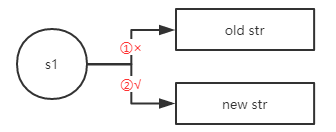
有图可以看到,当为s1从新指向一个新的字符串时,它首先断开与原字符串的指向关系,然后建立与新的字符串的指向关系。
数据结构重新初始化对Python语义的影响
我们再来观察复杂的数据类型(结构):
l1 = [1, 2, 3]
print(id(l1))
l1.append('a') # 20061360
print(id(l1)) # 20061360
l1 = [2, 3, 4]
print(id(l1)) # 20058320
由打印结果可以发现,当对列表中的元素进行修改的时候,是不会改变列表(l1)本身的内存地址。只会改变其内部元素的地址引用。而当我们对列表进行重新赋值(初始化)的时候,就等于重新给l1创建了一个新的内存地址。原来地址如果没有别的变量指向它,就会被垃圾回收机制回收掉了,释放内存空间。
上述这种情况同样适用其他数据结构中。
变量赋值
我们继续研究,来看变量赋值操作干了些什么事。
先来看字符串的赋值时发生了什么。
s1 = 'old str'
s2 = s1
print(id(s1), id(s2)) # 23713088 23713088
s2 = 'new str'
print(id(s1), id(s2)) # 23713088 23713120
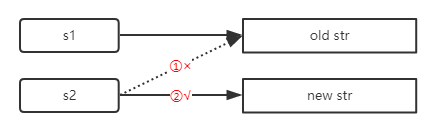
上图解释了代码中内存地质的变化。
开始,定义变量s1并指向old str,接着定义变量s2并且,s2 = s1,相当于s2同样指向字符串old str,所以,s1和s2指向的是同一个内存地址。
接着,变量s2重新赋值,指向字符串new str,此时变量s2的内存地址发生变化,但是并不会影响变量s1。
