1-Python - 字符编码
About
接下来展开讨论关于字符串的另一个知识点:字符编码。
字符编码的发展
我们都经历过,在编写一份Word文件的时候,突然电脑没电了。然后你辛辛苦苦的码的字都没了,只好从新开电脑再写了。那你有没有想过这是为什么呢?因为我们打开Word软件的时候,系统就将Word中的内容都读到内存中,继续编写内容,这些新编写的内容也在内存中。当单击保存的时候,这些数据会从内存中保存到硬盘上,如果没保存就突然断电(内存具有断电数据丢失的特性),这些数据也就无法保存。而我们要了解的是当打开和保存的时候,这其中发生的故事。
通过第一章编程语言的发展,我们知道计算机要想工作必须通电,即用“电”驱使计算机干活,也就是说“电”的特性决定了计算机的特性。电的特性即高低电平(人类从逻辑上将二进制数1对应高电平,二进制数0对应低电平),那我们得出结论:计算机只认识数字。那么在使用计算的过程中,用的都是人能读懂的字符,如何让计算机也读懂人类的字符呢?这必须经过一个过程:
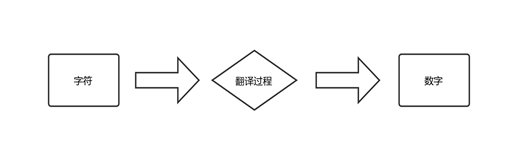
而这个过程(如Word保存数据的过程)实际就是一个字符如何对应一个特定数字的标准(过程),这个标准称为字符编码。
那接下来聊聊编码的前世今生。
ASCII编码
由于计算机是美国人发明,最早他们在规定英文字母数字包括特殊字符与数字对应的关系时,规定一个字节(8个二进制位)表示一个字符(英文字符/键盘上所有的字符),即2**8=256,能表示256个字符。并把这些对应关系编写在一张表上——ASCII(American Standard
Code for Information Interchange,美国信息交换标准代码)。比如A对应的00010001。
每八位表示一种变化,每种变化对应的表示一种字符,所以,最多也就能表示2**8=256个字符。
ASCII最初只用了后7位,也就是128个字符,包括英文(只有26个字符),算上一些特殊字符和数字,128(最高位没用上,默认补0)个字符也够用了,后来计算机为了表示拉丁文,就将最后一位也用了,至此ASCII表算是用满了。
注意:每个电平为一个bit(比特位),8个bit组成为一个Bytes(字节)。
先来补充一个字节转换关系:
8bit = 1Bytes = 1字节
1024Bytes = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
注意:字节单位为大写开头。硬盘上每存储1GB的文件,就是1GB = 1024(MB)*1024(KB)*1024(Bytes)*8(bit)这么多的bit位。
至此我们都用英文肯定没问题,但是各国的语言文字都不一样。比如计算机在漂洋过海来到中国后,如何处理中文,单拿一个字节表示一个汉字,这不能表达完所有的汉字。解决办法那就是扩大字节表示,ASCII用1个字节代表一个字符,那就用两个字节代表一个汉字,就是16位的二进制表示。位数越多,代表的变化就越多。就这样,中国人制定了自己的标准GB2312(截止到目前为止,最新为GB 18030-2005)编码,规定了包含中文字符与数字的特定对应关系。
计算机漂洋过海去了日本之后,日本也规定了自己的Shift_JIS编码,韩国人也不甘落后,规定了自己的EUC-KR编码。
可以想象一个画面,计算机每到一个新的语言环境,就会有一个新的编码规范表出现.....
此时,各家是各自为战,各搞各的,此时,乱世需要英雄啊!需要”人“来一统江湖!