再来看列表中有何变化:
l1 = [1, 2, 3]
l2 = l1
print(l1, id(l1)) # [1, 2, 3] 27794608
print(l2, id(l2)) # [1, 2, 3] 27794608
l1.append('a')
print(l1, id(l1)) # [1, 2, 3, 'a'] 27794608
print(l2, id(l2)) # [1, 2, 3, 'a'] 27794608
对照上图,我们发现,变量l1和l2都指向同一个列表。而通过l1添加一个元素时,会发现,变量l1和l2都发生变化,但是这两个变量的内存地址都没有变化。
就像你和你对象同喝一杯奶茶,杯子还是那个杯子,但是你猛嘬一口,你对象同样会感受到这杯奶茶少了一大半!
拷贝
通过之前的铺垫,我们知道了变量赋值的过程,对于复杂的数据结构来说,它保存了对值的引用,如果这个值被别的变量引用,那么这个值一旦发生变化,那么所有指向的它的变量都能感受到变化。
但是,我们很可能会碰到一种情况,一份数据要将原始内容保存,然后再去修改。这个时候,使用赋值就不会引起麻烦。所以,Python为类似的需求提供了copy模块,该模块提供了两种拷贝方法,一种是普通的拷贝(浅拷贝)copy.copy(),另一种是copy.deepcopy(),我们称为深拷贝。
接下来我们来一探究竟。
浅拷贝
先来看浅拷贝:
import copy
x = [4, 5]
l1 = [1, 2, 3, x]
l2 = copy.copy(l1)
print(l1, id(l1)) # [1, 2, 3, [4, 5]] 31913424
print(l2, id(l2)) # [1, 2, 3, [4, 5]] 31659672
l1.append('a')
print(l1, id(l1)) # [1, 2, 3, [4, 5], 'a'] 31913424
print(l2, id(l2)) # [1, 2, 3, [4, 5]] 31659672
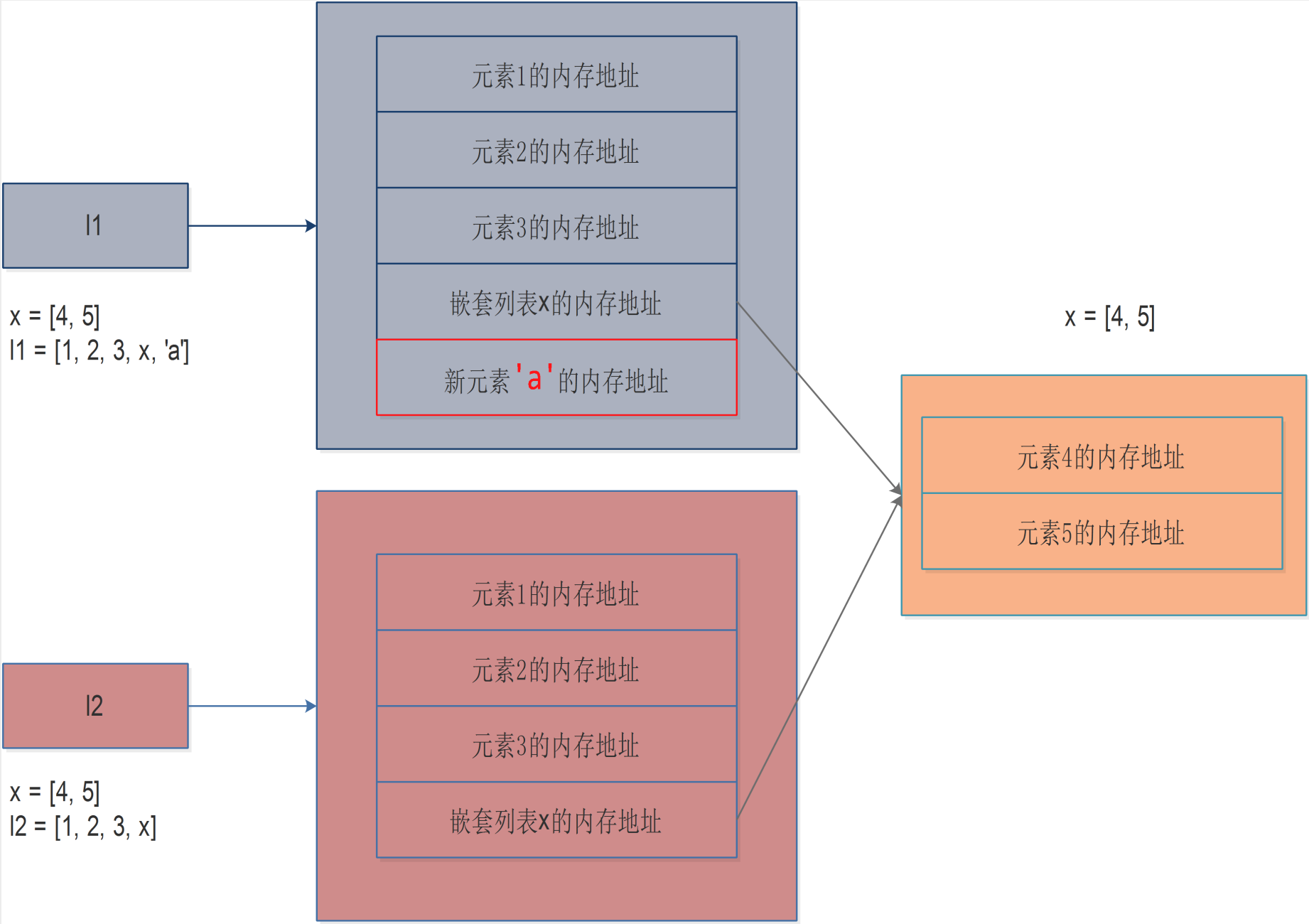
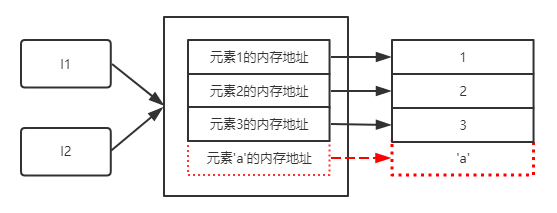
参考上图,我们来聊聊浅拷贝发生了么。
浅拷贝就是将原列表l1中的一级元素地址拷贝一份(包括嵌套列表x的内存地址),然后赋值给一个新的变量l2。此时,向l1中添加一个元素a,那么此时的存储关系如上图所示,l1中多了一个新元素a,而l2不会受影响。
看似没有什么问题,我们试着向嵌套列表x中添加一个元素试试:
import copy
x = [4, 5]
l1 = [1, 2, 3, x]
l2 = copy.copy(l1)
print(l1, id(l1)) # [1, 2, 3, [4, 5]] 31913424
print(l2, id(l2)) # [1, 2, 3, [4, 5]] 31659672
l1.append('a')
print(l1, id(l1)) # [1, 2, 3, [4, 5], 'a'] 31913424
print(l2, id(l2)) # [1, 2, 3, [4, 5]] 31659672
l1[3].append('w')
print(l1, id(l1)) # [1, 2, 3, [4, 5, 'w'], 'a'] 31913424
print(l2, id(l2)) # [1, 2, 3, [4, 5, 'w']] 31659672
我们通过l1向嵌套列表x添加一个元素w后,发现l2也受了影响。
这是怎么回事?我们来通过下图来分析:
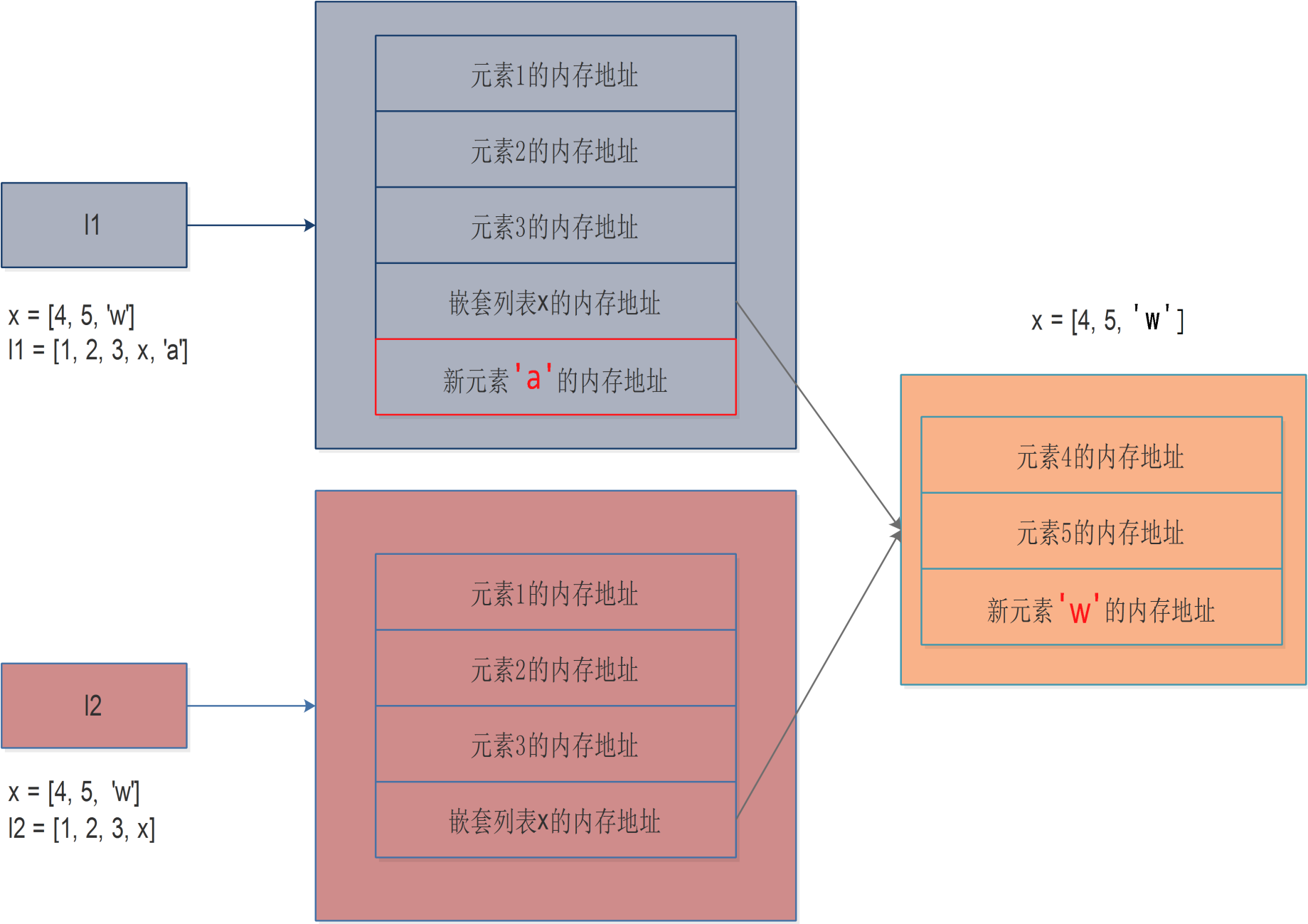
根据图中的关系所示,可以看到l1和l2保存的是嵌套列表的内存地址,那么修改嵌套列表中的元素,但并不会造成整个嵌套列表的内存地址发生改变,所以,结果显而易见,所有引用该嵌套列表的变量都会受到影响。
这种情况发生在字典嵌套字典、字典嵌套列表,列表嵌套字典、列表嵌套列表等复杂的嵌套中。
所以,当你使用浅拷贝的时候,要小心哦~
深拷贝
那么,很多时候,我们希望完全拷贝一份,并且它们之间没有半毛钱关系。
这时候,我们需要引入一个深拷贝的概念,即copy.deepcopy(),该方法会将原数据结构完全复制一份,两份数据之间不会相互影响。
import copy
x = [4, 5]
l1 = [1, 2, 3, x]
l2 = copy.deepcopy(l1)
print(l1, id(l1)) # [1, 2, 3, [4, 5]] 32249296
print(l2, id(l2)) # [1, 2, 3, [4, 5]] 32249616
l1.append('a')
print(l1, id(l1)) # [1, 2, 3, [4, 5], 'a'] 32249296
print(l2, id(l2)) # [1, 2, 3, [4, 5]] 32249616
l1[3].append('w')
print(l1, id(l1)) # [1, 2, 3, [4, 5, 'w'], 'a'] 32249296
print(l2, id(l2)) # [1, 2, 3, [4, 5]] 32249616
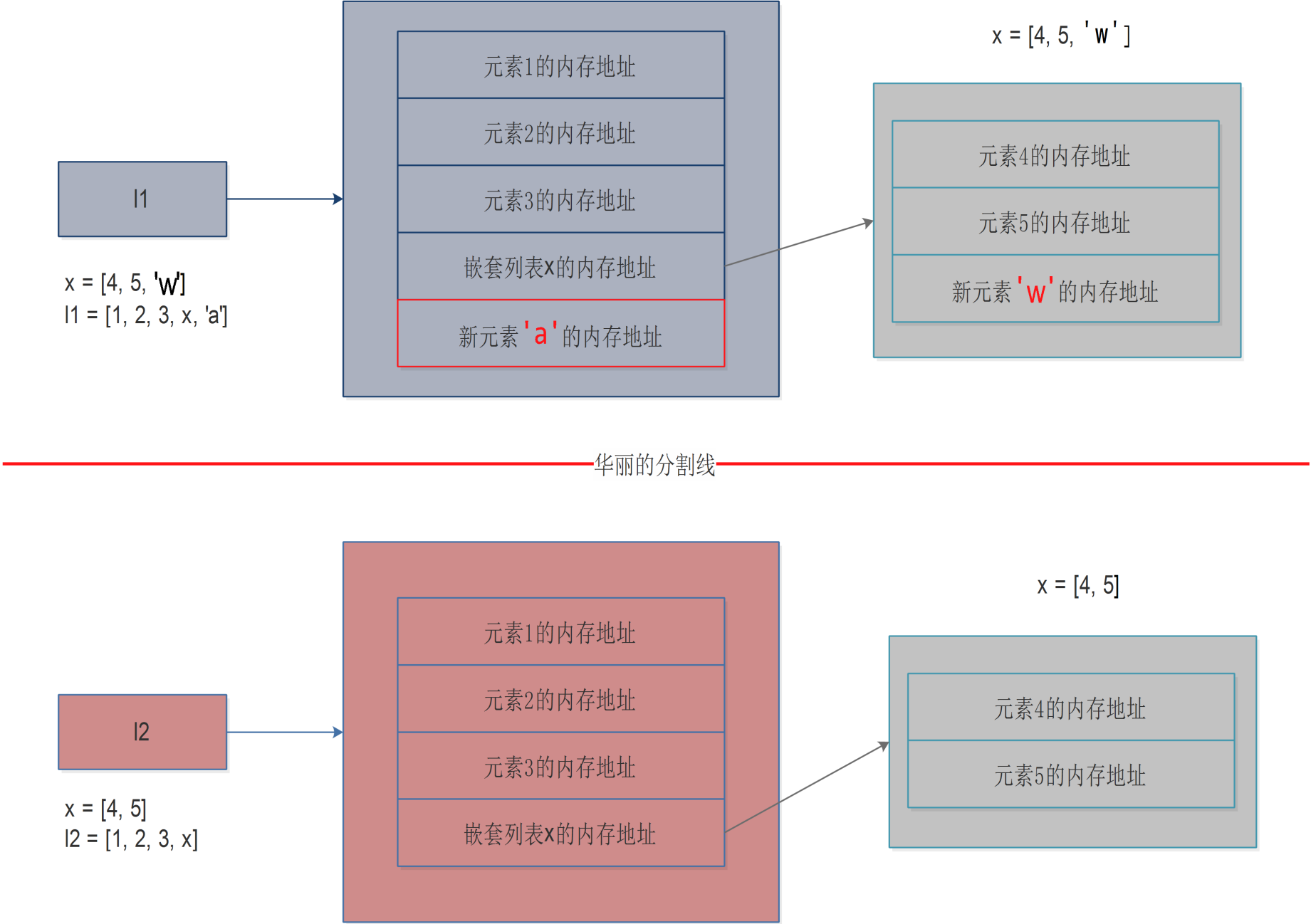