Unicode编码
这样看似挺好,大家都能使用计算机了。但是问题也出现了,假如精通八国语言的张开用八种语言写了一篇文章,那这篇文章,无论安照哪个国家的编码表,都会出现乱码(按照一个国家的标准保存的文字不会有问题,但其他的国家的文字不在这个编码表上就会乱码),这个时候就迫切的需要一个统一的标准(包含所有的语言)。于是Unicode(单一码,万国码,统一码)应运而生,Unicode规定用2个字节代表一个字符(所以说Unicode是定长的),生僻字用4个字节表示。并且Unicode兼容ASCII,是世界标准。
看似Unicode只能表示2**16-1=65535这么多字符,但实际Unicode可以表示一百万+的字符,因为Unicode中还存放着与其他编码的映射关系。所以,准确的说Unicode不算是严格意义上的字符编码表。
UTF系列:UTF-8
问题又来了!如果我们的文档内容全部为英文,用Unicode会比ASCII多耗费一倍的空间(ASCII一个字母占1个字节,而Unicode同样的字母要用2个字节(早期版本,现在是4个字节,来自维基百科:https://zh.wikipedia.org/wiki/Unicode))

这在存储和传输上十分的低效。所以为了改变Unicode定长的弊端,在Unicode的基础上演化出了UTF-8可变长度的编码。
UTF-8(8-bit Unicode Transformation Format)编码把一个Unicode字符根据数字的大小编码为1-6个字节(2003年重新规范为最多4个字节)。常用的英文字母占用1个字节,一般汉字占用3个字节,生僻字占用4~6个字节,这样,在存储的过程中非常节约空间。下表展示了字符在不同编码表上的表示方式。
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | ASCII无法识别中文 | 01001110 00101101 | 11100100 10111000 10101101 |
从上表中还可以发现,UTF-8编码中的第一个字节与ASCII编码兼容。所以,大量只支持ASCII编码的历史遗留的软件,在UTF-8编码下还可以欢快的工作。
扩展:UTF-8是一种可变长编码标准,是目前主流的编码方式。据统计2016年的互联网超过80%的网页采用UTF-8编码,其他的还有UTF-16,UTF-32,但我们由于篇幅限制不过多介绍。
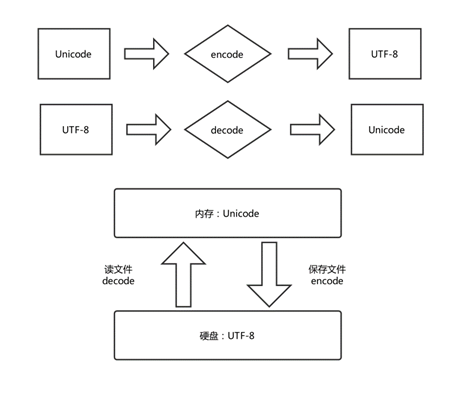
为什么计算机的内存采用Unicode编码,而存储一般选择UTF-8,因为在内存中要求处理效率高,用空间换时间,而且定长的Unicode可以访问万国语言而不乱码;UTF-8没有字节序,所以用来存储和传输就相当方便了。
保证不乱码的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码。
小结:
- Unicode,简单粗暴,所有字符都用4个字节表示,优点是字符与数字的转换速度快,缺点也很明显,占用空间大。
- UTF-8,对不同的字符用不同的长度表示,优点是节省空间,缺点是字符/数字的转换速度慢,因为它要计算出字符需要多长的Bytes才能够准确表示。
- 内存中使用的编码是Unicode,思想是用空间换时间,因为内存中的程序运行要尽可能的保证快。
- 硬盘或网络传输用UTF-8,网络I/O延迟或者磁盘I/O延迟要远大于UTF-8的转换延迟,而且I/O应该是尽可能的节省带宽。
字符编码之Python3
目前,内存中的编码固定为Unicode编码,我们仅能改变的是硬盘上的数据编码,所以在打开Word编写内容的时候,其实经历了如下图所示的从UTF-8(根据软件所使用的编码,也可是是其他的编码如GBK)格式的二进制文件解码为Unicode格式的内存中。
写文件:
name = "王战山"
data = name.encode('utf-8')
print(data, len(data)) # b'\xe7\x8e\x8b\xe6\x88\x98\xe5\xb1\xb1' 9
# 1.打开文件
f = open("db.txt", mode='wb')
# 2.写入内容
f.write(data)
# 3.关闭文件
f.close()
读文件:
# 1.打开文件
# - 关于路径 相对路径-当前运行的代码文件; 绝对路径-直接路径。
# - 打开模式 append+字节(压缩) a特点:文件不存在则创建文件 + 文件尾部追加
f = open("db.txt", mode='rb')
# 原始数据, 压缩后的数据,utf-8编码字节
content = f.read()
f.close()
print(content, len(content)) # b'\xe7\x8e\x8b\xe6\x88\x98\xe5\xb1\xb1' 9
# 字节转换回字符串
data_string = content.decode('utf-8')
print(data_string) # 王战山
如果读写文件编码不统一:
name = "王战山"
f = open("db.txt", mode='w', encoding='utf-8')
f.write(name)
f.close()
# 写时是以utf-8编码写入的,读的时候,也应该是utf-8
f = open("db.txt", mode='r', encoding='utf-8')
content1 = f.read()
f.close()
print(content1) # 王战山
# 如果不是utf-8,就会报错
f = open("db.txt", mode='r', encoding='gbk')
content2 = f.read() # UnicodeDecodeError: 'gbk' codec can't decode byte 0xb1 in position 8: incomplete multibyte sequence
f.close()
字符编码之Python2
由于Python的诞生要比Unicode要早,Python 2中默认就采用了ASCII编码。后来Unicode携手UTF-8一统江湖直到现在。所以Python 3默认采用UTF-8编码。
Python2字符(串)类型分为str和Unicode。