由上图可见,当使用copy.deepcopy()后,完整的将l1拷贝一份,赋值给l2(另开辟空间存储),而且l1和l2之间没有半毛钱关系,你l1怎么折腾(修改顶级元素或者修改嵌套列表内的元素),都跟我l2没有关系,反之亦然,如果我l2要是修改其元素的话,也跟你l1没有半毛钱关系。
这就是深拷贝!
对于对象的深浅拷贝的应用
如果你要对类的实例化对象进行拷贝的话,这里需要注意点。
import copy
class A:
li = [1, 2, 3]
def __init__(self):
self.li1 = ['a', 'b', 'c']
a = A()
a_copy = copy.copy(a)
a_deepcopy = copy.deepcopy(a)
# 通过对象修改类变量,可以通过打印看到所有的对象都受影响
a_copy.li.append(4)
a_deepcopy.li.append(5)
print(a.li, a_copy.li, a_deepcopy.li) # [1, 2, 3, 4, 5] [1, 2, 3, 4, 5] [1, 2, 3, 4, 5]
# 但修改对象自己的变量,则浅拷贝受影响,深拷贝不受影响
a_copy.li1.append('x')
a_deepcopy.li1.append('y')
print(a.li1, a_copy.li1, a_deepcopy.li1) # ['a', 'b', 'c', 'x'] ['a', 'b', 'c', 'x'] ['a', 'b', 'c', 'y']
欢迎斧正,that's all see also:[python——赋值与深浅拷贝](https://www.cnblogs.com/Eva-J/p/5534037.html)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号