当我们用Python 2解释器来执行一个py文件时。如果不指定编码,会发生错误:
a = "你好"
我们使用Python 2来执行该文件:
M:\>python27 a.py
File "a.py", line 1
SyntaxError: Non-ASCII character '\xe4' in file a.py on line 1, but no encoding declared; see
http://python.org/dev/peps/pep-0263/ for details
分析报错内容,中文字符不在ASCII表内,所以报错。原因是发生在Python解释器解释过程中的报错。其实Python解释器在执行这个文件的时候,经历了三个过程:
- Python解释器启动。
- Python解释器读取a.py文件,这一步跟notepad++一样,只是读了文件内容。而notepad++则是展示或者修改内容,而Python解释器则是要执行代码,当然,此时代码并没有执行。
- 按照Python的规则执行内容,在执行到将“你好”这个字符串赋值给“a”的时候,发生错误。因为在存储这个文件的时候没有指定编码格式,那么就是按照notepad++(默认)的格式(UTF-8)存储的(Unicode ▶ encode ▶ UTF-8)。所以当Python解释器再读取这个文件的时候(UTF-8 ▶ decode ▶ Unicode),也没错。错就错在当没有指明编码的时候,Python2是按照自己的默认编码来解释这个字符串,就造成了ASCII无法识别中文的问题。
解决办法,在解释器执行这个文件的时候,在文件的头部指定编码方式,告诉解释器要按照什么编码来执行:
# coding:GBK
a = '你好'
在经过文件头部指定编码方式之后,Python解释器就按照GBK编码的方式来执行文件,将“你好”这串字符串以GBK的方式赋值给变量“a”,保存在内存中。这也说明了,内存中的数据不一定全是Unicode的,是可以由我们自己指定的。但这就完了么, 没那么简单。我们来打印一下这个变量:
# coding:GBK
a = '你好'
print(a) # 浣犲ソ
print(type(a)) # <type 'str'>
什么情况?为什么不是我们想要的“你好”?这里说明一下,print()方法会在内部经过转换成让我们看着更友好的结果。其实真实的结果是第二行的打印结果,现在揭晓谜底,Python2在按照GBK存储的时候将这个变量结果以字节类型来存储在内存中的,类型也就是str字节字符串类型,那么第一个print的友好的结果为什么依然“不友好”呢?因为我们在开始存储这个py文件的时候是默认按照UTF-8的方式存储的,现在你却按照GBK的方式打印,当然“不友好”了,想要友好,我们要指定解码方式:
# coding:UTF-8
a = '你好'
print(a.decode('UTF-8')) # 你好
print(type(a)) # <type 'str'>
通过学习我们得出结论:Python 2的字符默认格式是Unicode,默认字节类型是str。另外,我们可以通过文件头来声明以什么方式解码。
# coding:UTF-8
or
# -*- coding: GBK -*-
注意:如果你在别处看到coding之后的编码方式为:gbk、utf8、utf-8等其他的方式的话。这些都为解释器所接受。
而Python 2想要将字符串存储为Unicode格式,就要在字符串前加“u”。
Python 2.7.14 (v2.7.14:84471935ed, Sep 16 2017, 20:19:30) [MSC v.1500 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> a = '你好'
>>> a, type(a)
('\xc4\xe3\xba\xc3', <type 'str'>)
>>> b = u'你好'
>>> b, type(b)
(u'\u4f60\u597d', <type 'unicode'>)
而Python 3的字节类型和字符串类型则分别为bytes和Unicode,所以,Python 3中的字符串在打印的时候就不会出现如Python 2一样的乱码,而且,这个Unicode类型的字符串想要得到bytes 类型,要通过encode来实现。
Python 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:14:34) [MSC v.1900 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> a = '你好'
>>> a, type(a)
('你好', <class 'str'>)
>>> a.encode('GBK')
b'\xc4\xe3\xba\xc3'
>>> a.encode('UTF-8')
b'\xe4\xbd\xa0\xe5\xa5\xbd'
通过上面的示例可以看到,无论encode为何种编码方式,都为bytes 类型,只是存储方式不同而已。
扩展:Python 2、Python 3可以通过sys模块来查看各自的编码方式。
# Python3.x
import sys
print(sys.getdefaultencoding()) # 'utf-8'
# Python2.x
import sys
print(sys.getdefaultencoding()) # 'ascii'
所以Python 2的字符串有两个类型str和Unicode,而Python 3则为bytes和Unicode。其实我们可以这样理解,Python 2中的str类型就是Python 3中的bytes类型 。
所以,在Python 3中字符串有两种,文本类型字符Unicode和字节类型(或称字节流)字符Bytes。
欢迎斧正,that's all,see also:
python基础之字符编码 | Python 编码为什么那么蛋疼? | PEP 263 -- Defining Python Source Code Encodings | ascii-code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号